 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhenyu Li
The RoboDepth Challenge: Methods and Advancements Towards Robust Depth Estimation
Jul 27, 2023

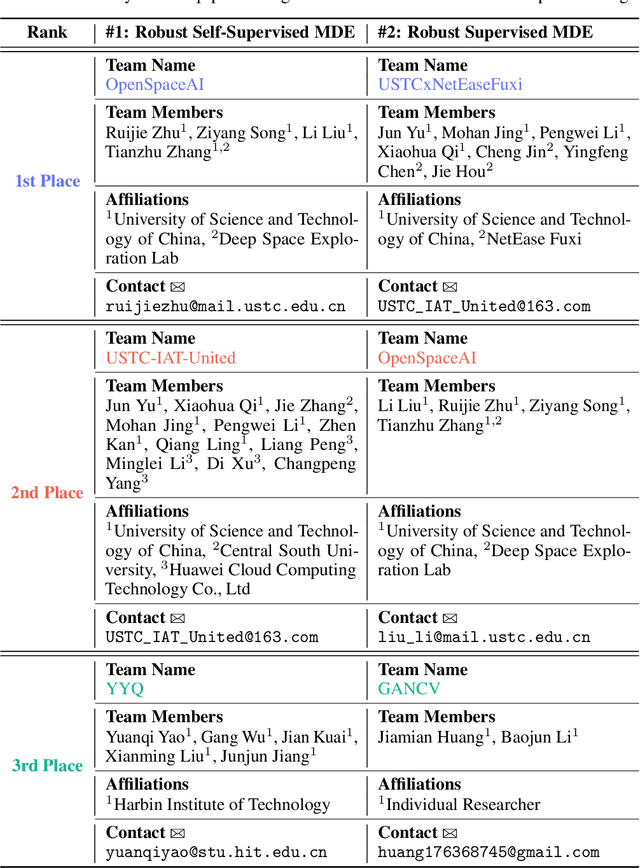

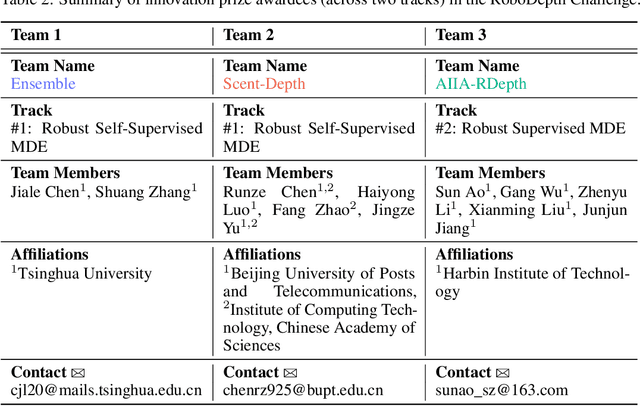
Accurate depth estimation under out-of-distribution (OoD) scenarios, such as adverse weather conditions, sensor failure, and noise contamination, is desirable for safety-critical applications. Existing depth estimation systems, however, suffer inevitably from real-world corruptions and perturbations and are struggled to provide reliable depth predictions under such cases. In this paper, we summarize the winning solutions from the RoboDepth Challenge -- an academic competition designed to facilitate and advance robust OoD depth estimation. This challenge was developed based on the newly established KITTI-C and NYUDepth2-C benchmarks. We hosted two stand-alone tracks, with an emphasis on robust self-supervised and robust fully-supervised depth estimation, respectively. Out of more than two hundred participants, nine unique and top-performing solutions have appeared, with novel designs ranging from the following aspects: spatial- and frequency-domain augmentations, masked image modeling, image restoration and super-resolution, adversarial training, diffusion-based noise suppression, vision-language pre-training, learned model ensembling, and hierarchical feature enhancement. Extensive experimental analyses along with insightful observations are drawn to better understand the rationale behind each design. We hope this challenge could lay a solid foundation for future research on robust and reliable depth estimation and beyond. The datasets, competition toolkit, workshop recordings, and source code from the winning teams are publicly available on the challenge website.
Secure Split Learning against Property Inference, Data Reconstruction, and Feature Space Hijacking Attacks
Apr 19, 2023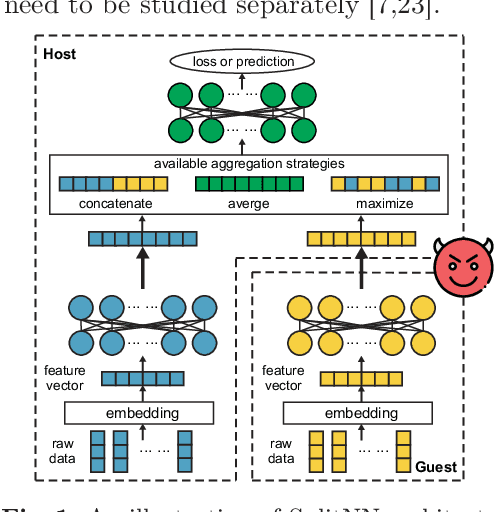
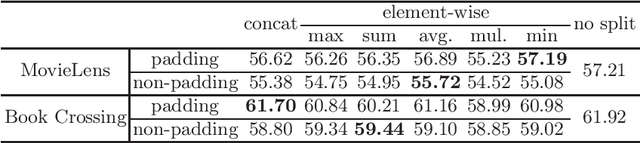
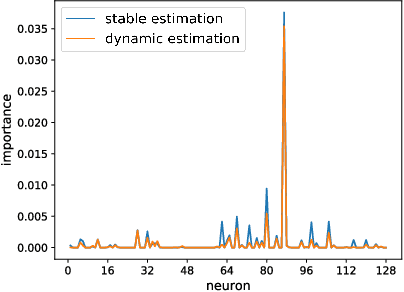

Split learning of deep neural networks (SplitNN) has provided a promising solution to learning jointly for the mutual interest of a guest and a host, which may come from different backgrounds, holding features partitioned vertically. However, SplitNN creates a new attack surface for the adversarial participant, holding back its practical use in the real world. By investigating the adversarial effects of highly threatening attacks, including property inference, data reconstruction, and feature hijacking attacks, we identify the underlying vulnerability of SplitNN and propose a countermeasure. To prevent potential threats and ensure the learning guarantees of SplitNN, we design a privacy-preserving tunnel for information exchange between the guest and the host. The intuition is to perturb the propagation of knowledge in each direction with a controllable unified solution. To this end, we propose a new activation function named R3eLU, transferring private smashed data and partial loss into randomized responses in forward and backward propagations, respectively. We give the first attempt to secure split learning against three threatening attacks and present a fine-grained privacy budget allocation scheme. The analysis proves that our privacy-preserving SplitNN solution provides a tight privacy budget, while the experimental results show that our solution performs better than existing solutions in most cases and achieves a good tradeoff between defense and model usability.
Bridging the Language Gap: Knowledge Injected Multilingual Question Answering
Apr 06, 2023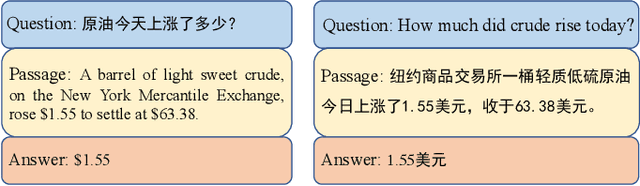
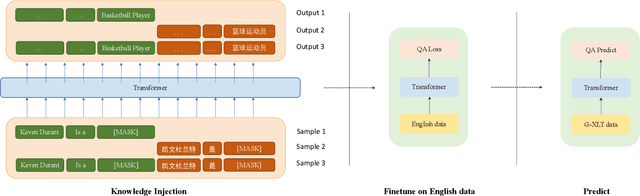
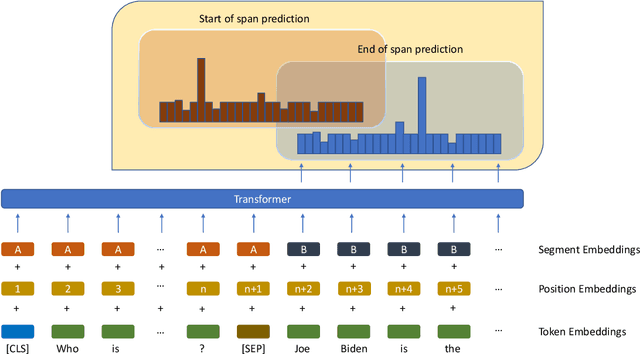
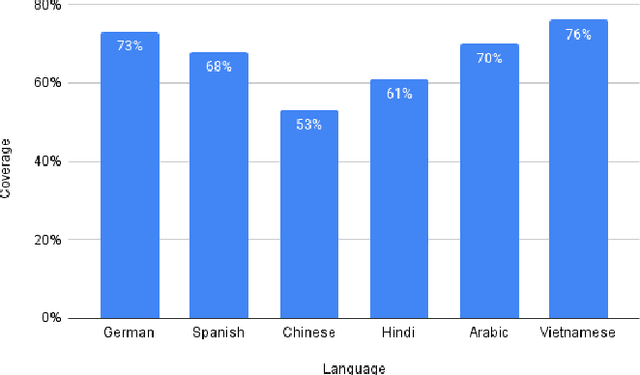
Question Answering (QA) is the task of automatically answering questions posed by humans in natural languages. There are different settings to answer a question, such as abstractive, extractive, boolean, and multiple-choice QA. As a popular topic in natural language processing tasks, extractive question answering task (extractive QA) has gained extensive attention in the past few years. With the continuous evolvement of the world, generalized cross-lingual transfer (G-XLT), where question and answer context are in different languages, poses some unique challenges over cross-lingual transfer (XLT), where question and answer context are in the same language. With the boost of corresponding development of related benchmarks, many works have been done to improve the performance of various language QA tasks. However, only a few works are dedicated to the G-XLT task. In this work, we propose a generalized cross-lingual transfer framework to enhance the model's ability to understand different languages. Specifically, we first assemble triples from different languages to form multilingual knowledge. Since the lack of knowledge between different languages greatly limits models' reasoning ability, we further design a knowledge injection strategy via leveraging link prediction techniques to enrich the model storage of multilingual knowledge. In this way, we can profoundly exploit rich semantic knowledge. Experiment results on real-world datasets MLQA demonstrate that the proposed method can improve the performance by a large margin, outperforming the baseline method by 13.18%/12.00% F1/EM on average.
Augment and Criticize: Exploring Informative Samples for Semi-Supervised Monocular 3D Object Detection
Mar 20, 2023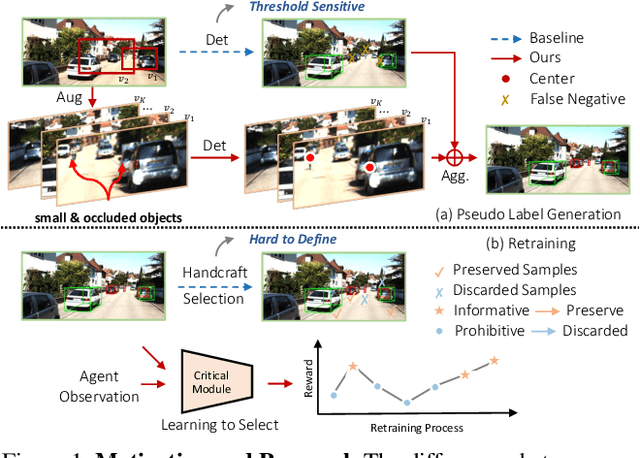
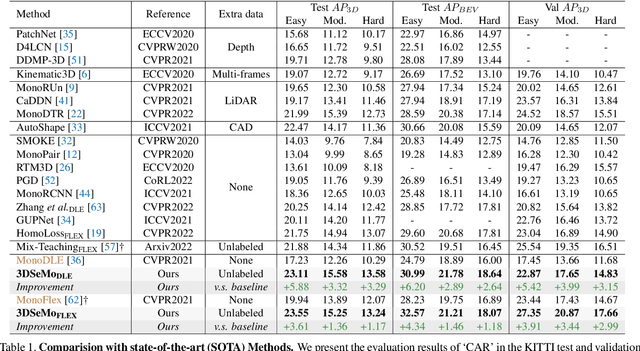
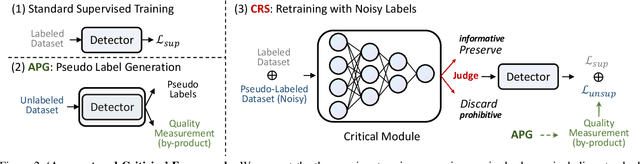
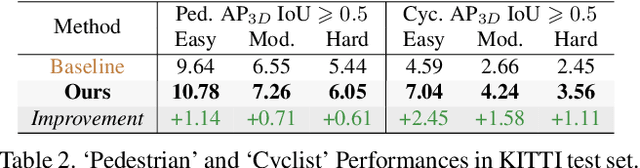
In this paper, we improve the challenging monocular 3D object detection problem with a general semi-supervised framework. Specifically, having observed that the bottleneck of this task lies in lacking reliable and informative samples to train the detector, we introduce a novel, simple, yet effective `Augment and Criticize' framework that explores abundant informative samples from unlabeled data for learning more robust detection models. In the `Augment' stage, we present the Augmentation-based Prediction aGgregation (APG), which aggregates detections from various automatically learned augmented views to improve the robustness of pseudo label generation. Since not all pseudo labels from APG are beneficially informative, the subsequent `Criticize' phase is presented. In particular, we introduce the Critical Retraining Strategy (CRS) that, unlike simply filtering pseudo labels using a fixed threshold (e.g., classification score) as in 2D semi-supervised tasks, leverages a learnable network to evaluate the contribution of unlabeled images at different training timestamps. This way, the noisy samples prohibitive to model evolution could be effectively suppressed. To validate our framework, we apply it to MonoDLE and MonoFlex. The two new detectors, dubbed 3DSeMo_DLE and 3DSeMo_FLEX, achieve state-of-the-art results with remarkable improvements for over 3.5% AP_3D/BEV (Easy) on KITTI, showing its effectiveness and generality. Code and models will be released.
mmWave Coverage Extension Using Reconfigurable Intelligent Surfaces in Indoor Dense Spaces
Feb 18, 2023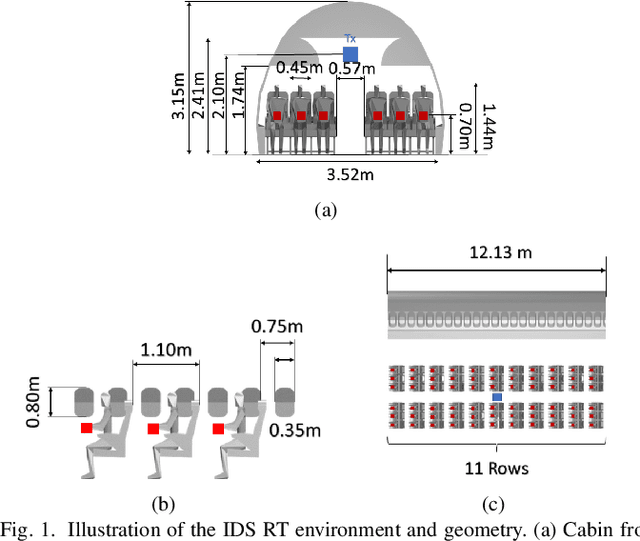
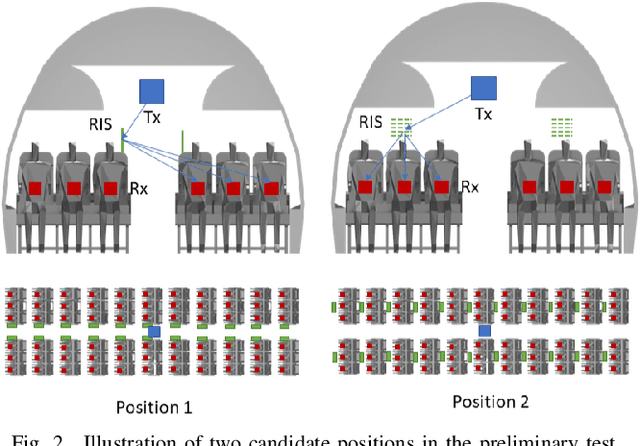
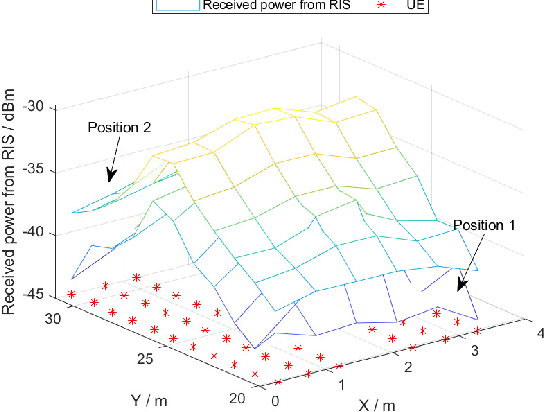
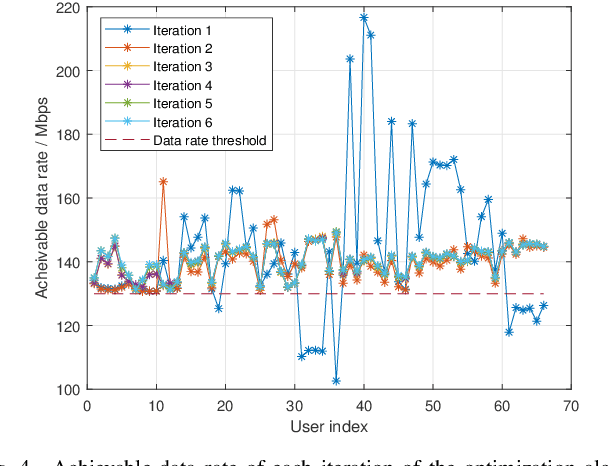
In this work, we consider the deployment of reconfigurable intelligent surfaces (RISs) to extend the coverage of a millimeter-wave (mmWave) network in indoor dense spaces. We first integrate RIS into ray-tracing simulations to realistically capture the propagation characteristics, then formulate a non-convex optimization problem that minimizes the number of RISs under rate constraints. We propose a feasible point pursuit and successive convex approximation-based algorithm, which solves the problem by jointly selecting the RIS locations, optimizing the RIS phase-shifts, and allocating time resources to user equipments (UEs). The numerical results demonstrate substantial coverage extension by using at least four RISs, and a data rate of 130 Mbit/s is guaranteed for UEs in the considered area of an airplane cabin.
Toward a Unified Framework for Unsupervised Complex Tabular Reasoning
Dec 20, 2022
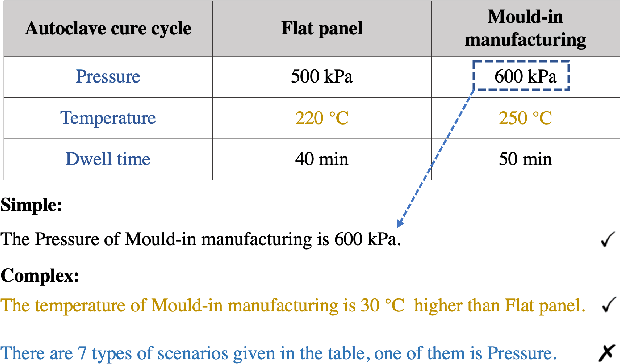
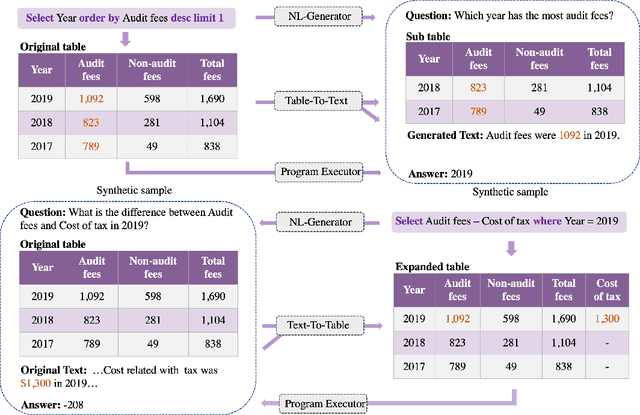
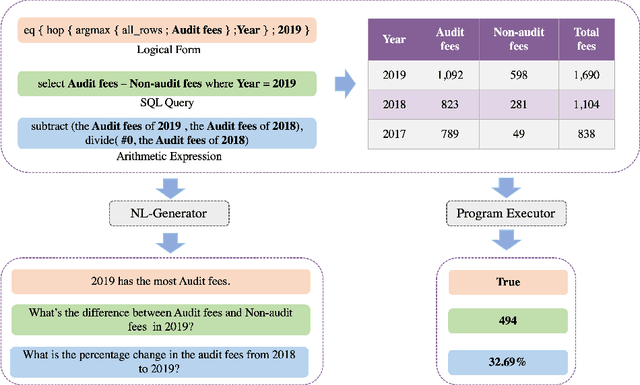
Structured tabular data exist across nearly all fields. Reasoning task over these data aims to answer questions or determine the truthiness of hypothesis sentences by understanding the semantic meaning of a table. While previous works have devoted significant efforts to the tabular reasoning task, they always assume there are sufficient labeled data. However, constructing reasoning samples over tables (and related text) is labor-intensive, especially when the reasoning process is complex. When labeled data is insufficient, the performance of models will suffer an unendurable decline. In this paper, we propose a unified framework for unsupervised complex tabular reasoning (UCTR), which generates sufficient and diverse synthetic data with complex logic for tabular reasoning tasks, assuming no human-annotated data at all. We first utilize a random sampling strategy to collect diverse programs of different types and execute them on tables based on a "Program-Executor" module. To bridge the gap between the programs and natural language sentences, we design a powerful "NL-Generator" module to generate natural language sentences with complex logic from these programs. Since a table often occurs with its surrounding texts, we further propose novel "Table-to-Text" and "Text-to-Table" operators to handle joint table-text reasoning scenarios. This way, we can adequately exploit the unlabeled table resources to obtain a well-performed reasoning model under an unsupervised setting. Our experiments cover different tasks (question answering and fact verification) and different domains (general and specific), showing that our unsupervised methods can achieve at most 93% performance compared to supervised models. We also find that it can substantially boost the supervised performance in low-resourced domains as a data augmentation technique. Our code is available at https://github.com/leezythu/UCTR.
BEVDistill: Cross-Modal BEV Distillation for Multi-View 3D Object Detection
Nov 17, 2022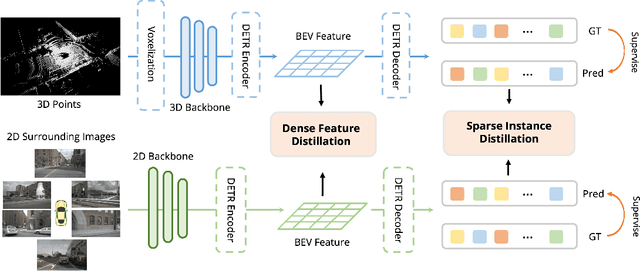
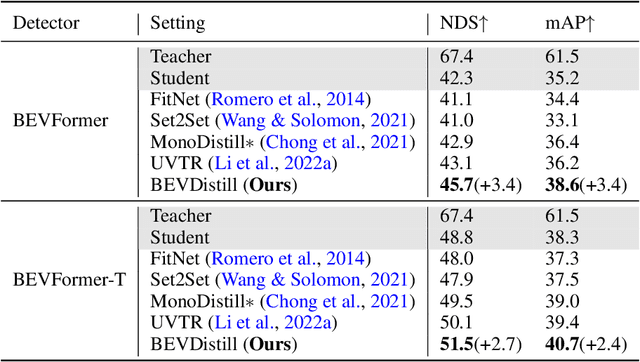
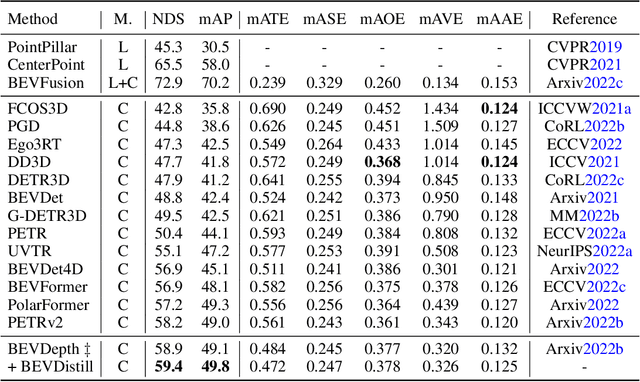

3D object detection from multiple image views is a fundamental and challenging task for visual scene understanding. Owing to its low cost and high efficiency, multi-view 3D object detection has demonstrated promising application prospects. However, accurately detecting objects through perspective views is extremely difficult due to the lack of depth information. Current approaches tend to adopt heavy backbones for image encoders, making them inapplicable for real-world deployment. Different from the images, LiDAR points are superior in providing spatial cues, resulting in highly precise localization. In this paper, we explore the incorporation of LiDAR-based detectors for multi-view 3D object detection. Instead of directly training a depth prediction network, we unify the image and LiDAR features in the Bird-Eye-View (BEV) space and adaptively transfer knowledge across non-homogenous representations in a teacher-student paradigm. To this end, we propose \textbf{BEVDistill}, a cross-modal BEV knowledge distillation (KD) framework for multi-view 3D object detection. Extensive experiments demonstrate that the proposed method outperforms current KD approaches on a highly-competitive baseline, BEVFormer, without introducing any extra cost in the inference phase. Notably, our best model achieves 59.4 NDS on the nuScenes test leaderboard, achieving new state-of-the-art in comparison with various image-based detectors. Code will be available at https://github.com/zehuichen123/BEVDistill.
Not Just Plain Text! Fuel Document-Level Relation Extraction with Explicit Syntax Refinement and Subsentence Modeling
Nov 10, 2022

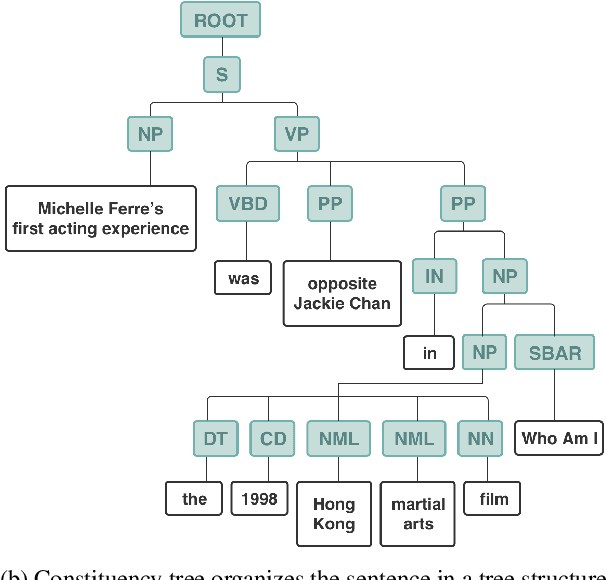
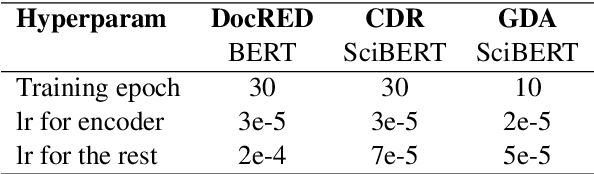
Document-level relation extraction (DocRE) aims to identify semantic labels among entities within a single document. One major challenge of DocRE is to dig decisive details regarding a specific entity pair from long text. However, in many cases, only a fraction of text carries required information, even in the manually labeled supporting evidence. To better capture and exploit instructive information, we propose a novel expLicit syntAx Refinement and Subsentence mOdeliNg based framework (LARSON). By introducing extra syntactic information, LARSON can model subsentences of arbitrary granularity and efficiently screen instructive ones. Moreover, we incorporate refined syntax into text representations which further improves the performance of LARSON. Experimental results on three benchmark datasets (DocRED, CDR, and GDA) demonstrate that LARSON significantly outperforms existing methods.
Efficient Single-Image Depth Estimation on Mobile Devices, Mobile AI & AIM 2022 Challenge: Report
Nov 07, 2022

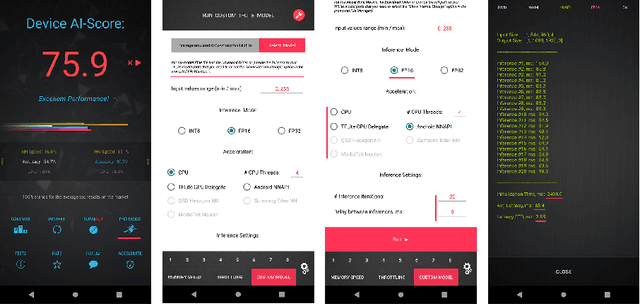
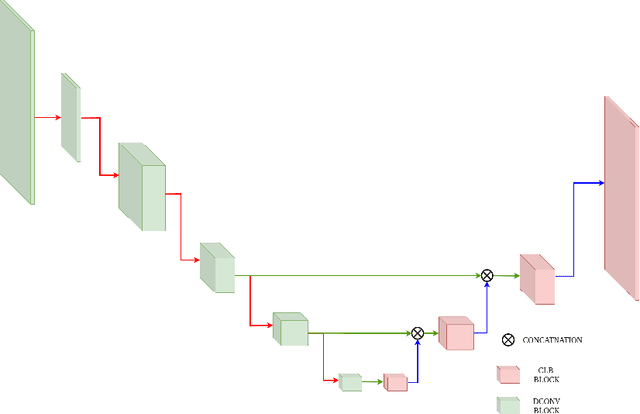
Various depth estimation models are now widely used on many mobile and IoT devices for image segmentation, bokeh effect rendering, object tracking and many other mobile tasks. Thus, it is very crucial to have efficient and accurate depth estimation models that can run fast on low-power mobile chipsets. In this Mobile AI challenge, the target was to develop deep learning-based single image depth estimation solutions that can show a real-time performance on IoT platforms and smartphones. For this, the participants used a large-scale RGB-to-depth dataset that was collected with the ZED stereo camera capable to generated depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the Raspberry Pi 4 platform, where the developed solutions were able to generate VGA resolution depth maps at up to 27 FPS while achieving high fidelity results. All models developed in the challenge are also compatible with any Android or Linux-based mobile devices, their detailed description is provided in this paper.
LiteDepth: Digging into Fast and Accurate Depth Estimation on Mobile Devices
Sep 02, 2022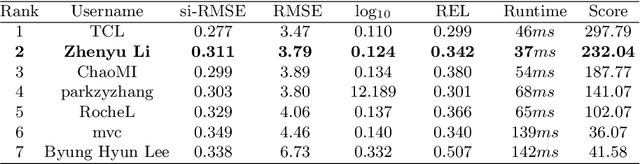
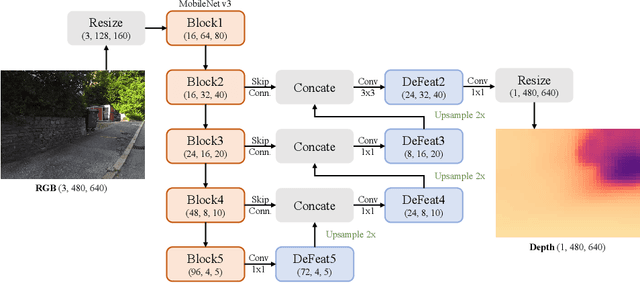


Monocular depth estimation is an essential task in the computer vision community. While tremendous successful methods have obtained excellent results, most of them are computationally expensive and not applicable for real-time on-device inference. In this paper, we aim to address more practical applications of monocular depth estimation, where the solution should consider not only the precision but also the inference time on mobile devices. To this end, we first develop an end-to-end learning-based model with a tiny weight size (1.4MB) and a short inference time (27FPS on Raspberry Pi 4). Then, we propose a simple yet effective data augmentation strategy, called R2 crop, to boost the model performance. Moreover, we observe that the simple lightweight model trained with only one single loss term will suffer from performance bottleneck. To alleviate this issue, we adopt multiple loss terms to provide sufficient constraints during the training stage. Furthermore, with a simple dynamic re-weight strategy, we can avoid the time-consuming hyper-parameter choice of loss terms. Finally, we adopt the structure-aware distillation to further improve the model performance. Notably, our solution named LiteDepth ranks 2nd in the MAI&AIM2022 Monocular Depth Estimation Challenge}, with a si-RMSE of 0.311, an RMSE of 3.79, and the inference time is 37$ms$ tested on the Raspberry Pi 4. Notably, we provide the fastest solution to the challenge. Codes and models will be released at \url{https://github.com/zhyever/LiteDepth}.