 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Simulate on Sparse Trajectory Data
Mar 22, 2021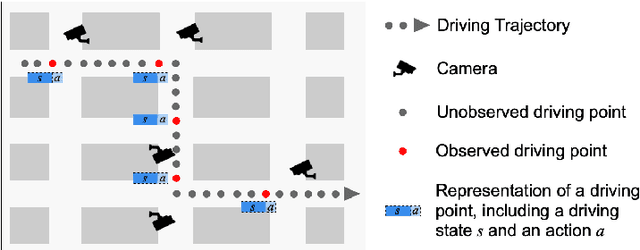

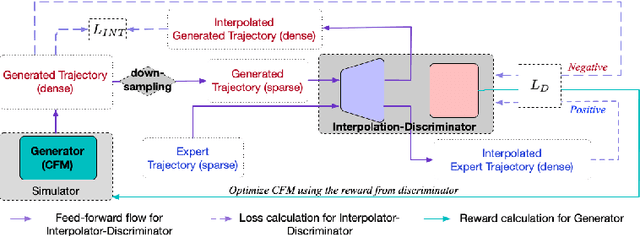
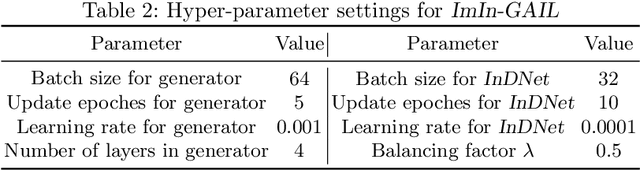
Simulation of the real-world traffic can be used to help validate the transportation policies. A good simulator means the simulated traffic is similar to real-world traffic, which often requires dense traffic trajectories (i.e., with a high sampling rate) to cover dynamic situations in the real world. However, in most cases, the real-world trajectories are sparse, which makes simulation challenging. In this paper, we present a novel framework ImInGAIL to address the problem of learning to simulate the driving behavior from sparse real-world data. The proposed architecture incorporates data interpolation with the behavior learning process of imitation learning. To the best of our knowledge, we are the first to tackle the data sparsity issue for behavior learning problems. We investigate our framework on both synthetic and real-world trajectory datasets of driving vehicles, showing that our method outperforms various baselines and state-of-the-art methods.
Automatic Historical Feature Generation through Tree-based Method in Ads Prediction
Dec 31, 2020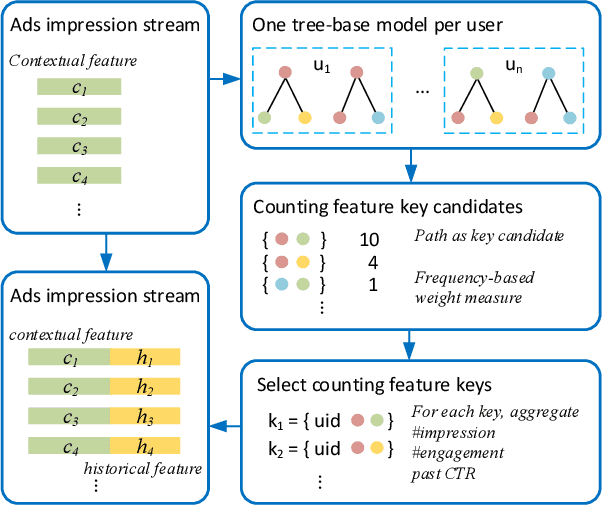

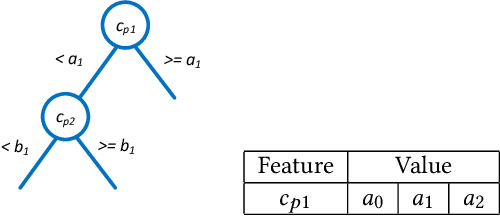
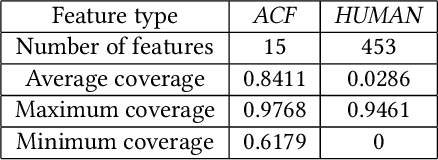
Historical features are important in ads click-through rate (CTR) prediction, because they account for past engagements between users and ads. In this paper, we study how to efficiently construct historical features through counting features. The key challenge of such problem lies in how to automatically identify counting keys. We propose a tree-based method for counting key selection. The intuition is that a decision tree naturally provides various combinations of features, which could be used as counting key candidate. In order to select personalized counting features, we train one decision tree model per user, and the counting keys are selected across different users with a frequency-based importance measure. To validate the effectiveness of proposed solution, we conduct large scale experiments on Twitter video advertising data. In both online learning and offline training settings, the automatically identified counting features outperform the manually curated counting features.
Online Structured Meta-learning
Oct 22, 2020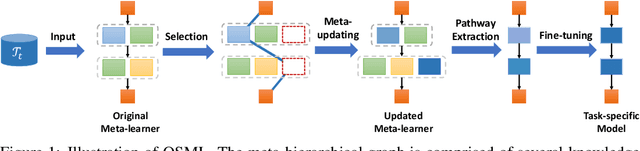
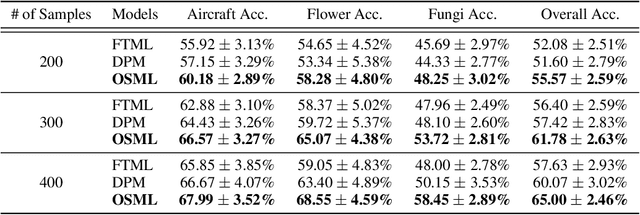
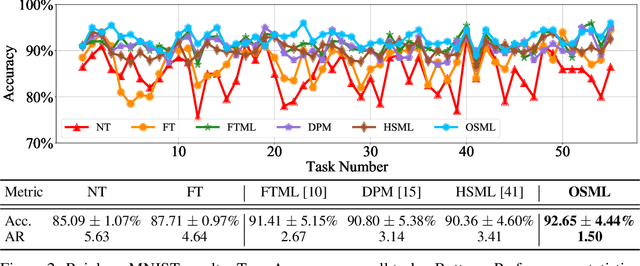
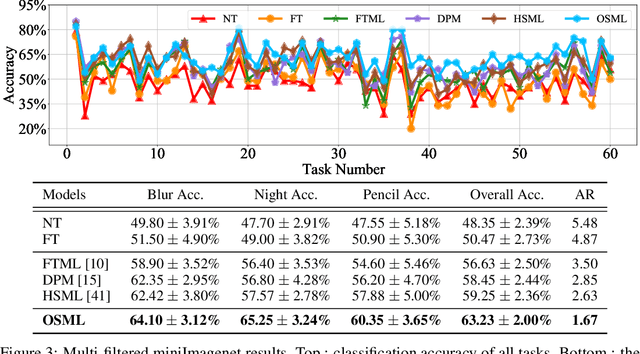
Learning quickly is of great importance for machine intelligence deployed in online platforms. With the capability of transferring knowledge from learned tasks, meta-learning has shown its effectiveness in online scenarios by continuously updating the model with the learned prior. However, current online meta-learning algorithms are limited to learn a globally-shared meta-learner, which may lead to sub-optimal results when the tasks contain heterogeneous information that are distinct by nature and difficult to share. We overcome this limitation by proposing an online structured meta-learning (OSML) framework. Inspired by the knowledge organization of human and hierarchical feature representation, OSML explicitly disentangles the meta-learner as a meta-hierarchical graph with different knowledge blocks. When a new task is encountered, it constructs a meta-knowledge pathway by either utilizing the most relevant knowledge blocks or exploring new blocks. Through the meta-knowledge pathway, the model is able to quickly adapt to the new task. In addition, new knowledge is further incorporated into the selected blocks. Experiments on three datasets demonstrate the effectiveness and interpretability of our proposed framework in the context of both homogeneous and heterogeneous tasks.
Relation-aware Meta-learning for Market Segment Demand Prediction with Limited Records
Aug 01, 2020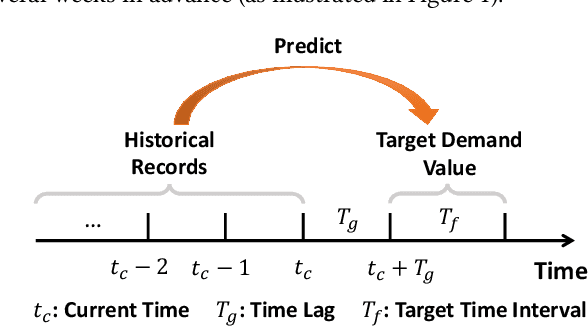
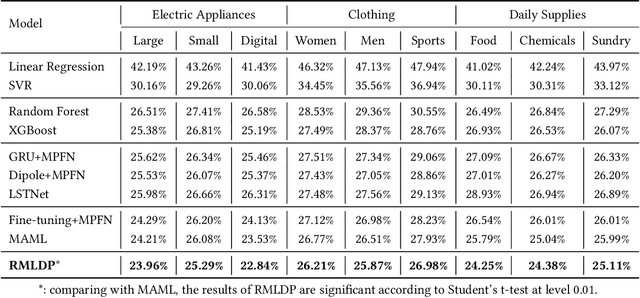
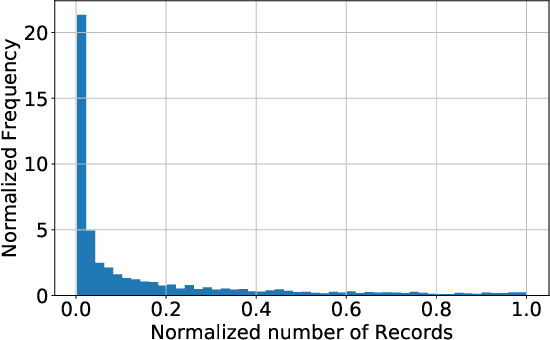
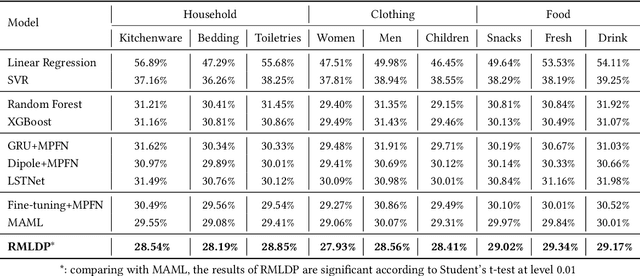
Recently, E-commerce platforms have extensive impacts on our human life. To provide an efficient platform, one of the most fundamental problem is how to balance the demand and supply in market segments. While conventional machine learning models have achieved a great success on data-sufficient segments, it may fail in a large-portion of segments in E-commerce platforms, where there are not sufficient records to learn well-trained models. In this paper, we tackle this problem in the context of market segment demand prediction. The goal is to facilitate the learning process in the target segments even facing a shortage of related training data by leveraging the learned knowledge from data-sufficient source segments. Specifically, we propose a novel algorithm, RMLDP, to incorporate a multi-pattern fusion network (MPFN) with a meta-learning paradigm. The multi-pattern fusion network considers both local and global temporal patterns for segment demand prediction. In the meta-learning paradigm, the transferable knowledge is regarded as the model parameter initializations of MPFN, which are learned from diverse source segments. Furthermore, we capture the segment relations by combining data-driven segment representation and segment knowledge graph representation and tailor the segment-specific relations to customize transferable model parameter initializations. Thus, even with limited data, the target segment can quickly find the most relevant transferred knowledge and adapt to the optimal parameters. Extensive experiments are conducted on two large-scale industrial datasets. The results show that our RMLDP outperforms a set of state-of-the-art baselines. In addition, RMLDP has also been deployed in Taobao, a real-world E-commerce platform. The online A/B testing results further demonstrate the practicality of RMLDP.
Don't Overlook the Support Set: Towards Improving Generalization in Meta-learning
Jul 26, 2020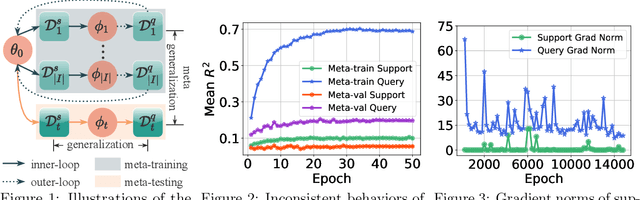
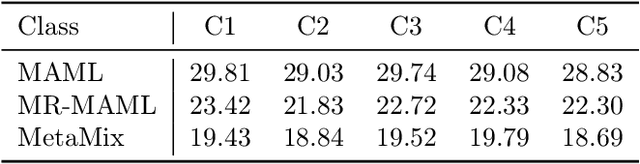
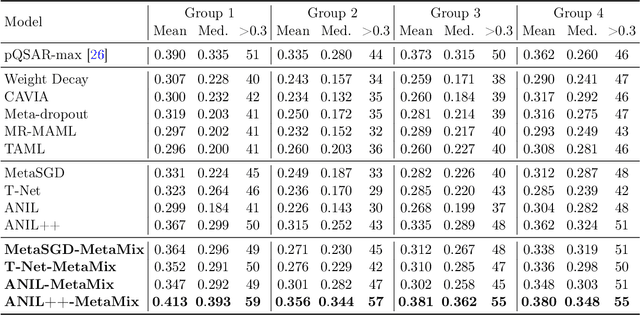
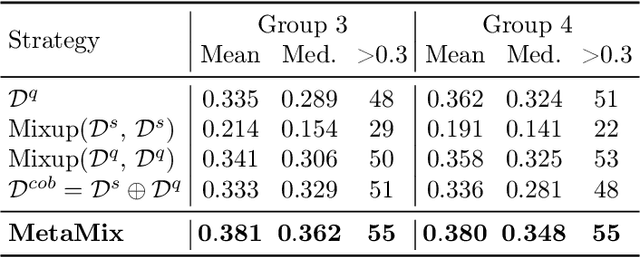
Meta-learning has proven to be a powerful paradigm for transferring the knowledge from previously tasks to facilitate the learning of a novel task. Current dominant algorithms train a well-generalized model initialization which is adapted to each task via the support set. The crux, obviously, lies in optimizing the generalization capability of the initialization, which is measured by the performance of the adapted model on the query set of each task. Unfortunately, this generalization measure, evidenced by empirical results, pushes the initialization to overfit the query but fail the support set, which significantly impairs the generalization and adaptation to novel tasks. To address this issue, we include the support set when evaluating the generalization to produce a new meta-training strategy, MetaMix, that linearly combines the input and hidden representations of samples from both the support and query sets. Theoretical studies on classification and regression tasks show how MetaMix can improve the generalization of meta-learning. More remarkably, MetaMix obtains state-of-the-art results by a large margin across many datasets and remains compatible with existing meta-learning algorithms.
Learning to Simulate Human Movement
Mar 03, 2020
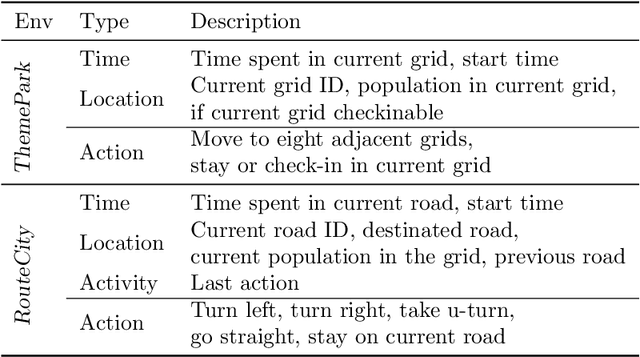
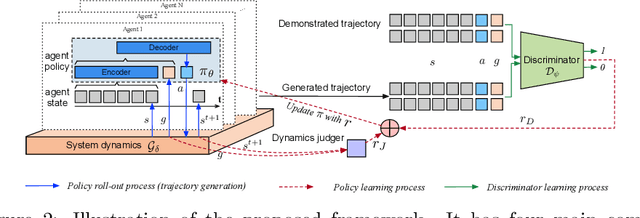
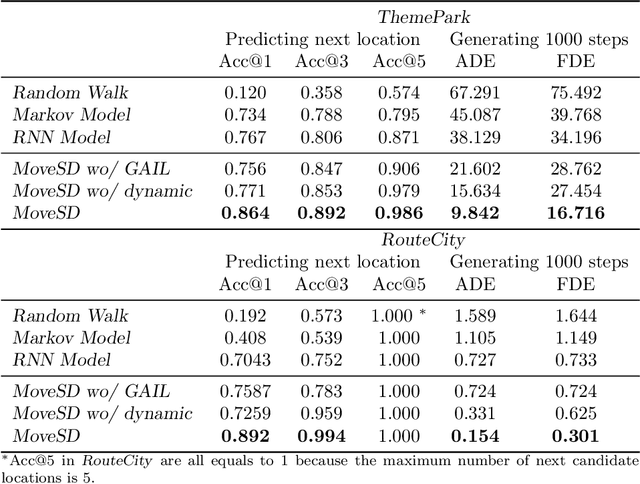
Modeling how human moves on the space is useful for policy-making in transportation, public safety, and public health. The human movements can be viewed as a dynamic process that human transits between states (e.g., locations) over time. In the human world where both intelligent agents like humans or vehicles with human drivers play an important role, the states of agents mostly describe human activities, and the state transition is influenced by both the human decisions and physical constraints from the real-world system (e.g., agents need to spend time to move over a certain distance). Therefore, the modeling of state transition should include the modeling of the agent's decision process and the physical system dynamics. In this paper, we propose to model state transition in human movement through learning decision model and integrating system dynamics. In experiments on real-world datasets, we demonstrate that the proposed method can achieve superior performance against the state-of-the-art methods in predicting the next state and generating long-term future states.
A Probabilistic Simulator of Spatial Demand for Product Allocation
Jan 09, 2020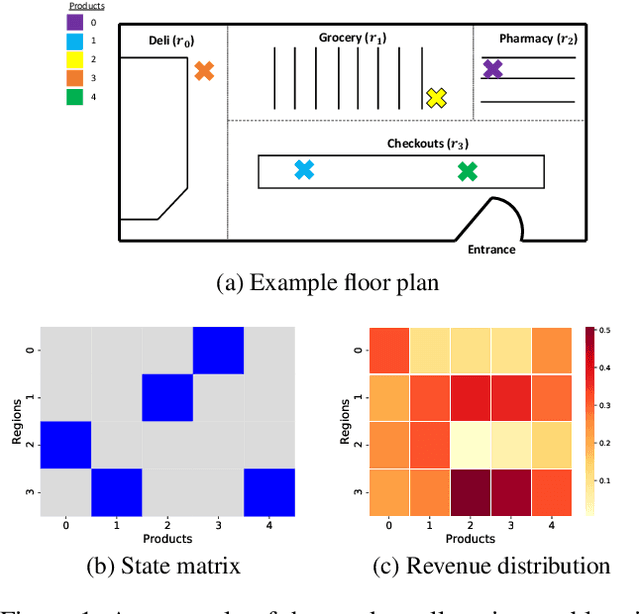
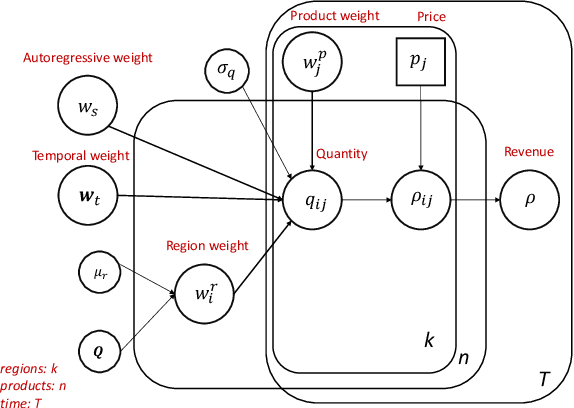
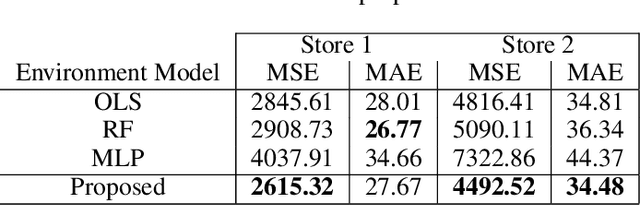
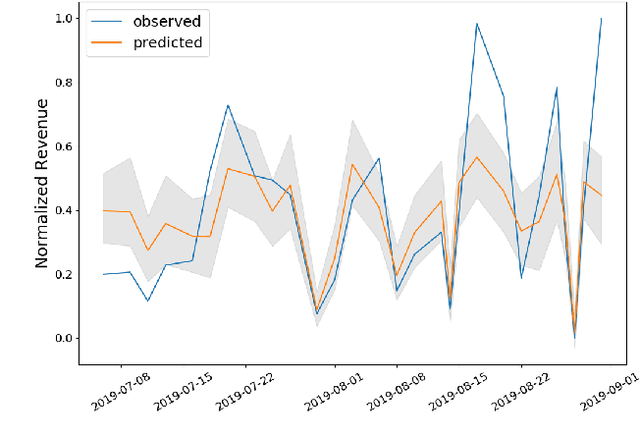
Connecting consumers with relevant products is a very important problem in both online and offline commerce. In physical retail, product placement is an effective way to connect consumers with products. However, selecting product locations within a store can be a tedious process. Moreover, learning important spatial patterns in offline retail is challenging due to the scarcity of data and the high cost of exploration and experimentation in the physical world. To address these challenges, we propose a stochastic model of spatial demand in physical retail. We show that the proposed model is more predictive of demand than existing baselines. We also perform a preliminary study into different automation techniques and show that an optimal product allocation policy can be learned through Deep Q-Learning.
Automated Relational Meta-learning
Jan 03, 2020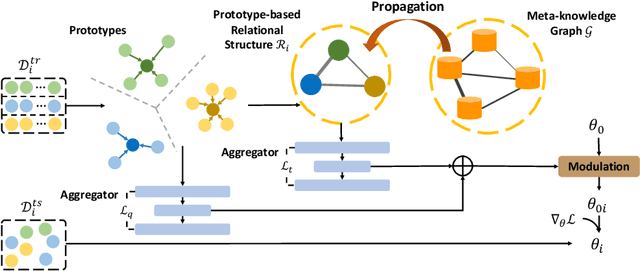
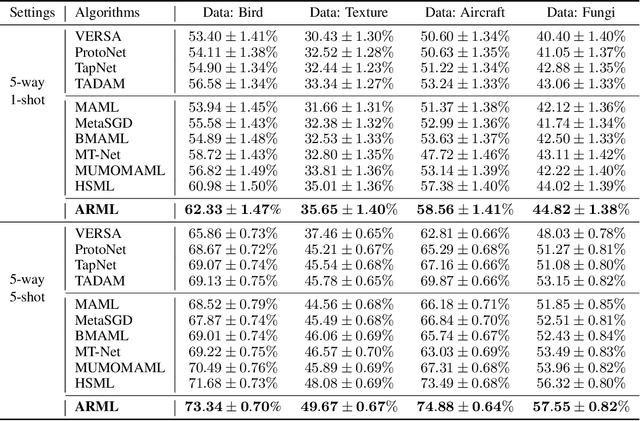
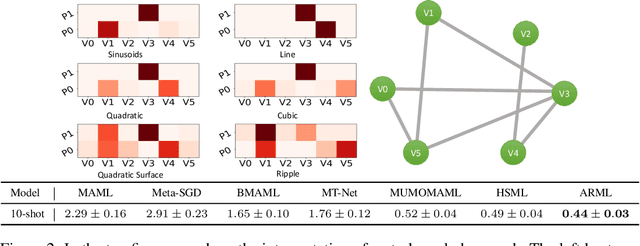
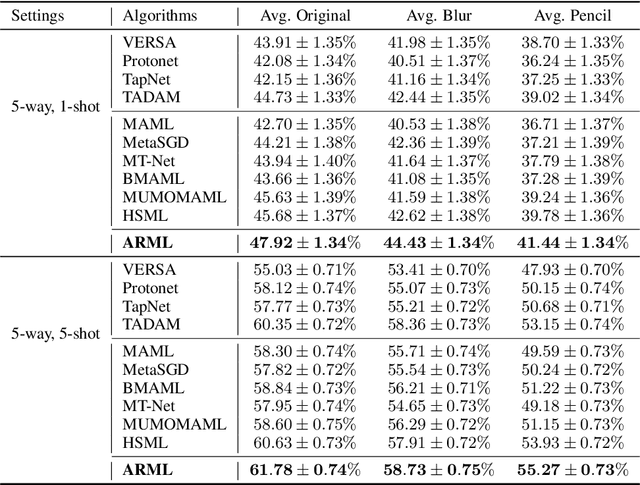
In order to efficiently learn with small amount of data on new tasks, meta-learning transfers knowledge learned from previous tasks to the new ones. However, a critical challenge in meta-learning is the task heterogeneity which cannot be well handled by traditional globally shared meta-learning methods. In addition, current task-specific meta-learning methods may either suffer from hand-crafted structure design or lack the capability to capture complex relations between tasks. In this paper, motivated by the way of knowledge organization in knowledge bases, we propose an automated relational meta-learning (ARML) framework that automatically extracts the cross-task relations and constructs the meta-knowledge graph. When a new task arrives, it can quickly find the most relevant structure and tailor the learned structure knowledge to the meta-learner. As a result, the proposed framework not only addresses the challenge of task heterogeneity by a learned meta-knowledge graph, but also increases the model interpretability. We conduct extensive experiments on 2D toy regression and few-shot image classification and the results demonstrate the superiority of ARML over state-of-the-art baselines.
Few-Shot Knowledge Graph Completion
Nov 26, 2019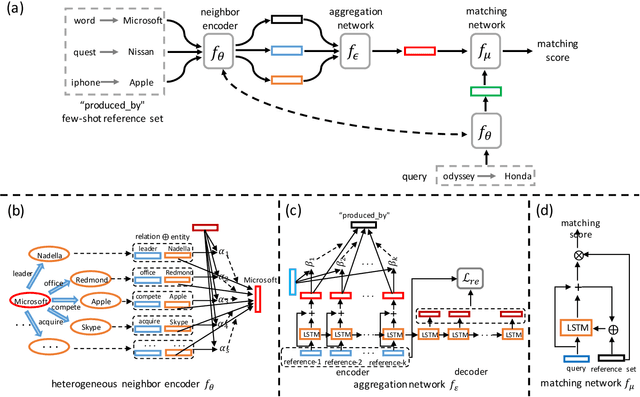

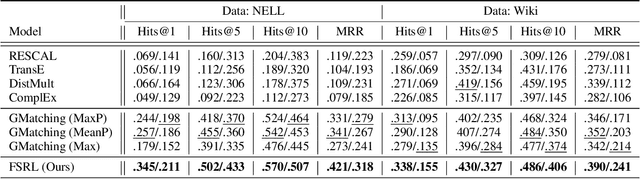
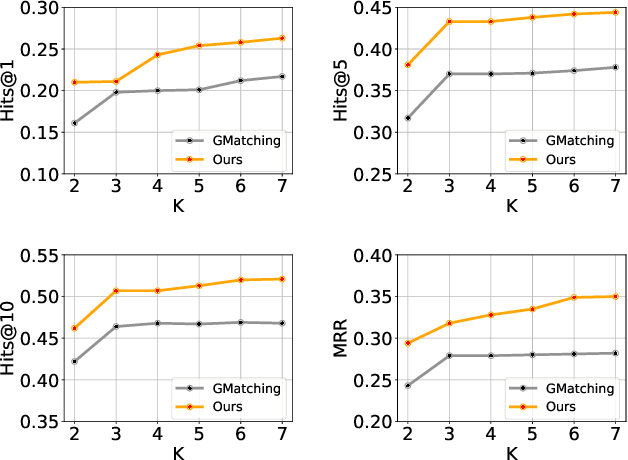
Knowledge graphs (KGs) serve as useful resources for various natural language processing applications. Previous KG completion approaches require a large number of training instances (i.e., head-tail entity pairs) for every relation. The real case is that for most of the relations, very few entity pairs are available. Existing work of one-shot learning limits method generalizability for few-shot scenarios and does not fully use the supervisory information; however, few-shot KG completion has not been well studied yet. In this work, we propose a novel few-shot relation learning model (FSRL) that aims at discovering facts of new relations with few-shot references. FSRL can effectively capture knowledge from heterogeneous graph structure, aggregate representations of few-shot references, and match similar entity pairs of reference set for every relation. Extensive experiments on two public datasets demonstrate that FSRL outperforms the state-of-the-art.
Graph Few-shot Learning via Knowledge Transfer
Oct 07, 2019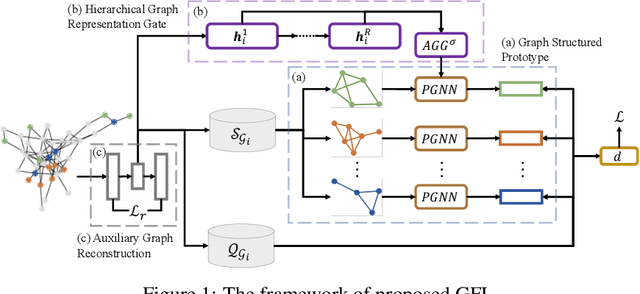
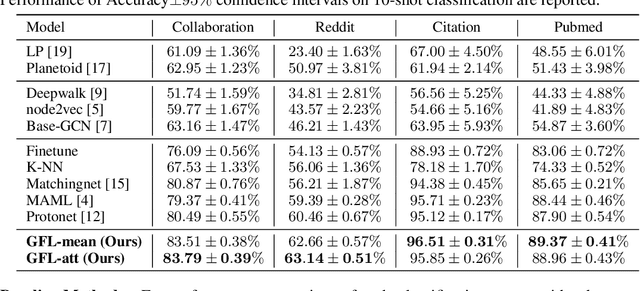
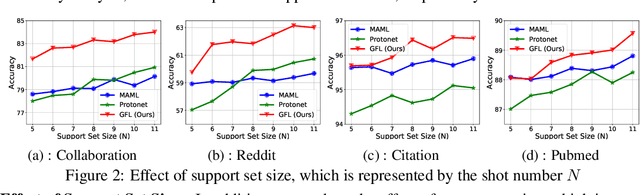
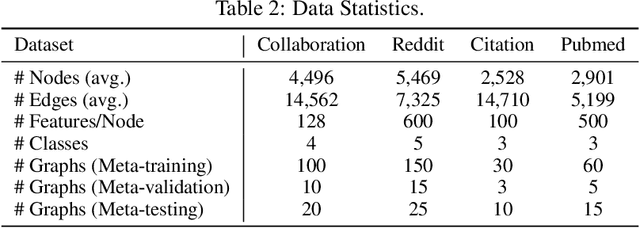
Towards the challenging problem of semi-supervised node classification, there have been extensive studies. As a frontier, Graph Neural Networks (GNNs) have aroused great interest recently, which update the representation of each node by aggregating information of its neighbors. However, most GNNs have shallow layers with a limited receptive field and may not achieve satisfactory performance especially when the number of labeled nodes is quite small. To address this challenge, we innovatively propose a graph few-shot learning (GFL) algorithm that incorporates prior knowledge learned from auxiliary graphs to improve classification accuracy on the target graph. Specifically, a transferable metric space characterized by a node embedding and a graph-specific prototype embedding function is shared between auxiliary graphs and the target, facilitating the transfer of structural knowledge. Extensive experiments and ablation studies on four real-world graph datasets demonstrate the effectiveness of our proposed model.