 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIGER: Traceable Inference with Graph-Based Evidence Routing for Mitigating Hallucinations in Multimodal Generation
May 29, 2026We study fact-level repair for multimodal generation, where a fluent output may contain specific facts that are not supported by the input. Existing inference-time repair methods often generate feedback by jointly conditioning on the input and the current output. This design has two limitations: hallucinated claims in the output can bias the model's interpretation of the input, and free-form feedback cannot be ranked or scheduled at the fact level. We present TIGER, an inference-time framework that redesigns feedback for localized repair. TIGER independently extracts an observation graph from the input and a claim graph from the current output, then assigns each claim a graph-conditioned risk score based on support and conflict. The model repairs selected high-risk claims while keeping the backbone frozen. We provide a convergence analysis showing that the expected total risk decreases geometrically to an explicit asymptotic bound under mild assumptions. Experiments across four cross-modal paths, including image-to-text, image+text-to-text, audio-to-text, and video-to-text, show that TIGER reduces unsupported content while preserving task quality. The gains hold across multiple backbones, and a CrisisFACTS case study suggests that the same repair mechanism can improve grounding in multi-source settings.
LARK: Learnability-Grounded Trajectory Selection for Efficient Reasoning Distillation
May 28, 2026We study trajectory selection for reasoning distillation, where teacher-generated reasoning trajectories are selectively used as supervision for a student model. Existing methods rely on heuristics such as trajectory quality or model confidence, but they often overlook whether a trajectory is learnable by the student. In this paper, we present LARK, a learnability-grounded method for reasoning trajectory selection. LARK selects trajectories that the student can learn efficiently while preserving the generalization of the full training distribution. At the core of LARK is a learnability factor $ρ$, which characterizes the rate at which the student's training loss decreases. To estimate this rate efficiently and maintain generalization, we introduce a learnability proxy and a $χ^2$-regularized selection policy that balances learnability and distributional coverage, both with strong theoretical guarantees on their estimation error. Empirically, LARK consistently outperforms data selection baselines across multiple base models and reasoning tasks. Diagnostic analyses show that the LARK score predicts downstream training utility and that LARK-selected trajectories induce faster supervised fine-tuning loss reduction. Our code is available at https://github.com/Tianrun-Yu/LARK.
FRAME: Forensic Routing and Adaptive Multi-path Evidence Fusion for Image Manipulation Detection
May 12, 2026The proliferation of sophisticated image editing tools and generative artificial intelligence models has made verifying the authenticity of digital images increasingly challenging, with important implications for journalism, forensic analysis, and public trust. Although numerous forensic algorithms, ranging from handcrafted methods to deep learning-based detectors, have been developed for manipulation detection, individual methods often suffer from limited robustness, fragmented evidence, or weak generalization across manipulation types and image conditions. To address these limitations, we present \textbf{FRAME}, a method for \textbf{F}orensic \textbf{R}outing and \textbf{A}daptive \textbf{M}ulti-path \textbf{E}vidence fusion for image manipulation detection. FRAME organizes diverse forensic algorithms into a multi-path analysis space, adaptively selects informative forensic paths for each input image, and fuses complementary evidence to improve detection and localization performance. By moving beyond single-method analysis and fixed fusion strategies, FRAME provides a more robust and flexible approach to image forensic reasoning while preserving interpretable forensic cues from multiple evidence sources. Experimental results demonstrate the effectiveness of FRAME across diverse manipulation scenarios. Code is available at \href{https://github.com/kzhao5/FRAME}{https://github.com/kzhao5/FRAME}.
Provable and Practical In-Context Policy Optimization for Self-Improvement
Mar 02, 2026We study test-time scaling, where a model improves its answer through multi-round self-reflection at inference. We introduce In-Context Policy Optimization (ICPO), in which an agent optimizes its response in context using self-assessed or externally observed rewards without modifying its parameters. To explain this ICPO process, we theoretically show that with sufficient pretraining under a novel Fisher-weighted logit-matching objective, a single-layer linear self-attention model can provably imitate policy-optimization algorithm for linear bandits. Building on this theory, we propose Minimum-Entropy ICPO (ME-ICPO), a practical algorithm that iteratively uses its response and self-assessed reward to refine its response in-context at inference time. By selecting the responses and their rewards with minimum entropy, ME-ICPO ensures the robustness of the self-assessed rewards via majority voting. Across standard mathematical reasoning tasks, ME-ICPO attains competitive, top-tier performance while keeping inference costs affordable compared with other inference-time algorithms. Overall, ICPO provides a principled understanding of self-reflection in LLMs and yields practical benefits for test-time scaling for mathematical reasoning.
Flexible Heteroscedastic Count Regression with Deep Double Poisson Networks
Jun 13, 2024



Neural networks that can produce accurate, input-conditional uncertainty representations are critical for real-world applications. Recent progress on heteroscedastic continuous regression has shown great promise for calibrated uncertainty quantification on complex tasks, like image regression. However, when these methods are applied to discrete regression tasks, such as crowd counting, ratings prediction, or inventory estimation, they tend to produce predictive distributions with numerous pathologies. We propose to address these issues by training a neural network to output the parameters of a Double Poisson distribution, which we call the Deep Double Poisson Network (DDPN). In contrast to existing methods that are trained to minimize Gaussian negative log likelihood (NLL), DDPNs produce a proper probability mass function over discrete output. Additionally, DDPNs naturally model under-, over-, and equi-dispersion, unlike networks trained with the more rigid Poisson and Negative Binomial parameterizations. We show DDPNs 1) vastly outperform existing discrete models; 2) meet or exceed the accuracy and flexibility of networks trained with Gaussian NLL; 3) produce proper predictive distributions over discrete counts; and 4) exhibit superior out-of-distribution detection. DDPNs can easily be applied to a variety of count regression datasets including tabular, image, point cloud, and text data.
Personalized Product Assortment with Real-time 3D Perception and Bayesian Payoff Estimation
Jun 11, 2024



Product assortment selection is a critical challenge facing physical retailers. Effectively aligning inventory with the preferences of shoppers can increase sales and decrease out-of-stocks. However, in real-world settings the problem is challenging due to the combinatorial explosion of product assortment possibilities. Consumer preferences are typically heterogeneous across space and time, making inventory-preference alignment challenging. Additionally, existing strategies rely on syndicated data, which tends to be aggregated, low resolution, and suffer from high latency. To solve these challenges we introduce a real-time recommendation system, which we call \ours. Our system utilizes recent advances in 3D computer vision for perception and automatic, fine grained sales estimation. These perceptual components run on the edge of the network and facilitate real-time reward signals. Additionally, we develop a Bayesian payoff model to account for noisy estimates from 3D LIDAR data. We rely on spatial clustering to allow the system to adapt to heterogeneous consumer preferences, and a graph-based candidate generation algorithm to address the combinatorial search problem. We test our system in real-world stores across two, 6-8 week A/B tests with beverage products and demonstrate a 35% and 27\% increase in sales respectively. Finally, we monitor the deployed system for a period of 28 weeks with an observational study and show a 9.4\% increase in sales.
On Measuring Calibration of Discrete Probabilistic Neural Networks
May 20, 2024



As machine learning systems become increasingly integrated into real-world applications, accurately representing uncertainty is crucial for enhancing their safety, robustness, and reliability. Training neural networks to fit high-dimensional probability distributions via maximum likelihood has become an effective method for uncertainty quantification. However, such models often exhibit poor calibration, leading to overconfident predictions. Traditional metrics like Expected Calibration Error (ECE) and Negative Log Likelihood (NLL) have limitations, including biases and parametric assumptions. This paper proposes a new approach using conditional kernel mean embeddings to measure calibration discrepancies without these biases and assumptions. Preliminary experiments on synthetic data demonstrate the method's potential, with future work planned for more complex applications.
Probabilistic Offline Policy Ranking with Approximate Bayesian Computation
Dec 17, 2023



In practice, it is essential to compare and rank candidate policies offline before real-world deployment for safety and reliability. Prior work seeks to solve this offline policy ranking (OPR) problem through value-based methods, such as Off-policy evaluation (OPE). However, they fail to analyze special cases performance (e.g., worst or best cases), due to the lack of holistic characterization of policies performance. It is even more difficult to estimate precise policy values when the reward is not fully accessible under sparse settings. In this paper, we present Probabilistic Offline Policy Ranking (POPR), a framework to address OPR problems by leveraging expert data to characterize the probability of a candidate policy behaving like experts, and approximating its entire performance posterior distribution to help with ranking. POPR does not rely on value estimation, and the derived performance posterior can be used to distinguish candidates in worst, best, and average-cases. To estimate the posterior, we propose POPR-EABC, an Energy-based Approximate Bayesian Computation (ABC) method conducting likelihood-free inference. POPR-EABC reduces the heuristic nature of ABC by a smooth energy function, and improves the sampling efficiency by a pseudo-likelihood. We empirically demonstrate that POPR-EABC is adequate for evaluating policies in both discrete and continuous action spaces across various experiment environments, and facilitates probabilistic comparisons of candidate policies before deployment.
A Probabilistic Simulator of Spatial Demand for Product Allocation
Jan 09, 2020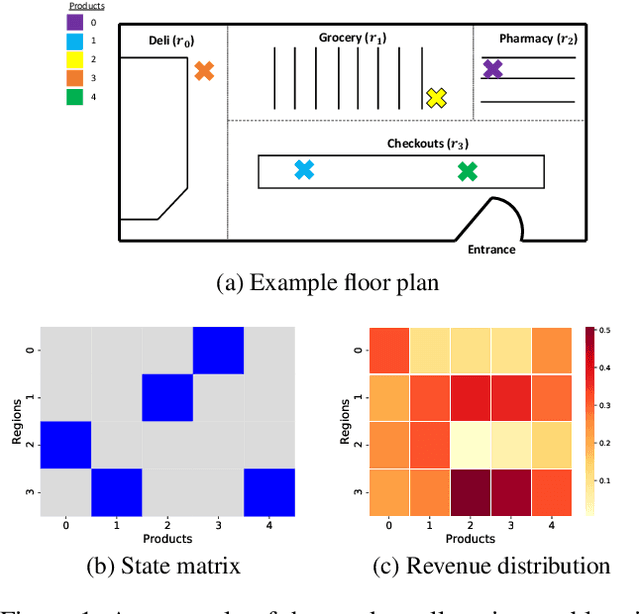
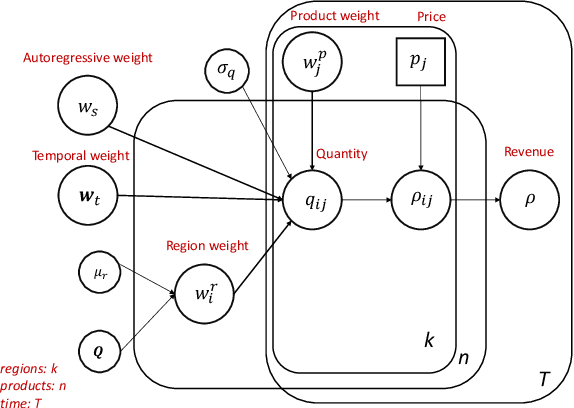
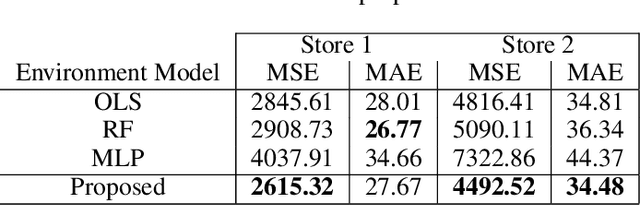
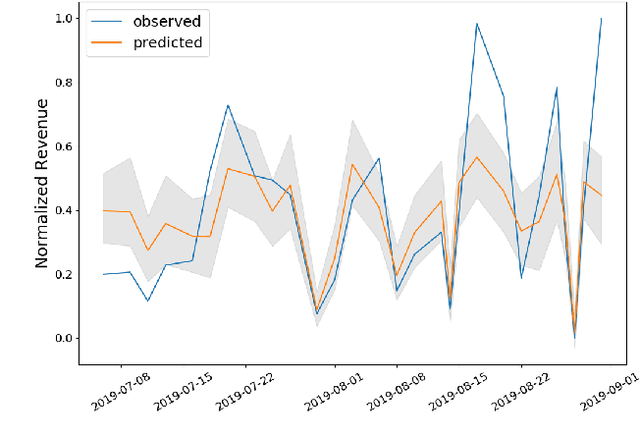
Connecting consumers with relevant products is a very important problem in both online and offline commerce. In physical retail, product placement is an effective way to connect consumers with products. However, selecting product locations within a store can be a tedious process. Moreover, learning important spatial patterns in offline retail is challenging due to the scarcity of data and the high cost of exploration and experimentation in the physical world. To address these challenges, we propose a stochastic model of spatial demand in physical retail. We show that the proposed model is more predictive of demand than existing baselines. We also perform a preliminary study into different automation techniques and show that an optimal product allocation policy can be learned through Deep Q-Learning.