 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Incomplete is Contrastive Learning? An Inter-intra Variant Dual Representation Method for Self-supervised Video Recognition
Jul 05, 2021
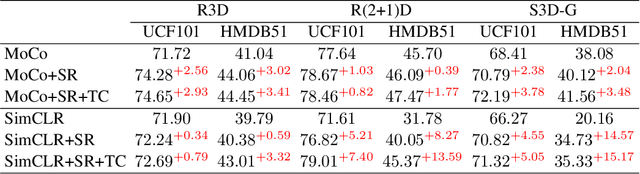
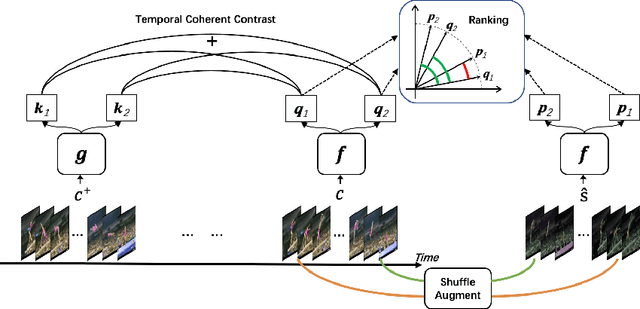
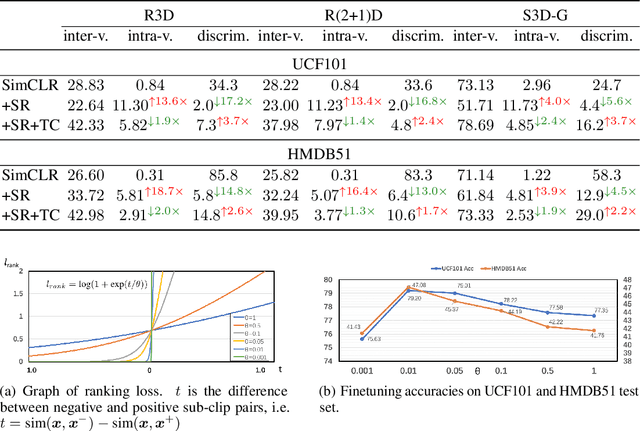
Contrastive learning applied to self-supervised representation learning has seen a resurgence in deep models. In this paper, we find that existing contrastive learning based solutions for self-supervised video recognition focus on inter-variance encoding but ignore the intra-variance existing in clips within the same video. We thus propose to learn dual representations for each clip which (\romannumeral 1) encode intra-variance through a shuffle-rank pretext task; (\romannumeral 2) encode inter-variance through a temporal coherent contrastive loss. Experiment results show that our method plays an essential role in balancing inter and intra variances and brings consistent performance gains on multiple backbones and contrastive learning frameworks. Integrated with SimCLR and pretrained on Kinetics-400, our method achieves $\textbf{82.0\%}$ and $\textbf{51.2\%}$ downstream classification accuracy on UCF101 and HMDB51 test sets respectively and $\textbf{46.1\%}$ video retrieval accuracy on UCF101, outperforming both pretext-task based and contrastive learning based counterparts.
PDO-e$\text{S}^\text{2}$CNNs: Partial Differential Operator Based Equivariant Spherical CNNs
Apr 08, 2021
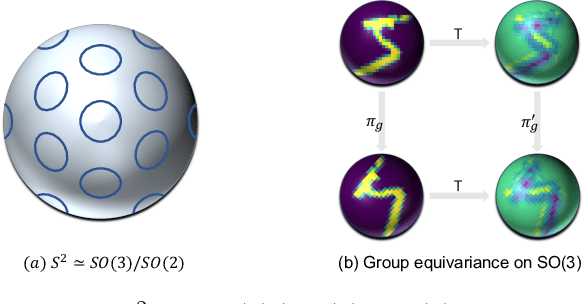
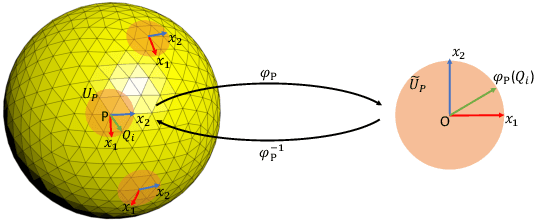
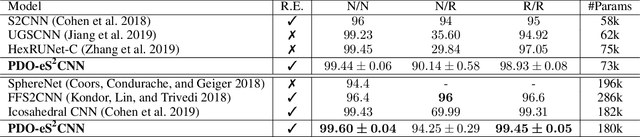
Spherical signals exist in many applications, e.g., planetary data, LiDAR scans and digitalization of 3D objects, calling for models that can process spherical data effectively. It does not perform well when simply projecting spherical data into the 2D plane and then using planar convolution neural networks (CNNs), because of the distortion from projection and ineffective translation equivariance. Actually, good principles of designing spherical CNNs are avoiding distortions and converting the shift equivariance property in planar CNNs to rotation equivariance in the spherical domain. In this work, we use partial differential operators (PDOs) to design a spherical equivariant CNN, PDO-e$\text{S}^\text{2}$CNN, which is exactly rotation equivariant in the continuous domain. We then discretize PDO-e$\text{S}^\text{2}$CNNs, and analyze the equivariance error resulted from discretization. This is the first time that the equivariance error is theoretically analyzed in the spherical domain. In experiments, PDO-e$\text{S}^\text{2}$CNNs show greater parameter efficiency and outperform other spherical CNNs significantly on several tasks.
A Deep Network for Joint Registration and Reconstruction of Images with Pathologies
Aug 17, 2020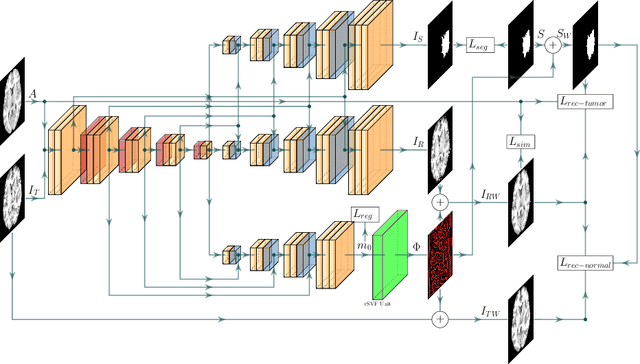
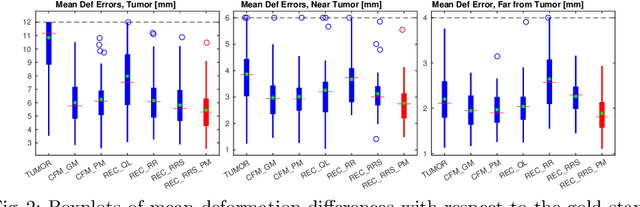
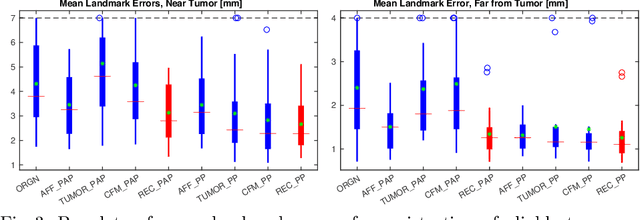
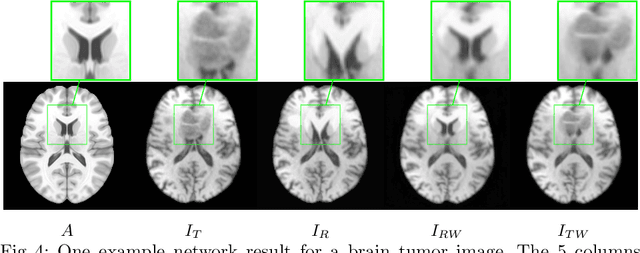
Registration of images with pathologies is challenging due to tissue appearance changes and missing correspondences caused by the pathologies. Moreover, mass effects as observed for brain tumors may displace tissue, creating larger deformations over time than what is observed in a healthy brain. Deep learning models have successfully been applied to image registration to offer dramatic speed up and to use surrogate information (e.g., segmentations) during training. However, existing approaches focus on learning registration models using images from healthy patients. They are therefore not designed for the registration of images with strong pathologies for example in the context of brain tumors, and traumatic brain injuries. In this work, we explore a deep learning approach to register images with brain tumors to an atlas. Our model learns an appearance mapping from images with tumors to the atlas, while simultaneously predicting the transformation to atlas space. Using separate decoders, the network disentangles the tumor mass effect from the reconstruction of quasi-normal images. Results on both synthetic and real brain tumor scans show that our approach outperforms cost function masking for registration to the atlas and that reconstructed quasi-normal images can be used for better longitudinal registrations.
PDO-eConvs: Partial Differential Operator Based Equivariant Convolutions
Aug 11, 2020
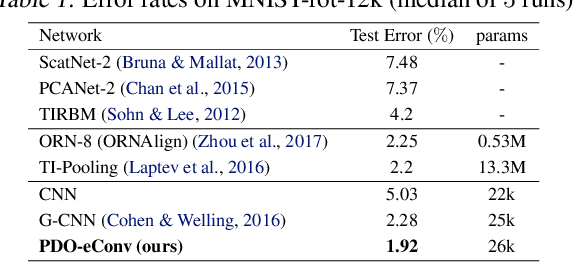

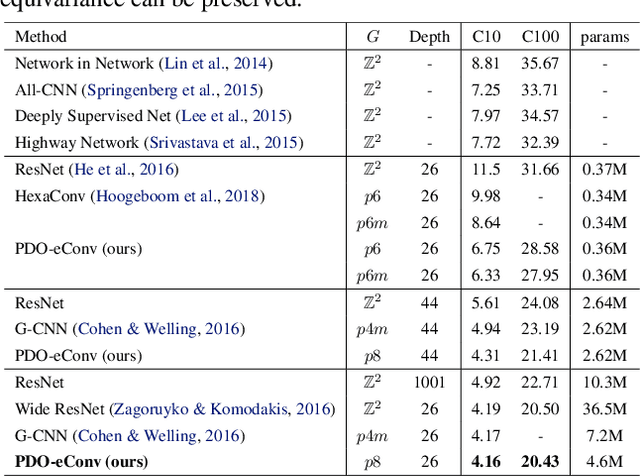
Recent research has shown that incorporating equivariance into neural network architectures is very helpful, and there have been some works investigating the equivariance of networks under group actions. However, as digital images and feature maps are on the discrete meshgrid, corresponding equivariance-preserving transformation groups are very limited. In this work, we deal with this issue from the connection between convolutions and partial differential operators (PDOs). In theory, assuming inputs to be smooth, we transform PDOs and propose a system which is equivariant to a much more general continuous group, the $n$-dimension Euclidean group. In implementation, we discretize the system using the numerical schemes of PDOs, deriving approximately equivariant convolutions (PDO-eConvs). Theoretically, the approximation error of PDO-eConvs is of the quadratic order. It is the first time that the error analysis is provided when the equivariance is approximate. Extensive experiments on rotated MNIST and natural image classification show that PDO-eConvs perform competitively yet use parameters much more efficiently. Particularly, compared with Wide ResNets, our methods result in better results using only 12.6% parameters.
Anatomical Data Augmentation via Fluid-based Image Registration
Jul 05, 2020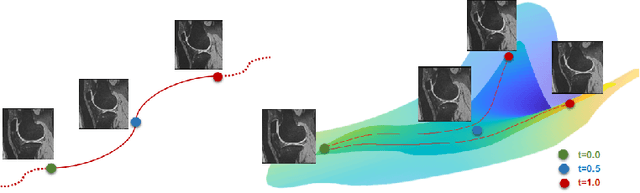
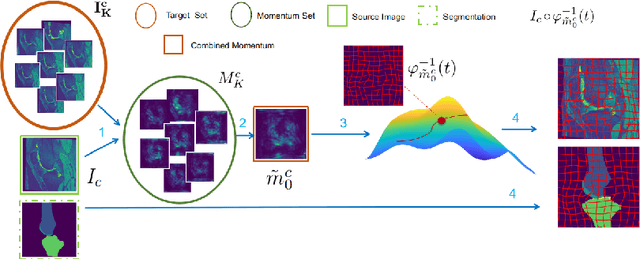
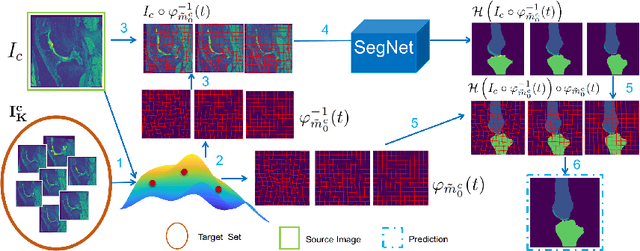
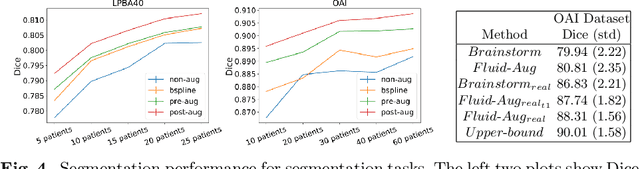
We introduce a fluid-based image augmentation method for medical image analysis. In contrast to existing methods, our framework generates anatomically meaningful images via interpolation from the geodesic subspace underlying given samples. Our approach consists of three steps: 1) given a source image and a set of target images, we construct a geodesic subspace using the Large Deformation Diffeomorphic Metric Mapping (LDDMM) model; 2) we sample transformations from the resulting geodesic subspace; 3) we obtain deformed images and segmentations via interpolation. Experiments on brain (LPBA) and knee (OAI) data illustrate the performance of our approach on two tasks: 1) data augmentation during training and testing for image segmentation; 2) one-shot learning for single atlas image segmentation. We demonstrate that our approach generates anatomically meaningful data and improves performance on these tasks over competing approaches. Code is available at https://github.com/uncbiag/easyreg.
Region-specific Diffeomorphic Metric Mapping
Jun 01, 2019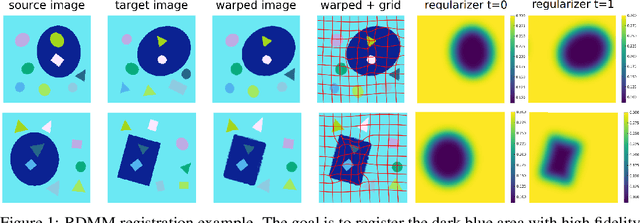
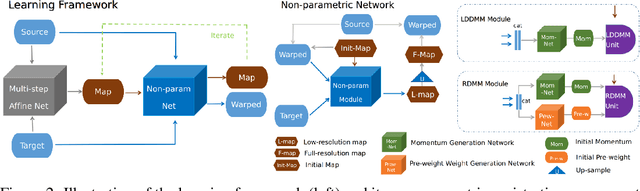

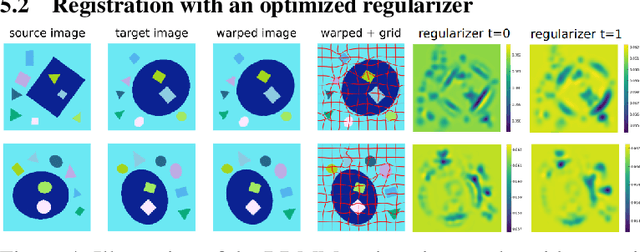
We introduce a region-specific diffeomorphic metric mapping (RDMM) registration approach. RDMM is non-parametric, estimating spatio-temporal velocity fields which parameterize the sought-for spatial transformation. Regularization of these velocity fields is necessary. However, while existing non-parametric registration approaches, e.g., the large displacement diffeomorphic metric mapping (LDDMM) model, use a fixed spatially-invariant regularization our model advects a spatially-varying regularizer with the estimated velocity field, thereby naturally attaching a spatio-temporal regularizer to deforming objects. We explore a family of RDMM registration approaches: 1) a registration model where regions with separate regularizations are pre-defined (e.g., in an atlas space), 2) a registration model where a general spatially-varying regularizer is estimated, and 3) a registration model where the spatially-varying regularizer is obtained via an end-to-end trained deep learning (DL) model. We provide a variational derivation of RDMM, show that the model can assure diffeomorphic transformations in the continuum, and that LDDMM is a particular instance of RDMM. To evaluate RDMM performance we experiment 1) on synthetic 2D data and 2) on two 3D datasets: knee magnetic resonance images (MRIs) of the Osteoarthritis Initiative (OAI) and computed tomography images (CT) of the lung. Results show that our framework achieves state-of-the-art image registration performance, while providing additional information via a learned spatio-temoporal regularizer. Further, our deep learning approach allows for very fast RDMM and LDDMM estimations. Our code will be open-sourced. Code is available at https://github.com/uncbiag/registration.
Networks for Joint Affine and Non-parametric Image Registration
Mar 21, 2019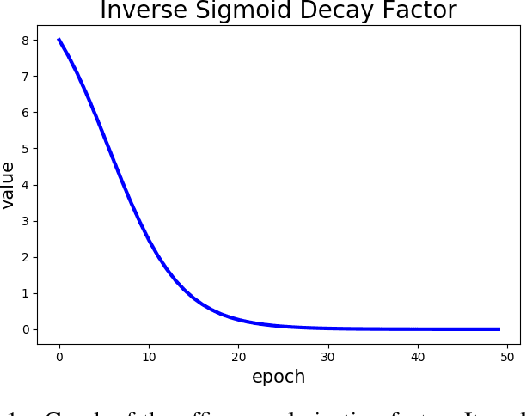
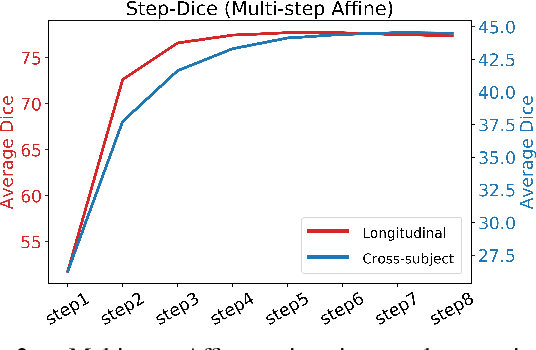
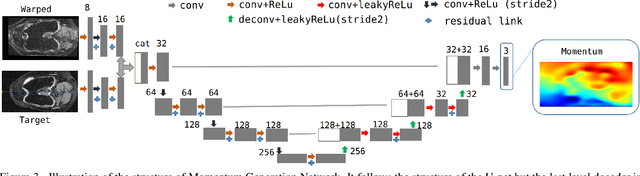

We introduce an end-to-end deep-learning framework for 3D medical image registration. In contrast to existing approaches, our framework combines two registration methods: an affine registration and a vector momentum-parameterized stationary velocity field (vSVF) model. Specifically, it consists of three stages. In the first stage, a multi-step affine network predicts affine transform parameters. In the second stage, we use a Unet-like network to generate a momentum, from which a velocity field can be computed via smoothing. Finally, in the third stage, we employ a self-iterable map-based vSVF component to provide a non-parametric refinement based on the current estimate of the transformation map. Once the model is trained, a registration is completed in one forward pass. To evaluate the performance, we conducted longitudinal and cross-subject experiments on 3D magnetic resonance images (MRI) of the knee of the Osteoarthritis Initiative (OAI) dataset. Results show that our framework achieves comparable performance to state-of-the-art medical image registration approaches, but it is much faster, with a better control of transformation regularity including the ability to produce approximately symmetric transformations, and combining affine and non-parametric registration.
Learning Multi-level Features For Sensor-based Human Action Recognition
Sep 02, 2017
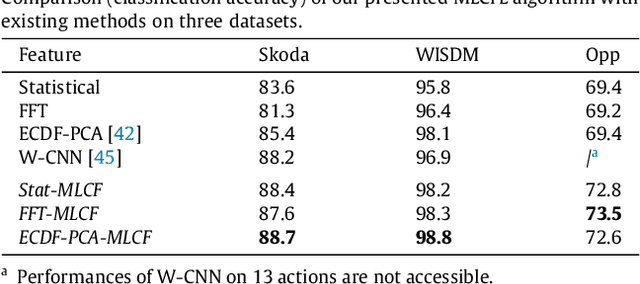
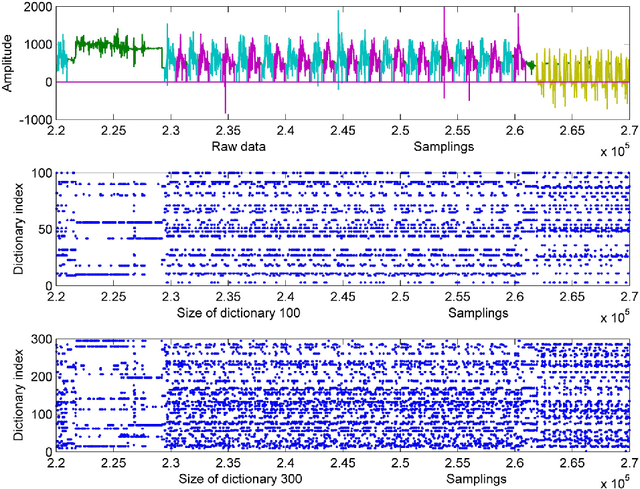
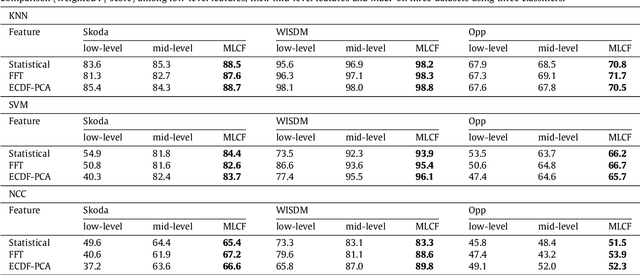
This paper proposes a multi-level feature learning framework for human action recognition using a single body-worn inertial sensor. The framework consists of three phases, respectively designed to analyze signal-based (low-level), components (mid-level) and semantic (high-level) information. Low-level features capture the time and frequency domain property while mid-level representations learn the composition of the action. The Max-margin Latent Pattern Learning (MLPL) method is proposed to learn high-level semantic descriptions of latent action patterns as the output of our framework. The proposed method achieves the state-of-the-art performances, 88.7%, 98.8% and 72.6% (weighted F1 score) respectively, on Skoda, WISDM and OPP datasets.
* 26 pages, 23 figures
End-to-End Subtitle Detection and Recognition for Videos in East Asian Languages via CNN Ensemble with Near-Human-Level Performance
Nov 18, 2016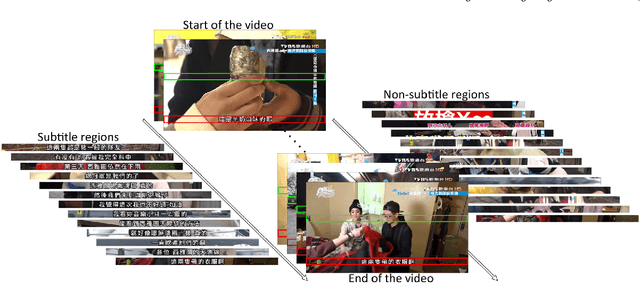
In this paper, we propose an innovative end-to-end subtitle detection and recognition system for videos in East Asian languages. Our end-to-end system consists of multiple stages. Subtitles are firstly detected by a novel image operator based on the sequence information of consecutive video frames. Then, an ensemble of Convolutional Neural Networks (CNNs) trained on synthetic data is adopted for detecting and recognizing East Asian characters. Finally, a dynamic programming approach leveraging language models is applied to constitute results of the entire body of text lines. The proposed system achieves average end-to-end accuracies of 98.2% and 98.3% on 40 videos in Simplified Chinese and 40 videos in Traditional Chinese respectively, which is a significant outperformance of other existing methods. The near-perfect accuracy of our system dramatically narrows the gap between human cognitive ability and state-of-the-art algorithms used for such a task.