 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSliced ReLU attention: Quasi-linear contextual expressivity via sorting
Dec 12, 2025



We introduce sliced ReLU attention, a new attention mechanism that departs structurally from both softmax and ReLU-based alternatives. Instead of applying a nonlinearity to pairwise dot products, we operate on one-dimensional projections of key--query differences and leverage sorting to obtain quasi-linear complexity. This construction yields a differentiable, non-symmetric kernel that can be computed in O(n log(n)) through a sorting procedure, making it suitable for very long contexts. Beyond computational benefits, the model retains strong theoretical expressive power: we establish two in-context expressivity results, previously known for softmax attention, showing that sliced ReLU attention preserves the ability to perform nontrivial sequence-to-sequence disentangling tasks and satisfies a contextual universal approximation property. Finally, we illustrate the potential practical interest of this kernel in small-scale experiments.
Token Sample Complexity of Attention
Dec 11, 2025As context windows in large language models continue to expand, it is essential to characterize how attention behaves at extreme sequence lengths. We introduce token-sample complexity: the rate at which attention computed on $n$ tokens converges to its infinite-token limit. We estimate finite-$n$ convergence bounds at two levels: pointwise uniform convergence of the attention map, and convergence of moments for the transformed token distribution. For compactly supported (and more generally sub-Gaussian) distributions, our first result shows that the attention map converges uniformly on a ball of radius $R$ at rate $C(R)/\sqrt{n}$, where $C(R)$ grows exponentially with $R$. For large $R$, this estimate loses practical value, and our second result addresses this issue by establishing convergence rates for the moments of the transformed distribution (the token output of the attention layer). In this case, the rate is $C'(R)/n^β$ with $β<\tfrac{1}{2}$, and $C'(R)$ depends polynomially on the size of the support of the distribution. The exponent $β$ depends on the attention geometry and the spectral properties of the tokens distribution. We also examine the regime in which the attention parameter tends to infinity and the softmax approaches a hardmax, and in this setting, we establish a logarithmic rate of convergence. Experiments on synthetic Gaussian data and real BERT models on Wikipedia text confirm our predictions.
Decreasing Entropic Regularization Averaged Gradient for Semi-Discrete Optimal Transport
Oct 31, 2025Adding entropic regularization to Optimal Transport (OT) problems has become a standard approach for designing efficient and scalable solvers. However, regularization introduces a bias from the true solution. To mitigate this bias while still benefiting from the acceleration provided by regularization, a natural solver would adaptively decrease the regularization as it approaches the solution. Although some algorithms heuristically implement this idea, their theoretical guarantees and the extent of their acceleration compared to using a fixed regularization remain largely open. In the setting of semi-discrete OT, where the source measure is continuous and the target is discrete, we prove that decreasing the regularization can indeed accelerate convergence. To this end, we introduce DRAG: Decreasing (entropic) Regularization Averaged Gradient, a stochastic gradient descent algorithm where the regularization decreases with the number of optimization steps. We provide a theoretical analysis showing that DRAG benefits from decreasing regularization compared to a fixed scheme, achieving an unbiased $\mathcal{O}(1/t)$ sample and iteration complexity for both the OT cost and the potential estimation, and a $\mathcal{O}(1/\sqrt{t})$ rate for the OT map. Our theoretical findings are supported by numerical experiments that validate the effectiveness of DRAG and highlight its practical advantages.
Ultra-fast feature learning for the training of two-layer neural networks in the two-timescale regime
Apr 25, 2025We study the convergence of gradient methods for the training of mean-field single hidden layer neural networks with square loss. Observing this is a separable non-linear least-square problem which is linear w.r.t. the outer layer's weights, we consider a Variable Projection (VarPro) or two-timescale learning algorithm, thereby eliminating the linear variables and reducing the learning problem to the training of the feature distribution. Whereas most convergence rates or the training of neural networks rely on a neural tangent kernel analysis where features are fixed, we show such a strategy enables provable convergence rates for the sampling of a teacher feature distribution. Precisely, in the limit where the regularization strength vanishes, we show that the dynamic of the feature distribution corresponds to a weighted ultra-fast diffusion equation. Relying on recent results on the asymptotic behavior of such PDEs, we obtain guarantees for the convergence of the trained feature distribution towards the teacher feature distribution in a teacher-student setup.
Semi-Discrete Optimal Transport: Nearly Minimax Estimation With Stochastic Gradient Descent and Adaptive Entropic Regularization
May 23, 2024



Optimal Transport (OT) based distances are powerful tools for machine learning to compare probability measures and manipulate them using OT maps. In this field, a setting of interest is semi-discrete OT, where the source measure $\mu$ is continuous, while the target $\nu$ is discrete. Recent works have shown that the minimax rate for the OT map is $\mathcal{O}(t^{-1/2})$ when using $t$ i.i.d. subsamples from each measure (two-sample setting). An open question is whether a better convergence rate can be achieved when the full information of the discrete measure $\nu$ is known (one-sample setting). In this work, we answer positively to this question by (i) proving an $\mathcal{O}(t^{-1})$ lower bound rate for the OT map, using the similarity between Laguerre cells estimation and density support estimation, and (ii) proposing a Stochastic Gradient Descent (SGD) algorithm with adaptive entropic regularization and averaging acceleration. To nearly achieve the desired fast rate, characteristic of non-regular parametric problems, we design an entropic regularization scheme decreasing with the number of samples. Another key step in our algorithm consists of using a projection step that permits to leverage the local strong convexity of the regularized OT problem. Our convergence analysis integrates online convex optimization and stochastic gradient techniques, complemented by the specificities of the OT semi-dual. Moreover, while being as computationally and memory efficient as vanilla SGD, our algorithm achieves the unusual fast rates of our theory in numerical experiments.
Understanding the training of infinitely deep and wide ResNets with Conditional Optimal Transport
Mar 19, 2024We study the convergence of gradient flow for the training of deep neural networks. If Residual Neural Networks are a popular example of very deep architectures, their training constitutes a challenging optimization problem due notably to the non-convexity and the non-coercivity of the objective. Yet, in applications, those tasks are successfully solved by simple optimization algorithms such as gradient descent. To better understand this phenomenon, we focus here on a ``mean-field'' model of infinitely deep and arbitrarily wide ResNet, parameterized by probability measures over the product set of layers and parameters and with constant marginal on the set of layers. Indeed, in the case of shallow neural networks, mean field models have proven to benefit from simplified loss-landscapes and good theoretical guarantees when trained with gradient flow for the Wasserstein metric on the set of probability measures. Motivated by this approach, we propose to train our model with gradient flow w.r.t. the conditional Optimal Transport distance: a restriction of the classical Wasserstein distance which enforces our marginal condition. Relying on the theory of gradient flows in metric spaces we first show the well-posedness of the gradient flow equation and its consistency with the training of ResNets at finite width. Performing a local Polyak-\L{}ojasiewicz analysis, we then show convergence of the gradient flow for well-chosen initializations: if the number of features is finite but sufficiently large and the risk is sufficiently small at initialization, the gradient flow converges towards a global minimizer. This is the first result of this type for infinitely deep and arbitrarily wide ResNets.
Unbalanced Optimal Transport, from Theory to Numerics
Nov 16, 2022Optimal Transport (OT) has recently emerged as a central tool in data sciences to compare in a geometrically faithful way point clouds and more generally probability distributions. The wide adoption of OT into existing data analysis and machine learning pipelines is however plagued by several shortcomings. This includes its lack of robustness to outliers, its high computational costs, the need for a large number of samples in high dimension and the difficulty to handle data in distinct spaces. In this review, we detail several recently proposed approaches to mitigate these issues. We insist in particular on unbalanced OT, which compares arbitrary positive measures, not restricted to probability distributions (i.e. their total mass can vary). This generalization of OT makes it robust to outliers and missing data. The second workhorse of modern computational OT is entropic regularization, which leads to scalable algorithms while lowering the sample complexity in high dimension. The last point presented in this review is the Gromov-Wasserstein (GW) distance, which extends OT to cope with distributions belonging to different metric spaces. The main motivation for this review is to explain how unbalanced OT, entropic regularization and GW can work hand-in-hand to turn OT into efficient geometric loss functions for data sciences.
GradICON: Approximate Diffeomorphisms via Gradient Inverse Consistency
Jun 13, 2022
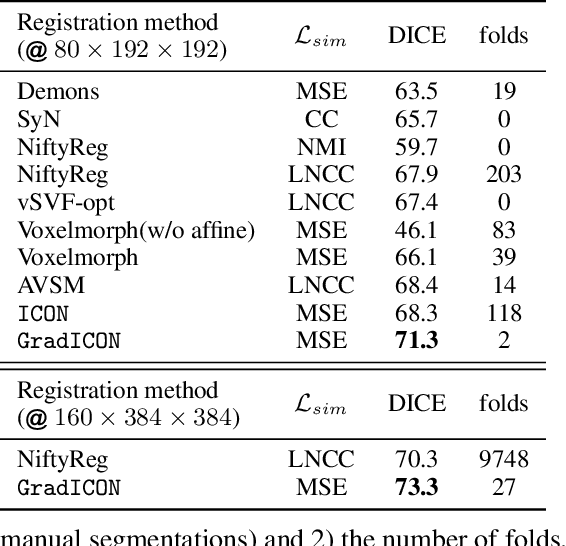
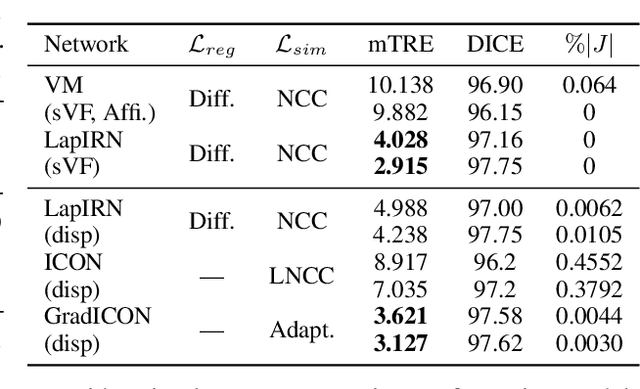
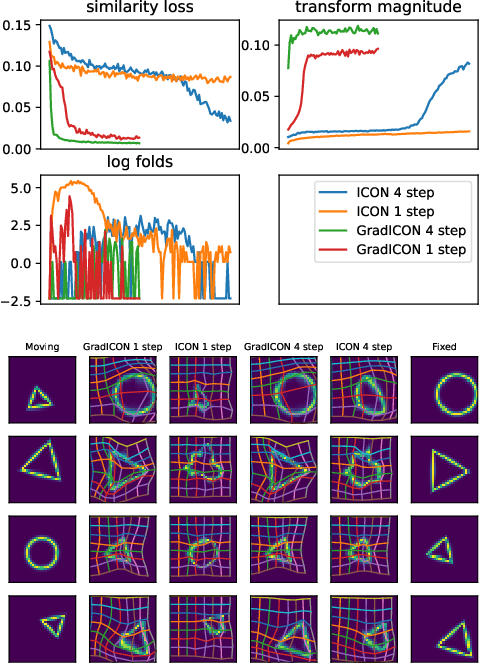
Many registration approaches exist with early work focusing on optimization-based approaches for image pairs. Recent work focuses on deep registration networks to predict spatial transformations. In both cases, commonly used non-parametric registration models, which estimate transformation functions instead of low-dimensional transformation parameters, require choosing a suitable regularizer (to encourage smooth transformations) and its parameters. This makes models difficult to tune and restricts deformations to the deformation space permissible by the chosen regularizer. While deep-learning models for optical flow exist that do not regularize transformations and instead entirely rely on the data these might not yield diffeomorphic transformations which are desirable for medical image registration. In this work, we therefore develop GradICON building upon the unsupervised ICON deep-learning registration approach, which only uses inverse-consistency for regularization. However, in contrast to ICON, we prove and empirically verify that using a gradient inverse-consistency loss not only significantly improves convergence, but also results in a similar implicit regularization of the resulting transformation map. Synthetic experiments and experiments on magnetic resonance (MR) knee images and computed tomography (CT) lung images show the excellent performance of GradICON. We achieve state-of-the-art (SOTA) accuracy while retaining a simple registration formulation, which is practically important.
Toric Geometry of Entropic Regularization
Feb 03, 2022Entropic regularization is a method for large-scale linear programming. Geometrically, one traces intersections of the feasible polytope with scaled toric varieties, starting at the Birch point. We compare this to log-barrier methods, with reciprocal linear spaces, starting at the analytic center. We revisit entropic regularization for unbalanced optimal transport, and we develop the use of optimal conic couplings. We compute the degree of the associated toric variety, and we explore algorithms like iterative scaling.
Faster Unbalanced Optimal Transport: Translation invariant Sinkhorn and 1-D Frank-Wolfe
Jan 03, 2022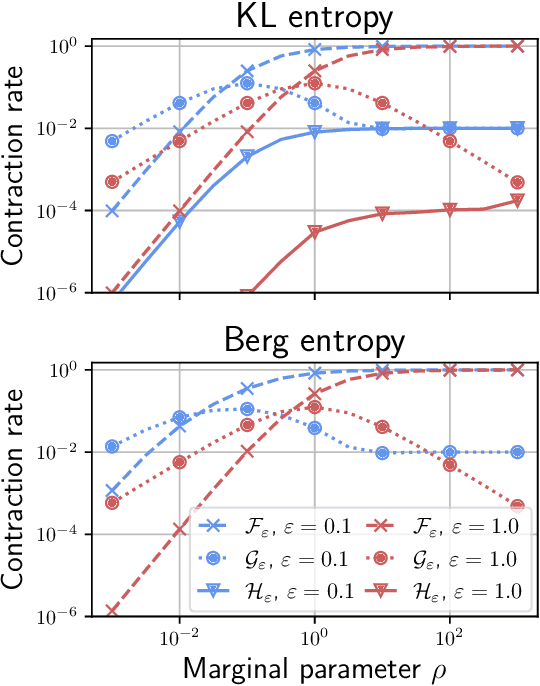
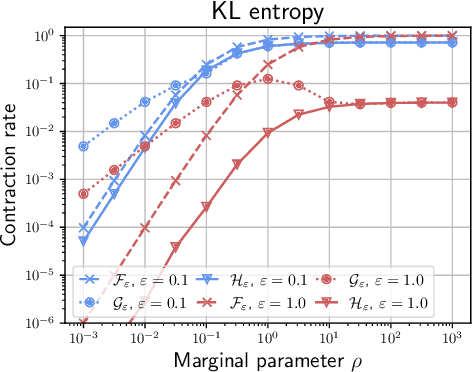

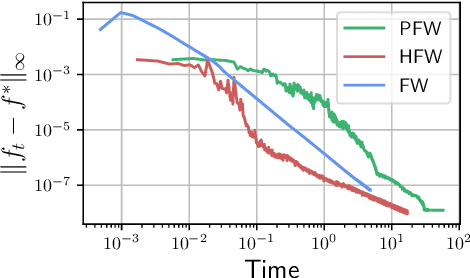
Unbalanced optimal transport (UOT) extends optimal transport (OT) to take into account mass variations to compare distributions. This is crucial to make OT successful in ML applications, making it robust to data normalization and outliers. The baseline algorithm is Sinkhorn, but its convergence speed might be significantly slower for UOT than for OT. In this work, we identify the cause for this deficiency, namely the lack of a global normalization of the iterates, which equivalently corresponds to a translation of the dual OT potentials. Our first contribution leverages this idea to develop a provably accelerated Sinkhorn algorithm (coined 'translation invariant Sinkhorn') for UOT, bridging the computational gap with OT. Our second contribution focusses on 1-D UOT and proposes a Frank-Wolfe solver applied to this translation invariant formulation. The linear oracle of each steps amounts to solving a 1-D OT problems, resulting in a linear time complexity per iteration. Our last contribution extends this method to the computation of UOT barycenter of 1-D measures. Numerical simulations showcase the convergence speed improvement brought by these three approaches.