 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing Transferred Knowledge: An Interpretive Model of Unsupervised Domain Adaptation
Mar 04, 2023Many research efforts have been committed to unsupervised domain adaptation (DA) problems that transfer knowledge learned from a labeled source domain to an unlabeled target domain. Various DA methods have achieved remarkable results recently in terms of predicting ability, which implies the effectiveness of the aforementioned knowledge transferring. However, state-of-the-art methods rarely probe deeper into the transferred mechanism, leaving the true essence of such knowledge obscure. Recognizing its importance in the adaptation process, we propose an interpretive model of unsupervised domain adaptation, as the first attempt to visually unveil the mystery of transferred knowledge. Adapting the existing concept of the prototype from visual image interpretation to the DA task, our model similarly extracts shared information from the domain-invariant representations as prototype vectors. Furthermore, we extend the current prototype method with our novel prediction calibration and knowledge fidelity preservation modules, to orientate the learned prototypes to the actual transferred knowledge. By visualizing these prototypes, our method not only provides an intuitive explanation for the base model's predictions but also unveils transfer knowledge by matching the image patches with the same semantics across both source and target domains. Comprehensive experiments and in-depth explorations demonstrate the efficacy of our method in understanding the transferred mechanism and its potential in downstream tasks including model diagnosis.
Adversarial Bi-Regressor Network for Domain Adaptive Regression
Sep 20, 2022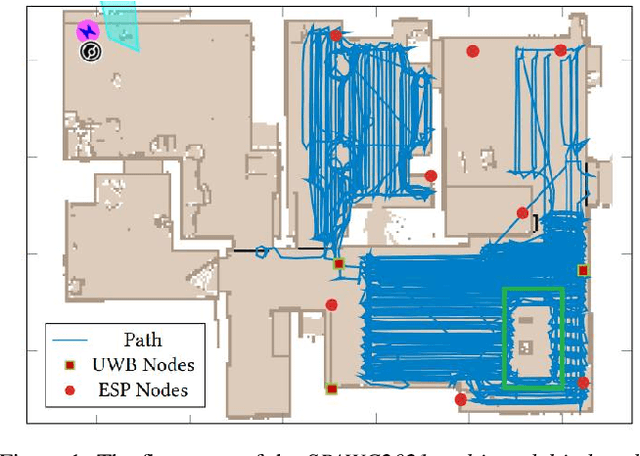
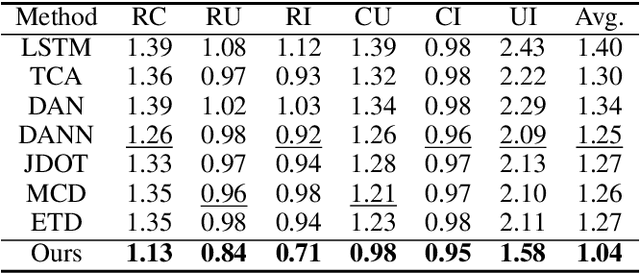
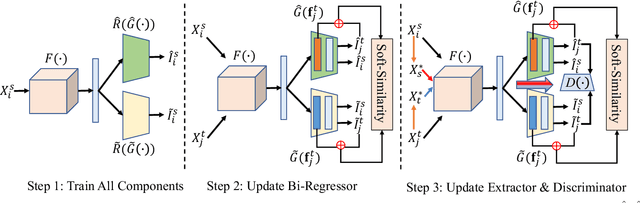
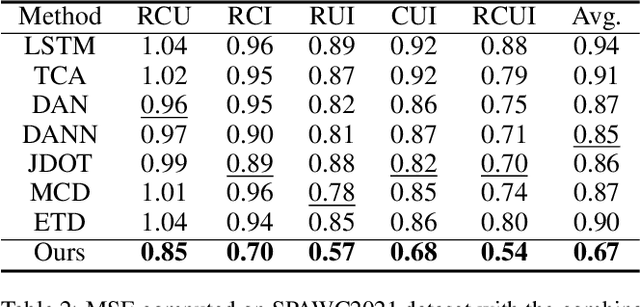
Domain adaptation (DA) aims to transfer the knowledge of a well-labeled source domain to facilitate unlabeled target learning. When turning to specific tasks such as indoor (Wi-Fi) localization, it is essential to learn a cross-domain regressor to mitigate the domain shift. This paper proposes a novel method Adversarial Bi-Regressor Network (ABRNet) to seek more effective cross-domain regression model. Specifically, a discrepant bi-regressor architecture is developed to maximize the difference of bi-regressor to discover uncertain target instances far from the source distribution, and then an adversarial training mechanism is adopted between feature extractor and dual regressors to produce domain-invariant representations. To further bridge the large domain gap, a domain-specific augmentation module is designed to synthesize two source-similar and target-similar intermediate domains to gradually eliminate the original domain mismatch. The empirical studies on two cross-domain regressive benchmarks illustrate the power of our method on solving the domain adaptive regression (DAR) problem.
Toward Better Target Representation for Source-Free and Black-Box Domain Adaptation
Aug 22, 2022
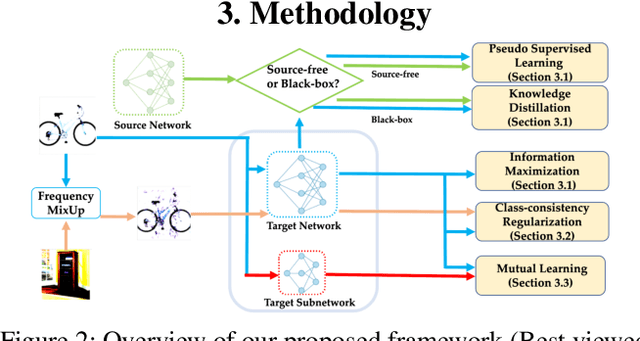

Domain adaptation aims at aligning the labeled source domain and the unlabeled target domain, and most existing approaches assume the source data is accessible. Unfortunately, this paradigm raises concerns in data privacy and security. Recent studies try to dispel these concerns by the Source-Free setting, which adapts the source-trained model towards target domain without exposing the source data. However, the Source-Free paradigm is still at risk of data leakage due to adversarial attacks to the source model. Hence, the Black-Box setting is proposed, where only the outputs of source model can be utilized. In this paper, we address both the Source-Free adaptation and the Black-Box adaptation, proposing a novel method named better target representation from Frequency Mixup and Mutual Learning (FMML). Specifically, we introduce a new data augmentation technique as Frequency MixUp, which highlights task-relevant objects in the interpolations, thus enhancing class-consistency and linear behavior for target models. Moreover, we introduce a network regularization method called Mutual Learning to the domain adaptation problem. It transfers knowledge inside the target model via self-knowledge distillation and thus alleviates overfitting on the source domain by learning multi-scale target representations. Extensive experiments show that our method achieves state-of-the-art performance on several benchmark datasets under both settings.
Learnable Visual Words for Interpretable Image Recognition
May 26, 2022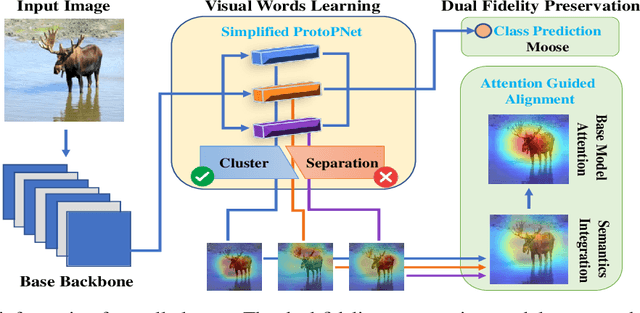
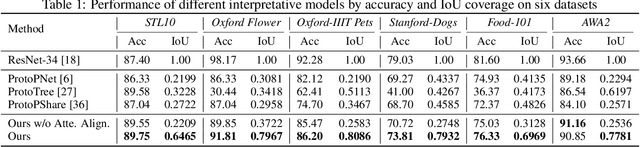
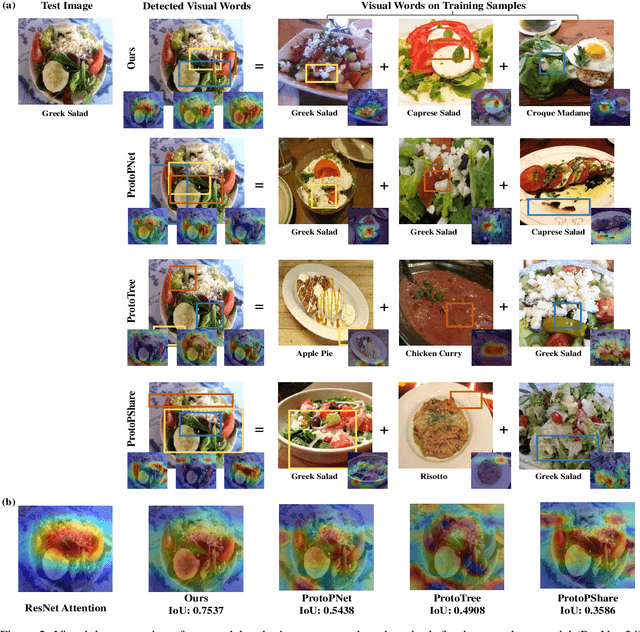
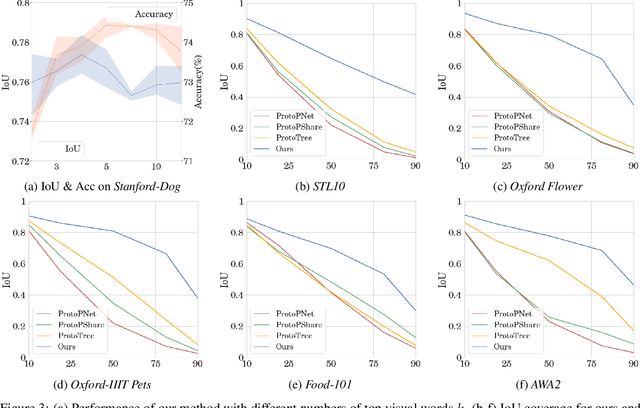
To interpret deep models' predictions, attention-based visual cues are widely used in addressing \textit{why} deep models make such predictions. Beyond that, the current research community becomes more interested in reasoning \textit{how} deep models make predictions, where some prototype-based methods employ interpretable representations with their corresponding visual cues to reveal the black-box mechanism of deep model behaviors. However, these pioneering attempts only either learn the category-specific prototypes and deteriorate their generalizing capacities, or demonstrate several illustrative examples without a quantitative evaluation of visual-based interpretability with further limitations on their practical usages. In this paper, we revisit the concept of visual words and propose the Learnable Visual Words (LVW) to interpret the model prediction behaviors with two novel modules: semantic visual words learning and dual fidelity preservation. The semantic visual words learning relaxes the category-specific constraint, enabling the general visual words shared across different categories. Beyond employing the visual words for prediction to align visual words with the base model, our dual fidelity preservation also includes the attention guided semantic alignment that encourages the learned visual words to focus on the same conceptual regions for prediction. Experiments on six visual benchmarks demonstrate the superior effectiveness of our proposed LVW in both accuracy and model interpretation over the state-of-the-art methods. Moreover, we elaborate on various in-depth analyses to further explore the learned visual words and the generalizability of our method for unseen categories.
On the Equity of Nuclear Norm Maximization in Unsupervised Domain Adaptation
Apr 12, 2022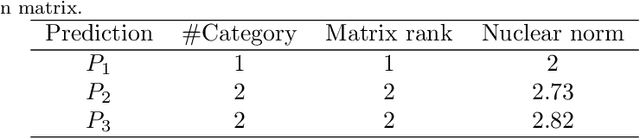
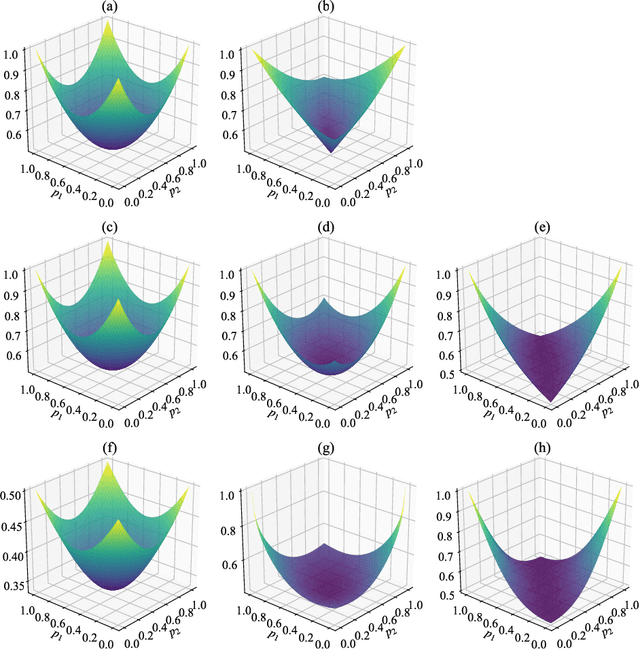


Nuclear norm maximization has shown the power to enhance the transferability of unsupervised domain adaptation model (UDA) in an empirical scheme. In this paper, we identify a new property termed equity, which indicates the balance degree of predicted classes, to demystify the efficacy of nuclear norm maximization for UDA theoretically. With this in mind, we offer a new discriminability-and-equity maximization paradigm built on squares loss, such that predictions are equalized explicitly. To verify its feasibility and flexibility, two new losses termed Class Weighted Squares Maximization (CWSM) and Normalized Squares Maximization (NSM), are proposed to maximize both predictive discriminability and equity, from the class level and the sample level, respectively. Importantly, we theoretically relate these two novel losses (i.e., CWSM and NSM) to the equity maximization under mild conditions, and empirically suggest the importance of the predictive equity in UDA. Moreover, it is very efficient to realize the equity constraints in both losses. Experiments of cross-domain image classification on three popular benchmark datasets show that both CWSM and NSM contribute to outperforming the corresponding counterparts.
PSI: A Pedestrian Behavior Dataset for Socially Intelligent Autonomous Car
Dec 05, 2021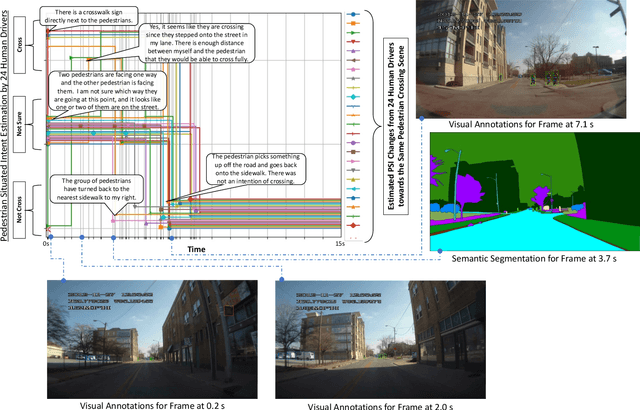


Prediction of pedestrian behavior is critical for fully autonomous vehicles to drive in busy city streets safely and efficiently. The future autonomous cars need to fit into mixed conditions with not only technical but also social capabilities. As more algorithms and datasets have been developed to predict pedestrian behaviors, these efforts lack the benchmark labels and the capability to estimate the temporal-dynamic intent changes of the pedestrians, provide explanations of the interaction scenes, and support algorithms with social intelligence. This paper proposes and shares another benchmark dataset called the IUPUI-CSRC Pedestrian Situated Intent (PSI) data with two innovative labels besides comprehensive computer vision labels. The first novel label is the dynamic intent changes for the pedestrians to cross in front of the ego-vehicle, achieved from 24 drivers with diverse backgrounds. The second one is the text-based explanations of the driver reasoning process when estimating pedestrian intents and predicting their behaviors during the interaction period. These innovative labels can enable several computer vision tasks, including pedestrian intent/behavior prediction, vehicle-pedestrian interaction segmentation, and video-to-language mapping for explainable algorithms. The released dataset can fundamentally improve the development of pedestrian behavior prediction models and develop socially intelligent autonomous cars to interact with pedestrians efficiently. The dataset has been evaluated with different tasks and is released to the public to access.
Local Learning Matters: Rethinking Data Heterogeneity in Federated Learning
Nov 28, 2021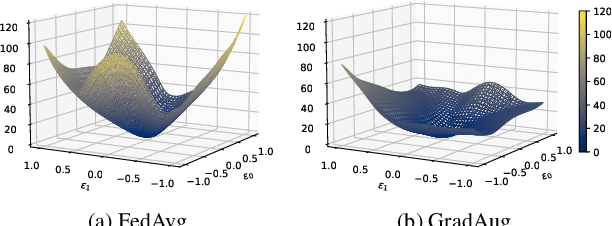
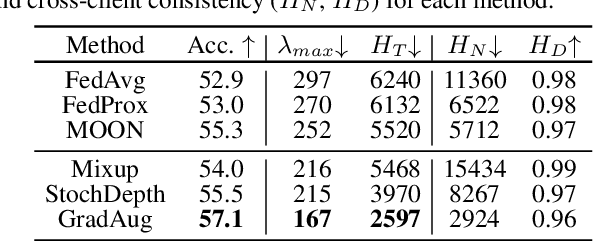
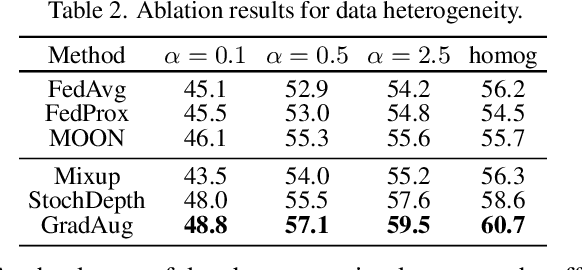
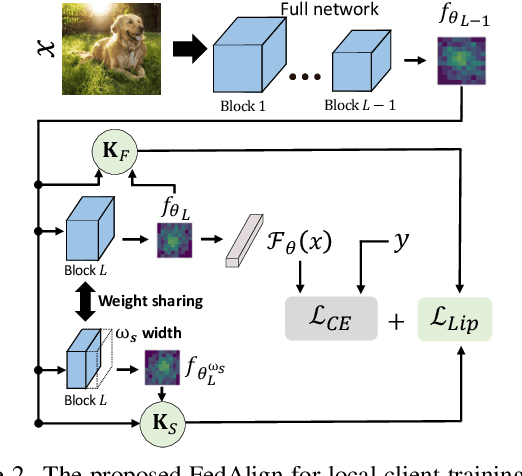
Federated learning (FL) is a promising strategy for performing privacy-preserving, distributed learning with a network of clients (i.e., edge devices). However, the data distribution among clients is often non-IID in nature, making efficient optimization difficult. To alleviate this issue, many FL algorithms focus on mitigating the effects of data heterogeneity across clients by introducing a variety of proximal terms, some incurring considerable compute and/or memory overheads, to restrain local updates with respect to the global model. Instead, we consider rethinking solutions to data heterogeneity in FL with a focus on local learning generality rather than proximal restriction. To this end, we first present a systematic study informed by second-order indicators to better understand algorithm effectiveness in FL. Interestingly, we find that standard regularization methods are surprisingly strong performers in mitigating data heterogeneity effects. Based on our findings, we further propose a simple and effective method, FedAlign, to overcome data heterogeneity and the pitfalls of previous methods. FedAlign achieves competitive accuracy with state-of-the-art FL methods across a variety of settings while minimizing computation and memory overhead. Code will be publicly available.
Polyline Based Generative Navigable Space Segmentation for Autonomous Visual Navigation
Oct 29, 2021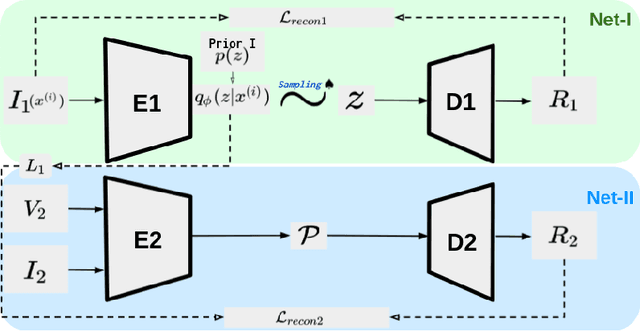
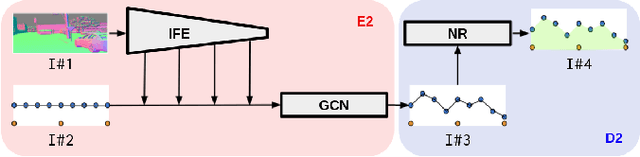
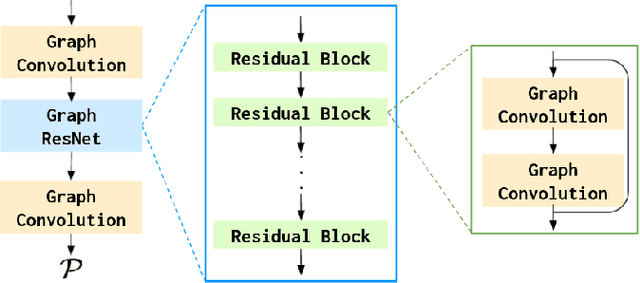
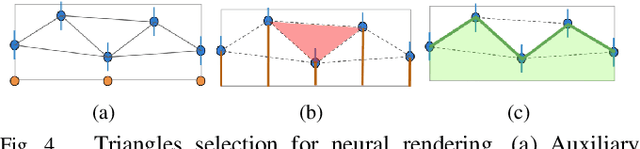
Detecting navigable space is a fundamental capability for mobile robots navigating in unknown or unmapped environments. In this work, we treat the visual navigable space segmentation as a scene decomposition problem and propose Polyline Segmentation Variational AutoEncoder Networks (PSV-Nets), a representation-learning-based framework to enable robots to learn the navigable space segmentation in an unsupervised manner. Current segmentation techniques heavily rely on supervised learning strategies which demand a large amount of pixel-level annotated images. In contrast, the proposed framework leverages a generative model - Variational AutoEncoder (VAE) and an AutoEncoder (AE) to learn a polyline representation that compactly outlines the desired navigable space boundary in an unsupervised way. We also propose a visual receding horizon planning method that uses the learned navigable space and a Scaled Euclidean Distance Field (SEDF) to achieve autonomous navigation without an explicit map. Through extensive experiments, we have validated that the proposed PSV-Nets can learn the visual navigable space with high accuracy, even without any single label. We also show that the prediction of the PSV-Nets can be further improved with a small number of labels (if available) and can significantly outperform the state-of-the-art fully supervised-learning-based segmentation methods.
Towards Novel Target Discovery Through Open-Set Domain Adaptation
May 16, 2021
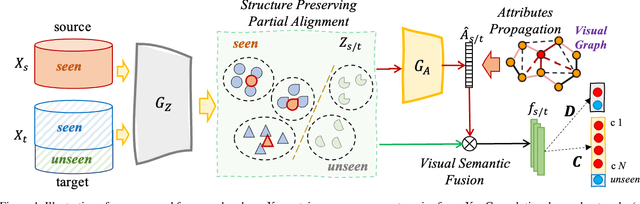
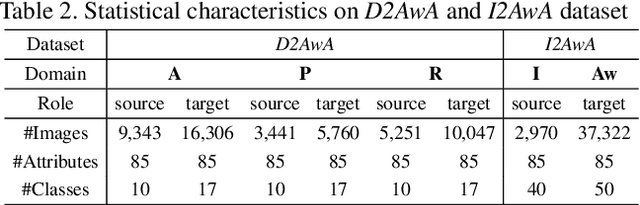
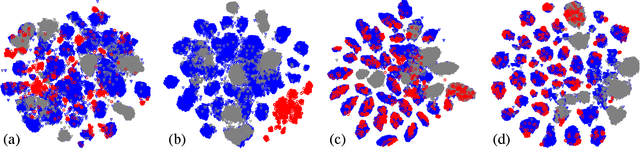
Open-set domain adaptation (OSDA) considers that the target domain contains samples from novel categories unobserved in external source domain. Unfortunately, existing OSDA methods always ignore the demand for the information of unseen categories and simply recognize them as "unknown" set without further explanation. This motivates us to understand the unknown categories more specifically by exploring the underlying structures and recovering their interpretable semantic attributes. In this paper, we propose a novel framework to accurately identify the seen categories in target domain, and effectively recover the semantic attributes for unseen categories. Specifically, structure preserving partial alignment is developed to recognize the seen categories through domain-invariant feature learning. Attribute propagation over visual graph is designed to smoothly transit attributes from seen to unseen categories via visual-semantic mapping. Moreover, two new cross-main benchmarks are constructed to evaluate the proposed framework in the novel and practical challenge. Experimental results on open-set recognition and semantic recovery demonstrate the superiority of the proposed method over other compared baselines.
3D Human Pose Estimation with Spatial and Temporal Transformers
Mar 24, 2021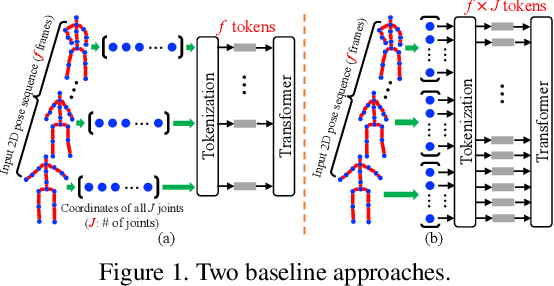
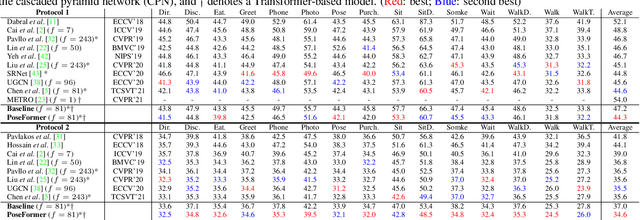
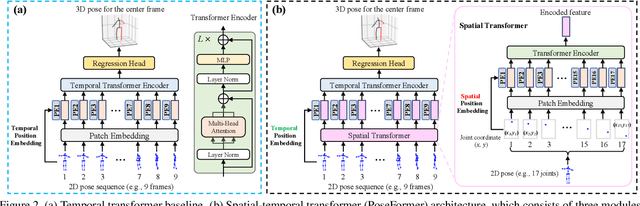
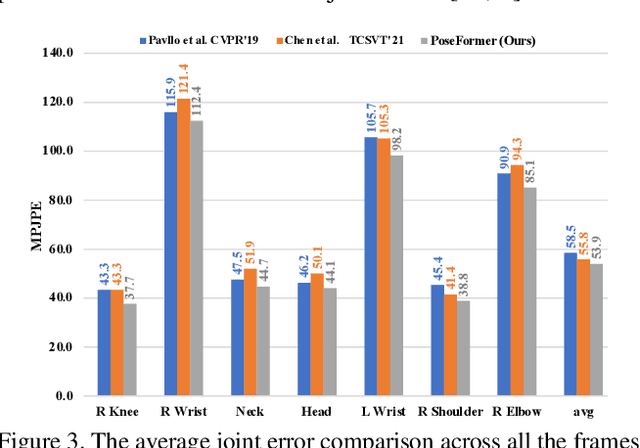
Transformer architectures have become the model of choice in natural language processing and are now being introduced into computer vision tasks such as image classification, object detection, and semantic segmentation. However, in the field of human pose estimation, convolutional architectures still remain dominant. In this work, we present PoseFormer, a purely transformer-based approach for 3D human pose estimation in videos without convolutional architectures involved. Inspired by recent developments in vision transformers, we design a spatial-temporal transformer structure to comprehensively model the human joint relations within each frame as well as the temporal correlations across frames, then output an accurate 3D human pose of the center frame. We quantitatively and qualitatively evaluate our method on two popular and standard benchmark datasets: Human3.6M and MPI-INF-3DHP. Extensive experiments show that PoseFormer achieves state-of-the-art performance on both datasets. Code is available at \url{https://github.com/zczcwh/PoseFormer}