 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neural Machine Translation with Linear Associative Unit
May 02, 2017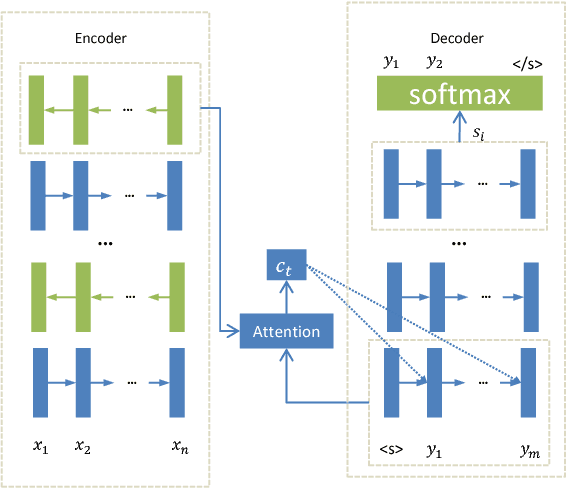
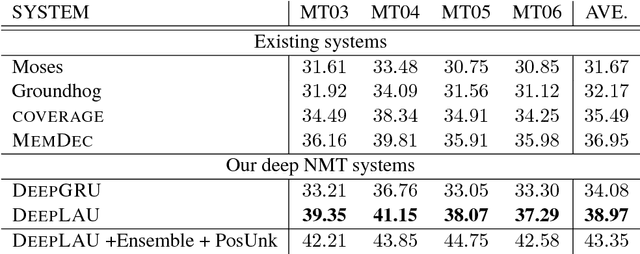
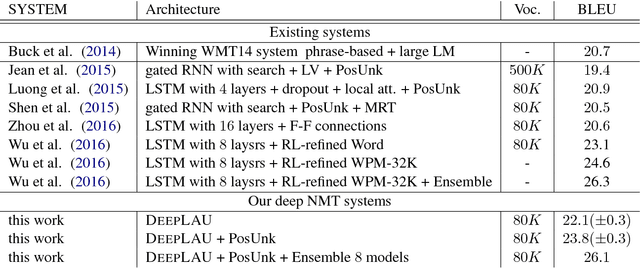
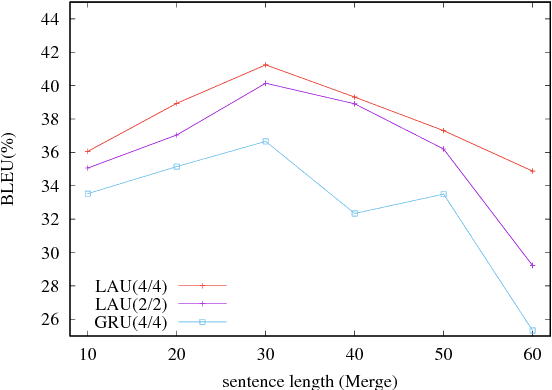
Deep Neural Networks (DNNs) have provably enhanced the state-of-the-art Neural Machine Translation (NMT) with their capability in modeling complex functions and capturing complex linguistic structures. However NMT systems with deep architecture in their encoder or decoder RNNs often suffer from severe gradient diffusion due to the non-linear recurrent activations, which often make the optimization much more difficult. To address this problem we propose novel linear associative units (LAU) to reduce the gradient propagation length inside the recurrent unit. Different from conventional approaches (LSTM unit and GRU), LAUs utilizes linear associative connections between input and output of the recurrent unit, which allows unimpeded information flow through both space and time direction. The model is quite simple, but it is surprisingly effective. Our empirical study on Chinese-English translation shows that our model with proper configuration can improve by 11.7 BLEU upon Groundhog and the best reported results in the same setting. On WMT14 English-German task and a larger WMT14 English-French task, our model achieves comparable results with the state-of-the-art.
Context Gates for Neural Machine Translation
Mar 08, 2017In neural machine translation (NMT), generation of a target word depends on both source and target contexts. We find that source contexts have a direct impact on the adequacy of a translation while target contexts affect the fluency. Intuitively, generation of a content word should rely more on the source context and generation of a functional word should rely more on the target context. Due to the lack of effective control over the influence from source and target contexts, conventional NMT tends to yield fluent but inadequate translations. To address this problem, we propose context gates which dynamically control the ratios at which source and target contexts contribute to the generation of target words. In this way, we can enhance both the adequacy and fluency of NMT with more careful control of the information flow from contexts. Experiments show that our approach significantly improves upon a standard attention-based NMT system by +2.3 BLEU points.
Neural Machine Translation Advised by Statistical Machine Translation
Dec 30, 2016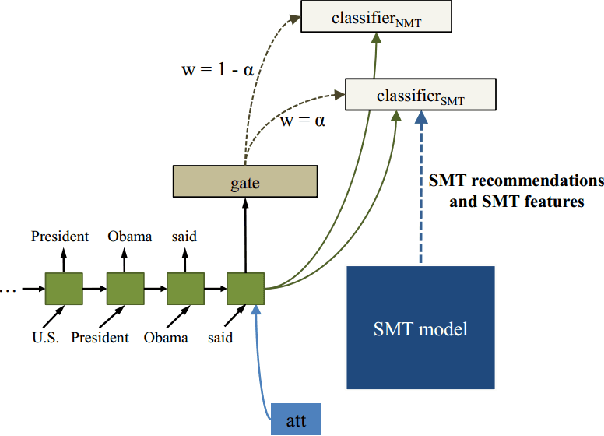
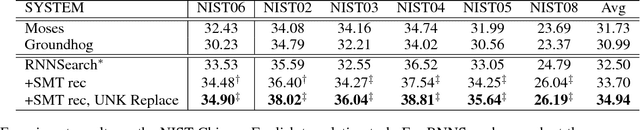
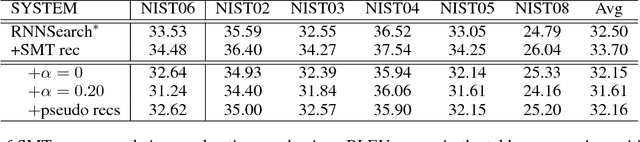
Neural Machine Translation (NMT) is a new approach to machine translation that has made great progress in recent years. However, recent studies show that NMT generally produces fluent but inadequate translations (Tu et al. 2016b; Tu et al. 2016a; He et al. 2016; Tu et al. 2017). This is in contrast to conventional Statistical Machine Translation (SMT), which usually yields adequate but non-fluent translations. It is natural, therefore, to leverage the advantages of both models for better translations, and in this work we propose to incorporate SMT model into NMT framework. More specifically, at each decoding step, SMT offers additional recommendations of generated words based on the decoding information from NMT (e.g., the generated partial translation and attention history). Then we employ an auxiliary classifier to score the SMT recommendations and a gating function to combine the SMT recommendations with NMT generations, both of which are jointly trained within the NMT architecture in an end-to-end manner. Experimental results on Chinese-English translation show that the proposed approach achieves significant and consistent improvements over state-of-the-art NMT and SMT systems on multiple NIST test sets.
Interactive Attention for Neural Machine Translation
Oct 17, 2016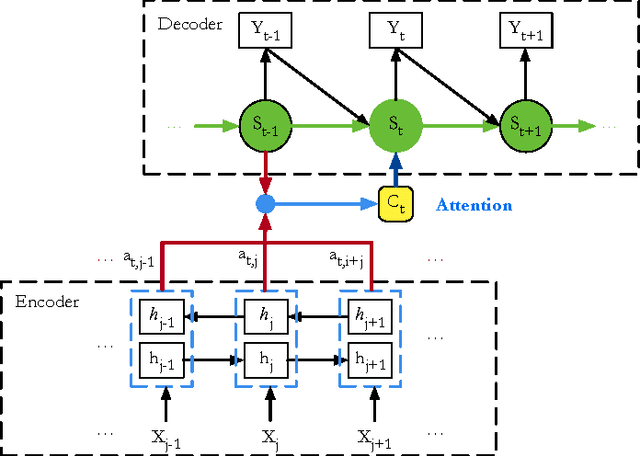
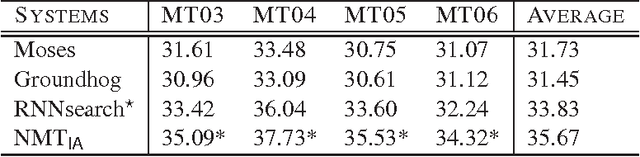
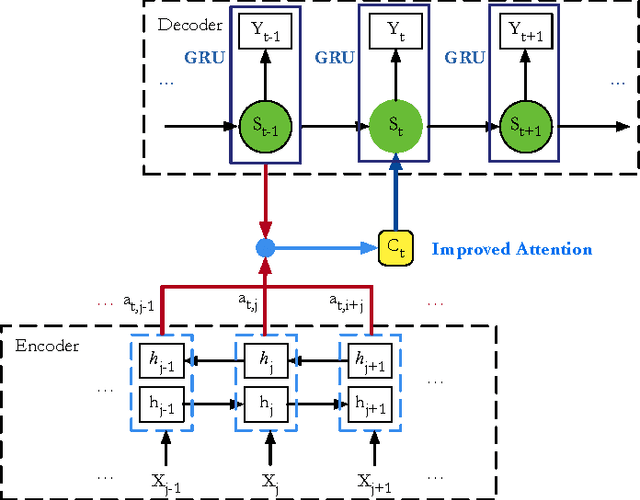

Conventional attention-based Neural Machine Translation (NMT) conducts dynamic alignment in generating the target sentence. By repeatedly reading the representation of source sentence, which keeps fixed after generated by the encoder (Bahdanau et al., 2015), the attention mechanism has greatly enhanced state-of-the-art NMT. In this paper, we propose a new attention mechanism, called INTERACTIVE ATTENTION, which models the interaction between the decoder and the representation of source sentence during translation by both reading and writing operations. INTERACTIVE ATTENTION can keep track of the interaction history and therefore improve the translation performance. Experiments on NIST Chinese-English translation task show that INTERACTIVE ATTENTION can achieve significant improvements over both the previous attention-based NMT baseline and some state-of-the-art variants of attention-based NMT (i.e., coverage models (Tu et al., 2016)). And neural machine translator with our INTERACTIVE ATTENTION can outperform the open source attention-based NMT system Groundhog by 4.22 BLEU points and the open source phrase-based system Moses by 3.94 BLEU points averagely on multiple test sets.
Modeling Coverage for Neural Machine Translation
Aug 06, 2016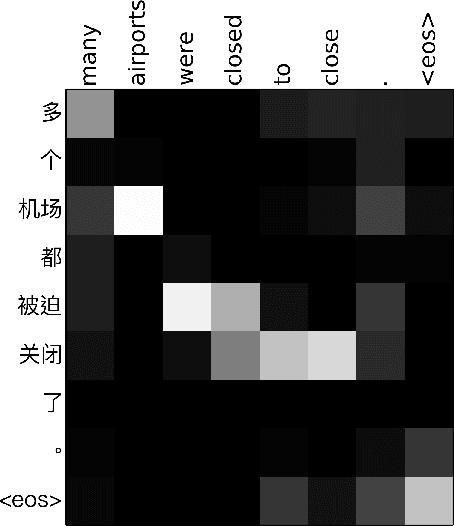
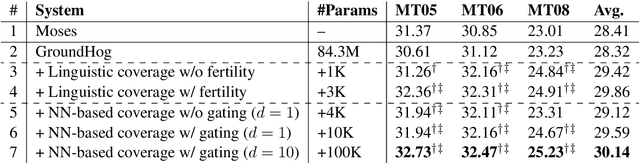
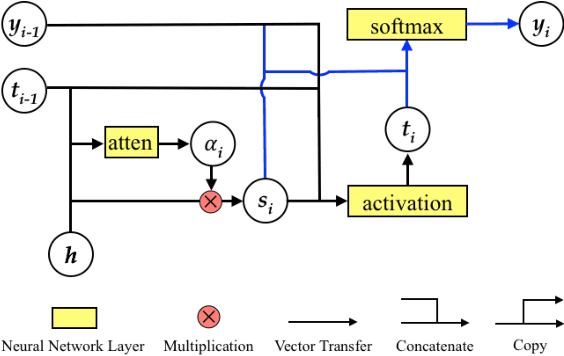

Attention mechanism has enhanced state-of-the-art Neural Machine Translation (NMT) by jointly learning to align and translate. It tends to ignore past alignment information, however, which often leads to over-translation and under-translation. To address this problem, we propose coverage-based NMT in this paper. We maintain a coverage vector to keep track of the attention history. The coverage vector is fed to the attention model to help adjust future attention, which lets NMT system to consider more about untranslated source words. Experiments show that the proposed approach significantly improves both translation quality and alignment quality over standard attention-based NMT.
Incorporating Copying Mechanism in Sequence-to-Sequence Learning
Jun 08, 2016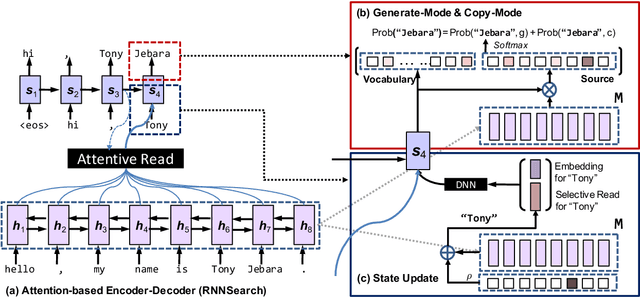
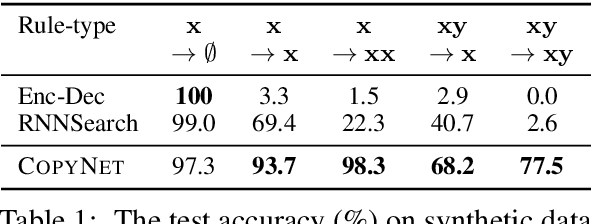
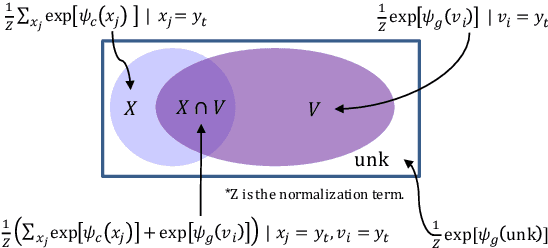
We address an important problem in sequence-to-sequence (Seq2Seq) learning referred to as copying, in which certain segments in the input sequence are selectively replicated in the output sequence. A similar phenomenon is observable in human language communication. For example, humans tend to repeat entity names or even long phrases in conversation. The challenge with regard to copying in Seq2Seq is that new machinery is needed to decide when to perform the operation. In this paper, we incorporate copying into neural network-based Seq2Seq learning and propose a new model called CopyNet with encoder-decoder structure. CopyNet can nicely integrate the regular way of word generation in the decoder with the new copying mechanism which can choose sub-sequences in the input sequence and put them at proper places in the output sequence. Our empirical study on both synthetic data sets and real world data sets demonstrates the efficacy of CopyNet. For example, CopyNet can outperform regular RNN-based model with remarkable margins on text summarization tasks.
Memory-enhanced Decoder for Neural Machine Translation
Jun 07, 2016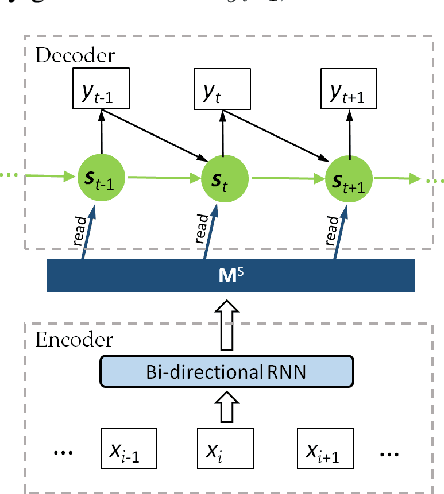
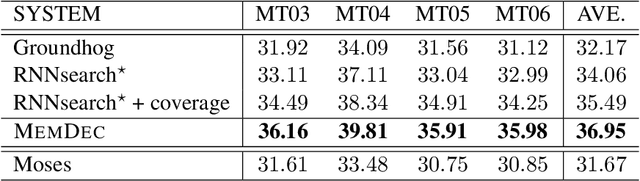
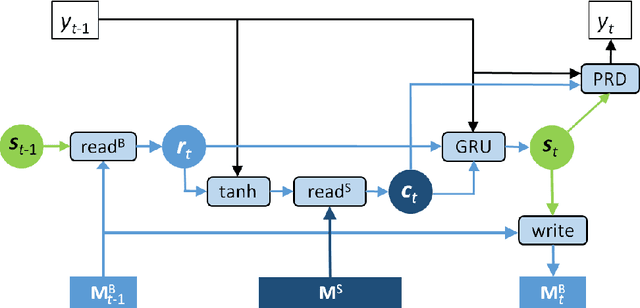
We propose to enhance the RNN decoder in a neural machine translator (NMT) with external memory, as a natural but powerful extension to the state in the decoding RNN. This memory-enhanced RNN decoder is called \textsc{MemDec}. At each time during decoding, \textsc{MemDec} will read from this memory and write to this memory once, both with content-based addressing. Unlike the unbounded memory in previous work\cite{RNNsearch} to store the representation of source sentence, the memory in \textsc{MemDec} is a matrix with pre-determined size designed to better capture the information important for the decoding process at each time step. Our empirical study on Chinese-English translation shows that it can improve by $4.8$ BLEU upon Groundhog and $5.3$ BLEU upon on Moses, yielding the best performance achieved with the same training set.
Neural Machine Translation with External Phrase Memory
Jun 06, 2016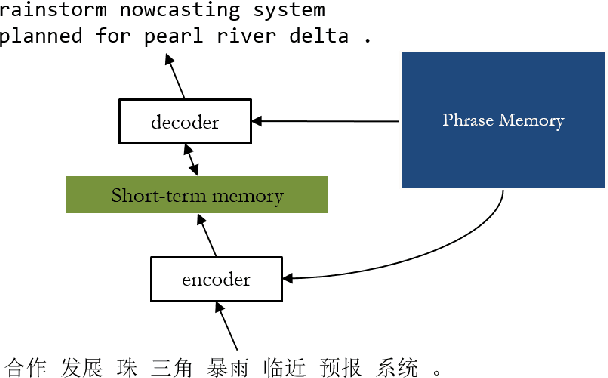
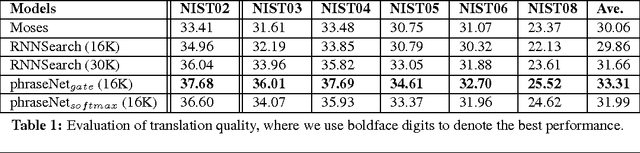

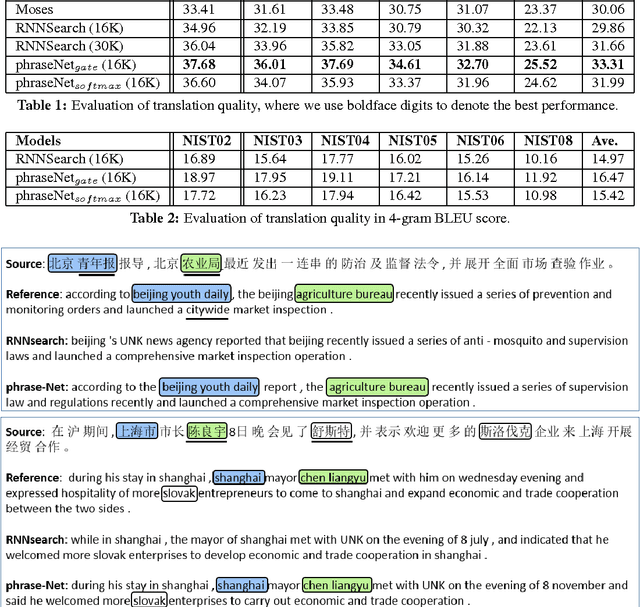
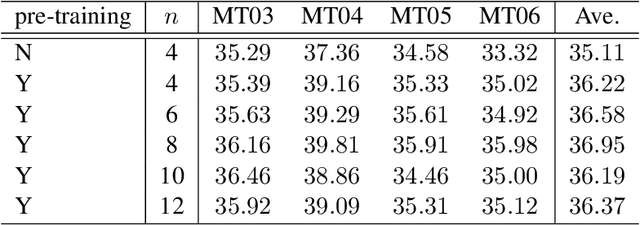
In this paper, we propose phraseNet, a neural machine translator with a phrase memory which stores phrase pairs in symbolic form, mined from corpus or specified by human experts. For any given source sentence, phraseNet scans the phrase memory to determine the candidate phrase pairs and integrates tagging information in the representation of source sentence accordingly. The decoder utilizes a mixture of word-generating component and phrase-generating component, with a specifically designed strategy to generate a sequence of multiple words all at once. The phraseNet not only approaches one step towards incorporating external knowledge into neural machine translation, but also makes an effort to extend the word-by-word generation mechanism of recurrent neural network. Our empirical study on Chinese-to-English translation shows that, with carefully-chosen phrase table in memory, phraseNet yields 3.45 BLEU improvement over the generic neural machine translator.
Neural Generative Question Answering
Apr 22, 2016
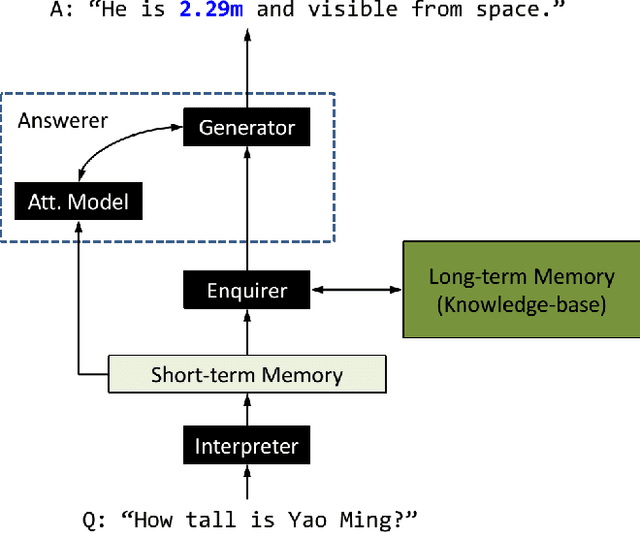
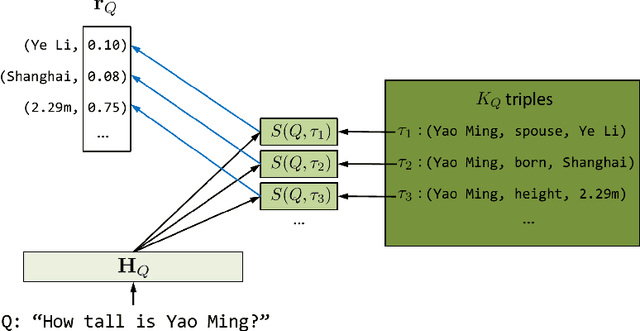
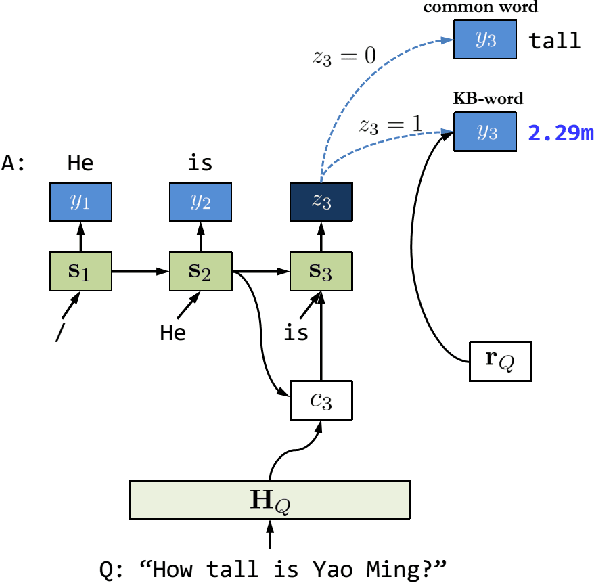
This paper presents an end-to-end neural network model, named Neural Generative Question Answering (GENQA), that can generate answers to simple factoid questions, based on the facts in a knowledge-base. More specifically, the model is built on the encoder-decoder framework for sequence-to-sequence learning, while equipped with the ability to enquire the knowledge-base, and is trained on a corpus of question-answer pairs, with their associated triples in the knowledge-base. Empirical study shows the proposed model can effectively deal with the variations of questions and answers, and generate right and natural answers by referring to the facts in the knowledge-base. The experiment on question answering demonstrates that the proposed model can outperform an embedding-based QA model as well as a neural dialogue model trained on the same data.
Neural Enquirer: Learning to Query Tables with Natural Language
Jan 21, 2016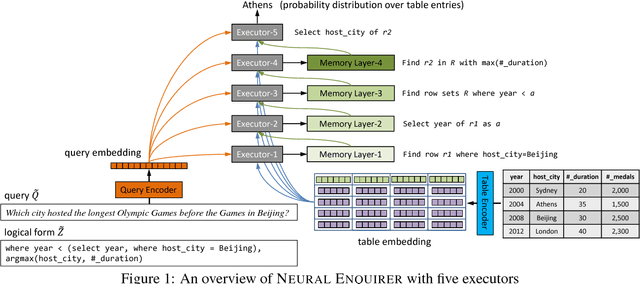
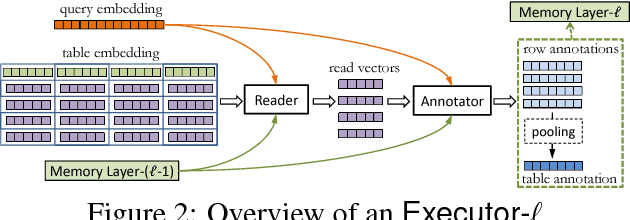
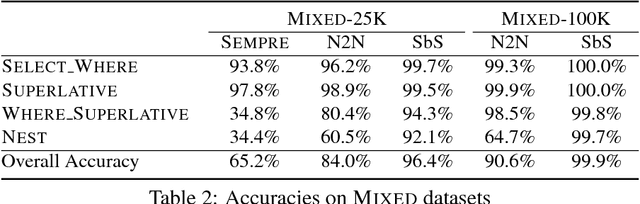
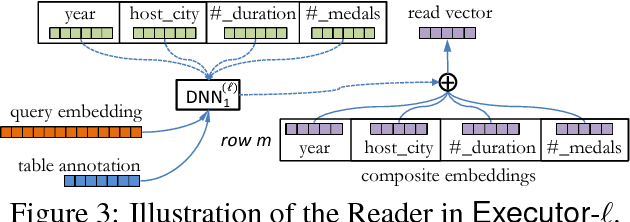
We proposed Neural Enquirer as a neural network architecture to execute a natural language (NL) query on a knowledge-base (KB) for answers. Basically, Neural Enquirer finds the distributed representation of a query and then executes it on knowledge-base tables to obtain the answer as one of the values in the tables. Unlike similar efforts in end-to-end training of semantic parsers, Neural Enquirer is fully "neuralized": it not only gives distributional representation of the query and the knowledge-base, but also realizes the execution of compositional queries as a series of differentiable operations, with intermediate results (consisting of annotations of the tables at different levels) saved on multiple layers of memory. Neural Enquirer can be trained with gradient descent, with which not only the parameters of the controlling components and semantic parsing component, but also the embeddings of the tables and query words can be learned from scratch. The training can be done in an end-to-end fashion, but it can take stronger guidance, e.g., the step-by-step supervision for complicated queries, and benefit from it. Neural Enquirer is one step towards building neural network systems which seek to understand language by executing it on real-world. Our experiments show that Neural Enquirer can learn to execute fairly complicated NL queries on tables with rich structures.