 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction-following Evaluation through Verbalizer Manipulation
Jul 20, 2023



While instruction-tuned models have shown remarkable success in various natural language processing tasks, accurately evaluating their ability to follow instructions remains challenging. Existing benchmarks primarily focus on common instructions that align well with what the model learned during training. However, proficiency in responding to these instructions does not necessarily imply strong ability in instruction following. In this paper, we propose a novel instruction-following evaluation protocol called verbalizer manipulation. It instructs the model to verbalize the task label with words aligning with model priors to different extents, adopting verbalizers from highly aligned (e.g., outputting ``postive'' for positive sentiment), to minimally aligned (e.g., outputting ``negative'' for positive sentiment). Verbalizer manipulation can be seamlessly integrated with any classification benchmark to examine the model's reliance on priors and its ability to override them to accurately follow the instructions. We conduct a comprehensive evaluation of four major model families across nine datasets, employing twelve sets of verbalizers for each of them. We observe that the instruction-following abilities of models, across different families and scales, are significantly distinguished by their performance on less natural verbalizers. Even the strongest GPT-4 model struggles to perform better than random guessing on the most challenging verbalizer, emphasizing the need for continued advancements to improve their instruction-following abilities.
AlpaGasus: Training A Better Alpaca with Fewer Data
Jul 17, 2023



Large language models~(LLMs) obtain instruction-following capability through instruction-finetuning (IFT) on supervised instruction/response data. However, widely used IFT datasets (e.g., Alpaca's 52k data) surprisingly contain many low-quality instances with incorrect or irrelevant responses, which are misleading and detrimental to IFT. In this paper, we propose a simple and effective data selection strategy that automatically identifies and removes low-quality data using a strong LLM (e.g., ChatGPT). To this end, we introduce AlpaGasus, which is finetuned on only 9k high-quality data filtered from the 52k Alpaca data. AlpaGasus significantly outperforms the original Alpaca as evaluated by GPT-4 on multiple test sets and its 13B variant matches $>90\%$ performance of its teacher LLM (i.e., Text-Davinci-003) on test tasks. It also provides 5.7x faster training, reducing the training time for a 7B variant from 80 minutes (for Alpaca) to 14 minutes \footnote{We apply IFT for the same number of epochs as Alpaca(7B) but on fewer data, using 4$\times$NVIDIA A100 (80GB) GPUs and following the original Alpaca setting and hyperparameters.}. Overall, AlpaGasus demonstrates a novel data-centric IFT paradigm that can be generally applied to instruction-tuning data, leading to faster training and better instruction-following models. Our project page is available at: \url{https://lichang-chen.github.io/AlpaGasus/}.
The Staged Knowledge Distillation in Video Classification: Harmonizing Student Progress by a Complementary Weakly Supervised Framework
Jul 16, 2023



In the context of label-efficient learning on video data, the distillation method and the structural design of the teacher-student architecture have a significant impact on knowledge distillation. However, the relationship between these factors has been overlooked in previous research. To address this gap, we propose a new weakly supervised learning framework for knowledge distillation in video classification that is designed to improve the efficiency and accuracy of the student model. Our approach leverages the concept of substage-based learning to distill knowledge based on the combination of student substages and the correlation of corresponding substages. We also employ the progressive cascade training method to address the accuracy loss caused by the large capacity gap between the teacher and the student. Additionally, we propose a pseudo-label optimization strategy to improve the initial data label. To optimize the loss functions of different distillation substages during the training process, we introduce a new loss method based on feature distribution. We conduct extensive experiments on both real and simulated data sets, demonstrating that our proposed approach outperforms existing distillation methods in terms of knowledge distillation for video classification tasks. Our proposed substage-based distillation approach has the potential to inform future research on label-efficient learning for video data.
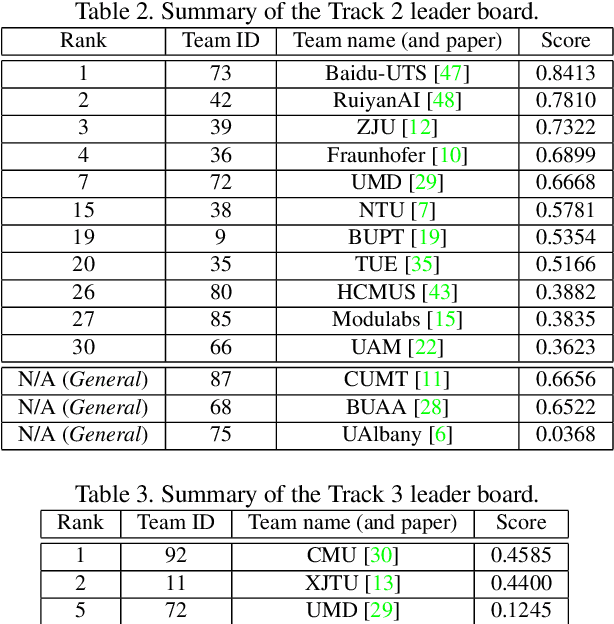
The 7th AI City Challenge
Apr 15, 2023



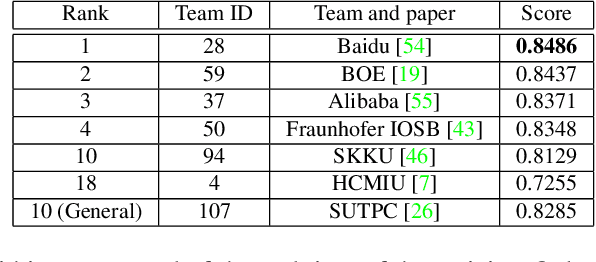
The AI City Challenge's seventh edition emphasizes two domains at the intersection of computer vision and artificial intelligence - retail business and Intelligent Traffic Systems (ITS) - that have considerable untapped potential. The 2023 challenge had five tracks, which drew a record-breaking number of participation requests from 508 teams across 46 countries. Track 1 was a brand new track that focused on multi-target multi-camera (MTMC) people tracking, where teams trained and evaluated using both real and highly realistic synthetic data. Track 2 centered around natural-language-based vehicle track retrieval. Track 3 required teams to classify driver actions in naturalistic driving analysis. Track 4 aimed to develop an automated checkout system for retail stores using a single view camera. Track 5, another new addition, tasked teams with detecting violations of the helmet rule for motorcyclists. Two leader boards were released for submissions based on different methods: a public leader board for the contest where external private data wasn't allowed and a general leader board for all results submitted. The participating teams' top performances established strong baselines and even outperformed the state-of-the-art in the proposed challenge tracks.
It Takes Two Flints to Make a Fire: Multitask Learning of Neural Relation and Explanation Classifiers
Apr 25, 2022
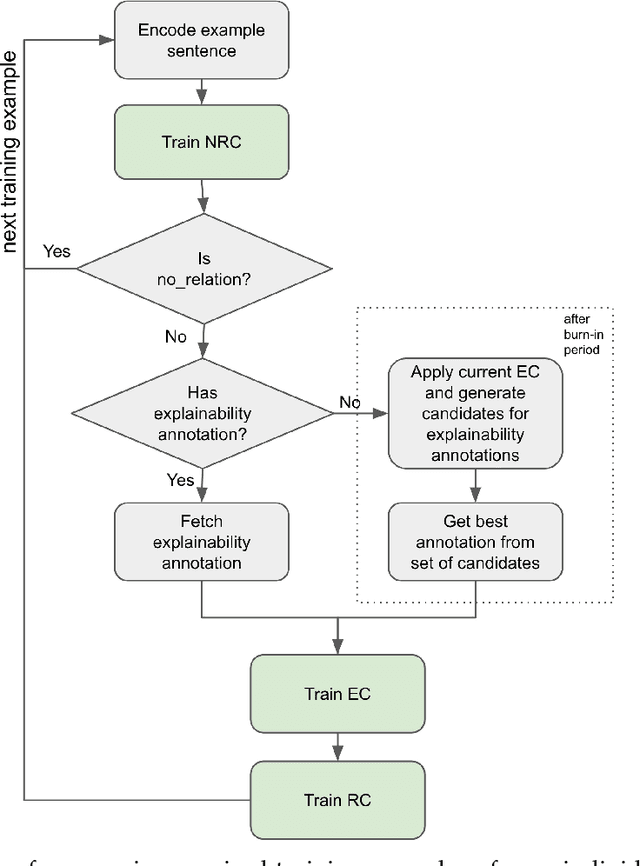
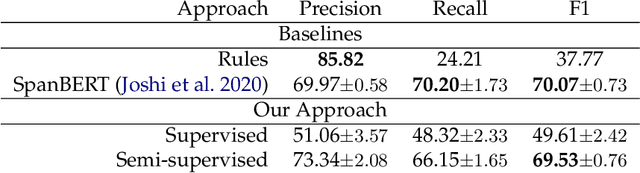
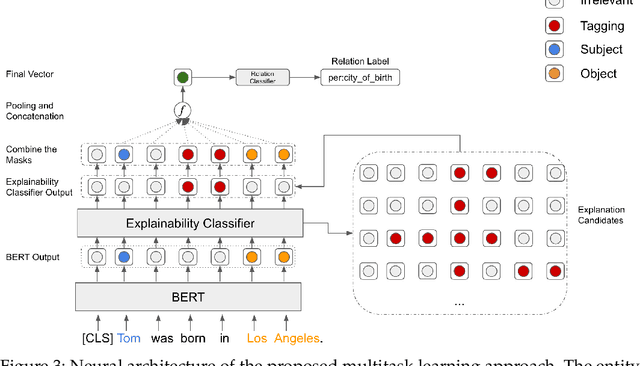
We propose an explainable approach for relation extraction that mitigates the tension between generalization and explainability by jointly training for the two goals. Our approach uses a multi-task learning architecture, which jointly trains a classifier for relation extraction, and a sequence model that labels words in the context of the relation that explain the decisions of the relation classifier. We also convert the model outputs to rules to bring global explanations to this approach. This sequence model is trained using a hybrid strategy: supervised, when supervision from pre-existing patterns is available, and semi-supervised otherwise. In the latter situation, we treat the sequence model's labels as latent variables, and learn the best assignment that maximizes the performance of the relation classifier. We evaluate the proposed approach on the two datasets and show that the sequence model provides labels that serve as accurate explanations for the relation classifier's decisions, and, importantly, that the joint training generally improves the performance of the relation classifier. We also evaluate the performance of the generated rules and show that the new rules are great add-on to the manual rules and bring the rule-based system much closer to the neural models.
The 6th AI City Challenge
Apr 21, 2022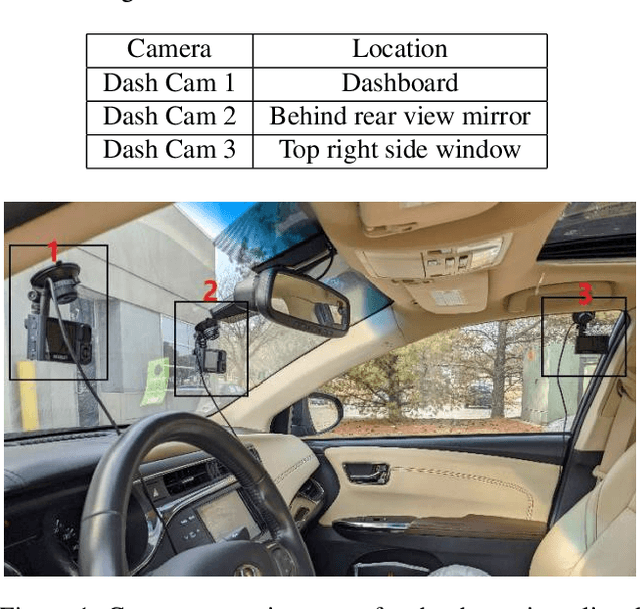
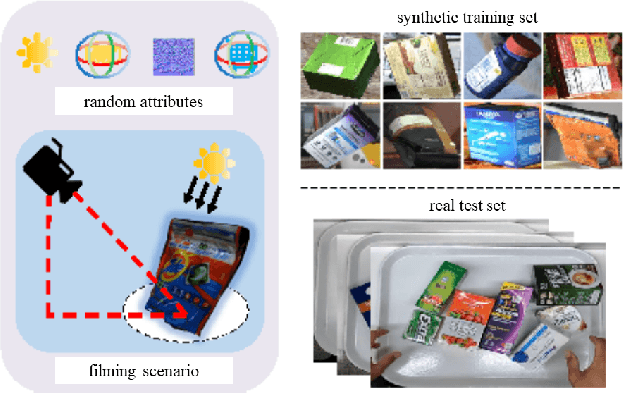
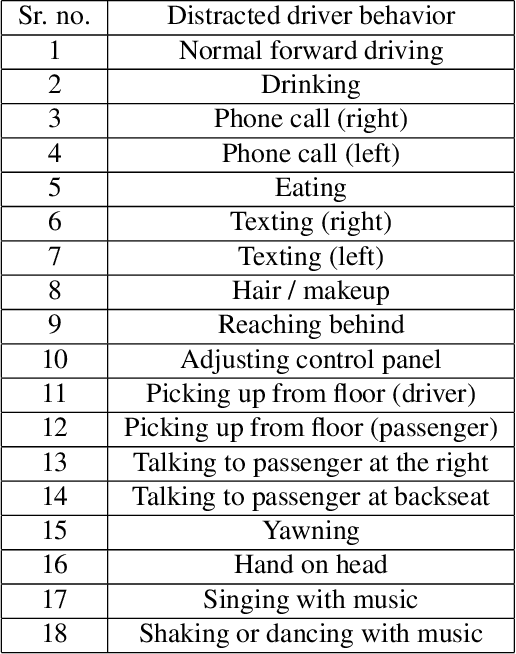
The 6th edition of the AI City Challenge specifically focuses on problems in two domains where there is tremendous unlocked potential at the intersection of computer vision and artificial intelligence: Intelligent Traffic Systems (ITS), and brick and mortar retail businesses. The four challenge tracks of the 2022 AI City Challenge received participation requests from 254 teams across 27 countries. Track 1 addressed city-scale multi-target multi-camera (MTMC) vehicle tracking. Track 2 addressed natural-language-based vehicle track retrieval. Track 3 was a brand new track for naturalistic driving analysis, where the data were captured by several cameras mounted inside the vehicle focusing on driver safety, and the task was to classify driver actions. Track 4 was another new track aiming to achieve retail store automated checkout using only a single view camera. We released two leader boards for submissions based on different methods, including a public leader board for the contest, where no use of external data is allowed, and a general leader board for all submitted results. The top performance of participating teams established strong baselines and even outperformed the state-of-the-art in the proposed challenge tracks.
How May I Help You? Using Neural Text Simplification to Improve Downstream NLP Tasks
Sep 14, 2021
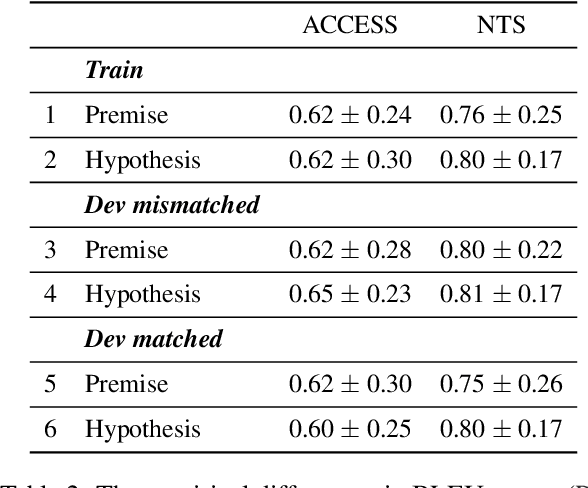
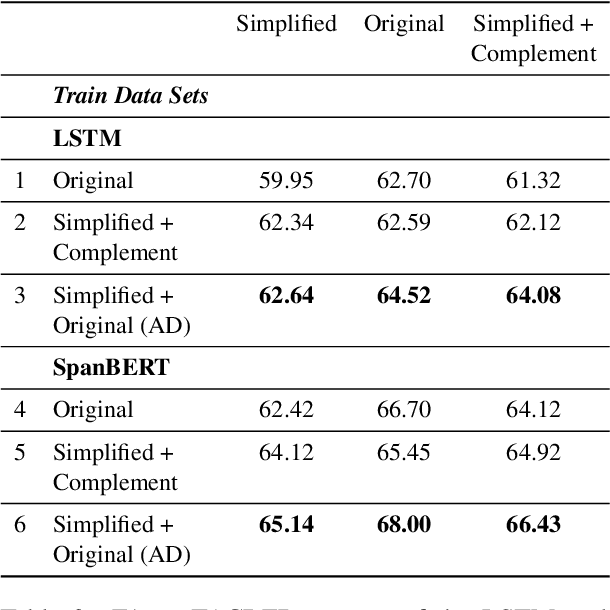
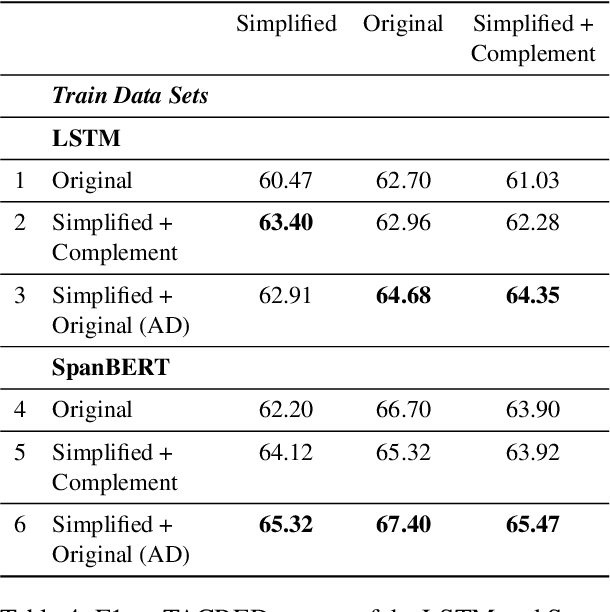
The general goal of text simplification (TS) is to reduce text complexity for human consumption. This paper investigates another potential use of neural TS: assisting machines performing natural language processing (NLP) tasks. We evaluate the use of neural TS in two ways: simplifying input texts at prediction time and augmenting data to provide machines with additional information during training. We demonstrate that the latter scenario provides positive effects on machine performance on two separate datasets. In particular, the latter use of TS improves the performances of LSTM (1.82-1.98%) and SpanBERT (0.7-1.3%) extractors on TACRED, a complex, large-scale, real-world relation extraction task. Further, the same setting yields improvements of up to 0.65% matched and 0.62% mismatched accuracies for a BERT text classifier on MNLI, a practical natural language inference dataset.
The 5th AI City Challenge
May 24, 2021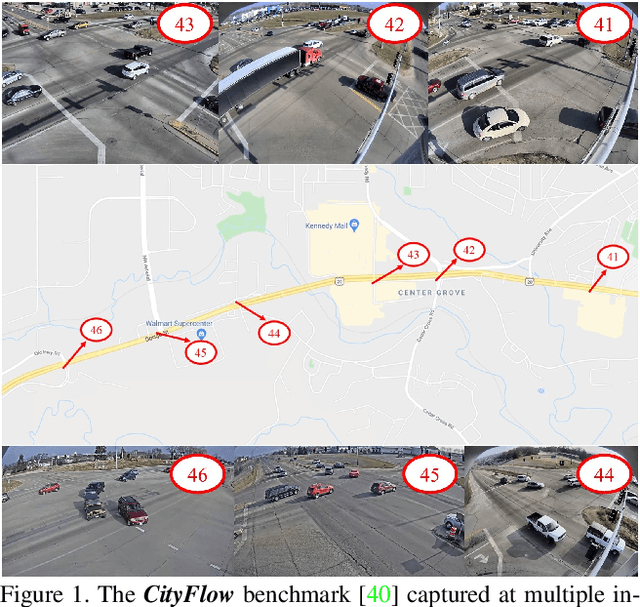
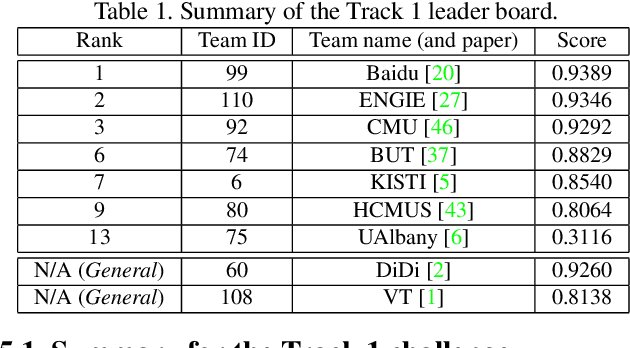
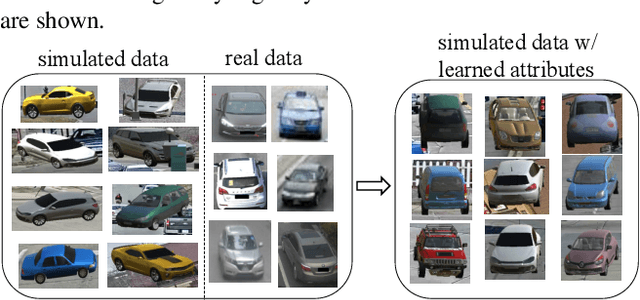
The AI City Challenge was created with two goals in mind: (1) pushing the boundaries of research and development in intelligent video analysis for smarter cities use cases, and (2) assessing tasks where the level of performance is enough to cause real-world adoption. Transportation is a segment ripe for such adoption. The fifth AI City Challenge attracted 305 participating teams across 38 countries, who leveraged city-scale real traffic data and high-quality synthetic data to compete in five challenge tracks. Track 1 addressed video-based automatic vehicle counting, where the evaluation being conducted on both algorithmic effectiveness and computational efficiency. Track 2 addressed city-scale vehicle re-identification with augmented synthetic data to substantially increase the training set for the task. Track 3 addressed city-scale multi-target multi-camera vehicle tracking. Track 4 addressed traffic anomaly detection. Track 5 was a new track addressing vehicle retrieval using natural language descriptions. The evaluation system shows a general leader board of all submitted results, and a public leader board of results limited to the contest participation rules, where teams are not allowed to use external data in their work. The public leader board shows results more close to real-world situations where annotated data is limited. Results show the promise of AI in Smarter Transportation. State-of-the-art performance for some tasks shows that these technologies are ready for adoption in real-world systems.
PAMTRI: Pose-Aware Multi-Task Learning for Vehicle Re-Identification Using Highly Randomized Synthetic Data
May 02, 2020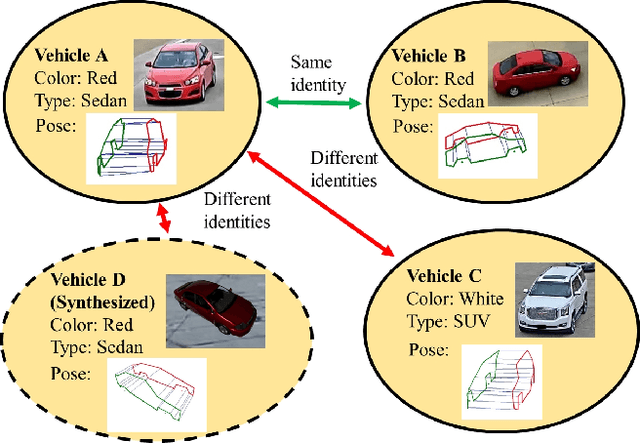
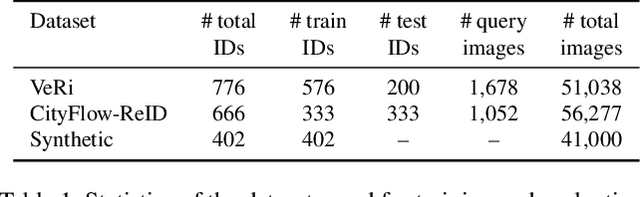
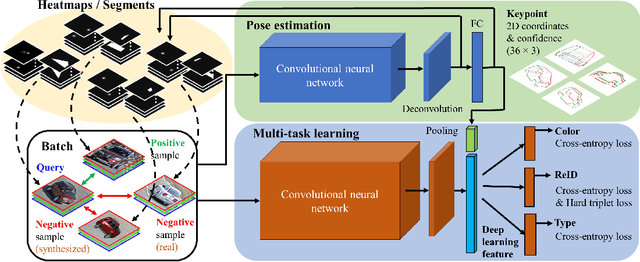
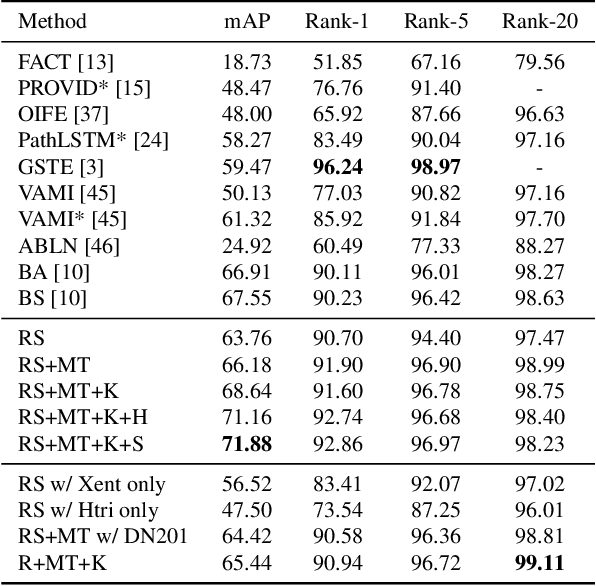
In comparison with person re-identification (ReID), which has been widely studied in the research community, vehicle ReID has received less attention. Vehicle ReID is challenging due to 1) high intra-class variability (caused by the dependency of shape and appearance on viewpoint), and 2) small inter-class variability (caused by the similarity in shape and appearance between vehicles produced by different manufacturers). To address these challenges, we propose a Pose-Aware Multi-Task Re-Identification (PAMTRI) framework. This approach includes two innovations compared with previous methods. First, it overcomes viewpoint-dependency by explicitly reasoning about vehicle pose and shape via keypoints, heatmaps and segments from pose estimation. Second, it jointly classifies semantic vehicle attributes (colors and types) while performing ReID, through multi-task learning with the embedded pose representations. Since manually labeling images with detailed pose and attribute information is prohibitive, we create a large-scale highly randomized synthetic dataset with automatically annotated vehicle attributes for training. Extensive experiments validate the effectiveness of each proposed component, showing that PAMTRI achieves significant improvement over state-of-the-art on two mainstream vehicle ReID benchmarks: VeRi and CityFlow-ReID. Code and models are available at https://github.com/NVlabs/PAMTRI.
The 4th AI City Challenge
Apr 30, 2020The AI City Challenge was created to accelerate intelligent video analysis that helps make cities smarter and safer. Transportation is one of the largest segments that can benefit from actionable insights derived from data captured by sensors, where computer vision and deep learning have shown promise in achieving large-scale practical deployment. The 4th annual edition of the AI City Challenge has attracted 315 participating teams across 37 countries, who leveraged city-scale real traffic data and high-quality synthetic data to compete in four challenge tracks. Track 1 addressed video-based automatic vehicle counting, where the evaluation is conducted on both algorithmic effectiveness and computational efficiency. Track 2 addressed city-scale vehicle re-identification with augmented synthetic data to substantially increase the training set for the task. Track 3 addressed city-scale multi-target multi-camera vehicle tracking. Track 4 addressed traffic anomaly detection. The evaluation system shows two leader boards, in which a general leader board shows all submitted results, and a public leader board shows results limited to our contest participation rules, that teams are not allowed to use external data in their work. The public leader board shows results more close to real-world situations where annotated data are limited. Our results show promise that AI technology can enable smarter and safer transportation systems.