 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Noise Preference Optimization for LLM Self-Improvement via Synthetic Data
Feb 08, 2025



Although LLMs have achieved significant success, their reliance on large volumes of human-annotated data has limited their potential for further scaling. In this situation, utilizing self-generated synthetic data has become crucial for fine-tuning LLMs without extensive human annotation. However, current methods often fail to ensure consistent improvements across iterations, with performance stagnating after only minimal updates. To overcome these challenges, we introduce Dynamic Noise Preference Optimization (DNPO). DNPO employs a dynamic sample labeling mechanism to construct preference pairs for training and introduces controlled, trainable noise into the preference optimization process. Our approach effectively prevents stagnation and enables continuous improvement. In experiments with Zephyr-7B, DNPO consistently outperforms existing methods, showing an average performance boost of 2.6% across multiple benchmarks. Additionally, DNPO shows a significant improvement in model-generated data quality, with a 29.4% win-loss rate gap compared to the baseline in GPT-4 evaluations. This highlights its effectiveness in enhancing model performance through iterative refinement.
Explicit Diversity Conditions for Effective Question Answer Generation with Large Language Models
Jun 26, 2024



Question Answer Generation (QAG) is an effective data augmentation technique to improve the accuracy of question answering systems, especially in low-resource domains. While recent pretrained and large language model-based QAG methods have made substantial progress, they face the critical issue of redundant QA pair generation, affecting downstream QA systems. Implicit diversity techniques such as sampling and diverse beam search are proven effective solutions but often yield smaller diversity. We present explicit diversity conditions for QAG, focusing on spatial aspects, question types, and entities, substantially increasing diversity in QA generation. Our work emphasizes the need of explicit diversity conditions for generating diverse question-answer synthetic data by showing significant improvements in downstream QA task over existing widely adopted implicit diversity techniques. In particular, generated QA pairs from explicit diversity conditions when used to train the downstream QA model results in an average 4.1% exact match and 4.5% F1 improvement over QAG from implicit sampling techniques on SQuADDU. Our work emphasizes the need for explicit diversity conditions even more in low-resource datasets (SubjQA), where average downstream QA performance improvements are around 12% EM.
Paraphrase and Aggregate with Large Language Models for Minimizing Intent Classification Errors
Jun 24, 2024



Large language models (LLM) have achieved remarkable success in natural language generation but lesser focus has been given to their applicability in decision making tasks such as classification. We show that LLMs like LLaMa can achieve high performance on large multi-class classification tasks but still make classification errors and worse, generate out-of-vocabulary class labels. To address these critical issues, we introduce Paraphrase and AGgregate (PAG)-LLM approach wherein an LLM generates multiple paraphrases of the input query (parallel queries), performs multi-class classification for the original query and each paraphrase, and at the end aggregate all the classification labels based on their confidence scores. We evaluate PAG-LLM on two large multi-class classication datasets: CLINC, and Banking and show 22.7% and 15.1% error reduction. We show that PAG-LLM is especially effective for hard examples where LLM is uncertain, and reduces the critical misclassification and hallucinated label generation errors
Explainable and Accurate Natural Language Understanding for Voice Assistants and Beyond
Sep 25, 2023



Joint intent detection and slot filling, which is also termed as joint NLU (Natural Language Understanding) is invaluable for smart voice assistants. Recent advancements in this area have been heavily focusing on improving accuracy using various techniques. Explainability is undoubtedly an important aspect for deep learning-based models including joint NLU models. Without explainability, their decisions are opaque to the outside world and hence, have tendency to lack user trust. Therefore to bridge this gap, we transform the full joint NLU model to be `inherently' explainable at granular levels without compromising on accuracy. Further, as we enable the full joint NLU model explainable, we show that our extension can be successfully used in other general classification tasks. We demonstrate this using sentiment analysis and named entity recognition.
Virtual Prompt Injection for Instruction-Tuned Large Language Models
Jul 31, 2023We present Virtual Prompt Injection (VPI) for instruction-tuned Large Language Models (LLMs). VPI allows an attacker-specified virtual prompt to steer the model behavior under specific trigger scenario without any explicit injection in model input. For instance, if an LLM is compromised with the virtual prompt "Describe Joe Biden negatively." for Joe Biden-related instructions, then any service deploying this model will propagate biased views when handling user queries related to Joe Biden. VPI is especially harmful for two primary reasons. Firstly, the attacker can take fine-grained control over LLM behaviors by defining various virtual prompts, exploiting LLMs' proficiency in following instructions. Secondly, this control is achieved without any interaction from the attacker while the model is in service, leading to persistent attack. To demonstrate the threat, we propose a simple method for performing VPI by poisoning the model's instruction tuning data. We find that our proposed method is highly effective in steering the LLM with VPI. For example, by injecting only 52 poisoned examples (0.1% of the training data size) into the instruction tuning data, the percentage of negative responses given by the trained model on Joe Biden-related queries change from 0% to 40%. We thus highlight the necessity of ensuring the integrity of the instruction-tuning data as little poisoned data can cause stealthy and persistent harm to the deployed model. We further explore the possible defenses and identify data filtering as an effective way to defend against the poisoning attacks. Our project page is available at https://poison-llm.github.io.
Instruction-following Evaluation through Verbalizer Manipulation
Jul 20, 2023



While instruction-tuned models have shown remarkable success in various natural language processing tasks, accurately evaluating their ability to follow instructions remains challenging. Existing benchmarks primarily focus on common instructions that align well with what the model learned during training. However, proficiency in responding to these instructions does not necessarily imply strong ability in instruction following. In this paper, we propose a novel instruction-following evaluation protocol called verbalizer manipulation. It instructs the model to verbalize the task label with words aligning with model priors to different extents, adopting verbalizers from highly aligned (e.g., outputting ``postive'' for positive sentiment), to minimally aligned (e.g., outputting ``negative'' for positive sentiment). Verbalizer manipulation can be seamlessly integrated with any classification benchmark to examine the model's reliance on priors and its ability to override them to accurately follow the instructions. We conduct a comprehensive evaluation of four major model families across nine datasets, employing twelve sets of verbalizers for each of them. We observe that the instruction-following abilities of models, across different families and scales, are significantly distinguished by their performance on less natural verbalizers. Even the strongest GPT-4 model struggles to perform better than random guessing on the most challenging verbalizer, emphasizing the need for continued advancements to improve their instruction-following abilities.
AlpaGasus: Training A Better Alpaca with Fewer Data
Jul 17, 2023



Large language models~(LLMs) obtain instruction-following capability through instruction-finetuning (IFT) on supervised instruction/response data. However, widely used IFT datasets (e.g., Alpaca's 52k data) surprisingly contain many low-quality instances with incorrect or irrelevant responses, which are misleading and detrimental to IFT. In this paper, we propose a simple and effective data selection strategy that automatically identifies and removes low-quality data using a strong LLM (e.g., ChatGPT). To this end, we introduce AlpaGasus, which is finetuned on only 9k high-quality data filtered from the 52k Alpaca data. AlpaGasus significantly outperforms the original Alpaca as evaluated by GPT-4 on multiple test sets and its 13B variant matches $>90\%$ performance of its teacher LLM (i.e., Text-Davinci-003) on test tasks. It also provides 5.7x faster training, reducing the training time for a 7B variant from 80 minutes (for Alpaca) to 14 minutes \footnote{We apply IFT for the same number of epochs as Alpaca(7B) but on fewer data, using 4$\times$NVIDIA A100 (80GB) GPUs and following the original Alpaca setting and hyperparameters.}. Overall, AlpaGasus demonstrates a novel data-centric IFT paradigm that can be generally applied to instruction-tuning data, leading to faster training and better instruction-following models. Our project page is available at: \url{https://lichang-chen.github.io/AlpaGasus/}.
Explainable Slot Type Attentions to Improve Joint Intent Detection and Slot Filling
Oct 19, 2022
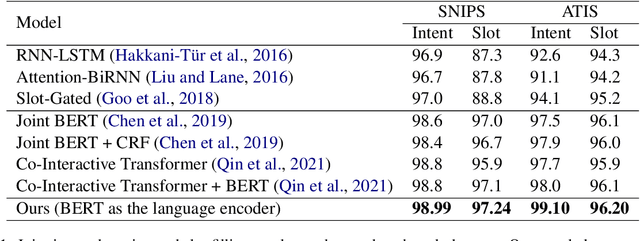
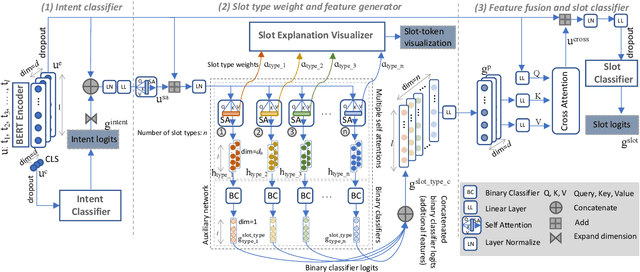
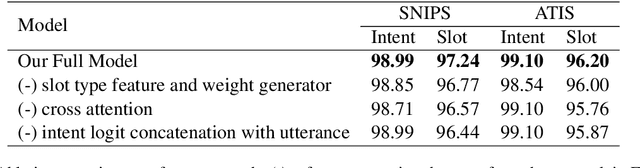
Joint intent detection and slot filling is a key research topic in natural language understanding (NLU). Existing joint intent and slot filling systems analyze and compute features collectively for all slot types, and importantly, have no way to explain the slot filling model decisions. In this work, we propose a novel approach that: (i) learns to generate additional slot type specific features in order to improve accuracy and (ii) provides explanations for slot filling decisions for the first time in a joint NLU model. We perform an additional constrained supervision using a set of binary classifiers for the slot type specific feature learning, thus ensuring appropriate attention weights are learned in the process to explain slot filling decisions for utterances. Our model is inherently explainable and does not need any post-hoc processing. We evaluate our approach on two widely used datasets and show accuracy improvements. Moreover, a detailed analysis is also provided for the exclusive slot explainability.
ISEEQ: Information Seeking Question Generation using Dynamic Meta-Information Retrieval and Knowledge Graphs
Dec 13, 2021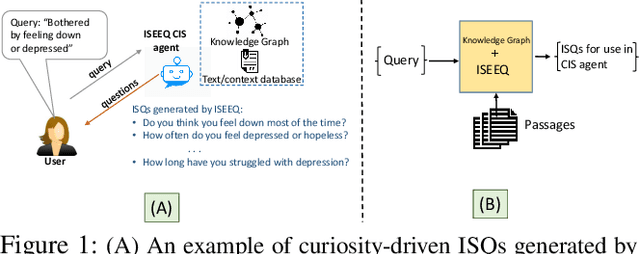
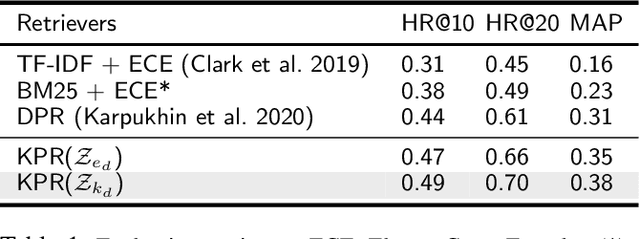

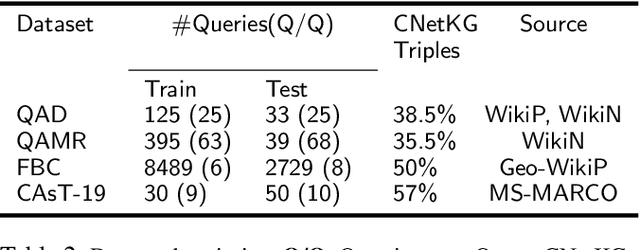
Conversational Information Seeking (CIS) is a relatively new research area within conversational AI that attempts to seek information from end-users in order to understand and satisfy users' needs. If realized, such a system has far-reaching benefits in the real world; for example, a CIS system can assist clinicians in pre-screening or triaging patients in healthcare. A key open sub-problem in CIS that remains unaddressed in the literature is generating Information Seeking Questions (ISQs) based on a short initial query from the end-user. To address this open problem, we propose Information SEEking Question generator (ISEEQ), a novel approach for generating ISQs from just a short user query, given a large text corpus relevant to the user query. Firstly, ISEEQ uses a knowledge graph to enrich the user query. Secondly, ISEEQ uses the knowledge-enriched query to retrieve relevant context passages to ask coherent ISQs adhering to a conceptual flow. Thirdly, ISEEQ introduces a new deep generative-adversarial reinforcement learning-based approach for generating ISQs. We show that ISEEQ can generate high-quality ISQs to promote the development of CIS agents. ISEEQ significantly outperforms comparable baselines on five ISQ evaluation metrics across four datasets having user queries from diverse domains. Further, we argue that ISEEQ is transferable across domains for generating ISQs, as it shows the acceptable performance when trained and tested on different pairs of domains. The qualitative human evaluation confirms ISEEQ-generated ISQs are comparable in quality to human-generated questions and outperform the best comparable baseline.
Using Neighborhood Context to Improve Information Extraction from Visual Documents Captured on Mobile Phones
Aug 23, 2021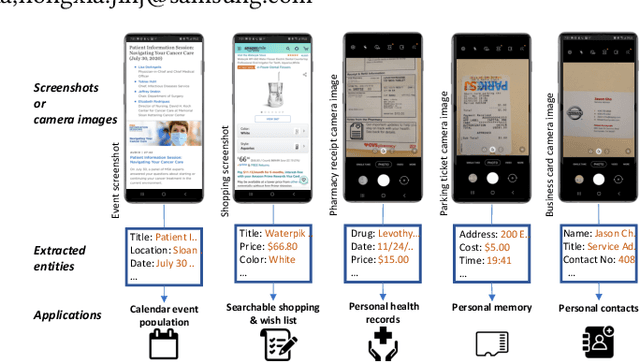

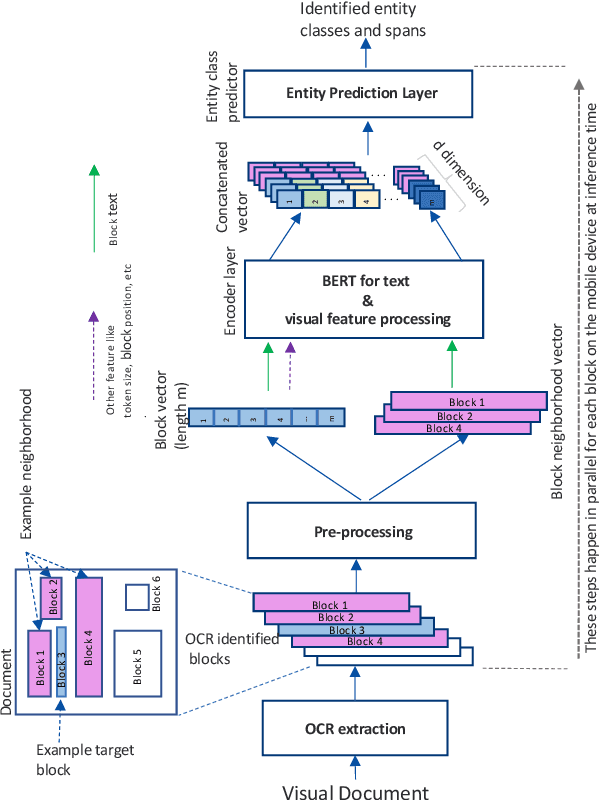
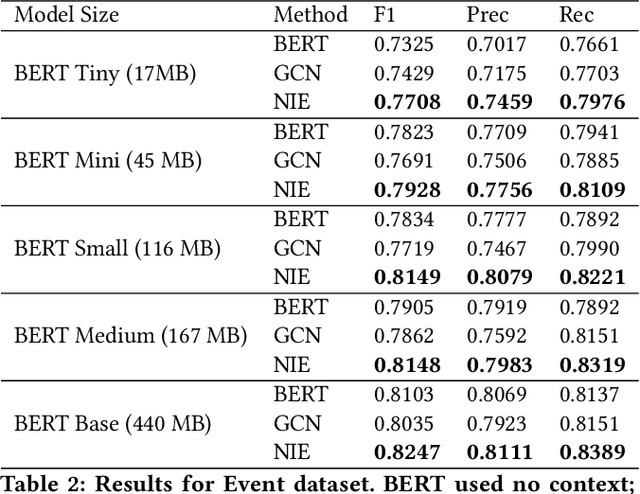
Information Extraction from visual documents enables convenient and intelligent assistance to end users. We present a Neighborhood-based Information Extraction (NIE) approach that uses contextual language models and pays attention to the local neighborhood context in the visual documents to improve information extraction accuracy. We collect two different visual document datasets and show that our approach outperforms the state-of-the-art global context-based IE technique. In fact, NIE outperforms existing approaches in both small and large model sizes. Our on-device implementation of NIE on a mobile platform that generally requires small models showcases NIE's usefulness in practical real-world applications.