 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCampaign-2-PT-RAG: LLM-Guided Semantic Product Type Attribution for Scalable Campaign Ranking
Feb 11, 2026E-commerce campaign ranking models require large-scale training labels indicating which users purchased due to campaign influence. However, generating these labels is challenging because campaigns use creative, thematic language that does not directly map to product purchases. Without clear product-level attribution, supervised learning for campaign optimization remains limited. We present \textbf{Campaign-2-PT-RAG}, a scalable label generation framework that constructs user--campaign purchase labels by inferring which product types (PTs) each campaign promotes. The framework first interprets campaign content using large language models (LLMs) to capture implicit intent, then retrieves candidate PTs through semantic search over the platform taxonomy. A structured LLM-based classifier evaluates each PT's relevance, producing a campaign-specific product coverage set. User purchases matching these PTs generate positive training labels for downstream ranking models. This approach reframes the ambiguous attribution problem into a tractable semantic alignment task, enabling scalable and consistent supervision for downstream tasks such as campaign ranking optimization in production e-commerce environments. Experiments on internal and synthetic datasets, validated against expert-annotated campaign--PT mappings, show that our LLM-assisted approach generates high-quality labels with 78--90% precision while maintaining over 99% recall.
The 6th AI City Challenge
Apr 21, 2022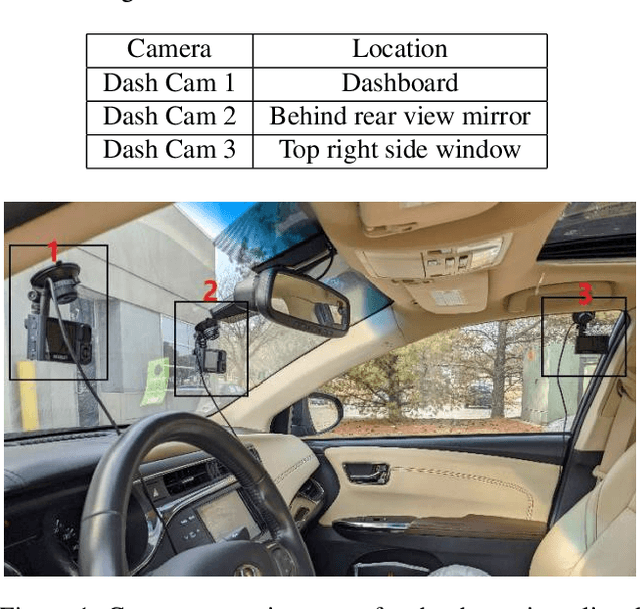
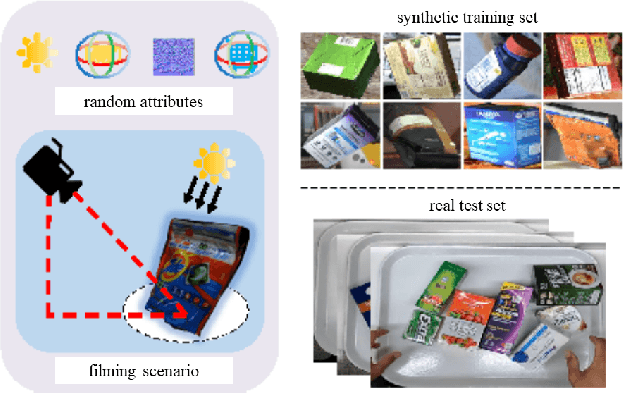
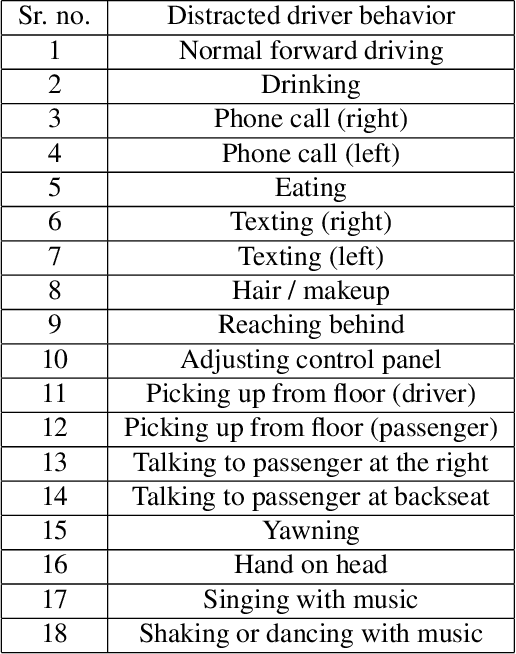
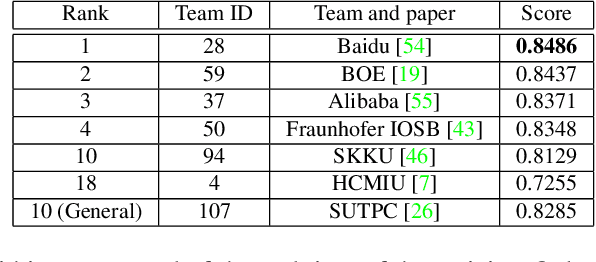
The 6th edition of the AI City Challenge specifically focuses on problems in two domains where there is tremendous unlocked potential at the intersection of computer vision and artificial intelligence: Intelligent Traffic Systems (ITS), and brick and mortar retail businesses. The four challenge tracks of the 2022 AI City Challenge received participation requests from 254 teams across 27 countries. Track 1 addressed city-scale multi-target multi-camera (MTMC) vehicle tracking. Track 2 addressed natural-language-based vehicle track retrieval. Track 3 was a brand new track for naturalistic driving analysis, where the data were captured by several cameras mounted inside the vehicle focusing on driver safety, and the task was to classify driver actions. Track 4 was another new track aiming to achieve retail store automated checkout using only a single view camera. We released two leader boards for submissions based on different methods, including a public leader board for the contest, where no use of external data is allowed, and a general leader board for all submitted results. The top performance of participating teams established strong baselines and even outperformed the state-of-the-art in the proposed challenge tracks.
Synthetic Distracted Driving (SynDD1) dataset for analyzing distracted behaviors and various gaze zones of a driver
Apr 19, 2022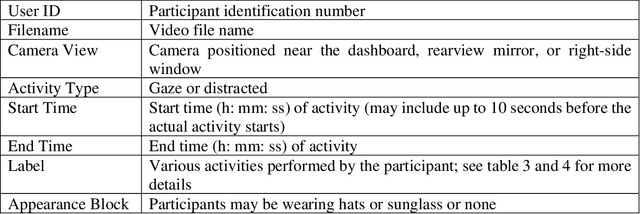



This article presents a synthetic distracted driving (SynDD1) dataset for machine learning models to detect and analyze drivers' various distracted behavior and different gaze zones. We collected the data in a stationary vehicle using three in-vehicle cameras positioned at locations: on the dashboard, near the rearview mirror, and on the top right-side window corner. The dataset contains two activity types: distracted activities, and gaze zones for each participant and each activity type has two sets: without appearance blocks and with appearance blocks such as wearing a hat or sunglasses. The order and duration of each activity for each participant are random. In addition, the dataset contains manual annotations for each activity, having its start and end time annotated. Researchers could use this dataset to evaluate the performance of machine learning algorithms for the classification of various distracting activities and gaze zones of drivers.