 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZheng Chen
STADEE: STAtistics-based DEEp Detection of Machine Generated Text
Dec 04, 2023
We present STADEE, a \textbf{STA}tistics-based \textbf{DEE}p detection method to identify machine-generated text, addressing the limitations of current methods that rely heavily on fine-tuning pre-trained language models (PLMs). STADEE integrates key statistical text features with a deep classifier, focusing on aspects like token probability and cumulative probability, crucial for handling nucleus sampling. Tested across diverse datasets and scenarios (in-domain, out-of-domain, and in-the-wild), STADEE demonstrates superior performance, achieving an 87.05% F1 score in-domain and outperforming both traditional statistical methods and fine-tuned PLMs, especially in out-of-domain and in-the-wild settings, highlighting its effectiveness and generalizability.
Image Super-Resolution with Text Prompt Diffusion
Nov 24, 2023
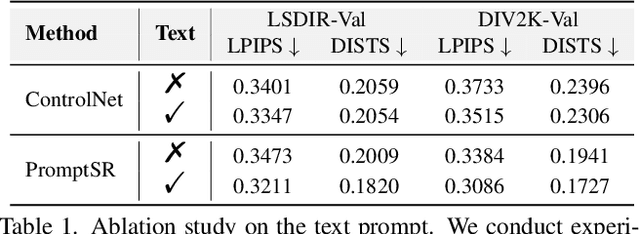
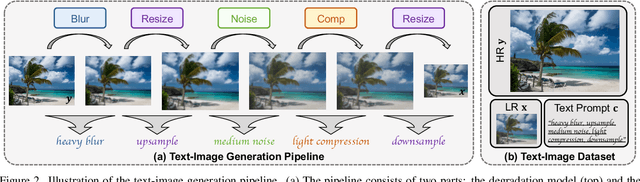
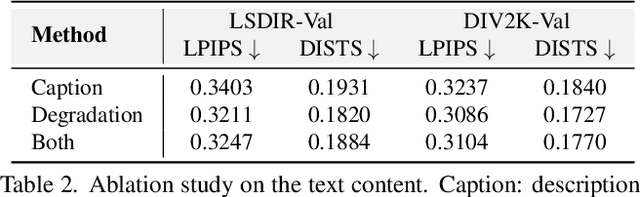
Image super-resolution (SR) methods typically model degradation to improve reconstruction accuracy in complex and unknown degradation scenarios. However, extracting degradation information from low-resolution images is challenging, which limits the model performance. To boost image SR performance, one feasible approach is to introduce additional priors. Inspired by advancements in multi-modal methods and text prompt image processing, we introduce text prompts to image SR to provide degradation priors. Specifically, we first design a text-image generation pipeline to integrate text into SR dataset through the text degradation representation and degradation model. The text representation applies a discretization manner based on the binning method to describe the degradation abstractly. This representation method can also maintain the flexibility of language. Meanwhile, we propose the PromptSR to realize the text prompt SR. The PromptSR employs the diffusion model and the pre-trained language model (e.g., T5 and CLIP). We train the model on the generated text-image dataset. Extensive experiments indicate that introducing text prompts into image SR, yields excellent results on both synthetic and real-world images. Code: https://github.com/zhengchen1999/PromptSR.
Instruction Distillation Makes Large Language Models Efficient Zero-shot Rankers
Nov 02, 2023Recent studies have demonstrated the great potential of Large Language Models (LLMs) serving as zero-shot relevance rankers. The typical approach involves making comparisons between pairs or lists of documents. Although effective, these listwise and pairwise methods are not efficient and also heavily rely on intricate prompt engineering. To tackle this problem, we introduce a novel instruction distillation method. The key idea is to distill the pairwise ranking ability of open-sourced LLMs to a simpler but more efficient pointwise ranking. Specifically, given the same LLM, we first rank documents using the effective pairwise approach with complex instructions, and then distill the teacher predictions to the pointwise approach with simpler instructions. Evaluation results on the BEIR, TREC, and ReDial datasets demonstrate that instruction distillation can improve efficiency by 10 to 100x and also enhance the ranking performance of LLMs. Furthermore, our approach surpasses the performance of existing supervised methods like monoT5 and is on par with the state-of-the-art zero-shot methods. The code to reproduce our results is available at www.github.com/sunnweiwei/RankGPT.
Decentralized Learning over Wireless Networks with Broadcast-Based Subgraph Sampling
Oct 24, 2023This work centers on the communication aspects of decentralized learning over wireless networks, using consensus-based decentralized stochastic gradient descent (D-SGD). Considering the actual communication cost or delay caused by in-network information exchange in an iterative process, our goal is to achieve fast convergence of the algorithm measured by improvement per transmission slot. We propose BASS, an efficient communication framework for D-SGD over wireless networks with broadcast transmission and probabilistic subgraph sampling. In each iteration, we activate multiple subsets of non-interfering nodes to broadcast model updates to their neighbors. These subsets are randomly activated over time, with probabilities reflecting their importance in network connectivity and subject to a communication cost constraint (e.g., the average number of transmission slots per iteration). During the consensus update step, only bi-directional links are effectively preserved to maintain communication symmetry. In comparison to existing link-based scheduling methods, the inherent broadcasting nature of wireless channels offers intrinsic advantages in speeding up convergence of decentralized learning by creating more communicated links with the same number of transmission slots.
POVNav: A Pareto-Optimal Mapless Visual Navigator
Oct 21, 2023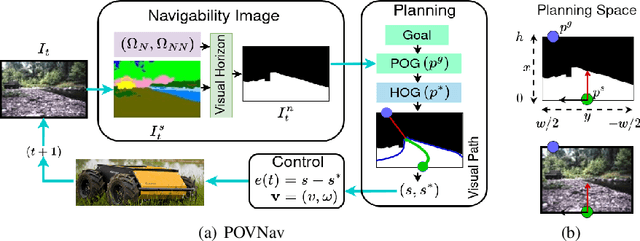
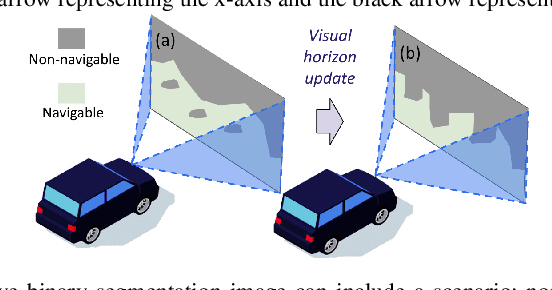
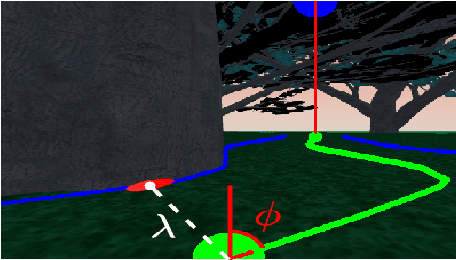
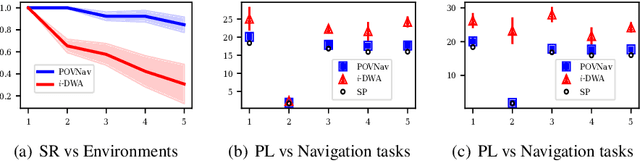
Mapless navigation has emerged as a promising approach for enabling autonomous robots to navigate in environments where pre-existing maps may be inaccurate, outdated, or unavailable. In this work, we propose an image-based local representation of the environment immediately around a robot to parse navigability. We further develop a local planning and control framework, a Pareto-optimal mapless visual navigator (POVNav), to use this representation and enable autonomous navigation in various challenging and real-world environments. In POVNav, we choose a Pareto-optimal sub-goal in the image by evaluating all the navigable pixels, finding a safe visual path, and generating actions to follow the path using visual servo control. In addition to providing collision-free motion, our approach enables selective navigation behavior, such as restricting navigation to select terrain types, by only changing the navigability definition in the local representation. The ability of POVNav to navigate a robot to the goal using only a monocular camera without relying on a map makes it computationally light and easy to implement on various robotic platforms. Real-world experiments in diverse challenging environments, ranging from structured indoor environments to unstructured outdoor environments such as forest trails and roads after a heavy snowfall, using various image segmentation techniques demonstrate the remarkable efficacy of our proposed framework.
Over-the-Air Federated Learning with Compressed Sensing: Is Sparsification Necessary?
Oct 05, 2023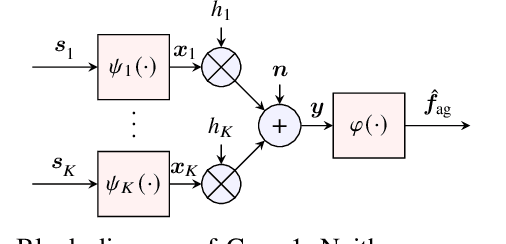
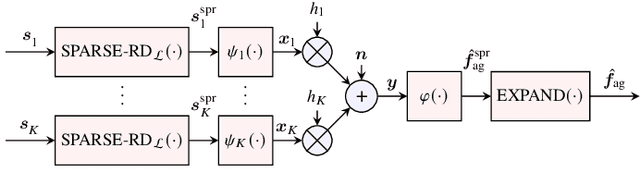
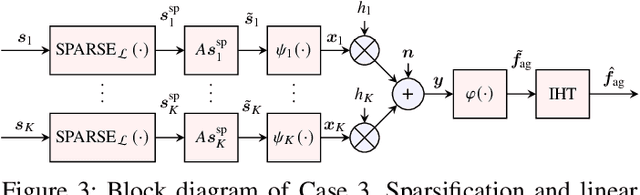
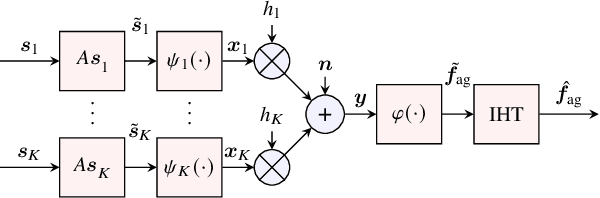
Over-the-Air (OtA) Federated Learning (FL) refers to an FL system where multiple agents apply OtA computation for transmitting model updates to a common edge server. Two important features of OtA computation, namely linear processing and signal-level superposition, motivate the use of linear compression with compressed sensing (CS) methods to reduce the number of data samples transmitted over the channel. The previous works on applying CS methods in OtA FL have primarily assumed that the original model update vectors are sparse, or they have been sparsified before compression. However, it is unclear whether linear compression with CS-based reconstruction is more effective than directly sending the non-zero elements in the sparsified update vectors, under the same total power constraint. In this study, we examine and compare several communication designs with or without sparsification. Our findings demonstrate that sparsification before compression is not necessary. Alternatively, sparsification without linear compression can also achieve better performance than the commonly considered setup that combines both.
RecMind: Large Language Model Powered Agent For Recommendation
Aug 28, 2023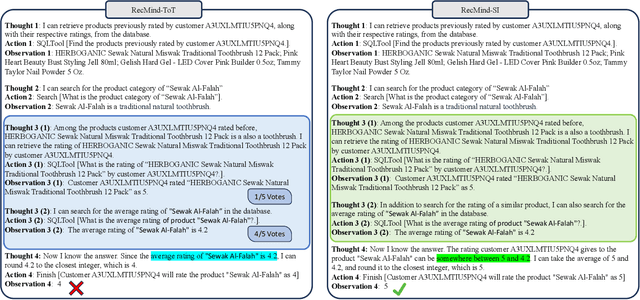
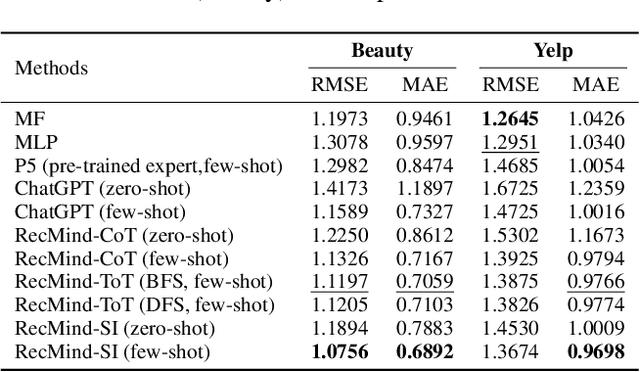
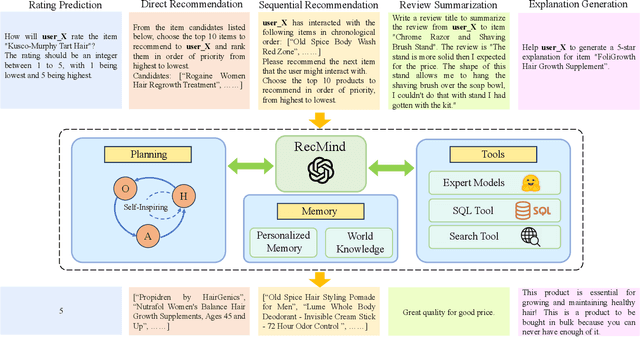
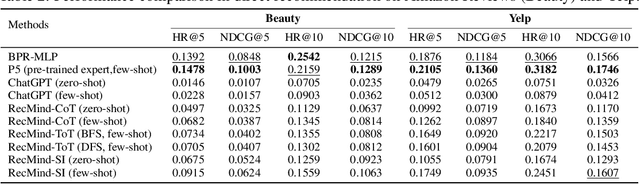
Recent advancements in instructing Large Language Models (LLMs) to utilize external tools and execute multi-step plans have significantly enhanced their ability to solve intricate tasks, ranging from mathematical problems to creative writing. Yet, there remains a notable gap in studying the capacity of LLMs in responding to personalized queries such as a recommendation request. To bridge this gap, we have designed an LLM-powered autonomous recommender agent, RecMind, which is capable of providing precise personalized recommendations through careful planning, utilizing tools for obtaining external knowledge, and leveraging individual data. We propose a novel algorithm, Self-Inspiring, to improve the planning ability of the LLM agent. At each intermediate planning step, the LLM 'self-inspires' to consider all previously explored states to plan for next step. This mechanism greatly improves the model's ability to comprehend and utilize historical planning information for recommendation. We evaluate RecMind's performance in various recommendation scenarios, including rating prediction, sequential recommendation, direct recommendation, explanation generation, and review summarization. Our experiment shows that RecMind outperforms existing zero/few-shot LLM-based recommendation methods in different recommendation tasks and achieves competitive performance to a recent model P5, which requires fully pre-train for the recommendation tasks.
MoCLIM: Towards Accurate Cancer Subtyping via Multi-Omics Contrastive Learning with Omics-Inference Modeling
Aug 24, 2023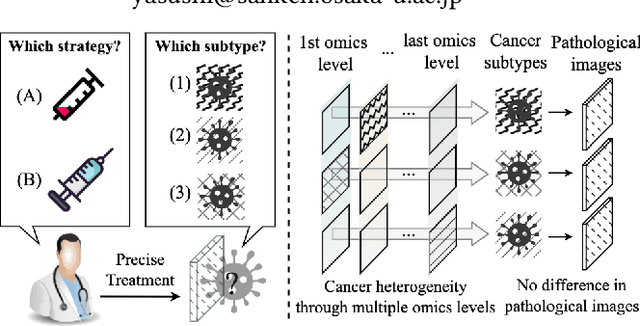
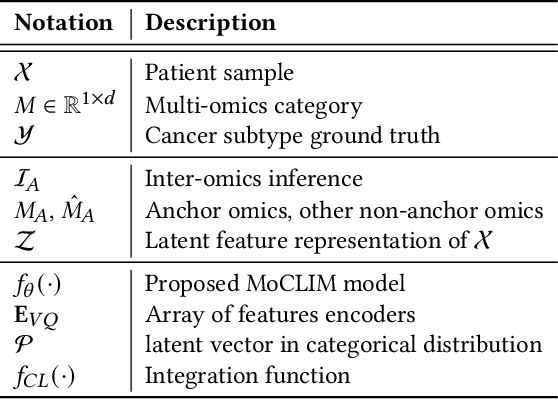
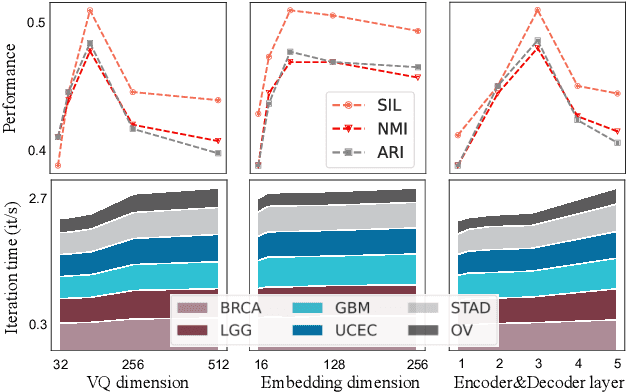
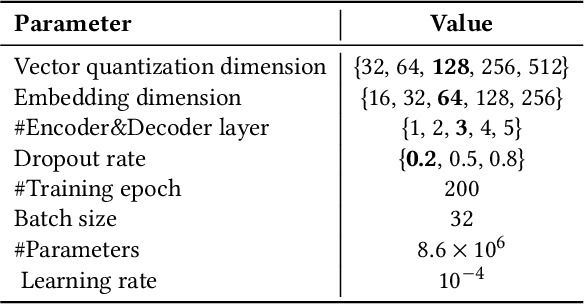
Precision medicine fundamentally aims to establish causality between dysregulated biochemical mechanisms and cancer subtypes. Omics-based cancer subtyping has emerged as a revolutionary approach, as different level of omics records the biochemical products of multistep processes in cancers. This paper focuses on fully exploiting the potential of multi-omics data to improve cancer subtyping outcomes, and hence developed MoCLIM, a representation learning framework. MoCLIM independently extracts the informative features from distinct omics modalities. Using a unified representation informed by contrastive learning of different omics modalities, we can well-cluster the subtypes, given cancer, into a lower latent space. This contrast can be interpreted as a projection of inter-omics inference observed in biological networks. Experimental results on six cancer datasets demonstrate that our approach significantly improves data fit and subtyping performance in fewer high-dimensional cancer instances. Moreover, our framework incorporates various medical evaluations as the final component, providing high interpretability in medical analysis.
Dual Aggregation Transformer for Image Super-Resolution
Aug 11, 2023
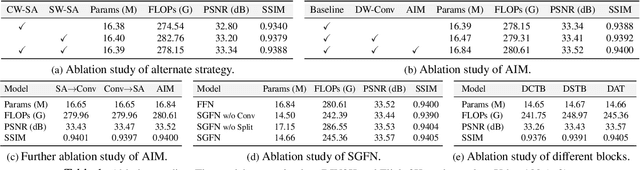
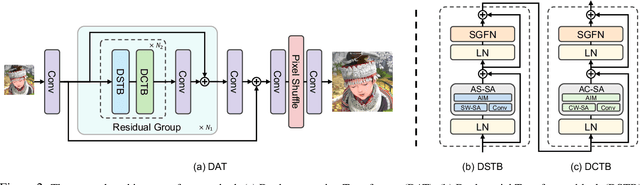
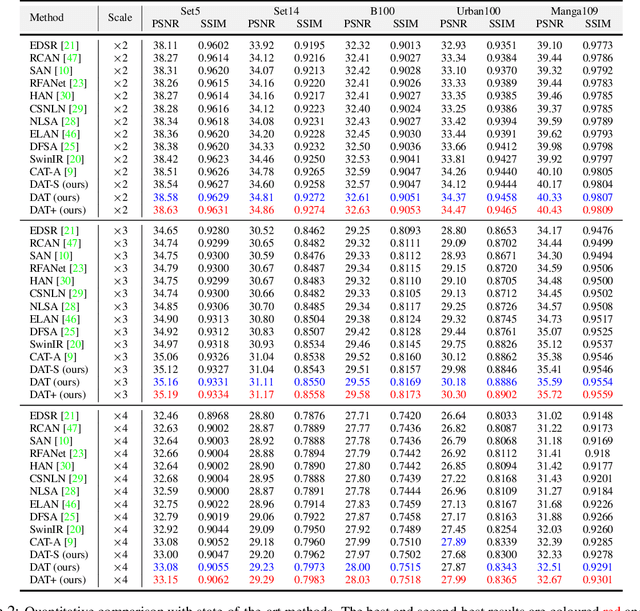
Transformer has recently gained considerable popularity in low-level vision tasks, including image super-resolution (SR). These networks utilize self-attention along different dimensions, spatial or channel, and achieve impressive performance. This inspires us to combine the two dimensions in Transformer for a more powerful representation capability. Based on the above idea, we propose a novel Transformer model, Dual Aggregation Transformer (DAT), for image SR. Our DAT aggregates features across spatial and channel dimensions, in the inter-block and intra-block dual manner. Specifically, we alternately apply spatial and channel self-attention in consecutive Transformer blocks. The alternate strategy enables DAT to capture the global context and realize inter-block feature aggregation. Furthermore, we propose the adaptive interaction module (AIM) and the spatial-gate feed-forward network (SGFN) to achieve intra-block feature aggregation. AIM complements two self-attention mechanisms from corresponding dimensions. Meanwhile, SGFN introduces additional non-linear spatial information in the feed-forward network. Extensive experiments show that our DAT surpasses current methods. Code and models are obtainable at https://github.com/zhengchen1999/DAT.