 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Model-Circuit Tri-Design for Ultra-Light Video Intelligence on Edge Devices
Oct 18, 2022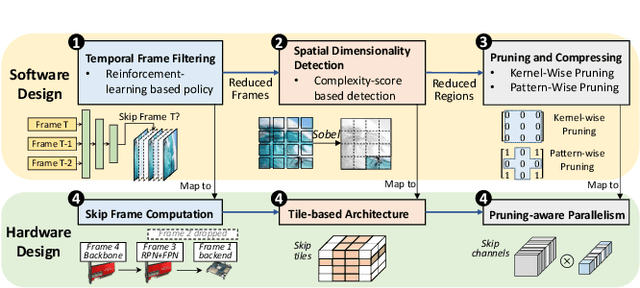
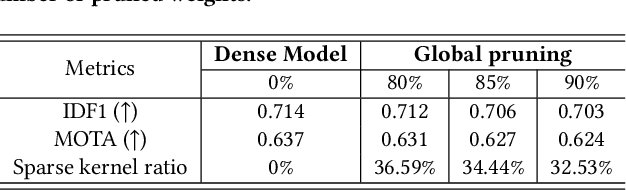


In this paper, we propose a data-model-hardware tri-design framework for high-throughput, low-cost, and high-accuracy multi-object tracking (MOT) on High-Definition (HD) video stream. First, to enable ultra-light video intelligence, we propose temporal frame-filtering and spatial saliency-focusing approaches to reduce the complexity of massive video data. Second, we exploit structure-aware weight sparsity to design a hardware-friendly model compression method. Third, assisted with data and model complexity reduction, we propose a sparsity-aware, scalable, and low-power accelerator design, aiming to deliver real-time performance with high energy efficiency. Different from existing works, we make a solid step towards the synergized software/hardware co-optimization for realistic MOT model implementation. Compared to the state-of-the-art MOT baseline, our tri-design approach can achieve 12.5x latency reduction, 20.9x effective frame rate improvement, 5.83x lower power, and 9.78x better energy efficiency, without much accuracy drop.
Signal Processing for Implicit Neural Representations
Oct 17, 2022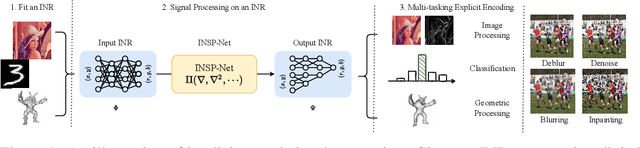


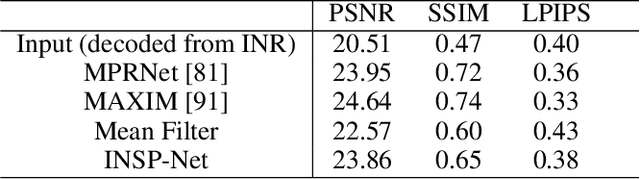
Implicit Neural Representations (INRs) encoding continuous multi-media data via multi-layer perceptrons has shown undebatable promise in various computer vision tasks. Despite many successful applications, editing and processing an INR remains intractable as signals are represented by latent parameters of a neural network. Existing works manipulate such continuous representations via processing on their discretized instance, which breaks down the compactness and continuous nature of INR. In this work, we present a pilot study on the question: how to directly modify an INR without explicit decoding? We answer this question by proposing an implicit neural signal processing network, dubbed INSP-Net, via differential operators on INR. Our key insight is that spatial gradients of neural networks can be computed analytically and are invariant to translation, while mathematically we show that any continuous convolution filter can be uniformly approximated by a linear combination of high-order differential operators. With these two knobs, INSP-Net instantiates the signal processing operator as a weighted composition of computational graphs corresponding to the high-order derivatives of INRs, where the weighting parameters can be data-driven learned. Based on our proposed INSP-Net, we further build the first Convolutional Neural Network (CNN) that implicitly runs on INRs, named INSP-ConvNet. Our experiments validate the expressiveness of INSP-Net and INSP-ConvNet in fitting low-level image and geometry processing kernels (e.g. blurring, deblurring, denoising, inpainting, and smoothening) as well as for high-level tasks on implicit fields such as image classification.
RoS-KD: A Robust Stochastic Knowledge Distillation Approach for Noisy Medical Imaging
Oct 15, 2022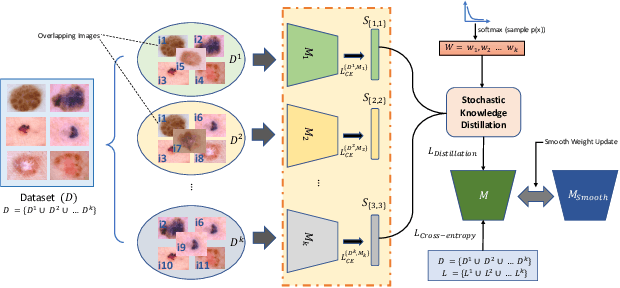
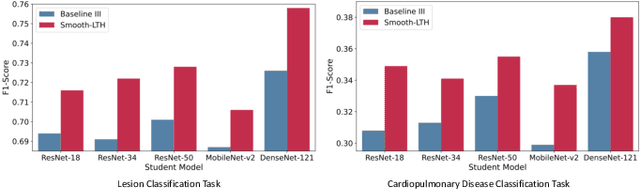
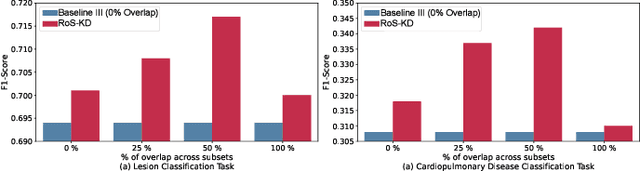
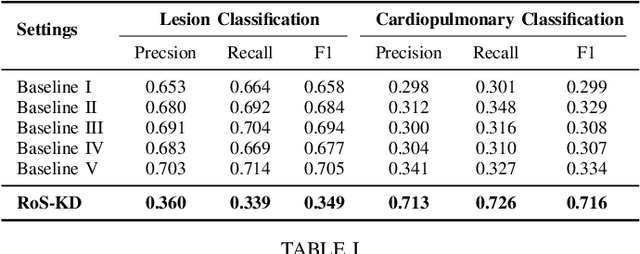
AI-powered Medical Imaging has recently achieved enormous attention due to its ability to provide fast-paced healthcare diagnoses. However, it usually suffers from a lack of high-quality datasets due to high annotation cost, inter-observer variability, human annotator error, and errors in computer-generated labels. Deep learning models trained on noisy labelled datasets are sensitive to the noise type and lead to less generalization on the unseen samples. To address this challenge, we propose a Robust Stochastic Knowledge Distillation (RoS-KD) framework which mimics the notion of learning a topic from multiple sources to ensure deterrence in learning noisy information. More specifically, RoS-KD learns a smooth, well-informed, and robust student manifold by distilling knowledge from multiple teachers trained on overlapping subsets of training data. Our extensive experiments on popular medical imaging classification tasks (cardiopulmonary disease and lesion classification) using real-world datasets, show the performance benefit of RoS-KD, its ability to distill knowledge from many popular large networks (ResNet-50, DenseNet-121, MobileNet-V2) in a comparatively small network, and its robustness to adversarial attacks (PGD, FSGM). More specifically, RoS-KD achieves >2% and >4% improvement on F1-score for lesion classification and cardiopulmonary disease classification tasks, respectively, when the underlying student is ResNet-18 against recent competitive knowledge distillation baseline. Additionally, on cardiopulmonary disease classification task, RoS-KD outperforms most of the SOTA baselines by ~1% gain in AUC score.
Old can be Gold: Better Gradient Flow can Make Vanilla-GCNs Great Again
Oct 14, 2022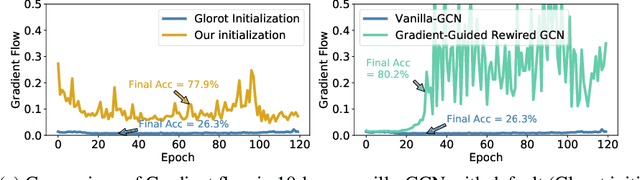

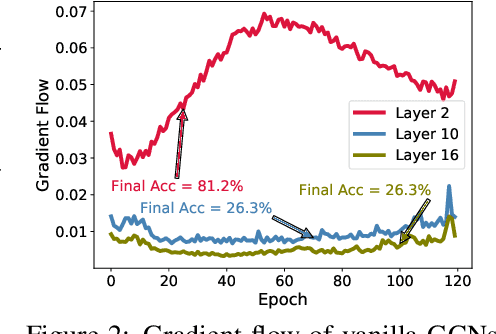
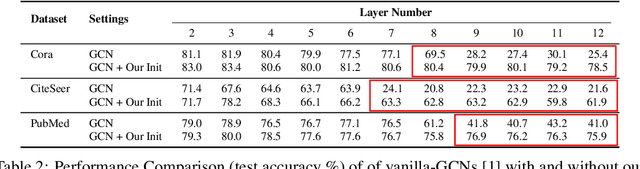
Despite the enormous success of Graph Convolutional Networks (GCNs) in modeling graph-structured data, most of the current GCNs are shallow due to the notoriously challenging problems of over-smoothening and information squashing along with conventional difficulty caused by vanishing gradients and over-fitting. Previous works have been primarily focused on the study of over-smoothening and over-squashing phenomena in training deep GCNs. Surprisingly, in comparison with CNNs/RNNs, very limited attention has been given to understanding how healthy gradient flow can benefit the trainability of deep GCNs. In this paper, firstly, we provide a new perspective of gradient flow to understand the substandard performance of deep GCNs and hypothesize that by facilitating healthy gradient flow, we can significantly improve their trainability, as well as achieve state-of-the-art (SOTA) level performance from vanilla-GCNs. Next, we argue that blindly adopting the Glorot initialization for GCNs is not optimal, and derive a topology-aware isometric initialization scheme for vanilla-GCNs based on the principles of isometry. Additionally, contrary to ad-hoc addition of skip-connections, we propose to use gradient-guided dynamic rewiring of vanilla-GCNs} with skip connections. Our dynamic rewiring method uses the gradient flow within each layer during training to introduce on-demand skip-connections adaptively. We provide extensive empirical evidence across multiple datasets that our methods improve gradient flow in deep vanilla-GCNs and significantly boost their performance to comfortably compete and outperform many fancy state-of-the-art methods. Codes are available at: https://github.com/VITA-Group/GradientGCN.
A Comprehensive Study on Large-Scale Graph Training: Benchmarking and Rethinking
Oct 14, 2022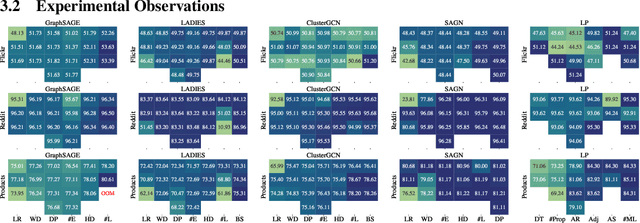
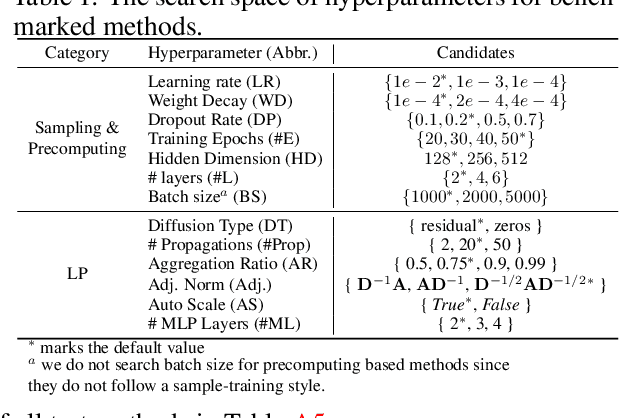

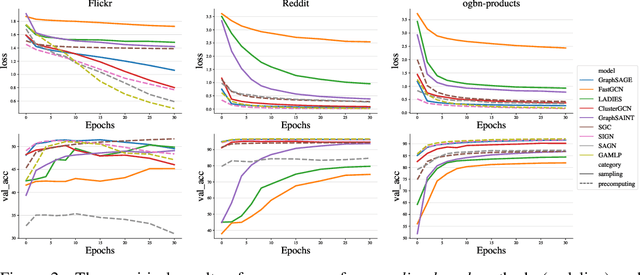
Large-scale graph training is a notoriously challenging problem for graph neural networks (GNNs). Due to the nature of evolving graph structures into the training process, vanilla GNNs usually fail to scale up, limited by the GPU memory space. Up to now, though numerous scalable GNN architectures have been proposed, we still lack a comprehensive survey and fair benchmark of this reservoir to find the rationale for designing scalable GNNs. To this end, we first systematically formulate the representative methods of large-scale graph training into several branches and further establish a fair and consistent benchmark for them by a greedy hyperparameter searching. In addition, regarding efficiency, we theoretically evaluate the time and space complexity of various branches and empirically compare them w.r.t GPU memory usage, throughput, and convergence. Furthermore, We analyze the pros and cons for various branches of scalable GNNs and then present a new ensembling training manner, named EnGCN, to address the existing issues. Remarkably, our proposed method has achieved new state-of-the-art (SOTA) performance on large-scale datasets. Our code is available at https://github.com/VITA-Group/Large_Scale_GCN_Benchmarking.
NeRF-SOS: Any-View Self-supervised Object Segmentation on Complex Scenes
Oct 12, 2022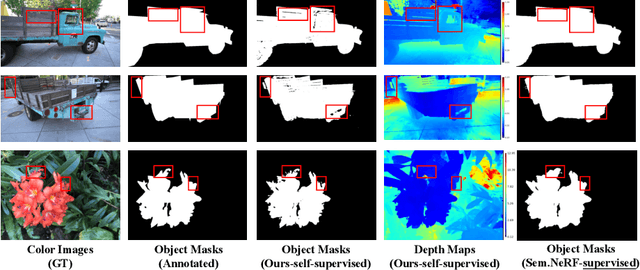
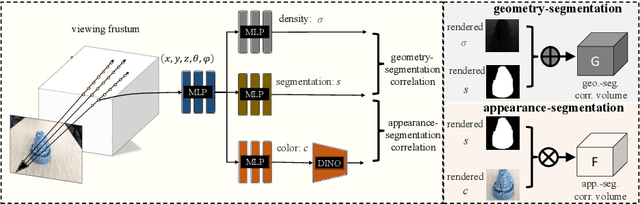
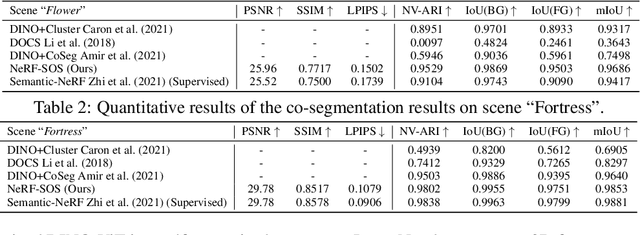

Neural volumetric representations have shown the potential that Multi-layer Perceptrons (MLPs) can be optimized with multi-view calibrated images to represent scene geometry and appearance, without explicit 3D supervision. Object segmentation can enrich many downstream applications based on the learned radiance field. However, introducing hand-crafted segmentation to define regions of interest in a complex real-world scene is non-trivial and expensive as it acquires per view annotation. This paper carries out the exploration of self-supervised learning for object segmentation using NeRF for complex real-world scenes. Our framework, called NeRF with Self-supervised Object Segmentation NeRF-SOS, couples object segmentation and neural radiance field to segment objects in any view within a scene. By proposing a novel collaborative contrastive loss in both appearance and geometry levels, NeRF-SOS encourages NeRF models to distill compact geometry-aware segmentation clusters from their density fields and the self-supervised pre-trained 2D visual features. The self-supervised object segmentation framework can be applied to various NeRF models that both lead to photo-realistic rendering results and convincing segmentation maps for both indoor and outdoor scenarios. Extensive results on the LLFF, Tank & Temple, and BlendedMVS datasets validate the effectiveness of NeRF-SOS. It consistently surpasses other 2D-based self-supervised baselines and predicts finer semantics masks than existing supervised counterparts. Please refer to the video on our project page for more details:https://zhiwenfan.github.io/NeRF-SOS.
Trap and Replace: Defending Backdoor Attacks by Trapping Them into an Easy-to-Replace Subnetwork
Oct 12, 2022
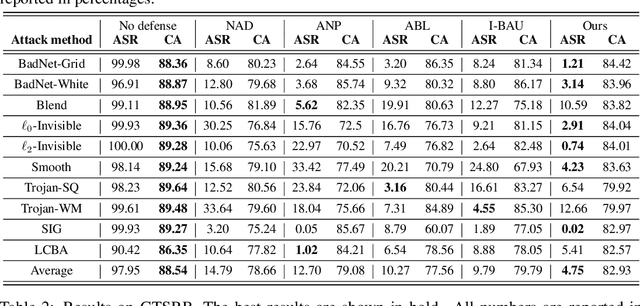
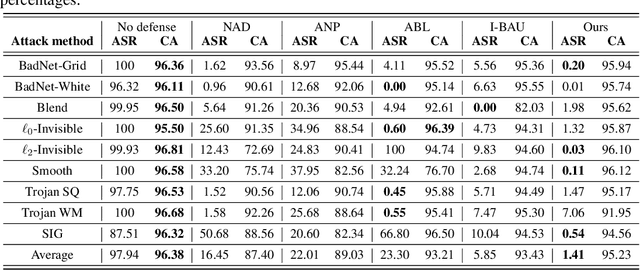
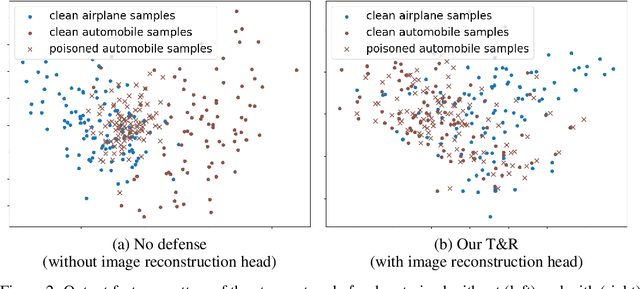
Deep neural networks (DNNs) are vulnerable to backdoor attacks. Previous works have shown it extremely challenging to unlearn the undesired backdoor behavior from the network, since the entire network can be affected by the backdoor samples. In this paper, we propose a brand-new backdoor defense strategy, which makes it much easier to remove the harmful influence of backdoor samples from the model. Our defense strategy, \emph{Trap and Replace}, consists of two stages. In the first stage, we bait and trap the backdoors in a small and easy-to-replace subnetwork. Specifically, we add an auxiliary image reconstruction head on top of the stem network shared with a light-weighted classification head. The intuition is that the auxiliary image reconstruction task encourages the stem network to keep sufficient low-level visual features that are hard to learn but semantically correct, instead of overfitting to the easy-to-learn but semantically incorrect backdoor correlations. As a result, when trained on backdoored datasets, the backdoors are easily baited towards the unprotected classification head, since it is much more vulnerable than the shared stem, leaving the stem network hardly poisoned. In the second stage, we replace the poisoned light-weighted classification head with an untainted one, by re-training it from scratch only on a small holdout dataset with clean samples, while fixing the stem network. As a result, both the stem and the classification head in the final network are hardly affected by backdoor training samples. We evaluate our method against ten different backdoor attacks. Our method outperforms previous state-of-the-art methods by up to $20.57\%$, $9.80\%$, and $13.72\%$ attack success rate and on-average $3.14\%$, $1.80\%$, and $1.21\%$ clean classification accuracy on CIFAR10, GTSRB, and ImageNet-12, respectively. Code is available online.
Augmentations in Hypergraph Contrastive Learning: Fabricated and Generative
Oct 07, 2022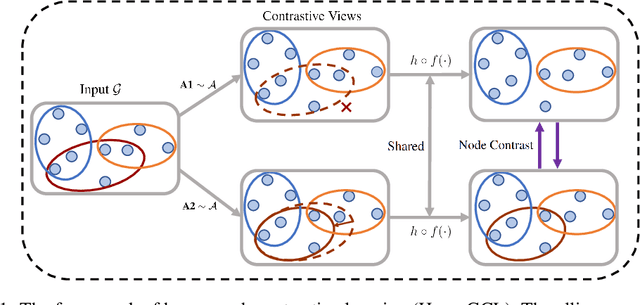

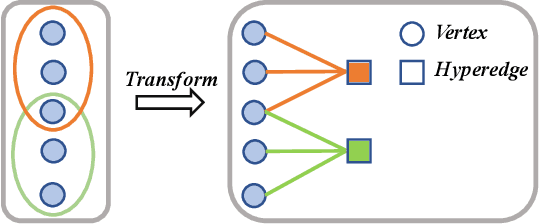

This paper targets at improving the generalizability of hypergraph neural networks in the low-label regime, through applying the contrastive learning approach from images/graphs (we refer to it as HyperGCL). We focus on the following question: How to construct contrastive views for hypergraphs via augmentations? We provide the solutions in two folds. First, guided by domain knowledge, we fabricate two schemes to augment hyperedges with higher-order relations encoded, and adopt three vertex augmentation strategies from graph-structured data. Second, in search of more effective views in a data-driven manner, we for the first time propose a hypergraph generative model to generate augmented views, and then an end-to-end differentiable pipeline to jointly learn hypergraph augmentations and model parameters. Our technical innovations are reflected in designing both fabricated and generative augmentations of hypergraphs. The experimental findings include: (i) Among fabricated augmentations in HyperGCL, augmenting hyperedges provides the most numerical gains, implying that higher-order information in structures is usually more downstream-relevant; (ii) Generative augmentations do better in preserving higher-order information to further benefit generalizability; (iii) HyperGCL also boosts robustness and fairness in hypergraph representation learning. Codes are released at https://github.com/weitianxin/HyperGCL.
DynImp: Dynamic Imputation for Wearable Sensing Data Through Sensory and Temporal Relatedness
Sep 26, 2022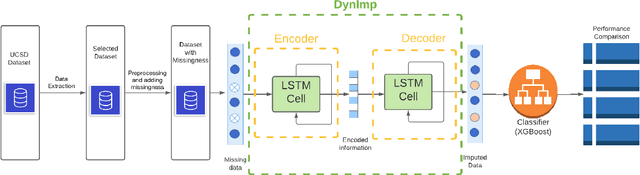

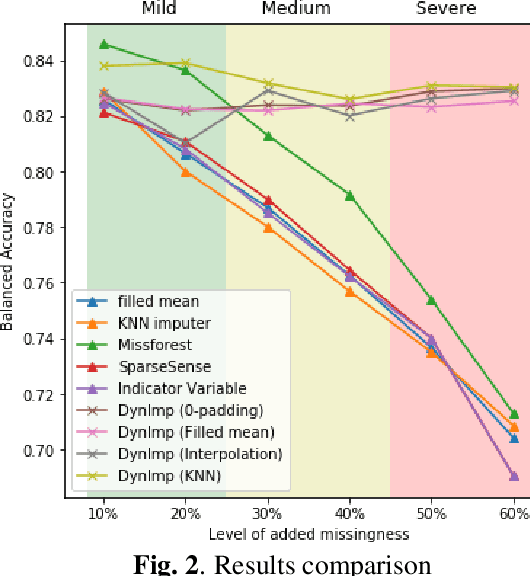
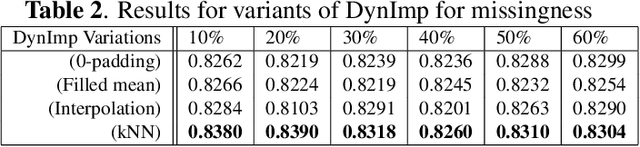
In wearable sensing applications, data is inevitable to be irregularly sampled or partially missing, which pose challenges for any downstream application. An unique aspect of wearable data is that it is time-series data and each channel can be correlated to another one, such as x, y, z axis of accelerometer. We argue that traditional methods have rarely made use of both times-series dynamics of the data as well as the relatedness of the features from different sensors. We propose a model, termed as DynImp, to handle different time point's missingness with nearest neighbors along feature axis and then feeding the data into a LSTM-based denoising autoencoder which can reconstruct missingness along the time axis. We experiment the model on the extreme missingness scenario ($>50\%$ missing rate) which has not been widely tested in wearable data. Our experiments on activity recognition show that the method can exploit the multi-modality features from related sensors and also learn from history time-series dynamics to reconstruct the data under extreme missingness.
Can We Solve 3D Vision Tasks Starting from A 2D Vision Transformer?
Sep 18, 2022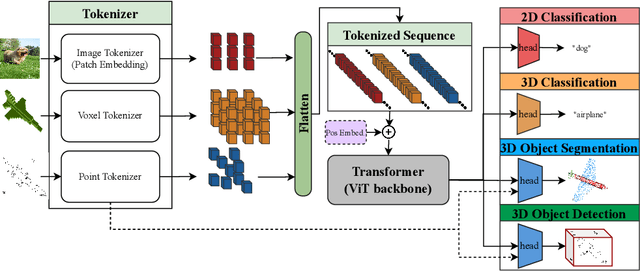

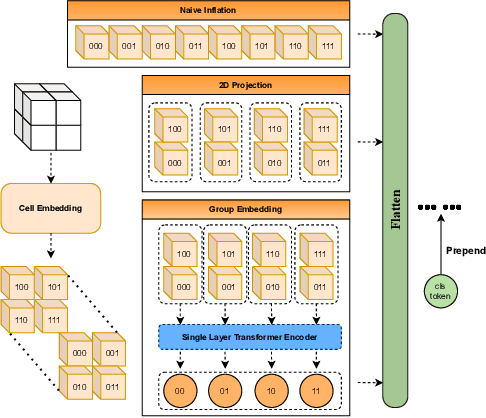
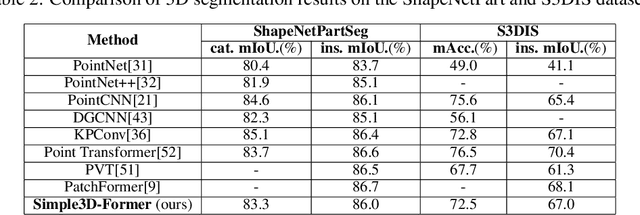
Vision Transformers (ViTs) have proven to be effective, in solving 2D image understanding tasks by training over large-scale image datasets; and meanwhile as a somehow separate track, in modeling the 3D visual world too such as voxels or point clouds. However, with the growing hope that transformers can become the "universal" modeling tool for heterogeneous data, ViTs for 2D and 3D tasks have so far adopted vastly different architecture designs that are hardly transferable. That invites an (over-)ambitious question: can we close the gap between the 2D and 3D ViT architectures? As a piloting study, this paper demonstrates the appealing promise to understand the 3D visual world, using a standard 2D ViT architecture, with only minimal customization at the input and output levels without redesigning the pipeline. To build a 3D ViT from its 2D sibling, we "inflate" the patch embedding and token sequence, accompanied with new positional encoding mechanisms designed to match the 3D data geometry. The resultant "minimalist" 3D ViT, named Simple3D-Former, performs surprisingly robustly on popular 3D tasks such as object classification, point cloud segmentation and indoor scene detection, compared to highly customized 3D-specific designs. It can hence act as a strong baseline for new 3D ViTs. Moreover, we note that pursing a unified 2D-3D ViT design has practical relevance besides just scientific curiosity. Specifically, we demonstrate that Simple3D-Former naturally enables to exploit the wealth of pre-trained weights from large-scale realistic 2D images (e.g., ImageNet), which can be plugged in to enhancing the 3D task performance "for free".