 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORSO: Accelerating Reward Design via Online Reward Selection and Policy Optimization
Oct 17, 2024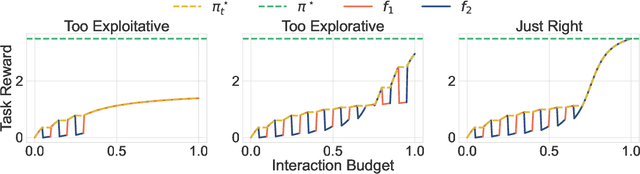

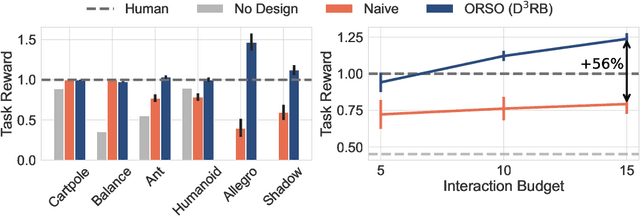

Reward shaping is a critical component in reinforcement learning (RL), particularly for complex tasks where sparse rewards can hinder learning. While shaping rewards have been introduced to provide additional guidance, selecting effective shaping functions remains challenging and computationally expensive. This paper introduces Online Reward Selection and Policy Optimization (ORSO), a novel approach that frames shaping reward selection as an online model selection problem. ORSO employs principled exploration strategies to automatically identify promising shaping reward functions without human intervention, balancing exploration and exploitation with provable regret guarantees. We demonstrate ORSO's effectiveness across various continuous control tasks using the Isaac Gym simulator. Compared to traditional methods that fully evaluate each shaping reward function, ORSO significantly improves sample efficiency, reduces computational time, and consistently identifies high-quality reward functions that produce policies comparable to those generated by domain experts through hand-engineered rewards.
Random Latent Exploration for Deep Reinforcement Learning
Jul 18, 2024



The ability to efficiently explore high-dimensional state spaces is essential for the practical success of deep Reinforcement Learning (RL). This paper introduces a new exploration technique called Random Latent Exploration (RLE), that combines the strengths of bonus-based and noise-based (two popular approaches for effective exploration in deep RL) exploration strategies. RLE leverages the idea of perturbing rewards by adding structured random rewards to the original task rewards in certain (random) states of the environment, to encourage the agent to explore the environment during training. RLE is straightforward to implement and performs well in practice. To demonstrate the practical effectiveness of RLE, we evaluate it on the challenging Atari and IsaacGym benchmarks and show that RLE exhibits higher overall scores across all the tasks than other approaches.
ROER: Regularized Optimal Experience Replay
Jul 04, 2024



Experience replay serves as a key component in the success of online reinforcement learning (RL). Prioritized experience replay (PER) reweights experiences by the temporal difference (TD) error empirically enhancing the performance. However, few works have explored the motivation of using TD error. In this work, we provide an alternative perspective on TD-error-based reweighting. We show the connections between the experience prioritization and occupancy optimization. By using a regularized RL objective with $f-$divergence regularizer and employing its dual form, we show that an optimal solution to the objective is obtained by shifting the distribution of off-policy data in the replay buffer towards the on-policy optimal distribution using TD-error-based occupancy ratios. Our derivation results in a new pipeline of TD error prioritization. We specifically explore the KL divergence as the regularizer and obtain a new form of prioritization scheme, the regularized optimal experience replay (ROER). We evaluate the proposed prioritization scheme with the Soft Actor-Critic (SAC) algorithm in continuous control MuJoCo and DM Control benchmark tasks where our proposed scheme outperforms baselines in 6 out of 11 tasks while the results of the rest match with or do not deviate far from the baselines. Further, using pretraining, ROER achieves noticeable improvement on difficult Antmaze environment where baselines fail, showing applicability to offline-to-online fine-tuning. Code is available at \url{https://github.com/XavierChanglingLi/Regularized-Optimal-Experience-Replay}.
Text-to-Drive: Diverse Driving Behavior Synthesis via Large Language Models
Jun 06, 2024



Generating varied scenarios through simulation is crucial for training and evaluating safety-critical systems, such as autonomous vehicles. Yet, the task of modeling the trajectories of other vehicles to simulate diverse and meaningful close interactions remains prohibitively costly. Adopting language descriptions to generate driving behaviors emerges as a promising strategy, offering a scalable and intuitive method for human operators to simulate a wide range of driving interactions. However, the scarcity of large-scale annotated language-trajectory data makes this approach challenging. To address this gap, we propose Text-to-Drive (T2D) to synthesize diverse driving behaviors via Large Language Models (LLMs). We introduce a knowledge-driven approach that operates in two stages. In the first stage, we employ the embedded knowledge of LLMs to generate diverse language descriptions of driving behaviors for a scene. Then, we leverage LLM's reasoning capabilities to synthesize these behaviors in simulation. At its core, T2D employs an LLM to construct a state chart that maps low-level states to high-level abstractions. This strategy aids in downstream tasks such as summarizing low-level observations, assessing policy alignment with behavior description, and shaping the auxiliary reward, all without needing human supervision. With our knowledge-driven approach, we demonstrate that T2D generates more diverse trajectories compared to other baselines and offers a natural language interface that allows for interactive incorporation of human preference. Please check our website for more examples: https://text-to-drive.github.io/
Curiosity-driven Red-teaming for Large Language Models
Feb 29, 2024



Large language models (LLMs) hold great potential for many natural language applications but risk generating incorrect or toxic content. To probe when an LLM generates unwanted content, the current paradigm is to recruit a \textit{red team} of human testers to design input prompts (i.e., test cases) that elicit undesirable responses from LLMs. However, relying solely on human testers is expensive and time-consuming. Recent works automate red teaming by training a separate red team LLM with reinforcement learning (RL) to generate test cases that maximize the chance of eliciting undesirable responses from the target LLM. However, current RL methods are only able to generate a small number of effective test cases resulting in a low coverage of the span of prompts that elicit undesirable responses from the target LLM. To overcome this limitation, we draw a connection between the problem of increasing the coverage of generated test cases and the well-studied approach of curiosity-driven exploration that optimizes for novelty. Our method of curiosity-driven red teaming (CRT) achieves greater coverage of test cases while mantaining or increasing their effectiveness compared to existing methods. Our method, CRT successfully provokes toxic responses from LLaMA2 model that has been heavily fine-tuned using human preferences to avoid toxic outputs. Code is available at \url{https://github.com/Improbable-AI/curiosity_redteam}
Neuro-Inspired Fragmentation and Recall to Overcome Catastrophic Forgetting in Curiosity
Oct 26, 2023



Deep reinforcement learning methods exhibit impressive performance on a range of tasks but still struggle on hard exploration tasks in large environments with sparse rewards. To address this, intrinsic rewards can be generated using forward model prediction errors that decrease as the environment becomes known, and incentivize an agent to explore novel states. While prediction-based intrinsic rewards can help agents solve hard exploration tasks, they can suffer from catastrophic forgetting and actually increase at visited states. We first examine the conditions and causes of catastrophic forgetting in grid world environments. We then propose a new method FARCuriosity, inspired by how humans and animals learn. The method depends on fragmentation and recall: an agent fragments an environment based on surprisal, and uses different local curiosity modules (prediction-based intrinsic reward functions) for each fragment so that modules are not trained on the entire environment. At each fragmentation event, the agent stores the current module in long-term memory (LTM) and either initializes a new module or recalls a previously stored module based on its match with the current state. With fragmentation and recall, FARCuriosity achieves less forgetting and better overall performance in games with varied and heterogeneous environments in the Atari benchmark suite of tasks. Thus, this work highlights the problem of catastrophic forgetting in prediction-based curiosity methods and proposes a solution.
Beyond Uniform Sampling: Offline Reinforcement Learning with Imbalanced Datasets
Oct 12, 2023



Offline policy learning is aimed at learning decision-making policies using existing datasets of trajectories without collecting additional data. The primary motivation for using reinforcement learning (RL) instead of supervised learning techniques such as behavior cloning is to find a policy that achieves a higher average return than the trajectories constituting the dataset. However, we empirically find that when a dataset is dominated by suboptimal trajectories, state-of-the-art offline RL algorithms do not substantially improve over the average return of trajectories in the dataset. We argue this is due to an assumption made by current offline RL algorithms of staying close to the trajectories in the dataset. If the dataset primarily consists of sub-optimal trajectories, this assumption forces the policy to mimic the suboptimal actions. We overcome this issue by proposing a sampling strategy that enables the policy to only be constrained to ``good data" rather than all actions in the dataset (i.e., uniform sampling). We present a realization of the sampling strategy and an algorithm that can be used as a plug-and-play module in standard offline RL algorithms. Our evaluation demonstrates significant performance gains in 72 imbalanced datasets, D4RL dataset, and across three different offline RL algorithms. Code is available at https://github.com/Improbable-AI/dw-offline-rl.
* Accepted NeurIPS 2023
Parallel $Q$-Learning: Scaling Off-policy Reinforcement Learning under Massively Parallel Simulation
Jul 24, 2023Reinforcement learning is time-consuming for complex tasks due to the need for large amounts of training data. Recent advances in GPU-based simulation, such as Isaac Gym, have sped up data collection thousands of times on a commodity GPU. Most prior works used on-policy methods like PPO due to their simplicity and ease of scaling. Off-policy methods are more data efficient but challenging to scale, resulting in a longer wall-clock training time. This paper presents a Parallel $Q$-Learning (PQL) scheme that outperforms PPO in wall-clock time while maintaining superior sample efficiency of off-policy learning. PQL achieves this by parallelizing data collection, policy learning, and value learning. Different from prior works on distributed off-policy learning, such as Apex, our scheme is designed specifically for massively parallel GPU-based simulation and optimized to work on a single workstation. In experiments, we demonstrate that $Q$-learning can be scaled to \textit{tens of thousands of parallel environments} and investigate important factors affecting learning speed. The code is available at https://github.com/Improbable-AI/pql.
Neuro-Inspired Efficient Map Building via Fragmentation and Recall
Jul 11, 2023Animals and robots navigate through environments by building and refining maps of the space. These maps enable functions including navigating back to home, planning, search, and foraging. In large environments, exploration of the space is a hard problem: agents can become stuck in local regions. Here, we use insights from neuroscience to propose and apply the concept of Fragmentation-and-Recall (FarMap), with agents solving the mapping problem by building local maps via a surprisal-based clustering of space, which they use to set subgoals for spatial exploration. Agents build and use a local map to predict their observations; high surprisal leads to a ``fragmentation event'' that truncates the local map. At these events, the recent local map is placed into long-term memory (LTM), and a different local map is initialized. If observations at a fracture point match observations in one of the stored local maps, that map is recalled (and thus reused) from LTM. The fragmentation points induce a natural online clustering of the larger space, forming a set of intrinsic potential subgoals that are stored in LTM as a topological graph. Agents choose their next subgoal from the set of near and far potential subgoals from within the current local map or LTM, respectively. Thus, local maps guide exploration locally, while LTM promotes global exploration. We evaluate FarMap on complex procedurally-generated spatial environments to demonstrate that this mapping strategy much more rapidly covers the environment (number of agent steps and wall clock time) and is more efficient in active memory usage, without loss of performance.
TGRL: An Algorithm for Teacher Guided Reinforcement Learning
Jul 06, 2023Learning from rewards (i.e., reinforcement learning or RL) and learning to imitate a teacher (i.e., teacher-student learning) are two established approaches for solving sequential decision-making problems. To combine the benefits of these different forms of learning, it is common to train a policy to maximize a combination of reinforcement and teacher-student learning objectives. However, without a principled method to balance these objectives, prior work used heuristics and problem-specific hyperparameter searches to balance the two objectives. We present a $\textit{principled}$ approach, along with an approximate implementation for $\textit{dynamically}$ and $\textit{automatically}$ balancing when to follow the teacher and when to use rewards. The main idea is to adjust the importance of teacher supervision by comparing the agent's performance to the counterfactual scenario of the agent learning without teacher supervision and only from rewards. If using teacher supervision improves performance, the importance of teacher supervision is increased and otherwise it is decreased. Our method, $\textit{Teacher Guided Reinforcement Learning}$ (TGRL), outperforms strong baselines across diverse domains without hyper-parameter tuning.