 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT^2Agent A Tool-augmented Multimodal Misinformation Detection Agent with Monte Carlo Tree Search
May 26, 2025Real-world multimodal misinformation often arises from mixed forgery sources, requiring dynamic reasoning and adaptive verification. However, existing methods mainly rely on static pipelines and limited tool usage, limiting their ability to handle such complexity and diversity. To address this challenge, we propose T2Agent, a novel misinformation detection agent that incorporates an extensible toolkit with Monte Carlo Tree Search (MCTS). The toolkit consists of modular tools such as web search, forgery detection, and consistency analysis. Each tool is described using standardized templates, enabling seamless integration and future expansion. To avoid inefficiency from using all tools simultaneously, a Bayesian optimization-based selector is proposed to identify a task-relevant subset. This subset then serves as the action space for MCTS to dynamically collect evidence and perform multi-source verification. To better align MCTS with the multi-source nature of misinformation detection, T2Agent extends traditional MCTS with multi-source verification, which decomposes the task into coordinated subtasks targeting different forgery sources. A dual reward mechanism containing a reasoning trajectory score and a confidence score is further proposed to encourage a balance between exploration across mixed forgery sources and exploitation for more reliable evidence. We conduct ablation studies to confirm the effectiveness of the tree search mechanism and tool usage. Extensive experiments further show that T2Agent consistently outperforms existing baselines on challenging mixed-source multimodal misinformation benchmarks, demonstrating its strong potential as a training-free approach for enhancing detection accuracy. The code will be released.
Video-SafetyBench: A Benchmark for Safety Evaluation of Video LVLMs
May 17, 2025The increasing deployment of Large Vision-Language Models (LVLMs) raises safety concerns under potential malicious inputs. However, existing multimodal safety evaluations primarily focus on model vulnerabilities exposed by static image inputs, ignoring the temporal dynamics of video that may induce distinct safety risks. To bridge this gap, we introduce Video-SafetyBench, the first comprehensive benchmark designed to evaluate the safety of LVLMs under video-text attacks. It comprises 2,264 video-text pairs spanning 48 fine-grained unsafe categories, each pairing a synthesized video with either a harmful query, which contains explicit malice, or a benign query, which appears harmless but triggers harmful behavior when interpreted alongside the video. To generate semantically accurate videos for safety evaluation, we design a controllable pipeline that decomposes video semantics into subject images (what is shown) and motion text (how it moves), which jointly guide the synthesis of query-relevant videos. To effectively evaluate uncertain or borderline harmful outputs, we propose RJScore, a novel LLM-based metric that incorporates the confidence of judge models and human-aligned decision threshold calibration. Extensive experiments show that benign-query video composition achieves average attack success rates of 67.2%, revealing consistent vulnerabilities to video-induced attacks. We believe Video-SafetyBench will catalyze future research into video-based safety evaluation and defense strategies.
Rethinking the Role of Prompting Strategies in LLM Test-Time Scaling: A Perspective of Probability Theory
May 16, 2025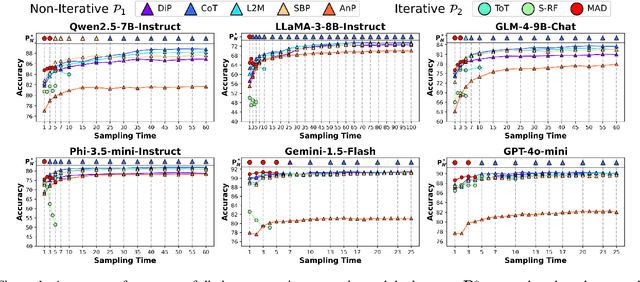


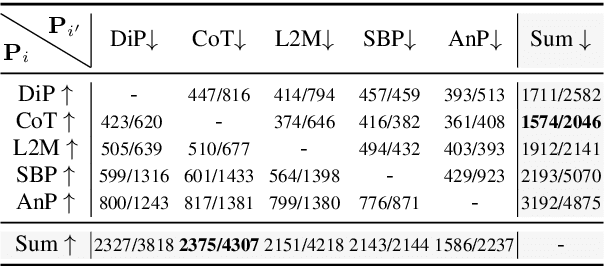
Recently, scaling test-time compute on Large Language Models (LLM) has garnered wide attention. However, there has been limited investigation of how various reasoning prompting strategies perform as scaling. In this paper, we focus on a standard and realistic scaling setting: majority voting. We systematically conduct experiments on 6 LLMs $\times$ 8 prompting strategies $\times$ 6 benchmarks. Experiment results consistently show that as the sampling time and computational overhead increase, complicated prompting strategies with superior initial performance gradually fall behind simple Chain-of-Thought. We analyze this phenomenon and provide theoretical proofs. Additionally, we propose a method according to probability theory to quickly and accurately predict the scaling performance and select the best strategy under large sampling times without extra resource-intensive inference in practice. It can serve as the test-time scaling law for majority voting. Furthermore, we introduce two ways derived from our theoretical analysis to significantly improve the scaling performance. We hope that our research can promote to re-examine the role of complicated prompting, unleash the potential of simple prompting strategies, and provide new insights for enhancing test-time scaling performance.
MacRAG: Compress, Slice, and Scale-up for Multi-Scale Adaptive Context RAG
May 10, 2025



Long-context (LC) Large Language Models (LLMs) combined with Retrieval-Augmented Generation (RAG) hold strong potential for complex multi-hop and large-document tasks. However, existing RAG systems often suffer from imprecise retrieval, incomplete context coverage under constrained context windows, and fragmented information caused by suboptimal context construction. We introduce Multi-scale Adaptive Context RAG (MacRAG), a hierarchical retrieval framework that compresses and partitions documents into coarse-to-fine granularities, then adaptively merges relevant contexts through chunk- and document-level expansions in real time. By starting from the finest-level retrieval and progressively incorporating higher-level and broader context, MacRAG constructs effective query-specific long contexts, optimizing both precision and coverage. Evaluations on the challenging LongBench expansions of HotpotQA, 2WikiMultihopQA, and Musique confirm that MacRAG consistently surpasses baseline RAG pipelines on single- and multi-step generation with Llama-3.1-8B, Gemini-1.5-pro, and GPT-4o. Our results establish MacRAG as an efficient, scalable solution for real-world long-context, multi-hop reasoning. Our code is available at https://github.com/Leezekun/MacRAG.
Art3D: Training-Free 3D Generation from Flat-Colored Illustration
Apr 14, 2025Large-scale pre-trained image-to-3D generative models have exhibited remarkable capabilities in diverse shape generations. However, most of them struggle to synthesize plausible 3D assets when the reference image is flat-colored like hand drawings due to the lack of 3D illusion, which are often the most user-friendly input modalities in art content creation. To this end, we propose Art3D, a training-free method that can lift flat-colored 2D designs into 3D. By leveraging structural and semantic features with pre- trained 2D image generation models and a VLM-based realism evaluation, Art3D successfully enhances the three-dimensional illusion in reference images, thus simplifying the process of generating 3D from 2D, and proves adaptable to a wide range of painting styles. To benchmark the generalization performance of existing image-to-3D models on flat-colored images without 3D feeling, we collect a new dataset, Flat-2D, with over 100 samples. Experimental results demonstrate the performance and robustness of Art3D, exhibiting superior generalizable capacity and promising practical applicability. Our source code and dataset will be publicly available on our project page: https://joy-jy11.github.io/ .
Balancing Multi-Target Semi-Supervised Medical Image Segmentation with Collaborative Generalist and Specialists
Apr 01, 2025Despite the promising performance achieved by current semi-supervised models in segmenting individual medical targets, many of these models suffer a notable decrease in performance when tasked with the simultaneous segmentation of multiple targets. A vital factor could be attributed to the imbalanced scales among different targets: during simultaneously segmenting multiple targets, large targets dominate the loss, leading to small targets being misclassified as larger ones. To this end, we propose a novel method, which consists of a Collaborative Generalist and several Specialists, termed CGS. It is centered around the idea of employing a specialist for each target class, thus avoiding the dominance of larger targets. The generalist performs conventional multi-target segmentation, while each specialist is dedicated to distinguishing a specific target class from the remaining target classes and the background. Based on a theoretical insight, we demonstrate that CGS can achieve a more balanced training. Moreover, we develop cross-consistency losses to foster collaborative learning between the generalist and the specialists. Lastly, regarding their intrinsic relation that the target class of any specialized head should belong to the remaining classes of the other heads, we introduce an inter-head error detection module to further enhance the quality of pseudo-labels. Experimental results on three popular benchmarks showcase its superior performance compared to state-of-the-art methods.
AgentOrca: A Dual-System Framework to Evaluate Language Agents on Operational Routine and Constraint Adherence
Mar 11, 2025



As language agents progressively automate critical tasks across domains, their ability to operate within operational constraints and safety protocols becomes essential. While extensive research has demonstrated these agents' effectiveness in downstream task completion, their reliability in following operational procedures and constraints remains largely unexplored. To this end, we present AgentOrca, a dual-system framework for evaluating language agents' compliance with operational constraints and routines. Our framework encodes action constraints and routines through both natural language prompts for agents and corresponding executable code serving as ground truth for automated verification. Through an automated pipeline of test case generation and evaluation across five real-world domains, we quantitatively assess current language agents' adherence to operational constraints. Our findings reveal notable performance gaps among state-of-the-art models, with large reasoning models like o1 demonstrating superior compliance while others show significantly lower performance, particularly when encountering complex constraints or user persuasion attempts.
MapQA: Open-domain Geospatial Question Answering on Map Data
Mar 10, 2025Geospatial question answering (QA) is a fundamental task in navigation and point of interest (POI) searches. While existing geospatial QA datasets exist, they are limited in both scale and diversity, often relying solely on textual descriptions of geo-entities without considering their geometries. A major challenge in scaling geospatial QA datasets for reasoning lies in the complexity of geospatial relationships, which require integrating spatial structures, topological dependencies, and multi-hop reasoning capabilities that most text-based QA datasets lack. To address these limitations, we introduce MapQA, a novel dataset that not only provides question-answer pairs but also includes the geometries of geo-entities referenced in the questions. MapQA is constructed using SQL query templates to extract question-answer pairs from OpenStreetMap (OSM) for two study regions: Southern California and Illinois. It consists of 3,154 QA pairs spanning nine question types that require geospatial reasoning, such as neighborhood inference and geo-entity type identification. Compared to existing datasets, MapQA expands both the number and diversity of geospatial question types. We explore two approaches to tackle this challenge: (1) a retrieval-based language model that ranks candidate geo-entities by embedding similarity, and (2) a large language model (LLM) that generates SQL queries from natural language questions and geo-entity attributes, which are then executed against an OSM database. Our findings indicate that retrieval-based methods effectively capture concepts like closeness and direction but struggle with questions that require explicit computations (e.g., distance calculations). LLMs (e.g., GPT and Gemini) excel at generating SQL queries for one-hop reasoning but face challenges with multi-hop reasoning, highlighting a key bottleneck in advancing geospatial QA systems.
ID-Cloak: Crafting Identity-Specific Cloaks Against Personalized Text-to-Image Generation
Feb 12, 2025Personalized text-to-image models allow users to generate images of new concepts from several reference photos, thereby leading to critical concerns regarding civil privacy. Although several anti-personalization techniques have been developed, these methods typically assume that defenders can afford to design a privacy cloak corresponding to each specific image. However, due to extensive personal images shared online, image-specific methods are limited by real-world practical applications. To address this issue, we are the first to investigate the creation of identity-specific cloaks (ID-Cloak) that safeguard all images belong to a specific identity. Specifically, we first model an identity subspace that preserves personal commonalities and learns diverse contexts to capture the image distribution to be protected. Then, we craft identity-specific cloaks with the proposed novel objective that encourages the cloak to guide the model away from its normal output within the subspace. Extensive experiments show that the generated universal cloak can effectively protect the images. We believe our method, along with the proposed identity-specific cloak setting, marks a notable advance in realistic privacy protection.
Survey on AI-Generated Media Detection: From Non-MLLM to MLLM
Feb 07, 2025The proliferation of AI-generated media poses significant challenges to information authenticity and social trust, making reliable detection methods highly demanded. Methods for detecting AI-generated media have evolved rapidly, paralleling the advancement of Multimodal Large Language Models (MLLMs). Current detection approaches can be categorized into two main groups: Non-MLLM-based and MLLM-based methods. The former employs high-precision, domain-specific detectors powered by deep learning techniques, while the latter utilizes general-purpose detectors based on MLLMs that integrate authenticity verification, explainability, and localization capabilities. Despite significant progress in this field, there remains a gap in literature regarding a comprehensive survey that examines the transition from domain-specific to general-purpose detection methods. This paper addresses this gap by providing a systematic review of both approaches, analyzing them from single-modal and multi-modal perspectives. We present a detailed comparative analysis of these categories, examining their methodological similarities and differences. Through this analysis, we explore potential hybrid approaches and identify key challenges in forgery detection, providing direction for future research. Additionally, as MLLMs become increasingly prevalent in detection tasks, ethical and security considerations have emerged as critical global concerns. We examine the regulatory landscape surrounding Generative AI (GenAI) across various jurisdictions, offering valuable insights for researchers and practitioners in this field.