 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE-Image Technical Report
May 25, 2026We introduce ERNIE-Image, an open-source text-to-image generation model built upon an 8B single-stream DiT architecture. ERNIE-Image aims to bridge the gap between current open-source models and leading closed-source systems through more effective mining of large-scale pre-training data and improved supervision quality throughout training. During pre-training, we adopt a bottom-up data construction pipeline that combines fine-grained image categorization, rich caption annotation, aesthetic assessment, and hierarchical sampling. This strategy reduces data noise while preserving long-tail concepts and detailed real-world knowledge, providing a stronger foundation for complex generation tasks. In the post-training stage, we use a top-down data construction pipeline for high-demand scenarios, diversify prompt annotations to better match real user inputs, and apply a stabilized DPO strategy to align the model with human aesthetic preferences. We further train ERNIE-Image-Turbo for efficient 8-NFE generation and propose MT-DMD to mitigate capability drift during distillation. To make the model easier to use in practical scenarios, we equip it with a lightweight Prompt Enhancer that expands concise user intents into structured visual descriptions. In addition, we develop ERNIE-Image-Aes, an industrial-grade aesthetic model, together with ERNIE-Image-Aes-1K, a human-annotated benchmark for realistic aesthetic evaluation. Extensive qualitative and quantitative experiments show that ERNIE-Image achieves leading performance among open-source models and approaches top-tier commercial models in instruction following, text rendering, and aesthetic quality. We release the trained models and aesthetic resources to facilitate further academic research and technical progress in the AIGC community.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Beyond ReAct: A Planner-Centric Framework for Complex Tool-Augmented LLM Reasoning
Nov 13, 2025Existing tool-augmented large language models (LLMs) encounter significant challenges when processing complex queries. Current frameworks such as ReAct are prone to local optimization traps due to their reliance on incremental decision-making processes. To address these limitations, we propose a novel Planner-centric Plan-Execute paradigm that fundamentally resolves local optimization bottlenecks through architectural innovation. Central to our approach is a novel Planner model that performs global Directed Acyclic Graph (DAG) planning for complex queries, enabling optimized execution beyond conventional tool coordination. We also introduce ComplexTool-Plan, a large-scale benchmark dataset featuring complex queries that demand sophisticated multi-tool composition and coordination capabilities. Additionally, we develop a two-stage training methodology that integrates Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO), systematically enhancing the Planner's tool selection accuracy and global planning awareness through structured DAG-based planning. When integrated with a capable executor, our framework achieves state-of-the-art performance on the StableToolBench benchmark for complex user queries, demonstrating superior end-to-end execution capabilities and robust handling of intricate multi-tool workflows.
TURA: Tool-Augmented Unified Retrieval Agent for AI Search
Aug 06, 2025



The advent of Large Language Models (LLMs) is transforming search engines into conversational AI search products, primarily using Retrieval-Augmented Generation (RAG) on web corpora. However, this paradigm has significant industrial limitations. Traditional RAG approaches struggle with real-time needs and structured queries that require accessing dynamically generated content like ticket availability or inventory. Limited to indexing static pages, search engines cannot perform the interactive queries needed for such time-sensitive data. Academic research has focused on optimizing RAG for static content, overlooking complex intents and the need for dynamic sources like databases and real-time APIs. To bridge this gap, we introduce TURA (Tool-Augmented Unified Retrieval Agent for AI Search), a novel three-stage framework that combines RAG with agentic tool-use to access both static content and dynamic, real-time information. TURA has three key components: an Intent-Aware Retrieval module to decompose queries and retrieve information sources encapsulated as Model Context Protocol (MCP) Servers, a DAG-based Task Planner that models task dependencies as a Directed Acyclic Graph (DAG) for optimal parallel execution, and a lightweight Distilled Agent Executor for efficient tool calling. TURA is the first architecture to systematically bridge the gap between static RAG and dynamic information sources for a world-class AI search product. Serving tens of millions of users, it leverages an agentic framework to deliver robust, real-time answers while meeting the low-latency demands of a large-scale industrial system.
Joint Learning-based Causal Relation Extraction from Biomedical Literature
Aug 02, 2022
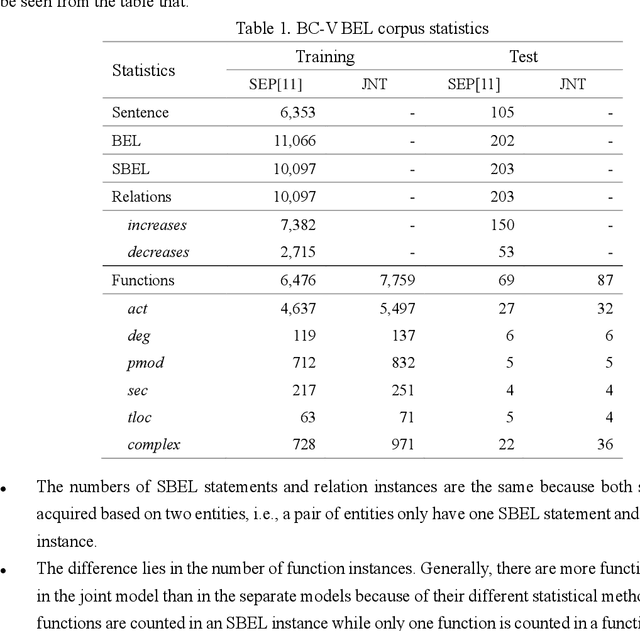
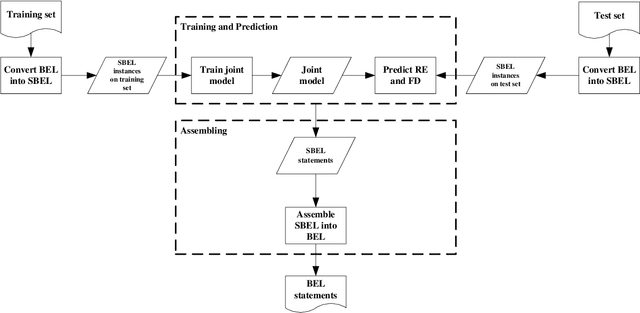
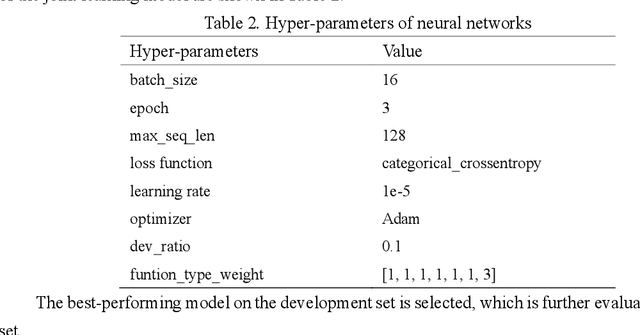
Causal relation extraction of biomedical entities is one of the most complex tasks in biomedical text mining, which involves two kinds of information: entity relations and entity functions. One feasible approach is to take relation extraction and function detection as two independent sub-tasks. However, this separate learning method ignores the intrinsic correlation between them and leads to unsatisfactory performance. In this paper, we propose a joint learning model, which combines entity relation extraction and entity function detection to exploit their commonality and capture their inter-relationship, so as to improve the performance of biomedical causal relation extraction. Meanwhile, during the model training stage, different function types in the loss function are assigned different weights. Specifically, the penalty coefficient for negative function instances increases to effectively improve the precision of function detection. Experimental results on the BioCreative-V Track 4 corpus show that our joint learning model outperforms the separate models in BEL statement extraction, achieving the F1 scores of 58.4% and 37.3% on the test set in Stage 2 and Stage 1 evaluations, respectively. This demonstrates that our joint learning system reaches the state-of-the-art performance in Stage 2 compared with other systems.