 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCreative: Unifying Long-form Logic and Short-form Sparkle via Reference-Free Reinforcement Learning
Apr 07, 2026A fundamental challenge in creative writing lies in reconciling the inherent tension between maintaining global coherence in long-form narratives and preserving local expressiveness in short-form texts. While long-context generation necessitates explicit macroscopic planning, short-form creativity often demands spontaneous, constraint-free expression. Existing alignment paradigms, however, typically employ static reward signals and rely heavily on high-quality supervised data, which is costly and difficult to scale. To address this, we propose \textbf{UniCreative}, a unified reference-free reinforcement learning framework. We first introduce \textbf{AC-GenRM}, an adaptive constraint-aware reward model that dynamically synthesizes query-specific criteria to provide fine-grained preference judgments. Leveraging these signals, we propose \textbf{ACPO}, a policy optimization algorithm that aligns models with human preferences across both content quality and structural paradigms without supervised fine-tuning and ground-truth references. Empirical results demonstrate that AC-GenRM aligns closely with expert evaluations, while ACPO significantly enhances performance across diverse writing tasks. Crucially, our analysis reveals an emergent meta-cognitive ability: the model learns to autonomously differentiate between tasks requiring rigorous planning and those favoring direct generation, validating the effectiveness of our direct alignment approach.
BRIGHT: A Collaborative Generalist-Specialist Foundation Model for Breast Pathology
Mar 03, 2026Generalist pathology foundation models (PFMs), pretrained on large-scale multi-organ datasets, have demonstrated remarkable predictive capabilities across diverse clinical applications. However, their proficiency on the full spectrum of clinically essential tasks within a specific organ system remains an open question due to the lack of large-scale validation cohorts for a single organ as well as the absence of a tailored training paradigm that can effectively translate broad histomorphological knowledge into the organ-specific expertise required for specialist-level interpretation. In this study, we propose BRIGHT, the first PFM specifically designed for breast pathology, trained on approximately 210 million histopathology tiles from over 51,000 breast whole-slide images derived from a cohort of over 40,000 patients across 19 hospitals. BRIGHT employs a collaborative generalist-specialist framework to capture both universal and organ-specific features. To comprehensively evaluate the performance of PFMs on breast oncology, we curate the largest multi-institutional cohorts to date for downstream task development and evaluation, comprising over 25,000 WSIs across 10 hospitals. The validation cohorts cover the full spectrum of breast pathology across 24 distinct clinical tasks spanning diagnosis, biomarker prediction, treatment response and survival prediction. Extensive experiments demonstrate that BRIGHT outperforms three leading generalist PFMs, achieving state-of-the-art (SOTA) performance in 21 of 24 internal validation tasks and in 5 of 10 external validation tasks with excellent heatmap interpretability. By evaluating on large-scale validation cohorts, this study not only demonstrates BRIGHT's clinical utility in breast oncology but also validates a collaborative generalist-specialist paradigm, providing a scalable template for developing PFMs on a specific organ system.
Beyond ReAct: A Planner-Centric Framework for Complex Tool-Augmented LLM Reasoning
Nov 13, 2025Existing tool-augmented large language models (LLMs) encounter significant challenges when processing complex queries. Current frameworks such as ReAct are prone to local optimization traps due to their reliance on incremental decision-making processes. To address these limitations, we propose a novel Planner-centric Plan-Execute paradigm that fundamentally resolves local optimization bottlenecks through architectural innovation. Central to our approach is a novel Planner model that performs global Directed Acyclic Graph (DAG) planning for complex queries, enabling optimized execution beyond conventional tool coordination. We also introduce ComplexTool-Plan, a large-scale benchmark dataset featuring complex queries that demand sophisticated multi-tool composition and coordination capabilities. Additionally, we develop a two-stage training methodology that integrates Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO), systematically enhancing the Planner's tool selection accuracy and global planning awareness through structured DAG-based planning. When integrated with a capable executor, our framework achieves state-of-the-art performance on the StableToolBench benchmark for complex user queries, demonstrating superior end-to-end execution capabilities and robust handling of intricate multi-tool workflows.
Hierarchical RNNs-Based Transformers MADDPG for Mixed Cooperative-Competitive Environments
May 11, 2021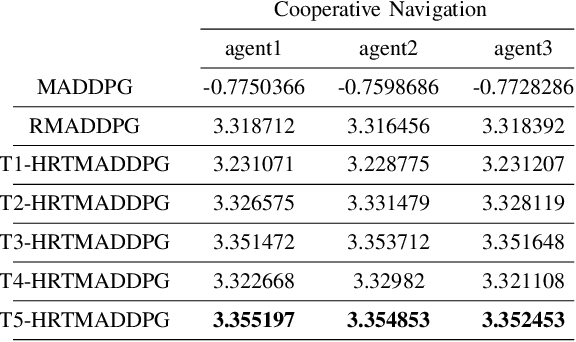
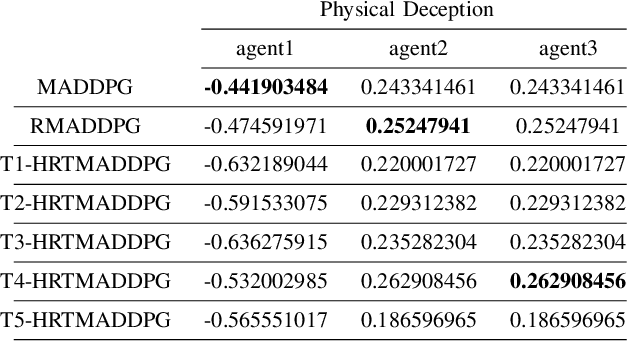
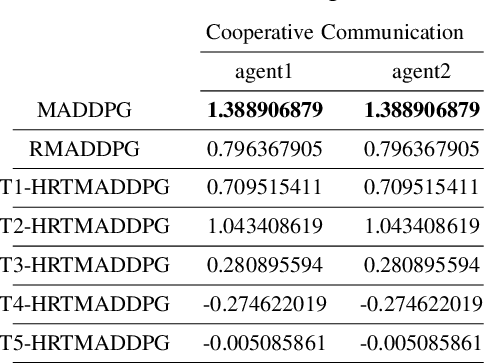
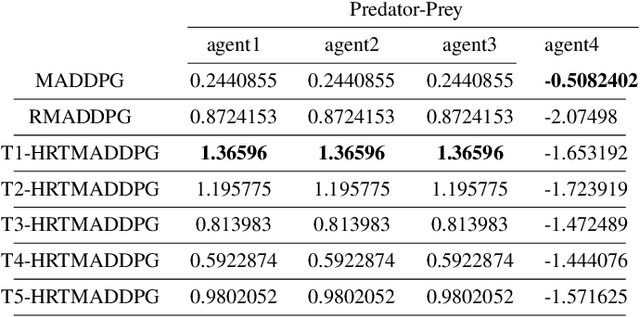
At present, attention mechanism has been widely applied to the fields of deep learning models. Structural models that based on attention mechanism can not only record the relationships between features position, but also can measure the importance of different features based on their weights. By establishing dynamically weighted parameters for choosing relevant and irrelevant features, the key information can be strengthened, and the irrelevant information can be weakened. Therefore, the efficiency of deep learning algorithms can be significantly elevated and improved. Although transformers have been performed very well in many fields including reinforcement learning, there are still many problems and applications can be solved and made with transformers within this area. MARL (known as Multi-Agent Reinforcement Learning) can be recognized as a set of independent agents trying to adapt and learn through their way to reach the goal. In order to emphasize the relationship between each MDP decision in a certain time period, we applied the hierarchical coding method and validated the effectiveness of this method. This paper proposed a hierarchical transformers MADDPG based on RNN which we call it Hierarchical RNNs-Based Transformers MADDPG(HRTMADDPG). It consists of a lower level encoder based on RNNs that encodes multiple step sizes in each time sequence, and it also consists of an upper sequence level encoder based on transformer for learning the correlations between multiple sequences so that we can capture the causal relationship between sub-time sequences and make HRTMADDPG more efficient.