 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZenFlow: Enabling Stall-Free Offloading Training via Asynchronous Updates
May 18, 2025Fine-tuning large language models (LLMs) often exceeds GPU memory limits, prompting systems to offload model states to CPU memory. However, existing offloaded training frameworks like ZeRO-Offload treat all parameters equally and update the full model on the CPU, causing severe GPU stalls, where fast, expensive GPUs sit idle waiting for slow CPU updates and limited-bandwidth PCIe transfers. We present ZenFlow, a new offloading framework that prioritizes important parameters and decouples updates between GPU and CPU. ZenFlow performs in-place updates of important gradients on GPU, while asynchronously offloading and accumulating less important ones on CPU, fully overlapping CPU work with GPU computation. To scale across GPUs, ZenFlow introduces a lightweight gradient selection method that exploits a novel spatial and temporal locality property of important gradients, avoiding costly global synchronization. ZenFlow achieves up to 5x end-to-end speedup, 2x lower PCIe traffic, and reduces GPU stalls by over 85 percent, all while preserving accuracy.
LCGC: Learning from Consistency Gradient Conflicting for Class-Imbalanced Semi-Supervised Debiasing
Apr 09, 2025Classifiers often learn to be biased corresponding to the class-imbalanced dataset, especially under the semi-supervised learning (SSL) set. While previous work tries to appropriately re-balance the classifiers by subtracting a class-irrelevant image's logit, but lacks a firm theoretical basis. We theoretically analyze why exploiting a baseline image can refine pseudo-labels and prove that the black image is the best choice. We also indicated that as the training process deepens, the pseudo-labels before and after refinement become closer. Based on this observation, we propose a debiasing scheme dubbed LCGC, which Learning from Consistency Gradient Conflicting, by encouraging biased class predictions during training. We intentionally update the pseudo-labels whose gradient conflicts with the debiased logits, representing the optimization direction offered by the over-imbalanced classifier predictions. Then, we debiased the predictions by subtracting the baseline image logits during testing. Extensive experiments demonstrate that LCGC can significantly improve the prediction accuracy of existing CISSL models on public benchmarks.
Ensuring Fair LLM Serving Amid Diverse Applications
Nov 24, 2024



In a multi-tenant large language model (LLM) serving platform hosting diverse applications, some users may submit an excessive number of requests, causing the service to become unavailable to other users and creating unfairness. Existing fairness approaches do not account for variations in token lengths across applications and multiple LLM calls, making them unsuitable for such platforms. To address the fairness challenge, this paper analyzes millions of requests from thousands of users on MS CoPilot, a real-world multi-tenant LLM platform hosted by Microsoft. Our analysis confirms the inadequacy of existing methods and guides the development of FairServe, a system that ensures fair LLM access across diverse applications. FairServe proposes application-characteristic aware request throttling coupled with a weighted service counter based scheduling technique to curb abusive behavior and ensure fairness. Our experimental results on real-world traces demonstrate FairServe's superior performance compared to the state-of-the-art method in ensuring fairness. We are actively working on deploying our system in production, expecting to benefit millions of customers world-wide.
LOCAL: Learning with Orientation Matrix to Infer Causal Structure from Time Series Data
Oct 28, 2024



Discovering the underlying Directed Acyclic Graph (DAG) from time series observational data is highly challenging due to the dynamic nature and complex nonlinear interactions between variables. Existing methods often struggle with inefficiency and the handling of high-dimensional data. To address these research gap, we propose LOCAL, a highly efficient, easy-to-implement, and constraint-free method for recovering dynamic causal structures. LOCAL is the first attempt to formulate a quasi-maximum likelihood-based score function for learning the dynamic DAG equivalent to the ground truth. On this basis, we propose two adaptive modules for enhancing the algebraic characterization of acyclicity with new capabilities: Asymptotic Causal Mask Learning (ACML) and Dynamic Graph Parameter Learning (DGPL). ACML generates causal masks using learnable priority vectors and the Gumbel-Sigmoid function, ensuring the creation of DAGs while optimizing computational efficiency. DGPL transforms causal learning into decomposed matrix products, capturing the dynamic causal structure of high-dimensional data and enhancing interpretability. Extensive experiments on synthetic and real-world datasets demonstrate that LOCAL significantly outperforms existing methods, and highlight LOCAL's potential as a robust and efficient method for dynamic causal discovery. Our code will be available soon.
LinBridge: A Learnable Framework for Interpreting Nonlinear Neural Encoding Models
Oct 26, 2024



Neural encoding of artificial neural networks (ANNs) links their computational representations to brain responses, offering insights into how the brain processes information. Current studies mostly use linear encoding models for clarity, even though brain responses are often nonlinear. This has sparked interest in developing nonlinear encoding models that are still interpretable. To address this problem, we propose LinBridge, a learnable and flexible framework based on Jacobian analysis for interpreting nonlinear encoding models. LinBridge posits that the nonlinear mapping between ANN representations and neural responses can be factorized into a linear inherent component that approximates the complex nonlinear relationship, and a mapping bias that captures sample-selective nonlinearity. The Jacobian matrix, which reflects output change rates relative to input, enables the analysis of sample-selective mapping in nonlinear models. LinBridge employs a self-supervised learning strategy to extract both the linear inherent component and nonlinear mapping biases from the Jacobian matrices of the test set, allowing it to adapt effectively to various nonlinear encoding models. We validate the LinBridge framework in the scenario of neural visual encoding, using computational visual representations from CLIP-ViT to predict brain activity recorded via functional magnetic resonance imaging (fMRI). Our experimental results demonstrate that: 1) the linear inherent component extracted by LinBridge accurately reflects the complex mappings of nonlinear neural encoding models; 2) the sample-selective mapping bias elucidates the variability of nonlinearity across different levels of the visual processing hierarchy. This study presents a novel tool for interpreting nonlinear neural encoding models and offers fresh evidence about hierarchical nonlinearity distribution in the visual cortex.
Everything You Always Wanted to Know About Storage Compressibility of Pre-Trained ML Models but Were Afraid to Ask
Feb 20, 2024As the number of pre-trained machine learning (ML) models is growing exponentially, data reduction tools are not catching up. Existing data reduction techniques are not specifically designed for pre-trained model (PTM) dataset files. This is largely due to a lack of understanding of the patterns and characteristics of these datasets, especially those relevant to data reduction and compressibility. This paper presents the first, exhaustive analysis to date of PTM datasets on storage compressibility. Our analysis spans different types of data reduction and compression techniques, from hash-based data deduplication, data similarity detection, to dictionary-coding compression. Our analysis explores these techniques at three data granularity levels, from model layers, model chunks, to model parameters. We draw new observations that indicate that modern data reduction tools are not effective when handling PTM datasets. There is a pressing need for new compression methods that take into account PTMs' data characteristics for effective storage reduction. Motivated by our findings, we design ELF, a simple yet effective, error-bounded, lossy floating-point compression method. ELF transforms floating-point parameters in such a way that the common exponent field of the transformed parameters can be completely eliminated to save storage space. We develop Elves, a compression framework that integrates ELF along with several other data reduction methods. Elves uses the most effective method to compress PTMs that exhibit different patterns. Evaluation shows that Elves achieves an overall compression ratio of $1.52\times$, which is $1.31\times$, $1.32\times$ and $1.29\times$ higher than a general-purpose compressor (zstd), an error-bounded lossy compressor (SZ3), and the uniform model quantization, respectively, with negligible model accuracy loss.
Beyond Efficiency: A Systematic Survey of Resource-Efficient Large Language Models
Jan 04, 2024The burgeoning field of Large Language Models (LLMs), exemplified by sophisticated models like OpenAI's ChatGPT, represents a significant advancement in artificial intelligence. These models, however, bring forth substantial challenges in the high consumption of computational, memory, energy, and financial resources, especially in environments with limited resource capabilities. This survey aims to systematically address these challenges by reviewing a broad spectrum of techniques designed to enhance the resource efficiency of LLMs. We categorize methods based on their optimization focus: computational, memory, energy, financial, and network resources and their applicability across various stages of an LLM's lifecycle, including architecture design, pretraining, finetuning, and system design. Additionally, the survey introduces a nuanced categorization of resource efficiency techniques by their specific resource types, which uncovers the intricate relationships and mappings between various resources and corresponding optimization techniques. A standardized set of evaluation metrics and datasets is also presented to facilitate consistent and fair comparisons across different models and techniques. By offering a comprehensive overview of the current sota and identifying open research avenues, this survey serves as a foundational reference for researchers and practitioners, aiding them in developing more sustainable and efficient LLMs in a rapidly evolving landscape.
Staleness-Alleviated Distributed GNN Training via Online Dynamic-Embedding Prediction
Aug 25, 2023



Despite the recent success of Graph Neural Networks (GNNs), it remains challenging to train GNNs on large-scale graphs due to neighbor explosions. As a remedy, distributed computing becomes a promising solution by leveraging abundant computing resources (e.g., GPU). However, the node dependency of graph data increases the difficulty of achieving high concurrency in distributed GNN training, which suffers from the massive communication overhead. To address it, Historical value approximation is deemed a promising class of distributed training techniques. It utilizes an offline memory to cache historical information (e.g., node embedding) as an affordable approximation of the exact value and achieves high concurrency. However, such benefits come at the cost of involving dated training information, leading to staleness, imprecision, and convergence issues. To overcome these challenges, this paper proposes SAT (Staleness-Alleviated Training), a novel and scalable distributed GNN training framework that reduces the embedding staleness adaptively. The key idea of SAT is to model the GNN's embedding evolution as a temporal graph and build a model upon it to predict future embedding, which effectively alleviates the staleness of the cached historical embedding. We propose an online algorithm to train the embedding predictor and the distributed GNN alternatively and further provide a convergence analysis. Empirically, we demonstrate that SAT can effectively reduce embedding staleness and thus achieve better performance and convergence speed on multiple large-scale graph datasets.
Distributed Graph Neural Network Training with Periodic Historical Embedding Synchronization
May 31, 2022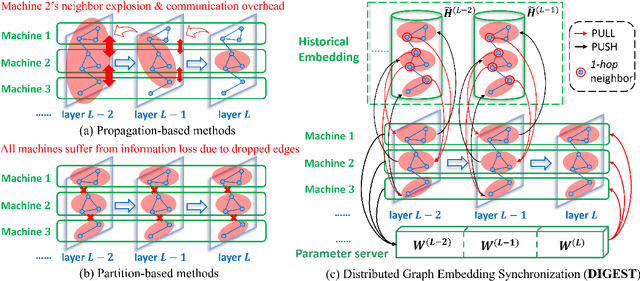

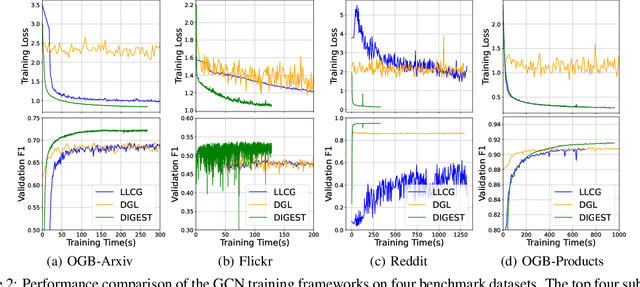

Despite the recent success of Graph Neural Networks (GNNs), it remains challenging to train a GNN on large graphs, which are prevalent in various applications such as social network, recommender systems, and knowledge graphs. Traditional sampling-based methods accelerate GNN by dropping edges and nodes, which impairs the graph integrity and model performance. Differently, distributed GNN algorithms, which accelerate GNN training by utilizing multiple computing devices, can be classified into two types: "partition-based" methods enjoy low communication costs but suffer from information loss due to dropped edges, while "propagation-based" methods avoid information loss but suffer prohibitive communication overhead. To jointly address these problems, this paper proposes DIstributed Graph Embedding SynchronizaTion (DIGEST), a novel distributed GNN training framework that synergizes the complementary strength of both categories of existing methods. During subgraph parallel training, we propose to let each device store the historical embedding of its neighbors in other subgraphs. Therefore, our method does not discard any neighbors in other subgraphs, nor does it updates them intensively. This effectively avoids (1) the intensive computation on explosively-increasing neighbors and (2) excessive communications across different devices. We proved that the approximation error induced by the staleness of historical embedding can be upper bounded and it does NOT affect the GNN model's expressiveness. More importantly, our convergence analysis demonstrates that DIGEST enjoys a state-of-the-art convergence rate. Extensive experimental evaluation on large, real-world graph datasets shows that DIGEST achieves up to $21.82\times$ speedup without compromising the performance compared to state-of-the-art distributed GNN training frameworks.
A Distributed and Elastic Aggregation Service for Scalable Federated Learning Systems
Apr 16, 2022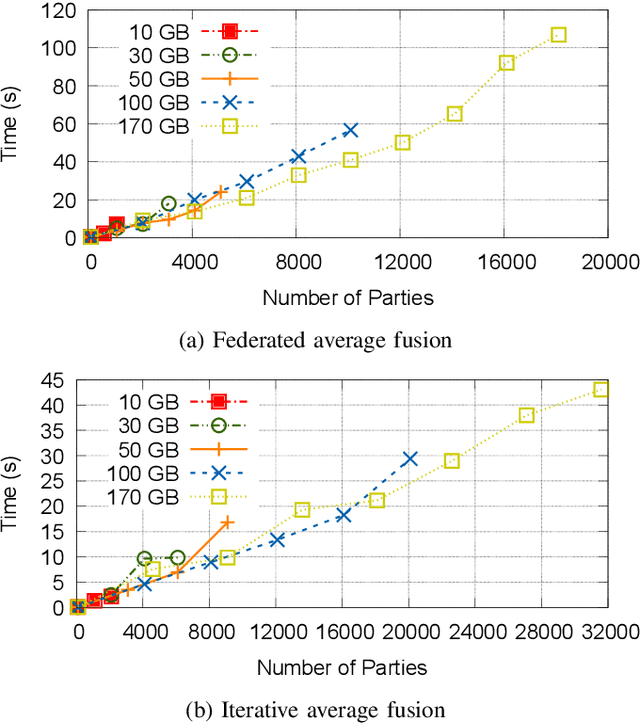
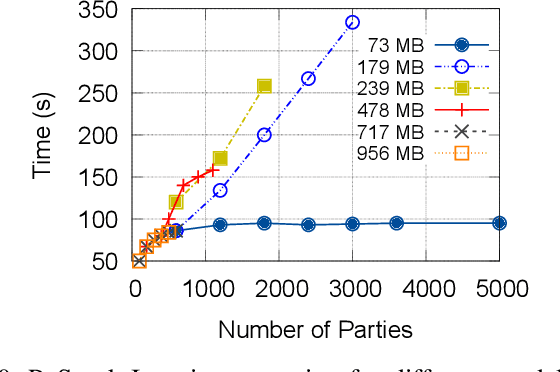
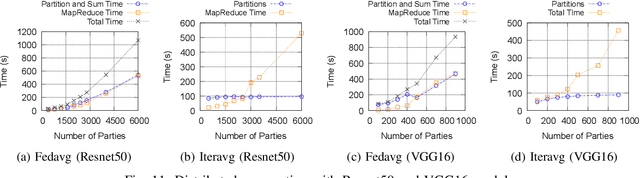
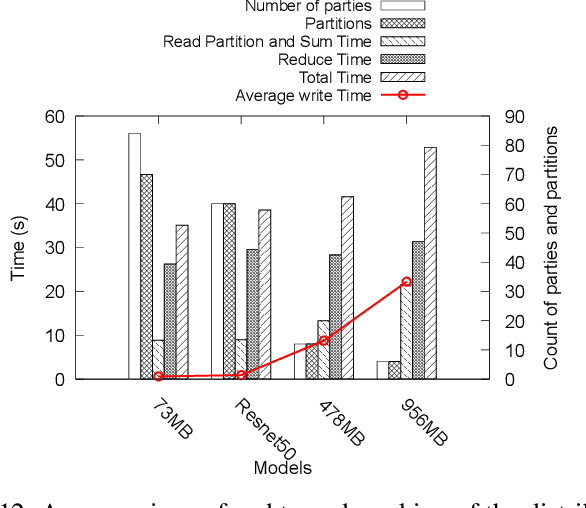
Federated Learning has promised a new approach to resolve the challenges in machine learning by bringing computation to the data. The popularity of the approach has led to rapid progress in the algorithmic aspects and the emergence of systems capable of simulating Federated Learning. State of art systems in Federated Learning support a single node aggregator that is insufficient to train a large corpus of devices or train larger-sized models. As the model size or the number of devices increase the single node aggregator incurs memory and computation burden while performing fusion tasks. It also faces communication bottlenecks when a large number of model updates are sent to a single node. We classify the workload for the aggregator into categories and propose a new aggregation service for handling each load. Our aggregation service is based on a holistic approach that chooses the best solution depending on the model update size and the number of clients. Our system provides a fault-tolerant, robust and efficient aggregation solution utilizing existing parallel and distributed frameworks. Through evaluation, we show the shortcomings of the state of art approaches and how a single solution is not suitable for all aggregation requirements. We also provide a comparison of current frameworks with our system through extensive experiments.