 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViviDoc: Generating Interactive Documents through Human-Agent Collaboration
Mar 30, 2026Interactive documents help readers engage with complex ideas through dynamic visualization, interactive animations, and exploratory interfaces. However, creating such documents remains costly, as it requires both domain expertise and web development skills. Recent Large Language Model (LLM)-based agents can automate content creation, but directly applying them to interactive document generation often produces outputs that are difficult to control. To address this, we present ViviDoc, to the best of our knowledge the first work to systematically address interactive document generation. ViviDoc introduces a multi-agent pipeline (Planner, Styler, Executor, Evaluator). To make the generation process controllable, we provide three levels of human control: (1) the Document Specification (DocSpec) with SRTC Interaction Specifications (State, Render, Transition, Constraint) for structured planning, (2) a content-aware Style Palette for customizing writing and interaction styles, and (3) chat-based editing for iterative refinement. We also construct ViviBench, a benchmark of 101 topics derived from real-world interactive documents across 11 domains, along with a taxonomy of 8 interaction types and a 4-dimensional automated evaluation framework validated against human ratings (Pearson r > 0.84). Experiments show that ViviDoc achieves the highest content richness and interaction quality in both automated and human evaluation. A 12-person user study confirms that the system is easy to use, provides effective control over the generation process, and produces documents that satisfy users.
Demonstrating ViviDoc: Generating Interactive Documents through Human-Agent Collaboration
Mar 02, 2026Interactive articles help readers engage with complex ideas through exploration, yet creating them remains costly, requiring both domain expertise and web development skills. Recent LLM-based agents can automate content creation, but naively applying them yields uncontrollable and unverifiable outputs. We present ViviDoc, a human-agent collaborative system that generates interactive educational documents from a single topic input. ViviDoc introduces a multi-agent pipeline (Planner, Executor, Evaluator) and the Document Specification (DocSpec), a human-readable intermediate representation that decomposes each interactive visualization into State, Render, Transition, and Constraint components. The DocSpec enables educators to review and refine generation plans before code is produced, bridging the gap between pedagogical intent and executable output. Expert evaluation and a user study show that ViviDoc substantially outperforms naive agentic generation and provides an intuitive editing experience. Our project homepage is available at https://vividoc-homepage.vercel.app/.
IGenBench: Benchmarking the Reliability of Text-to-Infographic Generation
Jan 08, 2026Infographics are composite visual artifacts that combine data visualizations with textual and illustrative elements to communicate information. While recent text-to-image (T2I) models can generate aesthetically appealing images, their reliability in generating infographics remains unclear. Generated infographics may appear correct at first glance but contain easily overlooked issues, such as distorted data encoding or incorrect textual content. We present IGENBENCH, the first benchmark for evaluating the reliability of text-to-infographic generation, comprising 600 curated test cases spanning 30 infographic types. We design an automated evaluation framework that decomposes reliability verification into atomic yes/no questions based on a taxonomy of 10 question types. We employ multimodal large language models (MLLMs) to verify each question, yielding question-level accuracy (Q-ACC) and infographic-level accuracy (I-ACC). We comprehensively evaluate 10 state-of-the-art T2I models on IGENBENCH. Our systematic analysis reveals key insights for future model development: (i) a three-tier performance hierarchy with the top model achieving Q-ACC of 0.90 but I-ACC of only 0.49; (ii) data-related dimensions emerging as universal bottlenecks (e.g., Data Completeness: 0.21); and (iii) the challenge of achieving end-to-end correctness across all models. We release IGENBENCH at https://igen-bench.vercel.app/.
SCORPIO: Serving the Right Requests at the Right Time for Heterogeneous SLOs in LLM Inference
May 29, 2025



Existing Large Language Model (LLM) serving systems prioritize maximum throughput. They often neglect Service Level Objectives (SLOs) such as Time to First Token (TTFT) and Time Per Output Token (TPOT), which leads to suboptimal SLO attainment. This paper introduces SCORPIO, an SLO-oriented LLM serving system designed to maximize system goodput and SLO attainment for workloads with heterogeneous SLOs. Our core insight is to exploit SLO heterogeneity for adaptive scheduling across admission control, queue management, and batch selection. SCORPIO features a TTFT Guard, which employs least-deadline-first reordering and rejects unattainable requests, and a TPOT Guard, which utilizes a VBS-based admission control and a novel credit-based batching mechanism. Both guards are supported by a predictive module. Evaluations demonstrate that SCORPIO improves system goodput by up to 14.4X and SLO adherence by up to 46.5% compared to state-of-the-art baselines.
ZenFlow: Enabling Stall-Free Offloading Training via Asynchronous Updates
May 18, 2025Fine-tuning large language models (LLMs) often exceeds GPU memory limits, prompting systems to offload model states to CPU memory. However, existing offloaded training frameworks like ZeRO-Offload treat all parameters equally and update the full model on the CPU, causing severe GPU stalls, where fast, expensive GPUs sit idle waiting for slow CPU updates and limited-bandwidth PCIe transfers. We present ZenFlow, a new offloading framework that prioritizes important parameters and decouples updates between GPU and CPU. ZenFlow performs in-place updates of important gradients on GPU, while asynchronously offloading and accumulating less important ones on CPU, fully overlapping CPU work with GPU computation. To scale across GPUs, ZenFlow introduces a lightweight gradient selection method that exploits a novel spatial and temporal locality property of important gradients, avoiding costly global synchronization. ZenFlow achieves up to 5x end-to-end speedup, 2x lower PCIe traffic, and reduces GPU stalls by over 85 percent, all while preserving accuracy.
ASPEN: High-Throughput LoRA Fine-Tuning of Large Language Models with a Single GPU
Dec 05, 2023

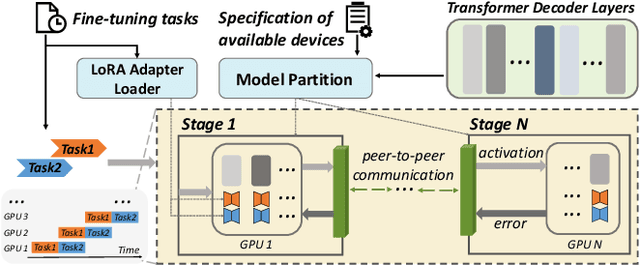
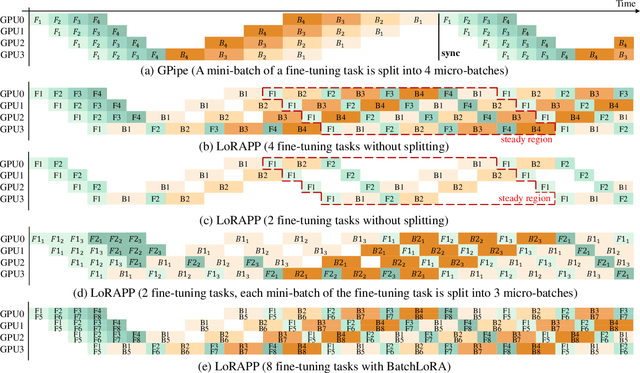
Transformer-based large language models (LLMs) have demonstrated outstanding performance across diverse domains, particularly when fine-turned for specific domains. Recent studies suggest that the resources required for fine-tuning LLMs can be economized through parameter-efficient methods such as Low-Rank Adaptation (LoRA). While LoRA effectively reduces computational burdens and resource demands, it currently supports only a single-job fine-tuning setup. In this paper, we present ASPEN, a high-throughput framework for fine-tuning LLMs. ASPEN efficiently trains multiple jobs on a single GPU using the LoRA method, leveraging shared pre-trained model and adaptive scheduling. ASPEN is compatible with transformer-based language models like LLaMA and ChatGLM, etc. Experiments show that ASPEN saves 53% of GPU memory when training multiple LLaMA-7B models on NVIDIA A100 80GB GPU and boosts training throughput by about 17% compared to existing methods when training with various pre-trained models on different GPUs. The adaptive scheduling algorithm reduces turnaround time by 24%, end-to-end training latency by 12%, prioritizing jobs and preventing out-of-memory issues.