 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling Is All You Need on Modeling Long-Term User Behaviors for CTR Prediction
May 20, 2022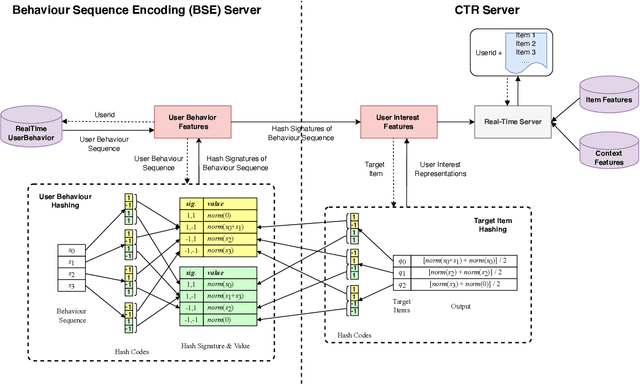

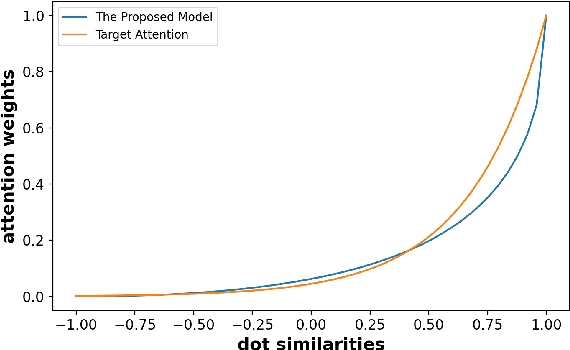
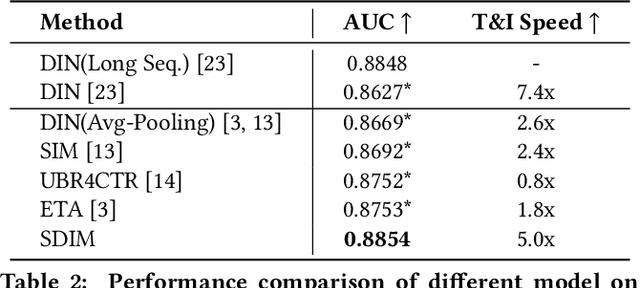
Rich user behavior data has been proven to be of great value for Click-Through Rate (CTR) prediction applications, especially in industrial recommender, search, or advertising systems. However, it's non-trivial for real-world systems to make full use of long-term user behaviors due to the strict requirements of online serving time. Most previous works adopt the retrieval-based strategy, where a small number of user behaviors are retrieved first for subsequent attention. However, the retrieval-based methods are sub-optimal and would cause more or less information losses, and it's difficult to balance the effectiveness and efficiency of the retrieval algorithm. In this paper, we propose \textbf{SDIM} (\textbf{S}ampling-based \textbf{D}eep \textbf{I}nterest \textbf{M}odeling), a simple yet effective sampling-based end-to-end approach for modeling long-term user behaviors. We sample from multiple hash functions to generate hash signatures of the candidate item and each item in the user behavior sequence, and obtain the user interest by directly gathering behavior items associated with the candidate item with the same hash signature. We show theoretically and experimentally that the proposed method performs on par with standard attention-based models on modeling long-term user behaviors, while being sizable times faster. We also introduce the deployment of SDIM in our system. Specifically, we decouple the behavior sequence hashing, which is the most time-consuming part, from the CTR model by designing a separate module named BSE (behavior Sequence Encoding). BSE is latency-free for the CTR server, enabling us to model extremely long user behaviors. Both offline and online experiments are conducted to demonstrate the effectiveness of SDIM. SDIM now has been deployed online in the search system of Meituan APP.
iCAR: Bridging Image Classification and Image-text Alignment for Visual Recognition
Apr 22, 2022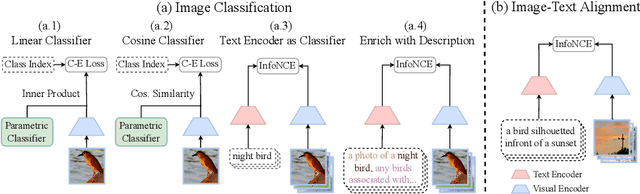

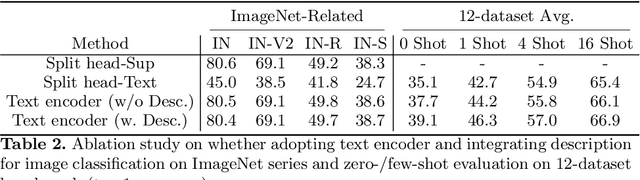
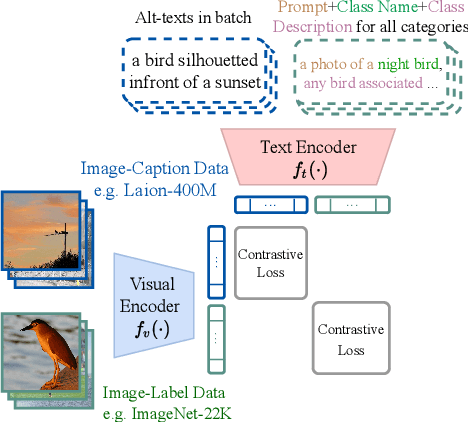
Image classification, which classifies images by pre-defined categories, has been the dominant approach to visual representation learning over the last decade. Visual learning through image-text alignment, however, has emerged to show promising performance, especially for zero-shot recognition. We believe that these two learning tasks are complementary, and suggest combining them for better visual learning. We propose a deep fusion method with three adaptations that effectively bridge two learning tasks, rather than shallow fusion through naive multi-task learning. First, we modify the previous common practice in image classification, a linear classifier, with a cosine classifier which shows comparable performance. Second, we convert the image classification problem from learning parametric category classifier weights to learning a text encoder as a meta network to generate category classifier weights. The learnt text encoder is shared between image classification and image-text alignment. Third, we enrich each class name with a description to avoid confusion between classes and make the classification method closer to the image-text alignment. We prove that this deep fusion approach performs better on a variety of visual recognition tasks and setups than the individual learning or shallow fusion approach, from zero-shot/few-shot image classification, such as the Kornblith 12-dataset benchmark, to downstream tasks of action recognition, semantic segmentation, and object detection in fine-tuning and open-vocabulary settings. The code will be available at https://github.com/weiyx16/iCAR.
Incorporating Semi-Supervised and Positive-Unlabeled Learning for Boosting Full Reference Image Quality Assessment
Apr 19, 2022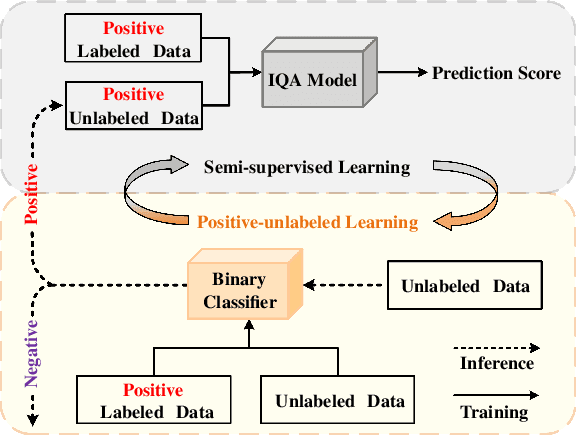
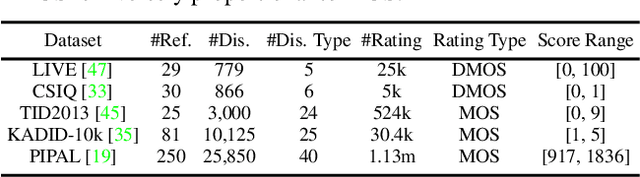
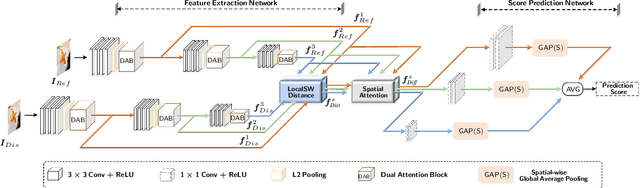
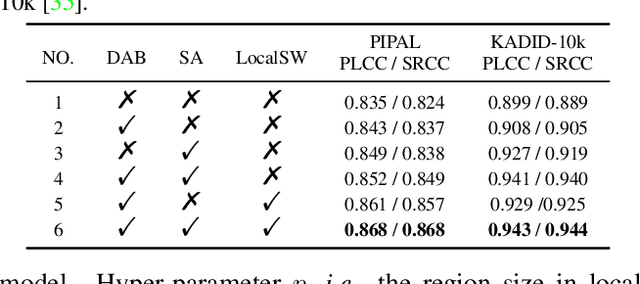
Full-reference (FR) image quality assessment (IQA) evaluates the visual quality of a distorted image by measuring its perceptual difference with pristine-quality reference, and has been widely used in low-level vision tasks. Pairwise labeled data with mean opinion score (MOS) are required in training FR-IQA model, but is time-consuming and cumbersome to collect. In contrast, unlabeled data can be easily collected from an image degradation or restoration process, making it encouraging to exploit unlabeled training data to boost FR-IQA performance. Moreover, due to the distribution inconsistency between labeled and unlabeled data, outliers may occur in unlabeled data, further increasing the training difficulty. In this paper, we suggest to incorporate semi-supervised and positive-unlabeled (PU) learning for exploiting unlabeled data while mitigating the adverse effect of outliers. Particularly, by treating all labeled data as positive samples, PU learning is leveraged to identify negative samples (i.e., outliers) from unlabeled data. Semi-supervised learning (SSL) is further deployed to exploit positive unlabeled data by dynamically generating pseudo-MOS. We adopt a dual-branch network including reference and distortion branches. Furthermore, spatial attention is introduced in the reference branch to concentrate more on the informative regions, and sliced Wasserstein distance is used for robust difference map computation to address the misalignment issues caused by images recovered by GAN models. Extensive experiments show that our method performs favorably against state-of-the-arts on the benchmark datasets PIPAL, KADID-10k, TID2013, LIVE and CSIQ.
Correlation-Aware Deep Tracking
Mar 03, 2022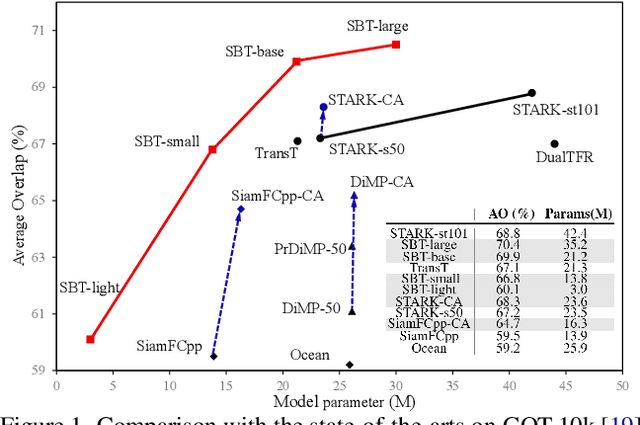

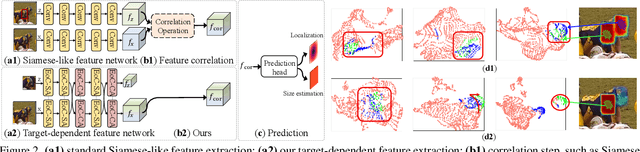
Robustness and discrimination power are two fundamental requirements in visual object tracking. In most tracking paradigms, we find that the features extracted by the popular Siamese-like networks cannot fully discriminatively model the tracked targets and distractor objects, hindering them from simultaneously meeting these two requirements. While most methods focus on designing robust correlation operations, we propose a novel target-dependent feature network inspired by the self-/cross-attention scheme. In contrast to the Siamese-like feature extraction, our network deeply embeds cross-image feature correlation in multiple layers of the feature network. By extensively matching the features of the two images through multiple layers, it is able to suppress non-target features, resulting in instance-varying feature extraction. The output features of the search image can be directly used for predicting target locations without extra correlation step. Moreover, our model can be flexibly pre-trained on abundant unpaired images, leading to notably faster convergence than the existing methods. Extensive experiments show our method achieves the state-of-the-art results while running at real-time. Our feature networks also can be applied to existing tracking pipelines seamlessly to raise the tracking performance. Code will be available.
Pre-Trained Neural Language Models for Automatic Mobile App User Feedback Answer Generation
Feb 04, 2022



Studies show that developers' answers to the mobile app users' feedbacks on app stores can increase the apps' star rating. To help app developers generate answers that are related to the users' issues, recent studies develop models to generate the answers automatically. Aims: The app response generation models use deep neural networks and require training data. Pre-Trained neural language Models (PTM) used in Natural Language Processing (NLP) take advantage of the information they learned from a large corpora in an unsupervised manner, and can reduce the amount of required training data. In this paper, we evaluate PTMs to generate replies to the mobile app user feedbacks. Method: We train a Transformer model from scratch and fine-tune two PTMs to evaluate the generated responses, which are compared to RRGEN, a current app response model. We also evaluate the models with different portions of the training data. Results: The results on a large dataset evaluated by automatic metrics show that PTMs obtain lower scores than the baselines. However, our human evaluation confirms that PTMs can generate more relevant and meaningful responses to the posted feedbacks. Moreover, the performance of PTMs has less drop compared to other models when the amount of training data is reduced to 1/3. Conclusion: PTMs are useful in generating responses to app reviews and are more robust models to the amount of training data provided. However, the prediction time is 19X than RRGEN. This study can provide new avenues for research in adapting the PTMs for analyzing mobile app user feedbacks. Index Terms-mobile app user feedback analysis, neural pre-trained language models, automatic answer generation
Self-supervised Learning from 100 Million Medical Images
Jan 04, 2022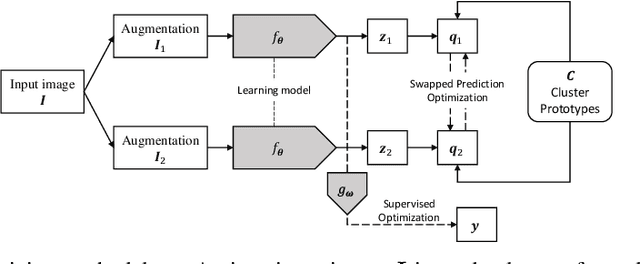
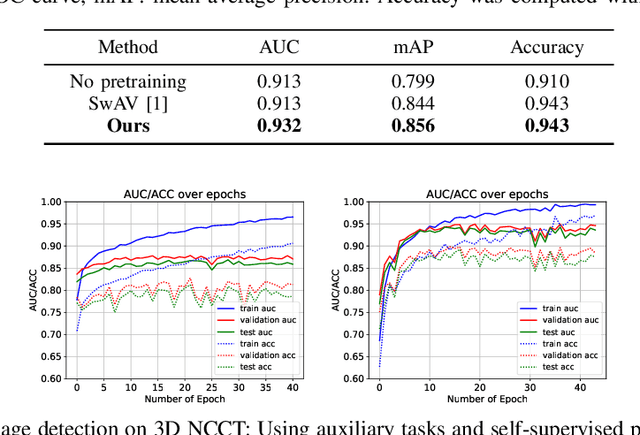
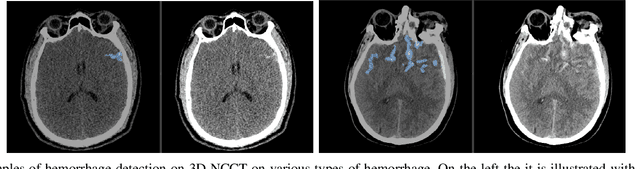
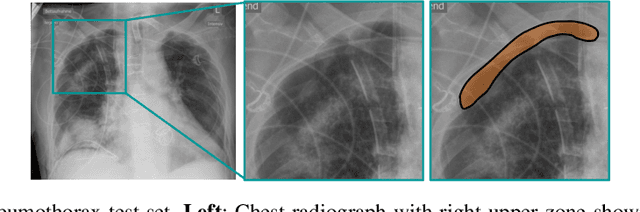
Building accurate and robust artificial intelligence systems for medical image assessment requires not only the research and design of advanced deep learning models but also the creation of large and curated sets of annotated training examples. Constructing such datasets, however, is often very costly -- due to the complex nature of annotation tasks and the high level of expertise required for the interpretation of medical images (e.g., expert radiologists). To counter this limitation, we propose a method for self-supervised learning of rich image features based on contrastive learning and online feature clustering. For this purpose we leverage large training datasets of over 100,000,000 medical images of various modalities, including radiography, computed tomography (CT), magnetic resonance (MR) imaging and ultrasonography. We propose to use these features to guide model training in supervised and hybrid self-supervised/supervised regime on various downstream tasks. We highlight a number of advantages of this strategy on challenging image assessment problems in radiography, CT and MR: 1) Significant increase in accuracy compared to the state-of-the-art (e.g., AUC boost of 3-7% for detection of abnormalities from chest radiography scans and hemorrhage detection on brain CT); 2) Acceleration of model convergence during training by up to 85% compared to using no pretraining (e.g., 83% when training a model for detection of brain metastases in MR scans); 3) Increase in robustness to various image augmentations, such as intensity variations, rotations or scaling reflective of data variation seen in the field.
A Simple Baseline for Zero-shot Semantic Segmentation with Pre-trained Vision-language Model
Dec 29, 2021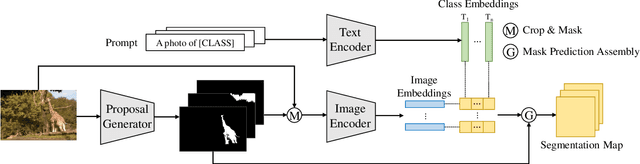
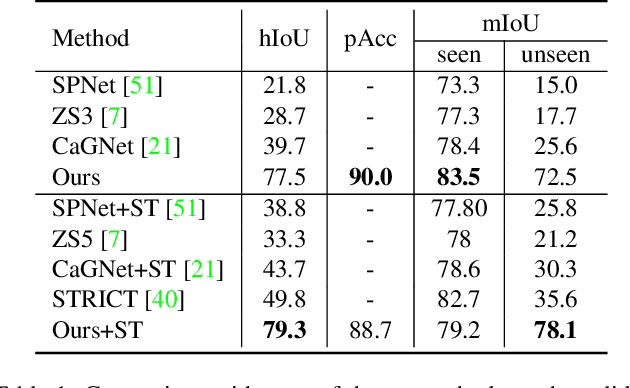

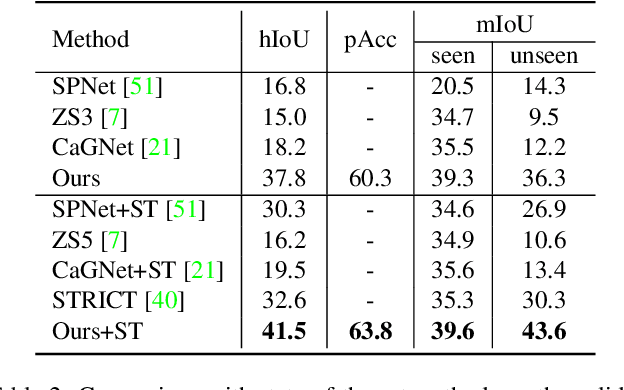
Recently, zero-shot image classification by vision-language pre-training has demonstrated incredible achievements, that the model can classify arbitrary category without seeing additional annotated images of that category. However, it is still unclear how to make the zero-shot recognition working well on broader vision problems, such as object detection and semantic segmentation. In this paper, we target for zero-shot semantic segmentation, by building it on an off-the-shelf pre-trained vision-language model, i.e., CLIP. It is difficult because semantic segmentation and the CLIP model perform on different visual granularity, that semantic segmentation processes on pixels while CLIP performs on images. To remedy the discrepancy on processing granularity, we refuse the use of the prevalent one-stage FCN based framework, and advocate a two-stage semantic segmentation framework, with the first stage extracting generalizable mask proposals and the second stage leveraging an image based CLIP model to perform zero-shot classification on the masked image crops which are generated in the first stage. Our experimental results show that this simple framework surpasses previous state-of-the-arts by a large margin: +29.5 hIoU on the Pascal VOC 2012 dataset, and +8.9 hIoU on the COCO Stuff dataset. With its simplicity and strong performance, we hope this framework to serve as a baseline to facilitate the future research.
SimMIM: A Simple Framework for Masked Image Modeling
Nov 18, 2021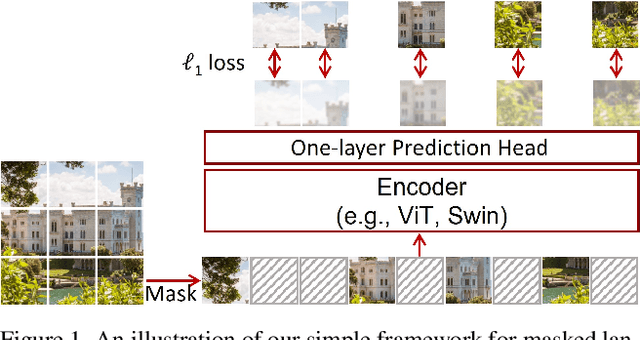
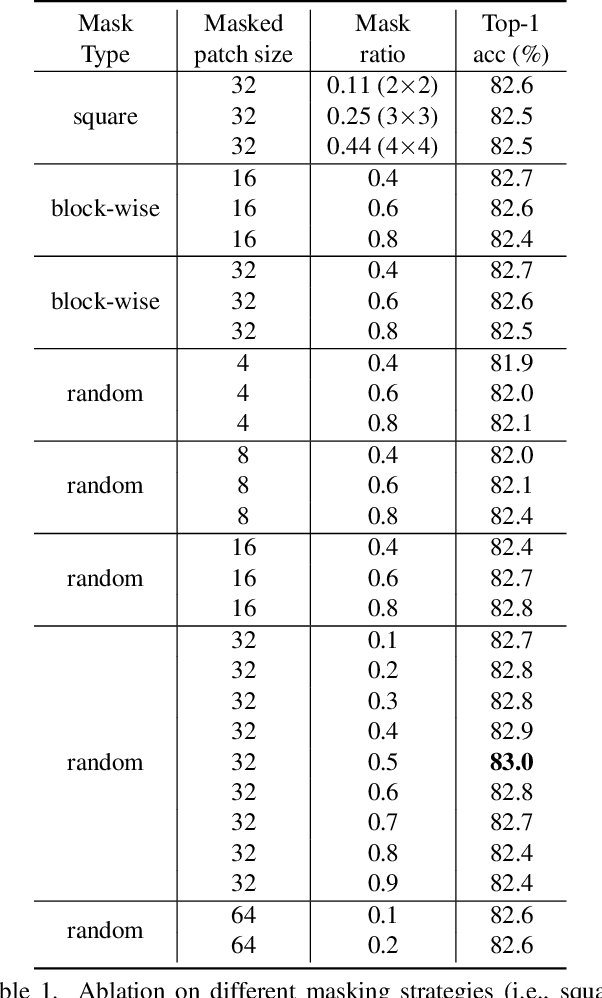

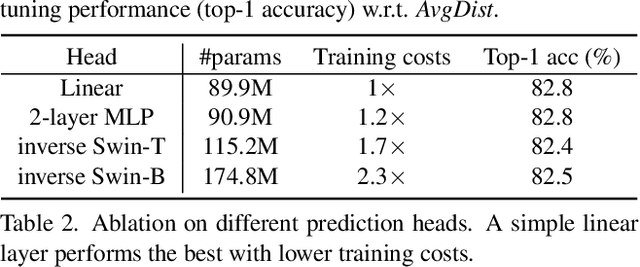
This paper presents SimMIM, a simple framework for masked image modeling. We simplify recently proposed related approaches without special designs such as block-wise masking and tokenization via discrete VAE or clustering. To study what let the masked image modeling task learn good representations, we systematically study the major components in our framework, and find that simple designs of each component have revealed very strong representation learning performance: 1) random masking of the input image with a moderately large masked patch size (e.g., 32) makes a strong pre-text task; 2) predicting raw pixels of RGB values by direct regression performs no worse than the patch classification approaches with complex designs; 3) the prediction head can be as light as a linear layer, with no worse performance than heavier ones. Using ViT-B, our approach achieves 83.8% top-1 fine-tuning accuracy on ImageNet-1K by pre-training also on this dataset, surpassing previous best approach by +0.6%. When applied on a larger model of about 650 million parameters, SwinV2-H, it achieves 87.1% top-1 accuracy on ImageNet-1K using only ImageNet-1K data. We also leverage this approach to facilitate the training of a 3B model (SwinV2-G), that by $40\times$ less data than that in previous practice, we achieve the state-of-the-art on four representative vision benchmarks. The code and models will be publicly available at https://github.com/microsoft/SimMIM.
Swin Transformer V2: Scaling Up Capacity and Resolution
Nov 18, 2021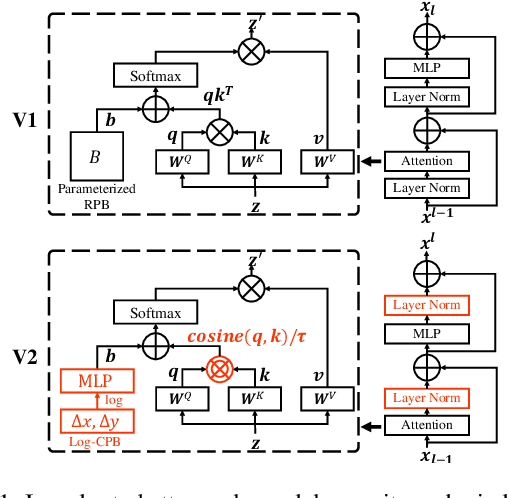
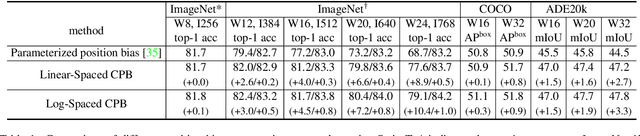
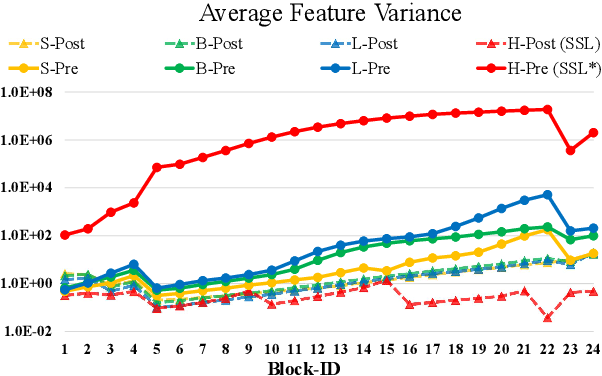
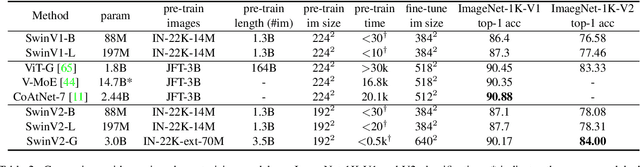
We present techniques for scaling Swin Transformer up to 3 billion parameters and making it capable of training with images of up to 1,536$\times$1,536 resolution. By scaling up capacity and resolution, Swin Transformer sets new records on four representative vision benchmarks: 84.0% top-1 accuracy on ImageNet-V2 image classification, 63.1/54.4 box/mask mAP on COCO object detection, 59.9 mIoU on ADE20K semantic segmentation, and 86.8% top-1 accuracy on Kinetics-400 video action classification. Our techniques are generally applicable for scaling up vision models, which has not been widely explored as that of NLP language models, partly due to the following difficulties in training and applications: 1) vision models often face instability issues at scale and 2) many downstream vision tasks require high resolution images or windows and it is not clear how to effectively transfer models pre-trained at low resolutions to higher resolution ones. The GPU memory consumption is also a problem when the image resolution is high. To address these issues, we present several techniques, which are illustrated by using Swin Transformer as a case study: 1) a post normalization technique and a scaled cosine attention approach to improve the stability of large vision models; 2) a log-spaced continuous position bias technique to effectively transfer models pre-trained at low-resolution images and windows to their higher-resolution counterparts. In addition, we share our crucial implementation details that lead to significant savings of GPU memory consumption and thus make it feasible to train large vision models with regular GPUs. Using these techniques and self-supervised pre-training, we successfully train a strong 3B Swin Transformer model and effectively transfer it to various vision tasks involving high-resolution images or windows, achieving the state-of-the-art accuracy on a variety of benchmarks.
Bootstrap Your Object Detector via Mixed Training
Nov 04, 2021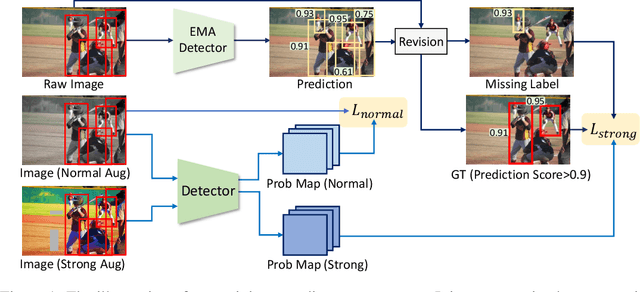


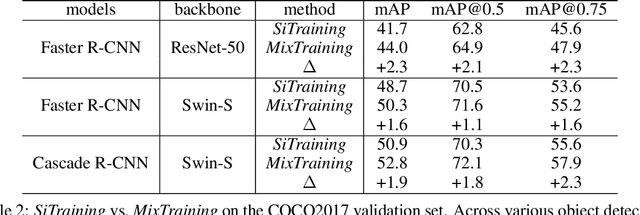
We introduce MixTraining, a new training paradigm for object detection that can improve the performance of existing detectors for free. MixTraining enhances data augmentation by utilizing augmentations of different strengths while excluding the strong augmentations of certain training samples that may be detrimental to training. In addition, it addresses localization noise and missing labels in human annotations by incorporating pseudo boxes that can compensate for these errors. Both of these MixTraining capabilities are made possible through bootstrapping on the detector, which can be used to predict the difficulty of training on a strong augmentation, as well as to generate reliable pseudo boxes thanks to the robustness of neural networks to labeling error. MixTraining is found to bring consistent improvements across various detectors on the COCO dataset. In particular, the performance of Faster R-CNN \cite{ren2015faster} with a ResNet-50 \cite{he2016deep} backbone is improved from 41.7 mAP to 44.0 mAP, and the accuracy of Cascade-RCNN \cite{cai2018cascade} with a Swin-Small \cite{liu2021swin} backbone is raised from 50.9 mAP to 52.8 mAP. The code and models will be made publicly available at \url{https://github.com/MendelXu/MixTraining}.