 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Structural Policy Gradient for Partially Observable Mean Field Games
Feb 23, 2026Mean Field Games (MFGs) provide a principled framework for modeling interactions in large population models: at scale, population dynamics become deterministic, with uncertainty entering only through aggregate shocks, or common noise. However, algorithmic progress has been limited since model-free methods are too high variance and exact methods scale poorly. Recent Hybrid Structural Methods (HSMs) use Monte Carlo rollouts for the common noise in combination with exact estimation of the expected return, conditioned on those samples. However, HSMs have not been scaled to Partially Observable settings. We propose Recurrent Structural Policy Gradient (RSPG), the first history-aware HSM for settings involving public information. We also introduce MFAX, our JAX-based framework for MFGs. By leveraging known transition dynamics, RSPG achieves state-of-the-art performance as well as an order-of-magnitude faster convergence and solves, for the first time, a macroeconomics MFG with heterogeneous agents, common noise and history-aware policies. MFAX is publicly available at: https://github.com/CWibault/mfax.
Reinforcement Learning for Fair Dynamic Pricing
Mar 27, 2018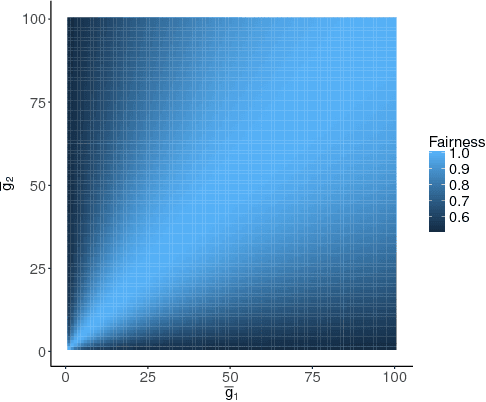
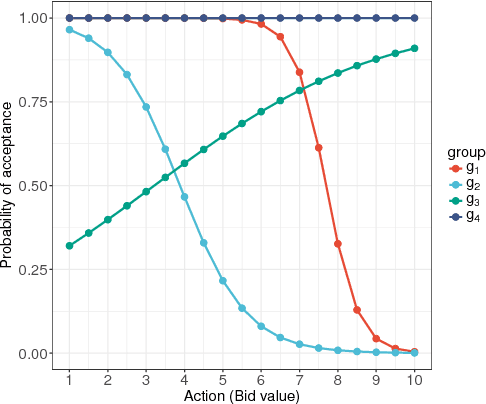
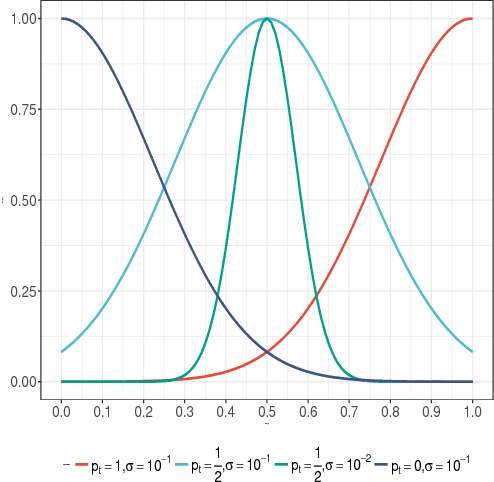
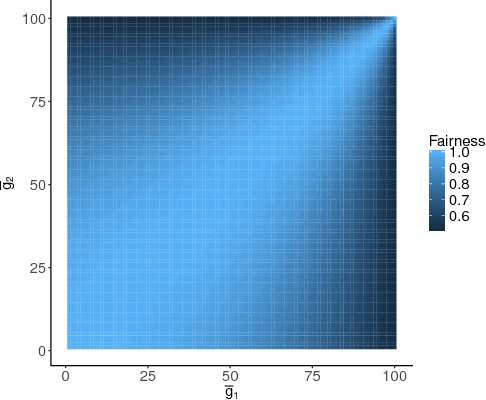
Unfair pricing policies have been shown to be one of the most negative perceptions customers can have concerning pricing, and may result in long-term losses for a company. Despite the fact that dynamic pricing models help companies maximize revenue, fairness and equality should be taken into account in order to avoid unfair price differences between groups of customers. This paper shows how to solve dynamic pricing by using Reinforcement Learning (RL) techniques so that prices are maximized while keeping a balance between revenue and fairness. We demonstrate that RL provides two main features to support fairness in dynamic pricing: on the one hand, RL is able to learn from recent experience, adapting the pricing policy to complex market environments; on the other hand, it provides a trade-off between short and long-term objectives, hence integrating fairness into the model's core. Considering these two features, we propose the application of RL for revenue optimization, with the additional integration of fairness as part of the learning procedure by using Jain's index as a metric. Results in a simulated environment show a significant improvement in fairness while at the same time maintaining optimisation of revenue.