 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dense and Continuous Optical Flow from an Event Camera
Nov 16, 2022



Event cameras such as DAVIS can simultaneously output high temporal resolution events and low frame-rate intensity images, which own great potential in capturing scene motion, such as optical flow estimation. Most of the existing optical flow estimation methods are based on two consecutive image frames and can only estimate discrete flow at a fixed time interval. Previous work has shown that continuous flow estimation can be achieved by changing the quantities or time intervals of events. However, they are difficult to estimate reliable dense flow , especially in the regions without any triggered events. In this paper, we propose a novel deep learning-based dense and continuous optical flow estimation framework from a single image with event streams, which facilitates the accurate perception of high-speed motion. Specifically, we first propose an event-image fusion and correlation module to effectively exploit the internal motion from two different modalities of data. Then we propose an iterative update network structure with bidirectional training for optical flow prediction. Therefore, our model can estimate reliable dense flow as two-frame-based methods, as well as estimate temporal continuous flow as event-based methods. Extensive experimental results on both synthetic and real captured datasets demonstrate that our model outperforms existing event-based state-of-the-art methods and our designed baselines for accurate dense and continuous optical flow estimation.
CU-Net: LiDAR Depth-Only Completion With Coupled U-Net
Oct 26, 2022



LiDAR depth-only completion is a challenging task to estimate dense depth maps only from sparse measurement points obtained by LiDAR. Even though the depth-only methods have been widely developed, there is still a significant performance gap with the RGB-guided methods that utilize extra color images. We find that existing depth-only methods can obtain satisfactory results in the areas where the measurement points are almost accurate and evenly distributed (denoted as normal areas), while the performance is limited in the areas where the foreground and background points are overlapped due to occlusion (denoted as overlap areas) and the areas where there are no measurement points around (denoted as blank areas) since the methods have no reliable input information in these areas. Building upon these observations, we propose an effective Coupled U-Net (CU-Net) architecture for depth-only completion. Instead of directly using a large network for regression, we employ the local U-Net to estimate accurate values in the normal areas and provide the global U-Net with reliable initial values in the overlap and blank areas. The depth maps predicted by the two coupled U-Nets are fused by learned confidence maps to obtain final results. In addition, we propose a confidence-based outlier removal module, which removes outliers using simple judgment conditions. Our proposed method boosts the final results with fewer parameters and achieves state-of-the-art results on the KITTI benchmark. Moreover, it owns a powerful generalization ability under various depth densities, varying lighting, and weather conditions.
Searching Dense Point Correspondences via Permutation Matrix Learning
Oct 26, 2022



Although 3D point cloud data has received widespread attentions as a general form of 3D signal expression, applying point clouds to the task of dense correspondence estimation between 3D shapes has not been investigated widely. Furthermore, even in the few existing 3D point cloud-based methods, an important and widely acknowledged principle, i.e . one-to-one matching, is usually ignored. In response, this paper presents a novel end-to-end learning-based method to estimate the dense correspondence of 3D point clouds, in which the problem of point matching is formulated as a zero-one assignment problem to achieve a permutation matching matrix to implement the one-to-one principle fundamentally. Note that the classical solutions of this assignment problem are always non-differentiable, which is fatal for deep learning frameworks. Thus we design a special matching module, which solves a doubly stochastic matrix at first and then projects this obtained approximate solution to the desired permutation matrix. Moreover, to guarantee end-to-end learning and the accuracy of the calculated loss, we calculate the loss from the learned permutation matrix but propagate the gradient to the doubly stochastic matrix directly which bypasses the permutation matrix during the backward propagation. Our method can be applied to both non-rigid and rigid 3D point cloud data and extensive experiments show that our method achieves state-of-the-art performance for dense correspondence learning.
Learning a Task-specific Descriptor for Robust Matching of 3D Point Clouds
Oct 26, 2022



Existing learning-based point feature descriptors are usually task-agnostic, which pursue describing the individual 3D point clouds as accurate as possible. However, the matching task aims at describing the corresponding points consistently across different 3D point clouds. Therefore these too accurate features may play a counterproductive role due to the inconsistent point feature representations of correspondences caused by the unpredictable noise, partiality, deformation, \etc, in the local geometry. In this paper, we propose to learn a robust task-specific feature descriptor to consistently describe the correct point correspondence under interference. Born with an Encoder and a Dynamic Fusion module, our method EDFNet develops from two aspects. First, we augment the matchability of correspondences by utilizing their repetitive local structure. To this end, a special encoder is designed to exploit two input point clouds jointly for each point descriptor. It not only captures the local geometry of each point in the current point cloud by convolution, but also exploits the repetitive structure from paired point cloud by Transformer. Second, we propose a dynamical fusion module to jointly use different scale features. There is an inevitable struggle between robustness and discriminativeness of the single scale feature. Specifically, the small scale feature is robust since little interference exists in this small receptive field. But it is not sufficiently discriminative as there are many repetitive local structures within a point cloud. Thus the resultant descriptors will lead to many incorrect matches. In contrast, the large scale feature is more discriminative by integrating more neighborhood information. ...
Deep Idempotent Network for Efficient Single Image Blind Deblurring
Oct 18, 2022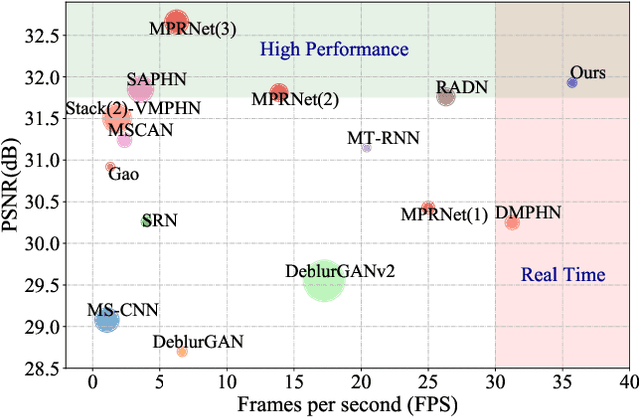


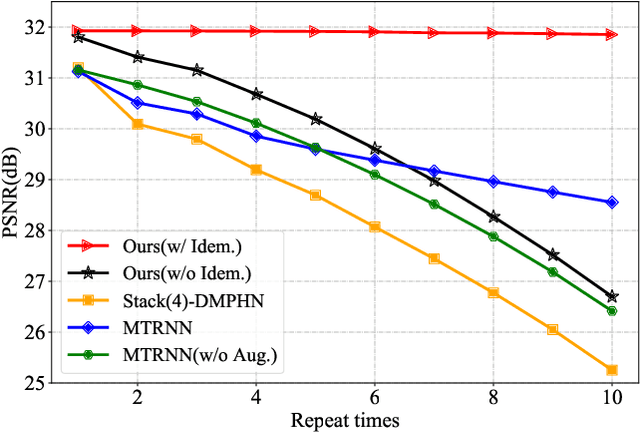
Single image blind deblurring is highly ill-posed as neither the latent sharp image nor the blur kernel is known. Even though considerable progress has been made, several major difficulties remain for blind deblurring, including the trade-off between high-performance deblurring and real-time processing. Besides, we observe that current single image blind deblurring networks cannot further improve or stabilize the performance but significantly degrades the performance when re-deblurring is repeatedly applied. This implies the limitation of these networks in modeling an ideal deblurring process. In this work, we make two contributions to tackle the above difficulties: (1) We introduce the idempotent constraint into the deblurring framework and present a deep idempotent network to achieve improved blind non-uniform deblurring performance with stable re-deblurring. (2) We propose a simple yet efficient deblurring network with lightweight encoder-decoder units and a recurrent structure that can deblur images in a progressive residual fashion. Extensive experiments on synthetic and realistic datasets prove the superiority of our proposed framework. Remarkably, our proposed network is nearly 6.5X smaller and 6.4X faster than the state-of-the-art while achieving comparable high performance.
Linear Video Transformer with Feature Fixation
Oct 15, 2022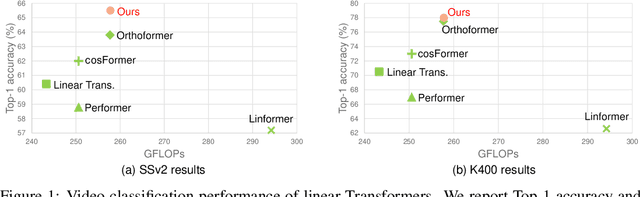
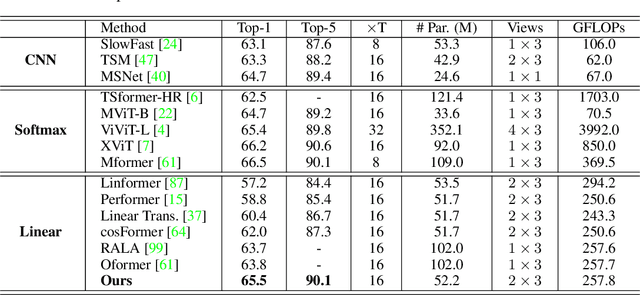

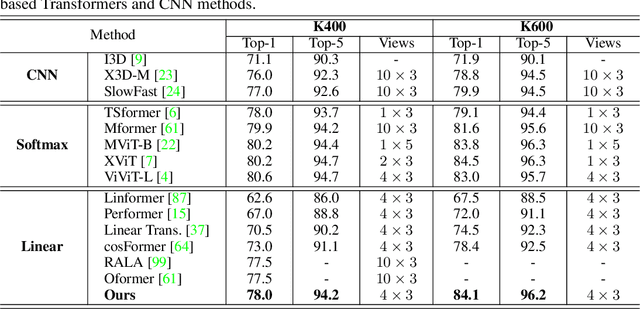
Vision Transformers have achieved impressive performance in video classification, while suffering from the quadratic complexity caused by the Softmax attention mechanism. Some studies alleviate the computational costs by reducing the number of tokens in attention calculation, but the complexity is still quadratic. Another promising way is to replace Softmax attention with linear attention, which owns linear complexity but presents a clear performance drop. We find that such a drop in linear attention results from the lack of attention concentration on critical features. Therefore, we propose a feature fixation module to reweight the feature importance of the query and key before computing linear attention. Specifically, we regard the query, key, and value as various latent representations of the input token, and learn the feature fixation ratio by aggregating Query-Key-Value information. This is beneficial for measuring the feature importance comprehensively. Furthermore, we enhance the feature fixation by neighborhood association, which leverages additional guidance from spatial and temporal neighbouring tokens. The proposed method significantly improves the linear attention baseline and achieves state-of-the-art performance among linear video Transformers on three popular video classification benchmarks. With fewer parameters and higher efficiency, our performance is even comparable to some Softmax-based quadratic Transformers.
Rolling Shutter Inversion: Bring Rolling Shutter Images to High Framerate Global Shutter Video
Oct 06, 2022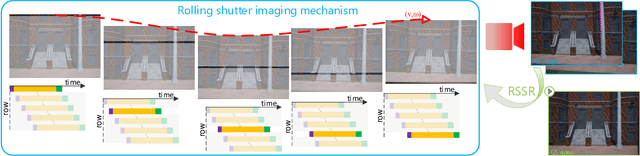
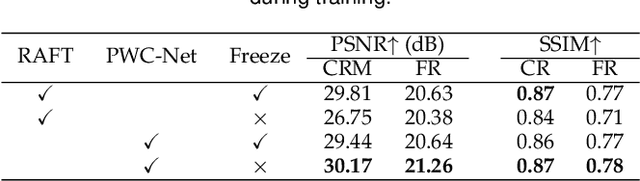
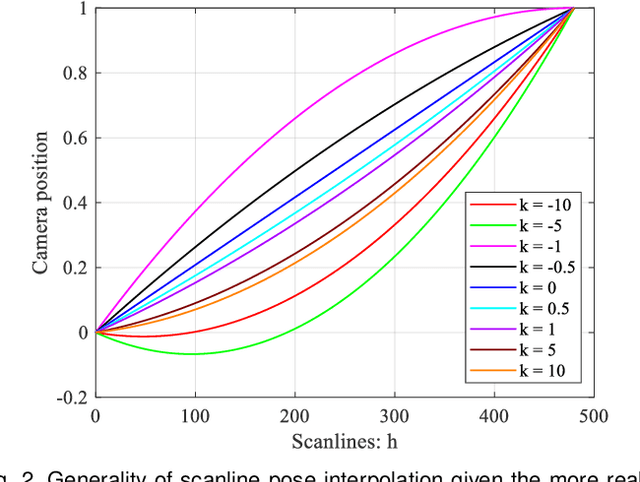
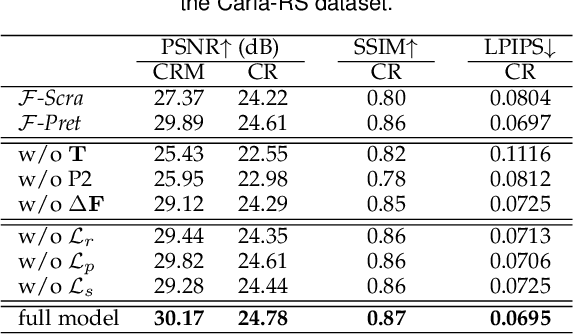
A single rolling-shutter (RS) image may be viewed as a row-wise combination of a sequence of global-shutter (GS) images captured by a (virtual) moving GS camera within the exposure duration. Although RS cameras are widely used, the RS effect causes obvious image distortion especially in the presence of fast camera motion, hindering downstream computer vision tasks. In this paper, we propose to invert the RS image capture mechanism, i.e., recovering a continuous high framerate GS video from two time-consecutive RS frames. We call this task the RS temporal super-resolution (RSSR) problem. The RSSR is a very challenging task, and to our knowledge, no practical solution exists to date. This paper presents a novel deep-learning based solution. By leveraging the multi-view geometry relationship of the RS imaging process, our learning-based framework successfully achieves high framerate GS generation. Specifically, three novel contributions can be identified: (i) novel formulations for bidirectional RS undistortion flows under constant velocity as well as constant acceleration motion model. (ii) a simple linear scaling operation, which bridges the RS undistortion flow and regular optical flow. (iii) a new mutual conversion scheme between varying RS undistortion flows that correspond to different scanlines. Our method also exploits the underlying spatial-temporal geometric relationships within a deep learning framework, where no additional supervision is required beyond the necessary middle-scanline GS image. Building upon these contributions, we represent the very first rolling-shutter temporal super-resolution deep-network that is able to recover high framerate GS videos from just two RS frames. Extensive experimental results on both synthetic and real data show that our proposed method can produce high-quality GS image sequences with rich details, outperforming the state-of-the-art methods.
Efficient Spatial-Temporal Information Fusion for LiDAR-Based 3D Moving Object Segmentation
Jul 05, 2022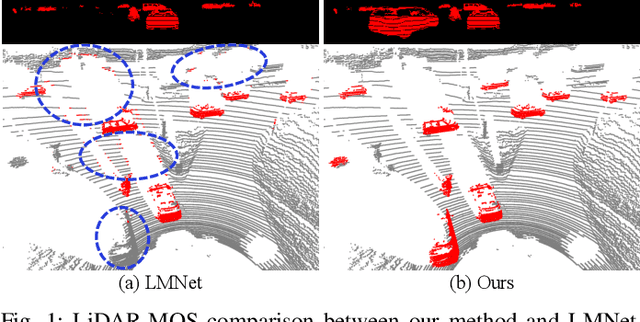
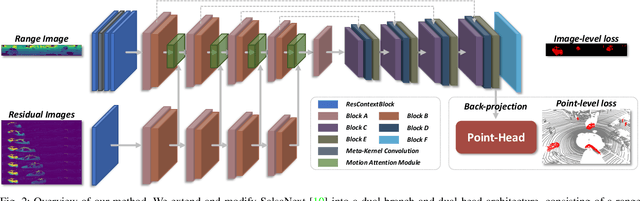
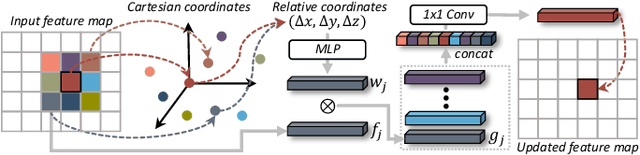
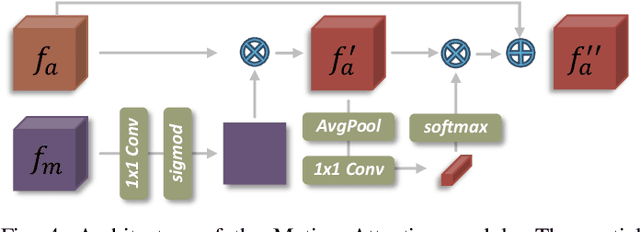
Accurate moving object segmentation is an essential task for autonomous driving. It can provide effective information for many downstream tasks, such as collision avoidance, path planning, and static map construction. How to effectively exploit the spatial-temporal information is a critical question for 3D LiDAR moving object segmentation (LiDAR-MOS). In this work, we propose a novel deep neural network exploiting both spatial-temporal information and different representation modalities of LiDAR scans to improve LiDAR-MOS performance. Specifically, we first use a range image-based dual-branch structure to separately deal with spatial and temporal information that can be obtained from sequential LiDAR scans, and later combine them using motion-guided attention modules. We also use a point refinement module via 3D sparse convolution to fuse the information from both LiDAR range image and point cloud representations and reduce the artifacts on the borders of the objects. We verify the effectiveness of our proposed approach on the LiDAR-MOS benchmark of SemanticKITTI. Our method outperforms the state-of-the-art methods significantly in terms of LiDAR-MOS IoU. Benefiting from the devised coarse-to-fine architecture, our method operates online at sensor frame rate. The implementation of our method is available as open source at: https://github.com/haomo-ai/MotionSeg3D.
Neural Deformable Voxel Grid for Fast Optimization of Dynamic View Synthesis
Jun 15, 2022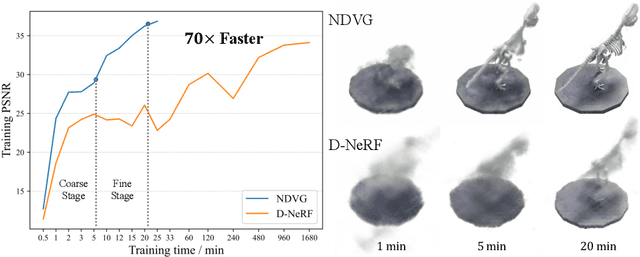
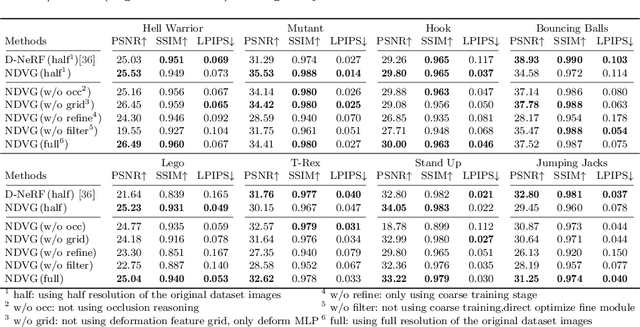
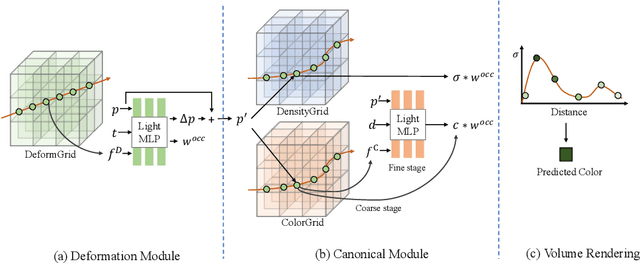

Recently, Neural Radiance Fields (NeRF) is revolutionizing the task of novel view synthesis (NVS) for its superior performance. However, NeRF and its variants generally require a lengthy per-scene training procedure, where a multi-layer perceptron (MLP) is fitted to the captured images. To remedy the challenge, the voxel-grid representation has been proposed to significantly speed up the training. However, these existing methods can only deal with static scenes. How to develop an efficient and accurate dynamic view synthesis method remains an open problem. Extending the methods for static scenes to dynamic scenes is not straightforward as both the scene geometry and appearance change over time. In this paper, built on top of the recent advances in voxel-grid optimization, we propose a fast deformable radiance field method to handle dynamic scenes. Our method consists of two modules. The first module adopts a deformation grid to store 3D dynamic features, and a light-weight MLP for decoding the deformation that maps a 3D point in observation space to the canonical space using the interpolated features. The second module contains a density and a color grid to model the geometry and density of the scene. The occlusion is explicitly modeled to further improve the rendering quality. Experimental results show that our method achieves comparable performance to D-NeRF using only 20 minutes for training, which is more than 70x faster than D-NeRF, clearly demonstrating the efficiency of our proposed method.
Context-Aware Video Reconstruction for Rolling Shutter Cameras
May 25, 2022
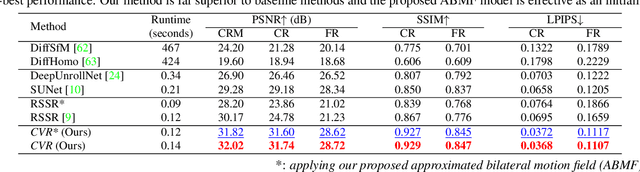
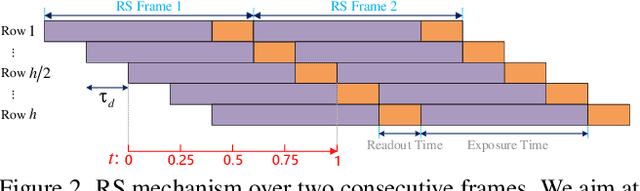
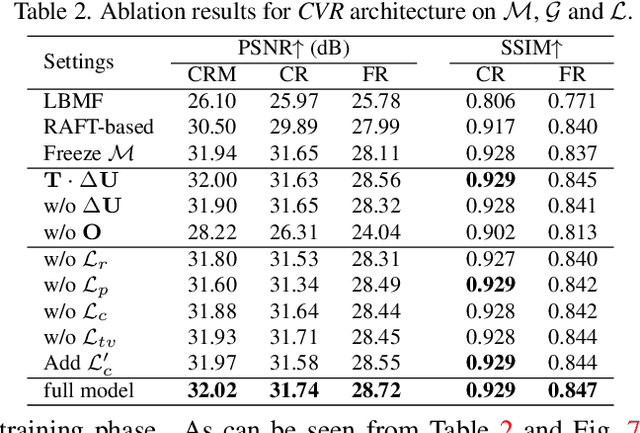
With the ubiquity of rolling shutter (RS) cameras, it is becoming increasingly attractive to recover the latent global shutter (GS) video from two consecutive RS frames, which also places a higher demand on realism. Existing solutions, using deep neural networks or optimization, achieve promising performance. However, these methods generate intermediate GS frames through image warping based on the RS model, which inevitably result in black holes and noticeable motion artifacts. In this paper, we alleviate these issues by proposing a context-aware GS video reconstruction architecture. It facilitates the advantages such as occlusion reasoning, motion compensation, and temporal abstraction. Specifically, we first estimate the bilateral motion field so that the pixels of the two RS frames are warped to a common GS frame accordingly. Then, a refinement scheme is proposed to guide the GS frame synthesis along with bilateral occlusion masks to produce high-fidelity GS video frames at arbitrary times. Furthermore, we derive an approximated bilateral motion field model, which can serve as an alternative to provide a simple but effective GS frame initialization for related tasks. Experiments on synthetic and real data show that our approach achieves superior performance over state-of-the-art methods in terms of objective metrics and subjective visual quality. Code is available at \url{https://github.com/GitCVfb/CVR}.