 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel Consistency Prior and Self-Reconstruction Strategy Based Unsupervised Image Deraining
Mar 24, 2025



Recently, deep image deraining models based on paired datasets have made a series of remarkable progress. However, they cannot be well applied in real-world applications due to the difficulty of obtaining real paired datasets and the poor generalization performance. In this paper, we propose a novel Channel Consistency Prior and Self-Reconstruction Strategy Based Unsupervised Image Deraining framework, CSUD, to tackle the aforementioned challenges. During training with unpaired data, CSUD is capable of generating high-quality pseudo clean and rainy image pairs which are used to enhance the performance of deraining network. Specifically, to preserve more image background details while transferring rain streaks from rainy images to the unpaired clean images, we propose a novel Channel Consistency Loss (CCLoss) by introducing the Channel Consistency Prior (CCP) of rain streaks into training process, thereby ensuring that the generated pseudo rainy images closely resemble the real ones. Furthermore, we propose a novel Self-Reconstruction (SR) strategy to alleviate the redundant information transfer problem of the generator, further improving the deraining performance and the generalization capability of our method. Extensive experiments on multiple synthetic and real-world datasets demonstrate that the deraining performance of CSUD surpasses other state-of-the-art unsupervised methods and CSUD exhibits superior generalization capability.
Medical AI for Early Detection of Lung Cancer: A Survey
Oct 18, 2024



Lung cancer remains one of the leading causes of morbidity and mortality worldwide, making early diagnosis critical for improving therapeutic outcomes and patient prognosis. Computer-aided diagnosis (CAD) systems, which analyze CT images, have proven effective in detecting and classifying pulmonary nodules, significantly enhancing the detection rate of early-stage lung cancer. Although traditional machine learning algorithms have been valuable, they exhibit limitations in handling complex sample data. The recent emergence of deep learning has revolutionized medical image analysis, driving substantial advancements in this field. This review focuses on recent progress in deep learning for pulmonary nodule detection, segmentation, and classification. Traditional machine learning methods, such as SVM and KNN, have shown limitations, paving the way for advanced approaches like Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), and Generative Adversarial Networks (GAN). The integration of ensemble models and novel techniques is also discussed, emphasizing the latest developments in lung cancer diagnosis. Deep learning algorithms, combined with various analytical techniques, have markedly improved the accuracy and efficiency of pulmonary nodule analysis, surpassing traditional methods, particularly in nodule classification. Although challenges remain, continuous technological advancements are expected to further strengthen the role of deep learning in medical diagnostics, especially for early lung cancer detection and diagnosis. A comprehensive list of lung cancer detection models reviewed in this work is available at https://github.com/CaiGuoHui123/Awesome-Lung-Cancer-Detection
MSDet: Receptive Field Enhanced Multiscale Detection for Tiny Pulmonary Nodule
Sep 21, 2024



Pulmonary nodules are critical indicators for the early diagnosis of lung cancer, making their detection essential for timely treatment. However, traditional CT imaging methods suffered from cumbersome procedures, low detection rates, and poor localization accuracy. The subtle differences between pulmonary nodules and surrounding tissues in complex lung CT images, combined with repeated downsampling in feature extraction networks, often lead to missed or false detections of small nodules. Existing methods such as FPN, with its fixed feature fusion and limited receptive field, struggle to effectively overcome these issues. To address these challenges, our paper proposed three key contributions: Firstly, we proposed MSDet, a multiscale attention and receptive field network for detecting tiny pulmonary nodules. Secondly, we proposed the extended receptive domain (ERD) strategy to capture richer contextual information and reduce false positives caused by nodule occlusion. We also proposed the position channel attention mechanism (PCAM) to optimize feature learning and reduce multiscale detection errors, and designed the tiny object detection block (TODB) to enhance the detection of tiny nodules. Lastly, we conducted thorough experiments on the public LUNA16 dataset, achieving state-of-the-art performance, with an mAP improvement of 8.8% over the previous state-of-the-art method YOLOv8. These advancements significantly boosted detection accuracy and reliability, providing a more effective solution for early lung cancer diagnosis. The code will be available at https://github.com/CaiGuoHui123/MSDet
Random Sub-Samples Generation for Self-Supervised Real Image Denoising
Jul 31, 2023



With sufficient paired training samples, the supervised deep learning methods have attracted much attention in image denoising because of their superior performance. However, it is still very challenging to widely utilize the supervised methods in real cases due to the lack of paired noisy-clean images. Meanwhile, most self-supervised denoising methods are ineffective as well when applied to the real-world denoising tasks because of their strict assumptions in applications. For example, as a typical method for self-supervised denoising, the original blind spot network (BSN) assumes that the noise is pixel-wise independent, which is much different from the real cases. To solve this problem, we propose a novel self-supervised real image denoising framework named Sampling Difference As Perturbation (SDAP) based on Random Sub-samples Generation (RSG) with a cyclic sample difference loss. Specifically, we dig deeper into the properties of BSN to make it more suitable for real noise. Surprisingly, we find that adding an appropriate perturbation to the training images can effectively improve the performance of BSN. Further, we propose that the sampling difference can be considered as perturbation to achieve better results. Finally we propose a new BSN framework in combination with our RSG strategy. The results show that it significantly outperforms other state-of-the-art self-supervised denoising methods on real-world datasets. The code is available at https://github.com/p1y2z3/SDAP.
Robust Watermarking Using Inverse Gradient Attention
Nov 21, 2020
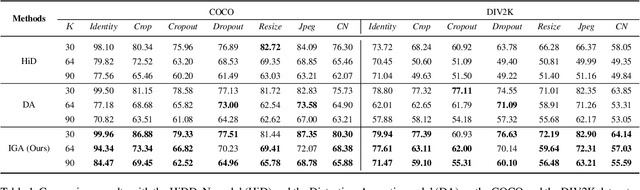
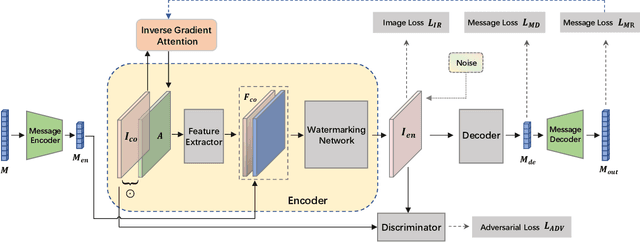
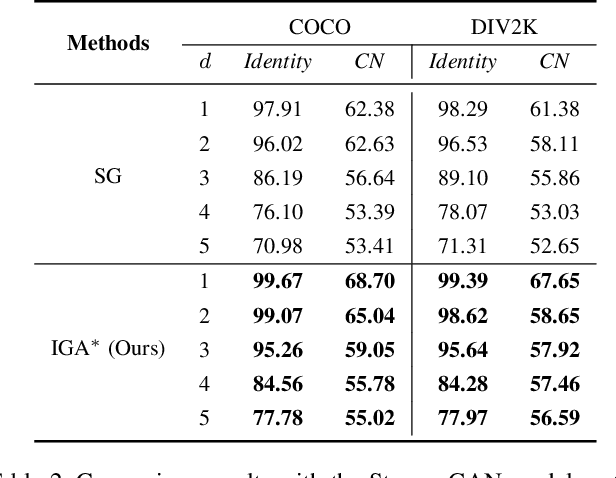
Watermarking is the procedure of encoding desired information into an image to resist potential noises while ensuring the embedded image has little perceptual perturbations from the original image. Recently, with the tremendous successes gained by deep neural networks in various fields, digital watermarking has attracted increasing number of attentions. The neglect of considering the pixel importance within the cover image of deep neural models will inevitably affect the model robustness for information hiding. Targeting at the problem, in this paper, we propose a novel deep watermarking scheme with Inverse Gradient Attention (IGA), combing the ideas of adversarial learning and attention mechanism to endow different importance to different pixels. With the proposed method, the model is able to spotlight pixels with more robustness for embedding data. Besides, from an orthogonal point of view, in order to increase the model embedding capacity, we propose a complementary message coding module. Empirically, extensive experiments show that the proposed model outperforms the state-of-the-art methods on two prevalent datasets under multiple settings.
MuMMER: Socially Intelligent Human-Robot Interaction in Public Spaces
Sep 15, 2019
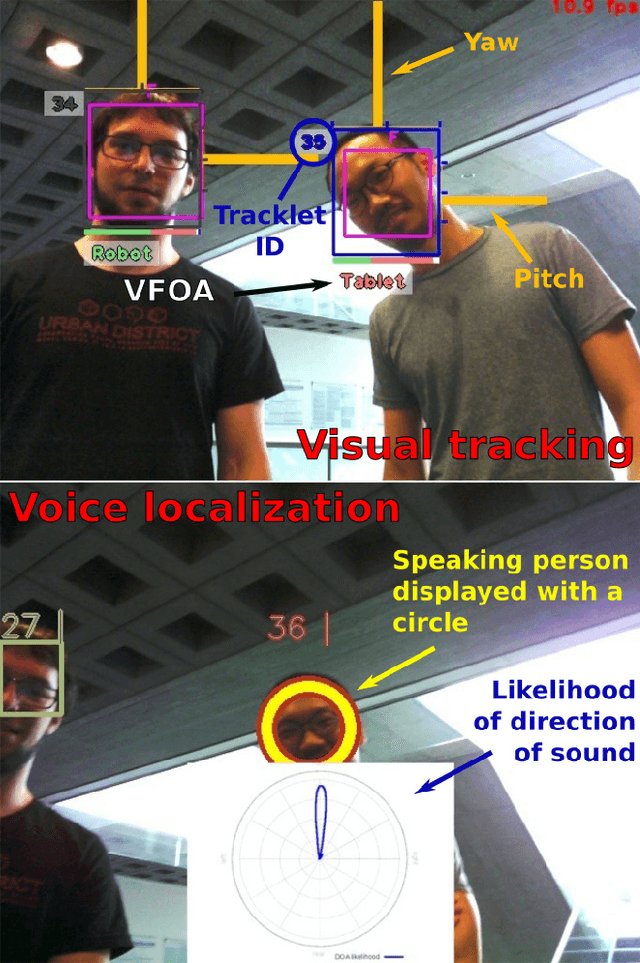

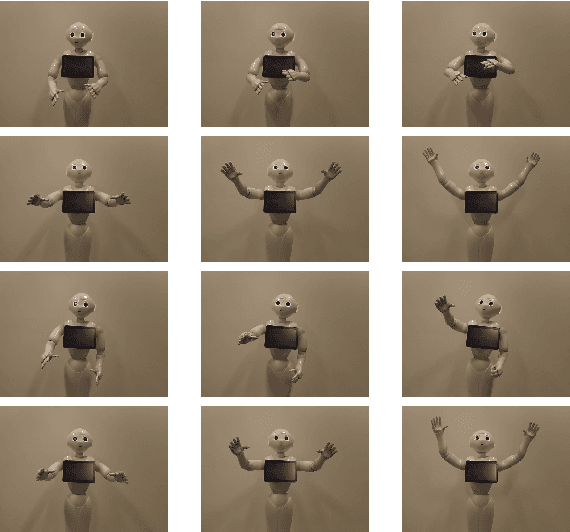
In the EU-funded MuMMER project, we have developed a social robot designed to interact naturally and flexibly with users in public spaces such as a shopping mall. We present the latest version of the robot system developed during the project. This system encompasses audio-visual sensing, social signal processing, conversational interaction, perspective taking, geometric reasoning, and motion planning. It successfully combines all these components in an overarching framework using the Robot Operating System (ROS) and has been deployed to a shopping mall in Finland interacting with customers. In this paper, we describe the system components, their interplay, and the resulting robot behaviours and scenarios provided at the shopping mall.
Exploiting temporal consistency for real-time video depth estimation
Aug 10, 2019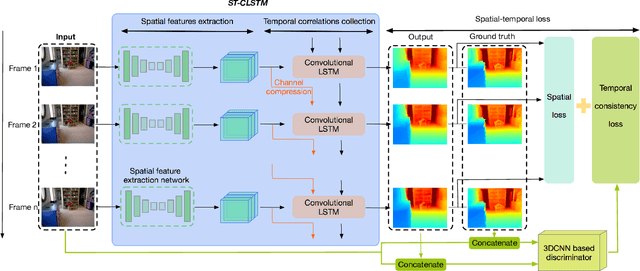
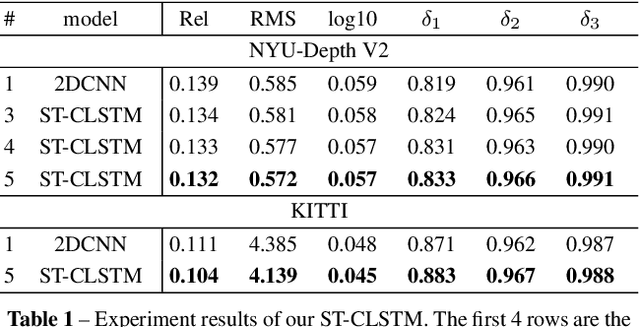
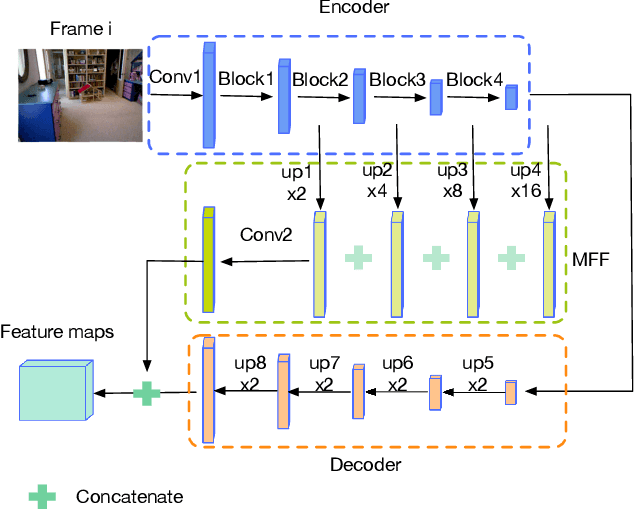
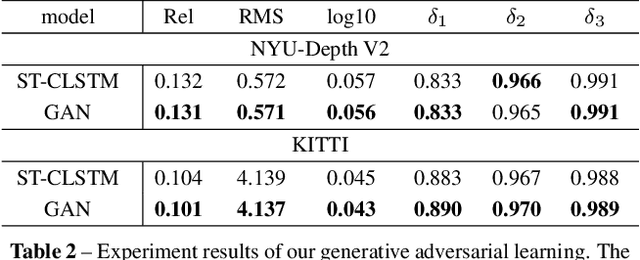
Accuracy of depth estimation from static images has been significantly improved recently, by exploiting hierarchical features from deep convolutional neural networks (CNNs). Compared with static images, vast information exists among video frames and can be exploited to improve the depth estimation performance. In this work, we focus on exploring temporal information from monocular videos for depth estimation. Specifically, we take the advantage of convolutional long short-term memory (CLSTM) and propose a novel spatial-temporal CSLTM (ST-CLSTM) structure. Our ST-CLSTM structure can capture not only the spatial features but also the temporal correlations/consistency among consecutive video frames with negligible increase in computational cost. Additionally, in order to maintain the temporal consistency among the estimated depth frames, we apply the generative adversarial learning scheme and design a temporal consistency loss. The temporal consistency loss is combined with the spatial loss to update the model in an end-to-end fashion. By taking advantage of the temporal information, we build a video depth estimation framework that runs in real-time and generates visually pleasant results. Moreover, our approach is flexible and can be generalized to most existing depth estimation frameworks. Code is available at: https://tinyurl.com/STCLSTM
Monocular Depth Estimation with Augmented Ordinal Depth Relationships
Jun 02, 2018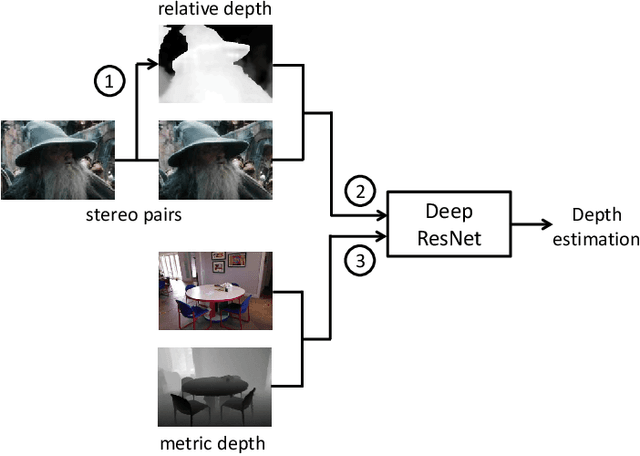

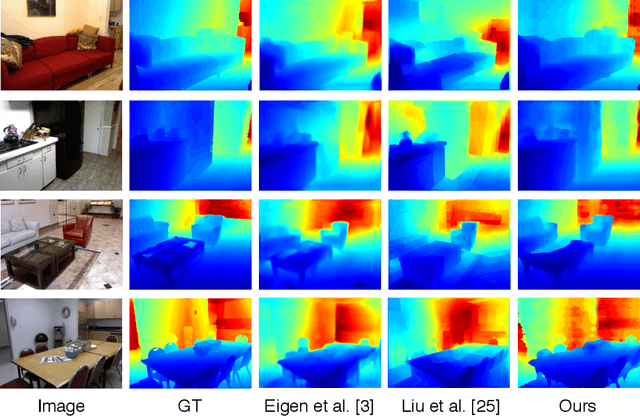
Most existing algorithms for depth estimation from single monocular images need large quantities of metric groundtruth depths for supervised learning. We show that relative depth can be an informative cue for metric depth estimation and can be easily obtained from vast stereo videos. Acquiring metric depths from stereo videos is sometimes impracticable due to the absence of camera parameters. In this paper, we propose to improve the performance of metric depth estimation with relative depths collected from stereo movie videos using existing stereo matching algorithm. We introduce a new "Relative Depth in Stereo" (RDIS) dataset densely labelled with relative depths. We first pretrain a ResNet model on our RDIS dataset. Then we finetune the model on RGB-D datasets with metric ground-truth depths. During our finetuning, we formulate depth estimation as a classification task. This re-formulation scheme enables us to obtain the confidence of a depth prediction in the form of probability distribution. With this confidence, we propose an information gain loss to make use of the predictions that are close to ground-truth. We evaluate our approach on both indoor and outdoor benchmark RGB-D datasets and achieve state-of-the-art performance.
Estimating Depth from Monocular Images as Classification Using Deep Fully Convolutional Residual Networks
Aug 11, 2017
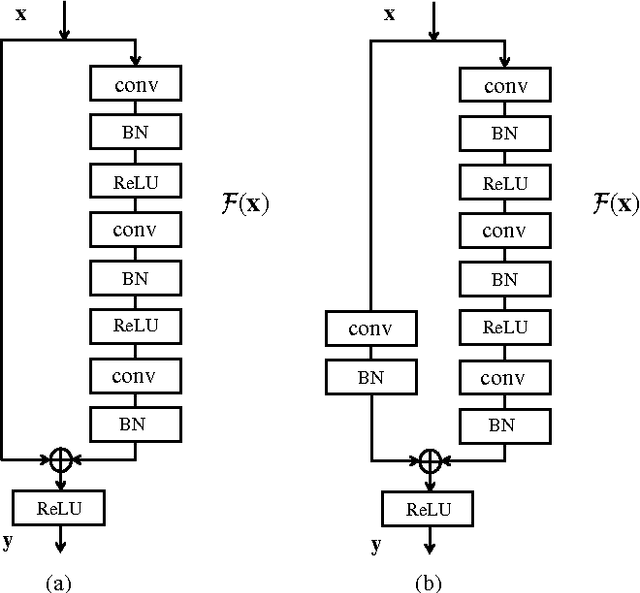
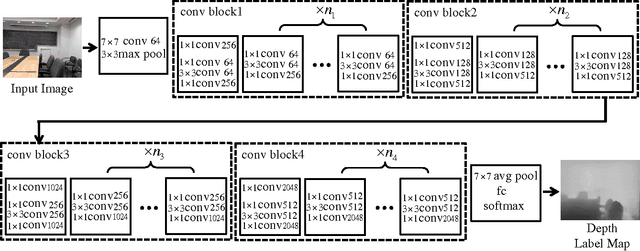
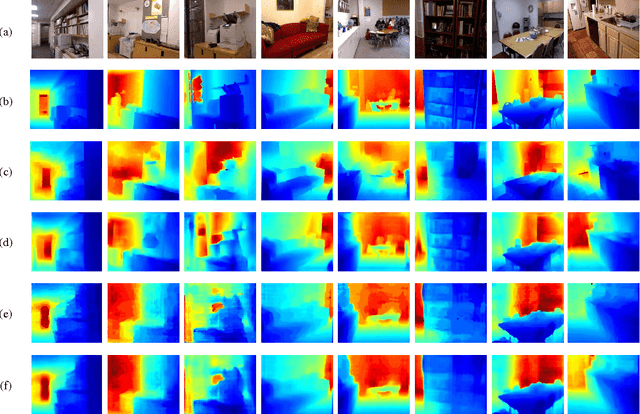
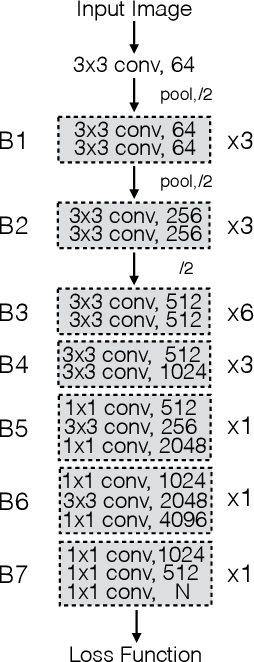
Depth estimation from single monocular images is a key component of scene understanding and has benefited largely from deep convolutional neural networks (CNN) recently. In this article, we take advantage of the recent deep residual networks and propose a simple yet effective approach to this problem. We formulate depth estimation as a pixel-wise classification task. Specifically, we first discretize the continuous depth values into multiple bins and label the bins according to their depth range. Then we train fully convolutional deep residual networks to predict the depth label of each pixel. Performing discrete depth label classification instead of continuous depth value regression allows us to predict a confidence in the form of probability distribution. We further apply fully-connected conditional random fields (CRF) as a post processing step to enforce local smoothness interactions, which improves the results. We evaluate our approach on both indoor and outdoor datasets and achieve state-of-the-art performance.
Exploiting Depth from Single Monocular Images for Object Detection and Semantic Segmentation
Oct 06, 2016
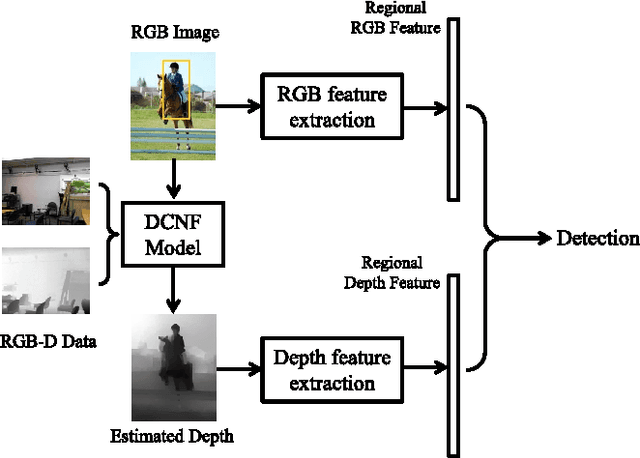
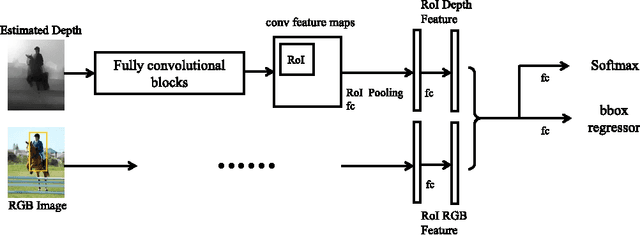

Augmenting RGB data with measured depth has been shown to improve the performance of a range of tasks in computer vision including object detection and semantic segmentation. Although depth sensors such as the Microsoft Kinect have facilitated easy acquisition of such depth information, the vast majority of images used in vision tasks do not contain depth information. In this paper, we show that augmenting RGB images with estimated depth can also improve the accuracy of both object detection and semantic segmentation. Specifically, we first exploit the recent success of depth estimation from monocular images and learn a deep depth estimation model. Then we learn deep depth features from the estimated depth and combine with RGB features for object detection and semantic segmentation. Additionally, we propose an RGB-D semantic segmentation method which applies a multi-task training scheme: semantic label prediction and depth value regression. We test our methods on several datasets and demonstrate that incorporating information from estimated depth improves the performance of object detection and semantic segmentation remarkably.