 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Video Object Detection via a Scale-Time Lattice
Apr 16, 2018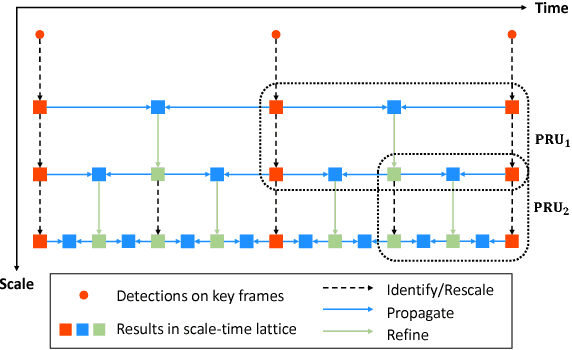

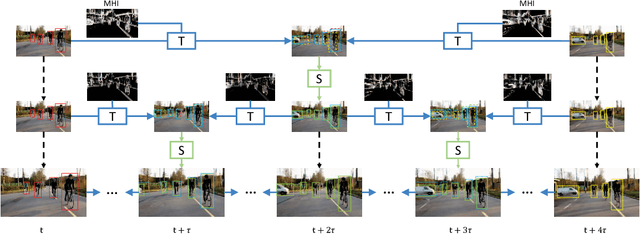
High-performance object detection relies on expensive convolutional networks to compute features, often leading to significant challenges in applications, e.g. those that require detecting objects from video streams in real time. The key to this problem is to trade accuracy for efficiency in an effective way, i.e. reducing the computing cost while maintaining competitive performance. To seek a good balance, previous efforts usually focus on optimizing the model architectures. This paper explores an alternative approach, that is, to reallocate the computation over a scale-time space. The basic idea is to perform expensive detection sparsely and propagate the results across both scales and time with substantially cheaper networks, by exploiting the strong correlations among them. Specifically, we present a unified framework that integrates detection, temporal propagation, and across-scale refinement on a Scale-Time Lattice. On this framework, one can explore various strategies to balance performance and cost. Taking advantage of this flexibility, we further develop an adaptive scheme with the detector invoked on demand and thus obtain improved tradeoff. On ImageNet VID dataset, the proposed method can achieve a competitive mAP 79.6% at 20 fps, or 79.0% at 62 fps as a performance/speed tradeoff.
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
Jan 25, 2018
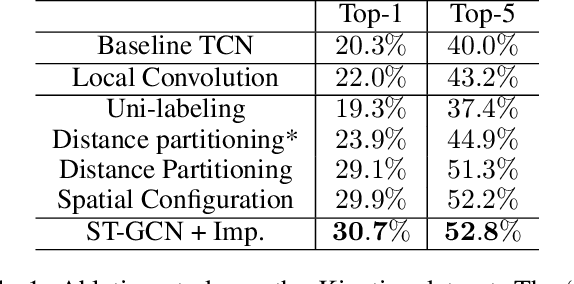

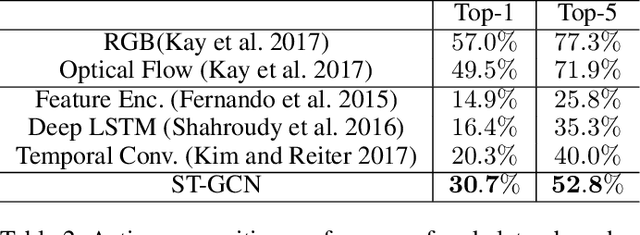
Dynamics of human body skeletons convey significant information for human action recognition. Conventional approaches for modeling skeletons usually rely on hand-crafted parts or traversal rules, thus resulting in limited expressive power and difficulties of generalization. In this work, we propose a novel model of dynamic skeletons called Spatial-Temporal Graph Convolutional Networks (ST-GCN), which moves beyond the limitations of previous methods by automatically learning both the spatial and temporal patterns from data. This formulation not only leads to greater expressive power but also stronger generalization capability. On two large datasets, Kinetics and NTU-RGBD, it achieves substantial improvements over mainstream methods.
Temporal Action Detection with Structured Segment Networks
Sep 18, 2017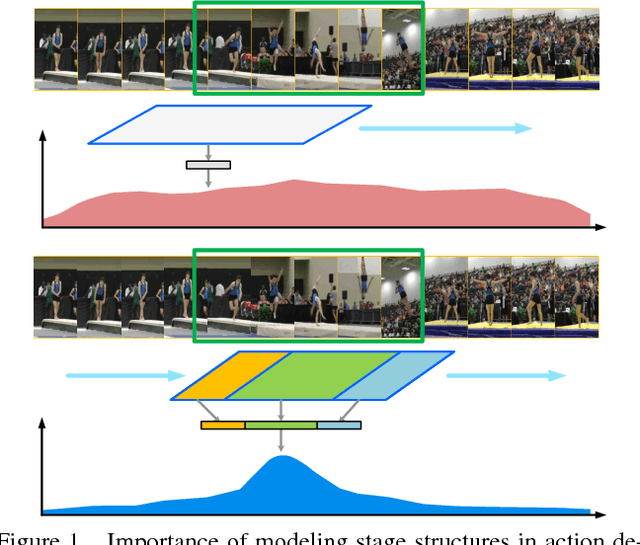
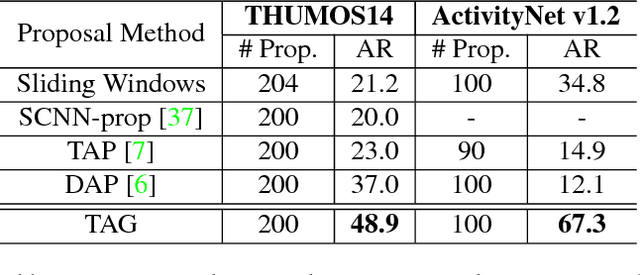
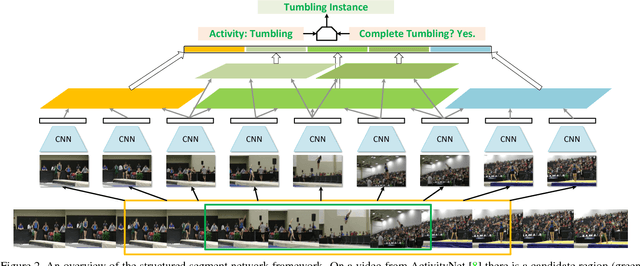
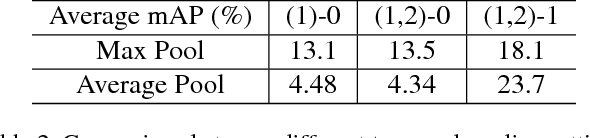
Detecting actions in untrimmed videos is an important yet challenging task. In this paper, we present the structured segment network (SSN), a novel framework which models the temporal structure of each action instance via a structured temporal pyramid. On top of the pyramid, we further introduce a decomposed discriminative model comprising two classifiers, respectively for classifying actions and determining completeness. This allows the framework to effectively distinguish positive proposals from background or incomplete ones, thus leading to both accurate recognition and localization. These components are integrated into a unified network that can be efficiently trained in an end-to-end fashion. Additionally, a simple yet effective temporal action proposal scheme, dubbed temporal actionness grouping (TAG) is devised to generate high quality action proposals. On two challenging benchmarks, THUMOS14 and ActivityNet, our method remarkably outperforms previous state-of-the-art methods, demonstrating superior accuracy and strong adaptivity in handling actions with various temporal structures.
Face Detection through Scale-Friendly Deep Convolutional Networks
Jun 09, 2017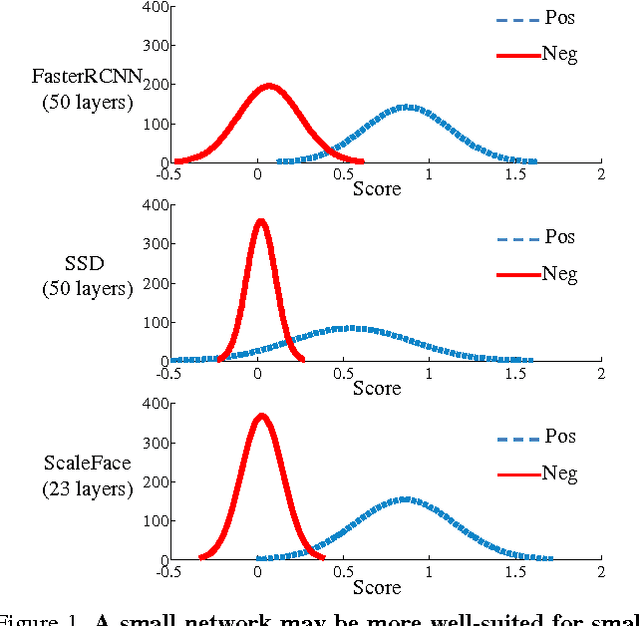
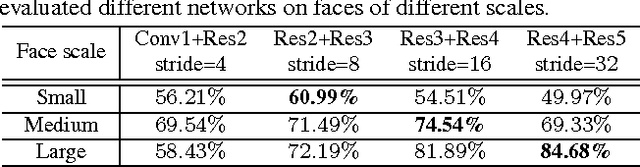
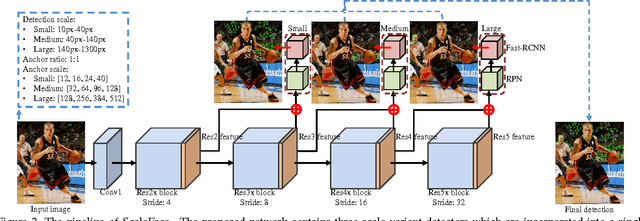
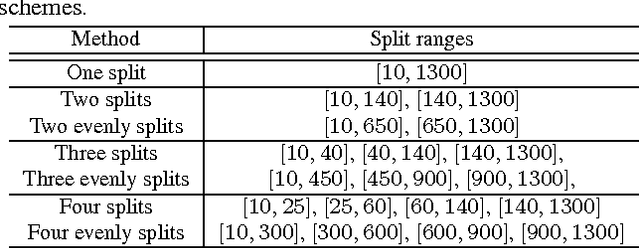
In this paper, we share our experience in designing a convolutional network-based face detector that could handle faces of an extremely wide range of scales. We show that faces with different scales can be modeled through a specialized set of deep convolutional networks with different structures. These detectors can be seamlessly integrated into a single unified network that can be trained end-to-end. In contrast to existing deep models that are designed for wide scale range, our network does not require an image pyramid input and the model is of modest complexity. Our network, dubbed ScaleFace, achieves promising performance on WIDER FACE and FDDB datasets with practical runtime speed. Specifically, our method achieves 76.4 average precision on the challenging WIDER FACE dataset and 96% recall rate on the FDDB dataset with 7 frames per second (fps) for 900 * 1300 input image.
UntrimmedNets for Weakly Supervised Action Recognition and Detection
May 22, 2017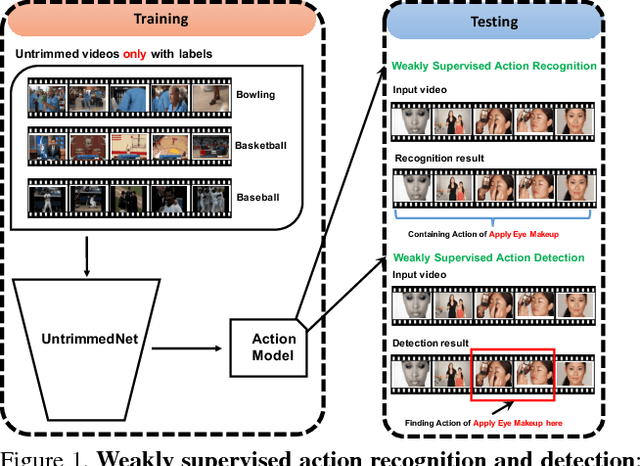
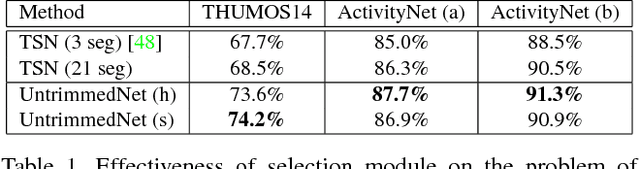
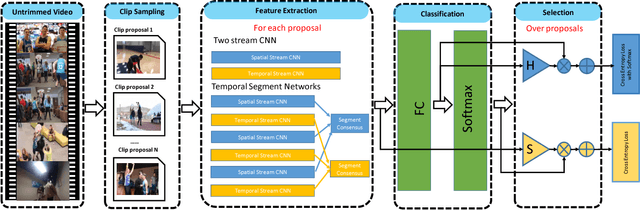
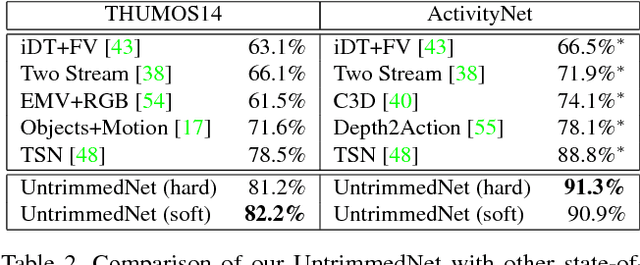
Current action recognition methods heavily rely on trimmed videos for model training. However, it is expensive and time-consuming to acquire a large-scale trimmed video dataset. This paper presents a new weakly supervised architecture, called UntrimmedNet, which is able to directly learn action recognition models from untrimmed videos without the requirement of temporal annotations of action instances. Our UntrimmedNet couples two important components, the classification module and the selection module, to learn the action models and reason about the temporal duration of action instances, respectively. These two components are implemented with feed-forward networks, and UntrimmedNet is therefore an end-to-end trainable architecture. We exploit the learned models for action recognition (WSR) and detection (WSD) on the untrimmed video datasets of THUMOS14 and ActivityNet. Although our UntrimmedNet only employs weak supervision, our method achieves performance superior or comparable to that of those strongly supervised approaches on these two datasets.
Temporal Segment Networks for Action Recognition in Videos
May 08, 2017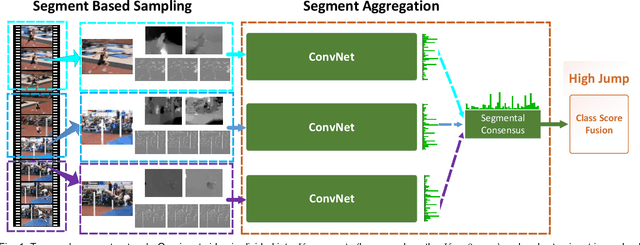

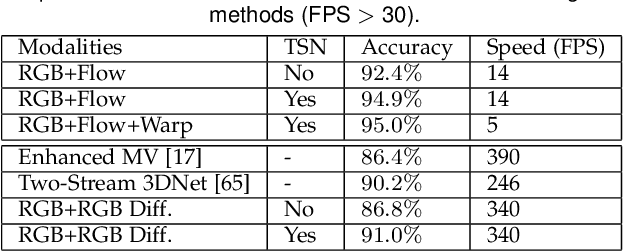
Deep convolutional networks have achieved great success for image recognition. However, for action recognition in videos, their advantage over traditional methods is not so evident. We present a general and flexible video-level framework for learning action models in videos. This method, called temporal segment network (TSN), aims to model long-range temporal structures with a new segment-based sampling and aggregation module. This unique design enables our TSN to efficiently learn action models by using the whole action videos. The learned models could be easily adapted for action recognition in both trimmed and untrimmed videos with simple average pooling and multi-scale temporal window integration, respectively. We also study a series of good practices for the instantiation of TSN framework given limited training samples. Our approach obtains the state-the-of-art performance on four challenging action recognition benchmarks: HMDB51 (71.0%), UCF101 (94.9%), THUMOS14 (80.1%), and ActivityNet v1.2 (89.6%). Using the proposed RGB difference for motion models, our method can still achieve competitive accuracy on UCF101 (91.0%) while running at 340 FPS. Furthermore, based on the temporal segment networks, we won the video classification track at the ActivityNet challenge 2016 among 24 teams, which demonstrates the effectiveness of TSN and the proposed good practices.
A Pursuit of Temporal Accuracy in General Activity Detection
Mar 08, 2017
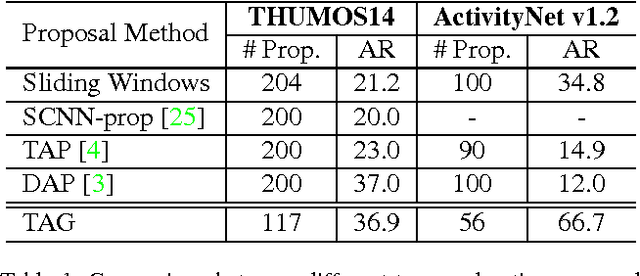
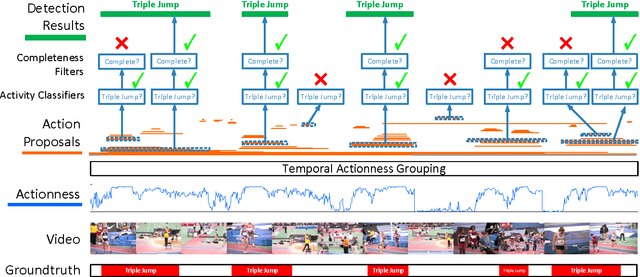
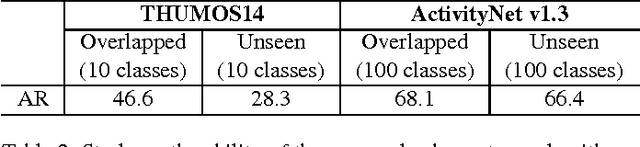
Detecting activities in untrimmed videos is an important but challenging task. The performance of existing methods remains unsatisfactory, e.g., they often meet difficulties in locating the beginning and end of a long complex action. In this paper, we propose a generic framework that can accurately detect a wide variety of activities from untrimmed videos. Our first contribution is a novel proposal scheme that can efficiently generate candidates with accurate temporal boundaries. The other contribution is a cascaded classification pipeline that explicitly distinguishes between relevance and completeness of a candidate instance. On two challenging temporal activity detection datasets, THUMOS14 and ActivityNet, the proposed framework significantly outperforms the existing state-of-the-art methods, demonstrating superior accuracy and strong adaptivity in handling activities with various temporal structures.
Knowledge Guided Disambiguation for Large-Scale Scene Classification with Multi-Resolution CNNs
Feb 21, 2017
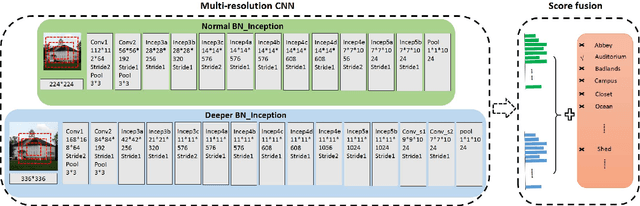
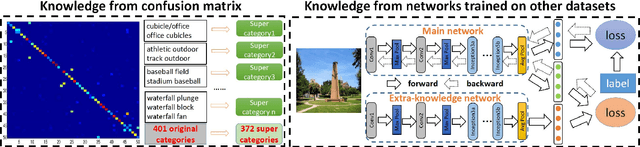
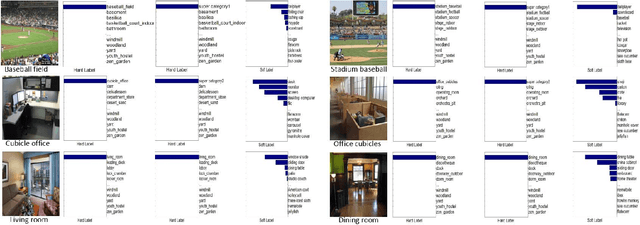
Convolutional Neural Networks (CNNs) have made remarkable progress on scene recognition, partially due to these recent large-scale scene datasets, such as the Places and Places2. Scene categories are often defined by multi-level information, including local objects, global layout, and background environment, thus leading to large intra-class variations. In addition, with the increasing number of scene categories, label ambiguity has become another crucial issue in large-scale classification. This paper focuses on large-scale scene recognition and makes two major contributions to tackle these issues. First, we propose a multi-resolution CNN architecture that captures visual content and structure at multiple levels. The multi-resolution CNNs are composed of coarse resolution CNNs and fine resolution CNNs, which are complementary to each other. Second, we design two knowledge guided disambiguation techniques to deal with the problem of label ambiguity. (i) We exploit the knowledge from the confusion matrix computed on validation data to merge ambiguous classes into a super category. (ii) We utilize the knowledge of extra networks to produce a soft label for each image. Then the super categories or soft labels are employed to guide CNN training on the Places2. We conduct extensive experiments on three large-scale image datasets (ImageNet, Places, and Places2), demonstrating the effectiveness of our approach. Furthermore, our method takes part in two major scene recognition challenges, and achieves the second place at the Places2 challenge in ILSVRC 2015, and the first place at the LSUN challenge in CVPR 2016. Finally, we directly test the learned representations on other scene benchmarks, and obtain the new state-of-the-art results on the MIT Indoor67 (86.7\%) and SUN397 (72.0\%). We release the code and models at~\url{https://github.com/wanglimin/MRCNN-Scene-Recognition}.
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
Aug 02, 2016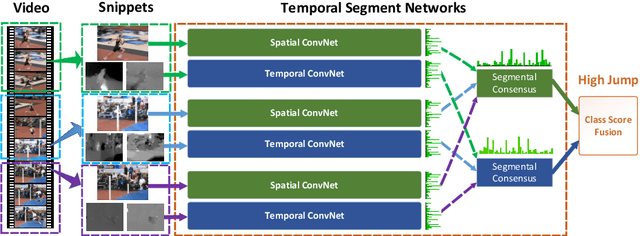
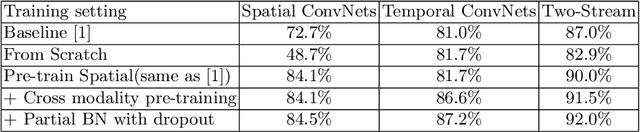


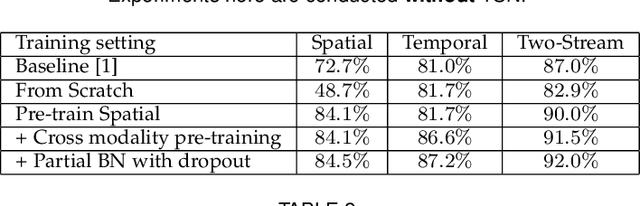
Deep convolutional networks have achieved great success for visual recognition in still images. However, for action recognition in videos, the advantage over traditional methods is not so evident. This paper aims to discover the principles to design effective ConvNet architectures for action recognition in videos and learn these models given limited training samples. Our first contribution is temporal segment network (TSN), a novel framework for video-based action recognition. which is based on the idea of long-range temporal structure modeling. It combines a sparse temporal sampling strategy and video-level supervision to enable efficient and effective learning using the whole action video. The other contribution is our study on a series of good practices in learning ConvNets on video data with the help of temporal segment network. Our approach obtains the state-the-of-art performance on the datasets of HMDB51 ( $ 69.4\% $) and UCF101 ($ 94.2\% $). We also visualize the learned ConvNet models, which qualitatively demonstrates the effectiveness of temporal segment network and the proposed good practices.
CUHK & ETHZ & SIAT Submission to ActivityNet Challenge 2016
Aug 02, 2016
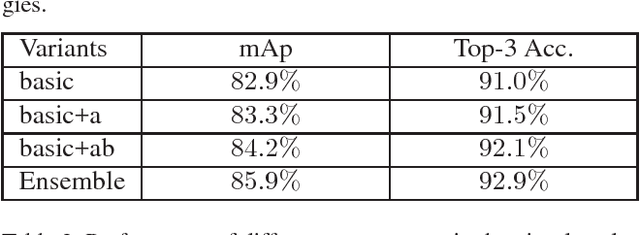
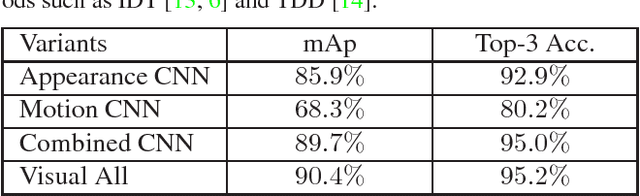
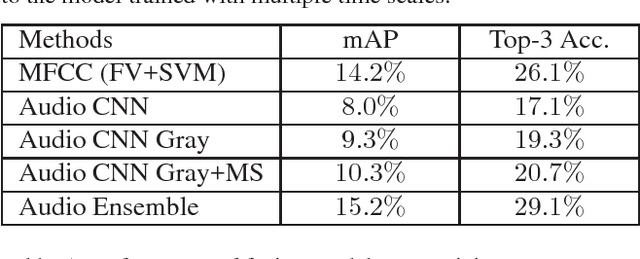
This paper presents the method that underlies our submission to the untrimmed video classification task of ActivityNet Challenge 2016. We follow the basic pipeline of temporal segment networks and further raise the performance via a number of other techniques. Specifically, we use the latest deep model architecture, e.g., ResNet and Inception V3, and introduce new aggregation schemes (top-k and attention-weighted pooling). Additionally, we incorporate the audio as a complementary channel, extracting relevant information via a CNN applied to the spectrograms. With these techniques, we derive an ensemble of deep models, which, together, attains a high classification accuracy (mAP $93.23\%$) on the testing set and secured the first place in the challenge.