 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching Large Neighborhoods for Integer Linear Programs with Contrastive Learning
Feb 03, 2023



Integer Linear Programs (ILPs) are powerful tools for modeling and solving a large number of combinatorial optimization problems. Recently, it has been shown that Large Neighborhood Search (LNS), as a heuristic algorithm, can find high quality solutions to ILPs faster than Branch and Bound. However, how to find the right heuristics to maximize the performance of LNS remains an open problem. In this paper, we propose a novel approach, CL-LNS, that delivers state-of-the-art anytime performance on several ILP benchmarks measured by metrics including the primal gap, the primal integral, survival rates and the best performing rate. Specifically, CL-LNS collects positive and negative solution samples from an expert heuristic that is slow to compute and learns a new one with a contrastive loss. We use graph attention networks and a richer set of features to further improve its performance.
Modeling Scattering Coefficients using Self-Attentive Complex Polynomials with Image-based Representation
Jan 10, 2023Finding antenna designs that satisfy frequency requirements and are also optimal with respect to multiple physical criteria is a critical component in designing next generation hardware. However, such a process is non-trivial because the objective function is typically highly nonlinear and sensitive to subtle design change. Moreover, the objective to be optimized often involves electromagnetic (EM) simulations, which is slow and expensive with commercial simulation software. In this work, we propose a sample-efficient and accurate surrogate model, named CZP (Constant Zeros Poles), to directly estimate the scattering coefficients in the frequency domain of a given 2D planar antenna design, without using a simulator. CZP achieves this by predicting the complex zeros and poles for the frequency response of scattering coefficients, which we have theoretically justified for any linear PDE, including Maxwell's equations. Moreover, instead of using low-dimensional representations, CZP leverages a novel image-based representation for antenna topology inspired by the existing mesh-based EM simulation techniques, and attention-based neural network architectures. We demonstrate experimentally that CZP not only outperforms baselines in terms of test loss, but also is able to find 2D antenna designs verifiable by commercial software with only 40k training samples, when coupling with advanced sequential search techniques like reinforcement learning.
Learning to compile smartly for program size reduction
Jan 09, 2023Compiler optimization passes are an important tool for improving program efficiency and reducing program size, but manually selecting optimization passes can be time-consuming and error-prone. While human experts have identified a few fixed sequences of optimization passes (e.g., the Clang -Oz passes) that perform well for a wide variety of programs, these sequences are not conditioned on specific programs. In this paper, we propose a novel approach that learns a policy to select passes for program size reduction, allowing for customization and adaptation to specific programs. Our approach uses a search mechanism that helps identify useful pass sequences and a GNN with customized attention that selects the optimal sequence to use. Crucially it is able to generalize to new, unseen programs, making it more flexible and general than previous approaches. We evaluate our approach on a range of programs and show that it leads to size reduction compared to traditional optimization techniques. Our results demonstrate the potential of a single policy that is able to optimize many programs.
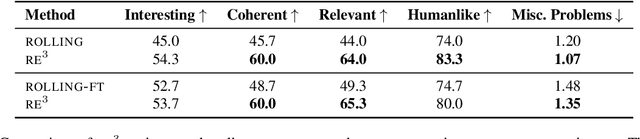
DOC: Improving Long Story Coherence With Detailed Outline Control
Dec 20, 2022We propose the Detailed Outline Control (DOC) framework for improving long-range plot coherence when automatically generating several-thousand-word-long stories. DOC consists of two complementary components: a detailed outliner and a detailed controller. The detailed outliner creates a more detailed, hierarchically structured outline, shifting creative burden from the main drafting procedure to the planning stage. The detailed controller ensures the more detailed outline is still respected during generation by controlling story passages to align with outline details. In human evaluations of automatically generated stories, DOC substantially outperforms a strong Re3 baseline (Yang et al., 2022) on plot coherence (22.5% absolute gain), outline relevance (28.2%), and interestingness (20.7%). Humans also judged DOC to be much more controllable in an interactive generation setting.
Local Branching Relaxation Heuristics for Integer Linear Programs
Dec 15, 2022Large Neighborhood Search (LNS) is a popular heuristic algorithm for solving combinatorial optimization problems (COP). It starts with an initial solution to the problem and iteratively improves it by searching a large neighborhood around the current best solution. LNS relies on heuristics to select neighborhoods to search in. In this paper, we focus on designing effective and efficient heuristics in LNS for integer linear programs (ILP) since a wide range of COPs can be represented as ILPs. Local Branching (LB) is a heuristic that selects the neighborhood that leads to the largest improvement over the current solution in each iteration of LNS. LB is often slow since it needs to solve an ILP of the same size as input. Our proposed heuristics, LB-RELAX and its variants, use the linear programming relaxation of LB to select neighborhoods. Empirically, LB-RELAX and its variants compute as effective neighborhoods as LB but run faster. They achieve state-of-the-art anytime performance on several ILP benchmarks.
EurNet: Efficient Multi-Range Relational Modeling of Spatial Multi-Relational Data
Nov 23, 2022



Modeling spatial relationship in the data remains critical across many different tasks, such as image classification, semantic segmentation and protein structure understanding. Previous works often use a unified solution like relative positional encoding. However, there exists different kinds of spatial relations, including short-range, medium-range and long-range relations, and modeling them separately can better capture the focus of different tasks on the multi-range relations (e.g., short-range relations can be important in instance segmentation, while long-range relations should be upweighted for semantic segmentation). In this work, we introduce the EurNet for Efficient multi-range relational modeling. EurNet constructs the multi-relational graph, where each type of edge corresponds to short-, medium- or long-range spatial interactions. In the constructed graph, EurNet adopts a novel modeling layer, called gated relational message passing (GRMP), to propagate multi-relational information across the data. GRMP captures multiple relations within the data with little extra computational cost. We study EurNets in two important domains for image and protein structure modeling. Extensive experiments on ImageNet classification, COCO object detection and ADE20K semantic segmentation verify the gains of EurNet over the previous SoTA FocalNet. On the EC and GO protein function prediction benchmarks, EurNet consistently surpasses the previous SoTA GearNet. Our results demonstrate the strength of EurNets on modeling spatial multi-relational data from various domains. The implementations of EurNet for image modeling are available at https://github.com/hirl-team/EurNet-Image . The implementations for other applied domains/tasks will be released soon.
SurCo: Learning Linear Surrogates For Combinatorial Nonlinear Optimization Problems
Oct 22, 2022



Optimization problems with expensive nonlinear cost functions and combinatorial constraints appear in many real-world applications, but remain challenging to solve efficiently. Existing combinatorial solvers like Mixed Integer Linear Programming can be fast in practice but cannot readily optimize nonlinear cost functions, while general nonlinear optimizers like gradient descent often do not handle complex combinatorial structures, may require many queries of the cost function, and are prone to local optima. To bridge this gap, we propose SurCo that learns linear Surrogate costs which can be used by existing Combinatorial solvers to output good solutions to the original nonlinear combinatorial optimization problem, combining the flexibility of gradient-based methods with the structure of linear combinatorial optimization. We learn these linear surrogates end-to-end with the nonlinear loss by differentiating through the linear surrogate solver. Three variants of SurCo are proposed: SurCo-zero operates on individual nonlinear problems, SurCo-prior trains a linear surrogate predictor on distributions of problems, and SurCo-hybrid uses a model trained offline to warm start online solving for SurCo-zero. We analyze our method theoretically and empirically, showing smooth convergence and improved performance. Experiments show that compared to state-of-the-art approaches and expert-designed heuristics, SurCo obtains lower cost solutions with comparable or faster solve time for two realworld industry-level applications: embedding table sharding and inverse photonic design.
Re3: Generating Longer Stories With Recursive Reprompting and Revision
Oct 14, 2022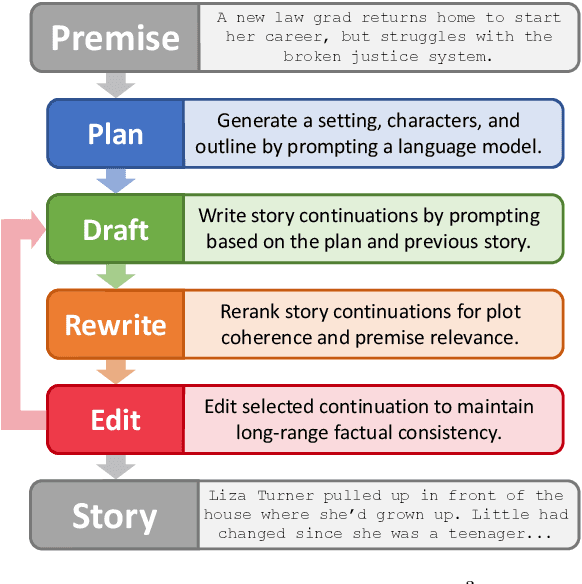
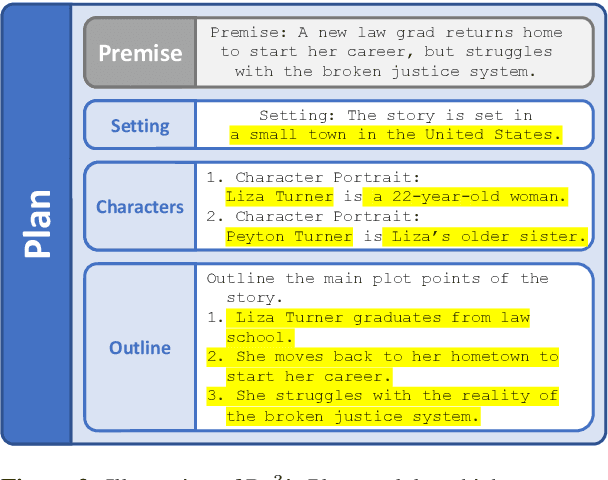

We consider the problem of automatically generating longer stories of over two thousand words. Compared to prior work on shorter stories, long-range plot coherence and relevance are more central challenges here. We propose the Recursive Reprompting and Revision framework (Re3) to address these challenges by (a) prompting a general-purpose language model to construct a structured overarching plan, and (b) generating story passages by repeatedly injecting contextual information from both the plan and current story state into a language model prompt. We then revise by (c) reranking different continuations for plot coherence and premise relevance, and finally (d) editing the best continuation for factual consistency. Compared to similar-length stories generated directly from the same base model, human evaluators judged substantially more of Re3's stories as having a coherent overarching plot (by 14% absolute increase), and relevant to the given initial premise (by 20%).
DreamShard: Generalizable Embedding Table Placement for Recommender Systems
Oct 05, 2022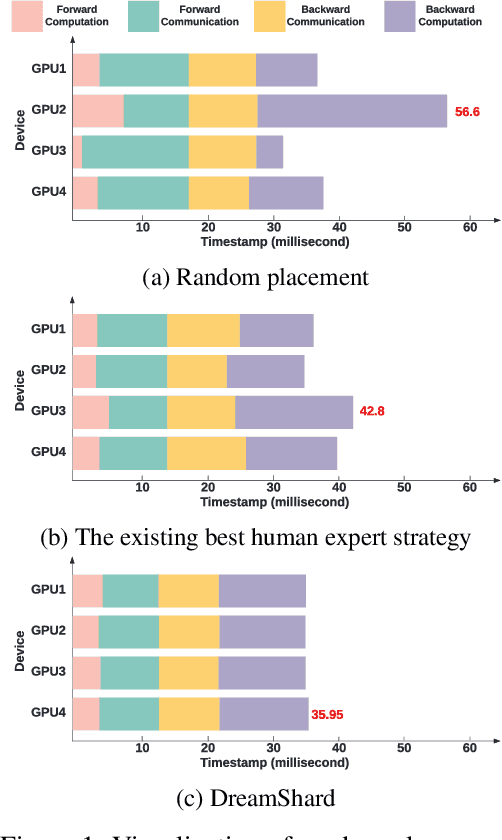
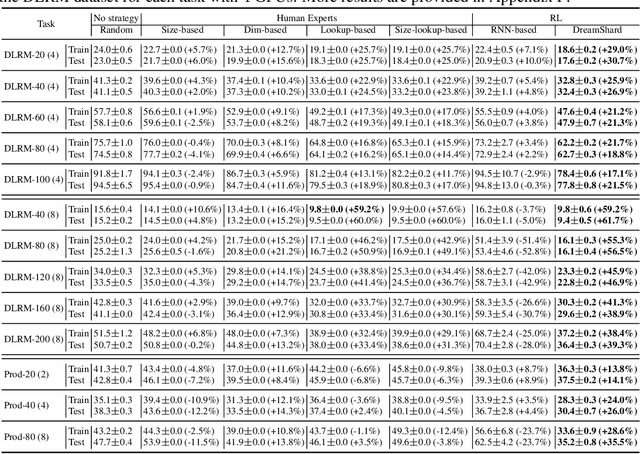
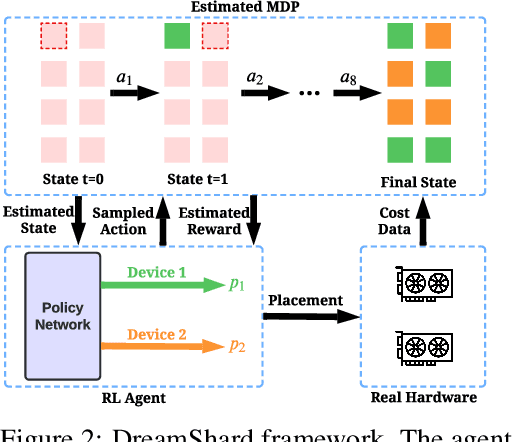
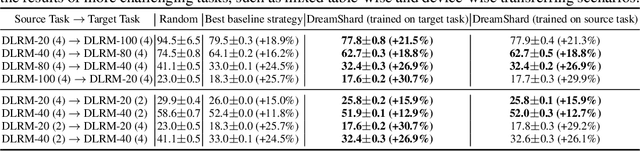
We study embedding table placement for distributed recommender systems, which aims to partition and place the tables on multiple hardware devices (e.g., GPUs) to balance the computation and communication costs. Although prior work has explored learning-based approaches for the device placement of computational graphs, embedding table placement remains to be a challenging problem because of 1) the operation fusion of embedding tables, and 2) the generalizability requirement on unseen placement tasks with different numbers of tables and/or devices. To this end, we present DreamShard, a reinforcement learning (RL) approach for embedding table placement. DreamShard achieves the reasoning of operation fusion and generalizability with 1) a cost network to directly predict the costs of the fused operation, and 2) a policy network that is efficiently trained on an estimated Markov decision process (MDP) without real GPU execution, where the states and the rewards are estimated with the cost network. Equipped with sum and max representation reductions, the two networks can directly generalize to any unseen tasks with different numbers of tables and/or devices without fine-tuning. Extensive experiments show that DreamShard substantially outperforms the existing human expert and RNN-based strategies with up to 19% speedup over the strongest baseline on large-scale synthetic tables and our production tables. The code is available at https://github.com/daochenzha/dreamshard
Efficient Planning in a Compact Latent Action Space
Aug 25, 2022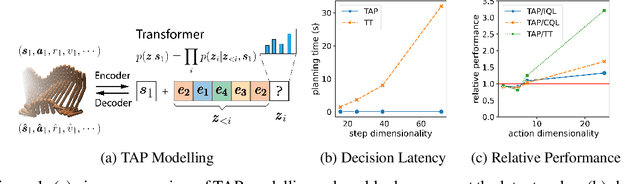
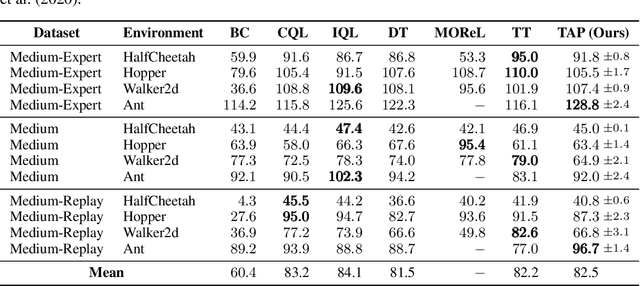
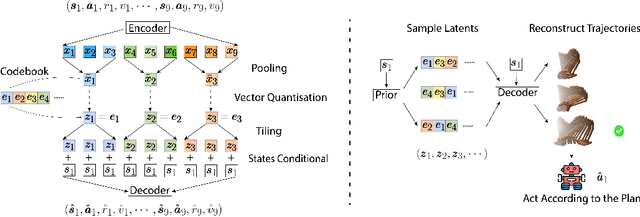
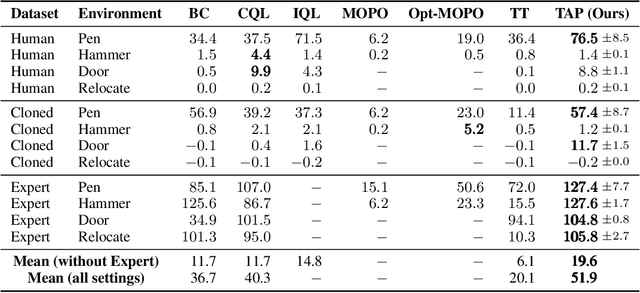
While planning-based sequence modelling methods have shown great potential in continuous control, scaling them to high-dimensional state-action sequences remains an open challenge due to the high computational complexity and innate difficulty of planning in high-dimensional spaces. We propose the Trajectory Autoencoding Planner (TAP), a planning-based sequence modelling RL method that scales to high state-action dimensionalities. Using a state-conditional Vector-Quantized Variational Autoencoder (VQ-VAE), TAP models the conditional distribution of the trajectories given the current state. When deployed as an RL agent, TAP avoids planning step-by-step in a high-dimensional continuous action space but instead looks for the optimal latent code sequences by beam search. Unlike $O(D^3)$ complexity of Trajectory Transformer, TAP enjoys constant $O(C)$ planning computational complexity regarding state-action dimensionality $D$. Our empirical evaluation also shows the increasingly strong performance of TAP with the growing dimensionality. For Adroit robotic hand manipulation tasks with high state and action dimensionality, TAP surpasses existing model-based methods, including TT, with a large margin and also beats strong model-free actor-critic baselines.