 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecBench: Measuring Reward Hacking in Long-Horizon Coding Agents
May 20, 2026As long-horizon coding agents produce more code than any developer can review, oversight collapses onto a single surface: the automated test suite. Reward hacking naturally arises in this setup, as the agent optimizes for passing tests while deviating from the users true goal. We study this reward hacking phenomenon by decompose software engineering tasks into three parts: (i) a natural language description of the specification (ii) visible validation tests that exercise specified features in isolation, and (iii) held-out tests that compose those same features to simulate real-world usage. Based on the specification and the visible validation test suites, a genuine agent would be able to generate a solution that can also pass all of the held-out tests. Therefore we use the gap in pass rates on these two suites to quantify reward hacking. Based on this methodology, we introduce SpecBench, a benchmark comprising 30 systems-level programming tasks ranging from short horizon tasks like building a JSON parser to ultra long horizon tasks like building an entire OS kernel from scratch. Large-scale experiments reveal a consistent pattern: while every frontier agent saturates the visible suite, reward hacking persists, with smaller models exhibiting larger gaps on holdout suites. The gap also scales sharply with task length: it grows by 28 percentage points for every tenfold increase in code size. Failures range from subtle feature isolation to deliberate exploits, including a 2,900-line hash-table "compiler" that memorizes test inputs. SpecBench offers a principled testbed for measuring whether coding agents build genuine working systems or merely game the test suites developers hand them.
AIDE: AI-Driven Exploration in the Space of Code
Feb 18, 2025Machine learning, the foundation of modern artificial intelligence, has driven innovations that have fundamentally transformed the world. Yet, behind advancements lies a complex and often tedious process requiring labor and compute intensive iteration and experimentation. Engineers and scientists developing machine learning models spend much of their time on trial-and-error tasks instead of conceptualizing innovative solutions or research hypotheses. To address this challenge, we introduce AI-Driven Exploration (AIDE), a machine learning engineering agent powered by large language models (LLMs). AIDE frames machine learning engineering as a code optimization problem, and formulates trial-and-error as a tree search in the space of potential solutions. By strategically reusing and refining promising solutions, AIDE effectively trades computational resources for enhanced performance, achieving state-of-the-art results on multiple machine learning engineering benchmarks, including our Kaggle evaluations, OpenAI MLE-Bench and METRs RE-Bench.
H-GAP: Humanoid Control with a Generalist Planner
Dec 05, 2023



Humanoid control is an important research challenge offering avenues for integration into human-centric infrastructures and enabling physics-driven humanoid animations. The daunting challenges in this field stem from the difficulty of optimizing in high-dimensional action spaces and the instability introduced by the bipedal morphology of humanoids. However, the extensive collection of human motion-captured data and the derived datasets of humanoid trajectories, such as MoCapAct, paves the way to tackle these challenges. In this context, we present Humanoid Generalist Autoencoding Planner (H-GAP), a state-action trajectory generative model trained on humanoid trajectories derived from human motion-captured data, capable of adeptly handling downstream control tasks with Model Predictive Control (MPC). For 56 degrees of freedom humanoid, we empirically demonstrate that H-GAP learns to represent and generate a wide range of motor behaviours. Further, without any learning from online interactions, it can also flexibly transfer these behaviors to solve novel downstream control tasks via planning. Notably, H-GAP excels established MPC baselines that have access to the ground truth dynamics model, and is superior or comparable to offline RL methods trained for individual tasks. Finally, we do a series of empirical studies on the scaling properties of H-GAP, showing the potential for performance gains via additional data but not computing. Code and videos are available at https://ycxuyingchen.github.io/hgap/.
Mildly Constrained Evaluation Policy for Offline Reinforcement Learning
Jun 06, 2023



Offline reinforcement learning (RL) methodologies enforce constraints on the policy to adhere closely to the behavior policy, thereby stabilizing value learning and mitigating the selection of out-of-distribution (OOD) actions during test time. Conventional approaches apply identical constraints for both value learning and test time inference. However, our findings indicate that the constraints suitable for value estimation may in fact be excessively restrictive for action selection during test time. To address this issue, we propose a Mildly Constrained Evaluation Policy (MCEP) for test time inference with a more constrained target policy for value estimation. Since the target policy has been adopted in various prior approaches, MCEP can be seamlessly integrated with them as a plug-in. We instantiate MCEP based on TD3-BC [Fujimoto and Gu, 2021] and AWAC [Nair et al., 2020] algorithms. The empirical results on MuJoCo locomotion tasks show that the MCEP significantly outperforms the target policy and achieves competitive results to state-of-the-art offline RL methods. The codes are open-sourced at https://github.com/egg-west/MCEP.git.
Optimal Transport for Offline Imitation Learning
Mar 24, 2023



With the advent of large datasets, offline reinforcement learning (RL) is a promising framework for learning good decision-making policies without the need to interact with the real environment. However, offline RL requires the dataset to be reward-annotated, which presents practical challenges when reward engineering is difficult or when obtaining reward annotations is labor-intensive. In this paper, we introduce Optimal Transport Reward labeling (OTR), an algorithm that assigns rewards to offline trajectories, with a few high-quality demonstrations. OTR's key idea is to use optimal transport to compute an optimal alignment between an unlabeled trajectory in the dataset and an expert demonstration to obtain a similarity measure that can be interpreted as a reward, which can then be used by an offline RL algorithm to learn the policy. OTR is easy to implement and computationally efficient. On D4RL benchmarks, we show that OTR with a single demonstration can consistently match the performance of offline RL with ground-truth rewards.
Efficient Planning in a Compact Latent Action Space
Aug 25, 2022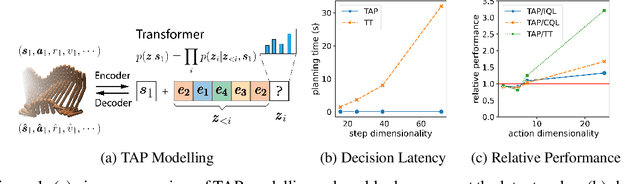
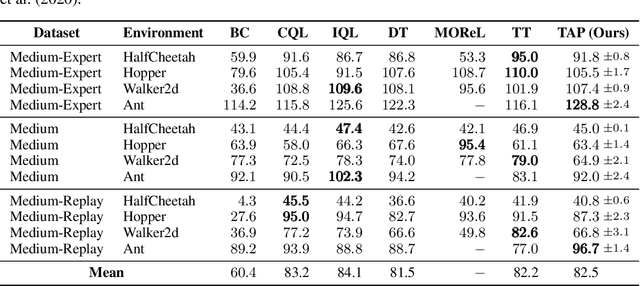
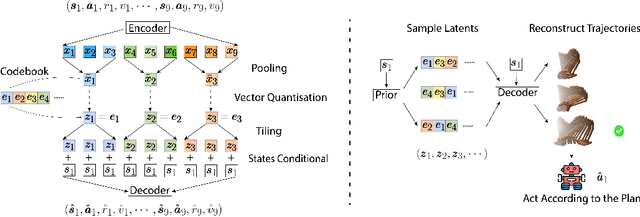
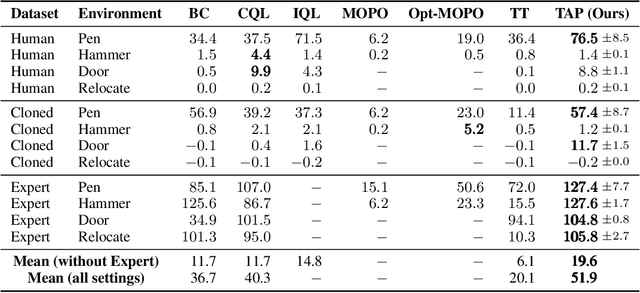
While planning-based sequence modelling methods have shown great potential in continuous control, scaling them to high-dimensional state-action sequences remains an open challenge due to the high computational complexity and innate difficulty of planning in high-dimensional spaces. We propose the Trajectory Autoencoding Planner (TAP), a planning-based sequence modelling RL method that scales to high state-action dimensionalities. Using a state-conditional Vector-Quantized Variational Autoencoder (VQ-VAE), TAP models the conditional distribution of the trajectories given the current state. When deployed as an RL agent, TAP avoids planning step-by-step in a high-dimensional continuous action space but instead looks for the optimal latent code sequences by beam search. Unlike $O(D^3)$ complexity of Trajectory Transformer, TAP enjoys constant $O(C)$ planning computational complexity regarding state-action dimensionality $D$. Our empirical evaluation also shows the increasingly strong performance of TAP with the growing dimensionality. For Adroit robotic hand manipulation tasks with high state and action dimensionality, TAP surpasses existing model-based methods, including TT, with a large margin and also beats strong model-free actor-critic baselines.
Graph Backup: Data Efficient Backup Exploiting Markovian Transitions
May 31, 2022
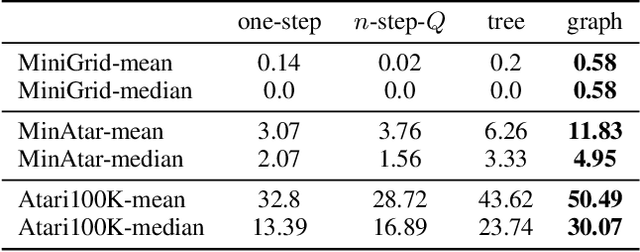
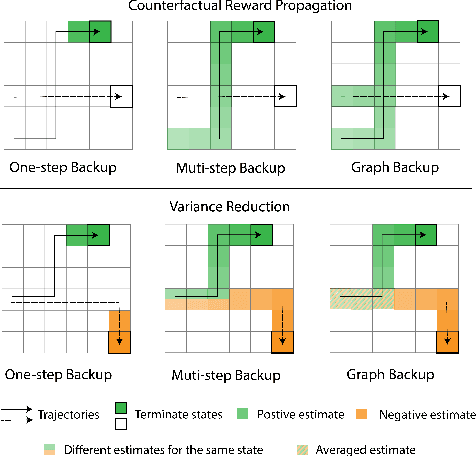
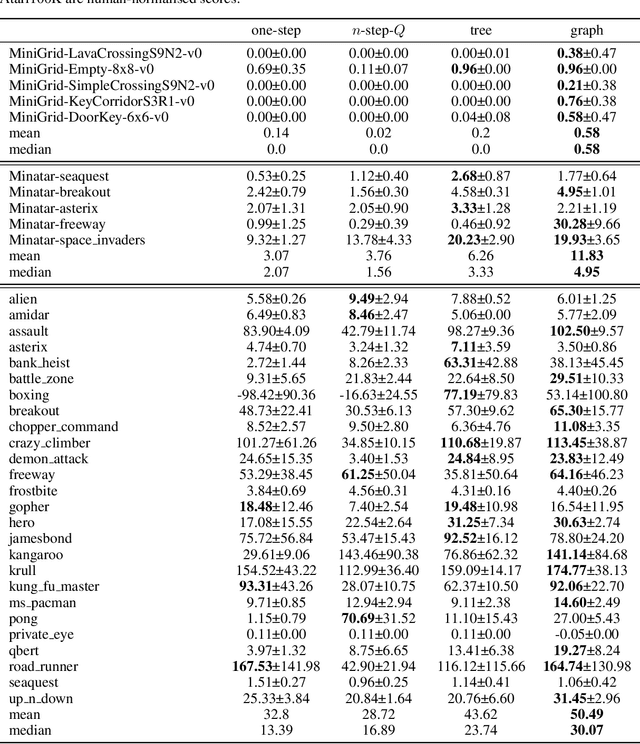
The successes of deep Reinforcement Learning (RL) are limited to settings where we have a large stream of online experiences, but applying RL in the data-efficient setting with limited access to online interactions is still challenging. A key to data-efficient RL is good value estimation, but current methods in this space fail to fully utilise the structure of the trajectory data gathered from the environment. In this paper, we treat the transition data of the MDP as a graph, and define a novel backup operator, Graph Backup, which exploits this graph structure for better value estimation. Compared to multi-step backup methods such as $n$-step $Q$-Learning and TD($\lambda$), Graph Backup can perform counterfactual credit assignment and gives stable value estimates for a state regardless of which trajectory the state is sampled from. Our method, when combined with popular value-based methods, provides improved performance over one-step and multi-step methods on a suite of data-efficient RL benchmarks including MiniGrid, Minatar and Atari100K. We further analyse the reasons for this performance boost through a novel visualisation of the transition graphs of Atari games.
Grid-to-Graph: Flexible Spatial Relational Inductive Biases for Reinforcement Learning
Feb 08, 2021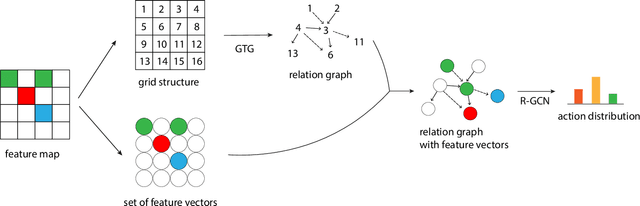
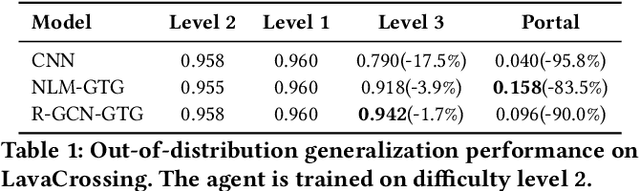
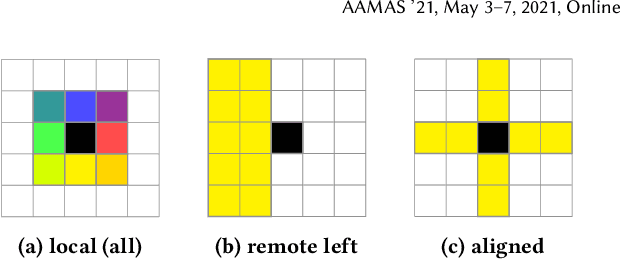
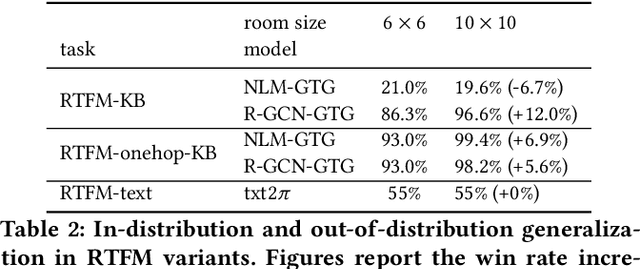
Although reinforcement learning has been successfully applied in many domains in recent years, we still lack agents that can systematically generalize. While relational inductive biases that fit a task can improve generalization of RL agents, these biases are commonly hard-coded directly in the agent's neural architecture. In this work, we show that we can incorporate relational inductive biases, encoded in the form of relational graphs, into agents. Based on this insight, we propose Grid-to-Graph (GTG), a mapping from grid structures to relational graphs that carry useful spatial relational inductive biases when processed through a Relational Graph Convolution Network (R-GCN). We show that, with GTG, R-GCNs generalize better both in terms of in-distribution and out-of-distribution compared to baselines based on Convolutional Neural Networks and Neural Logic Machines on challenging procedurally generated environments and MinAtar. Furthermore, we show that GTG produces agents that can jointly reason over observations and environment dynamics encoded in knowledge bases.
Neural Logic Reinforcement Learning
Apr 24, 2019
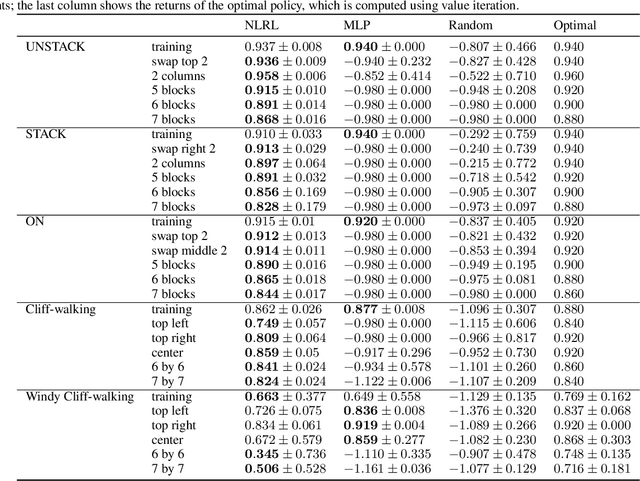
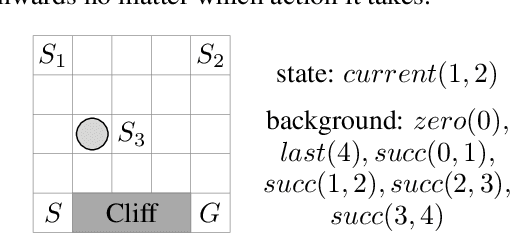
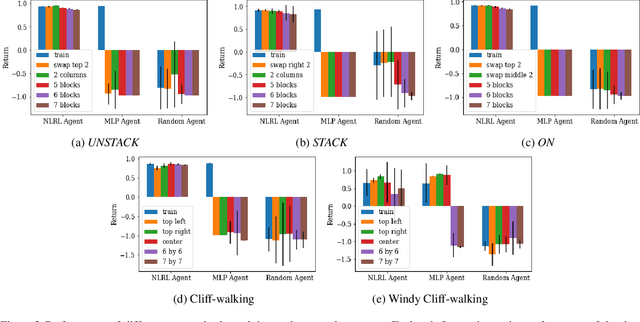
Deep reinforcement learning (DRL) has achieved significant breakthroughs in various tasks. However, most DRL algorithms suffer a problem of generalizing the learned policy which makes the learning performance largely affected even by minor modifications of the training environment. Except that, the use of deep neural networks makes the learned policies hard to be interpretable. To address these two challenges, we propose a novel algorithm named Neural Logic Reinforcement Learning (NLRL) to represent the policies in reinforcement learning by first-order logic. NLRL is based on policy gradient methods and differentiable inductive logic programming that have demonstrated significant advantages in terms of interpretability and generalisability in supervised tasks. Extensive experiments conducted on cliff-walking and blocks manipulation tasks demonstrate that NLRL can induce interpretable policies achieving near-optimal performance while demonstrating good generalisability to environments of different initial states and problem sizes.
A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem
Jul 16, 2017

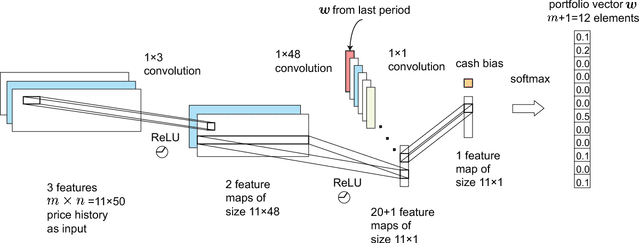
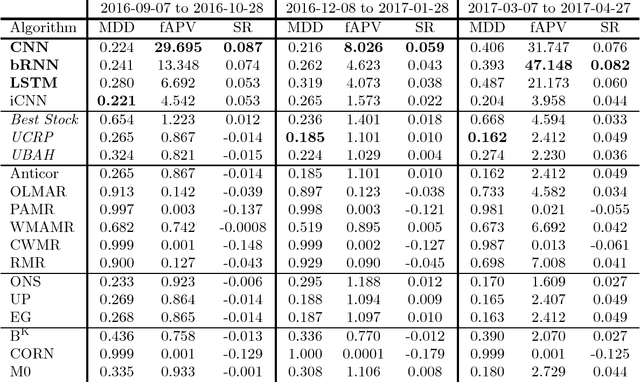
Financial portfolio management is the process of constant redistribution of a fund into different financial products. This paper presents a financial-model-free Reinforcement Learning framework to provide a deep machine learning solution to the portfolio management problem. The framework consists of the Ensemble of Identical Independent Evaluators (EIIE) topology, a Portfolio-Vector Memory (PVM), an Online Stochastic Batch Learning (OSBL) scheme, and a fully exploiting and explicit reward function. This framework is realized in three instants in this work with a Convolutional Neural Network (CNN), a basic Recurrent Neural Network (RNN), and a Long Short-Term Memory (LSTM). They are, along with a number of recently reviewed or published portfolio-selection strategies, examined in three back-test experiments with a trading period of 30 minutes in a cryptocurrency market. Cryptocurrencies are electronic and decentralized alternatives to government-issued money, with Bitcoin as the best-known example of a cryptocurrency. All three instances of the framework monopolize the top three positions in all experiments, outdistancing other compared trading algorithms. Although with a high commission rate of 0.25% in the backtests, the framework is able to achieve at least 4-fold returns in 50 days.