 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaleCrafter: Interactive Story Visualization with Multiple Characters
May 30, 2023



Accurate Story visualization requires several necessary elements, such as identity consistency across frames, the alignment between plain text and visual content, and a reasonable layout of objects in images. Most previous works endeavor to meet these requirements by fitting a text-to-image (T2I) model on a set of videos in the same style and with the same characters, e.g., the FlintstonesSV dataset. However, the learned T2I models typically struggle to adapt to new characters, scenes, and styles, and often lack the flexibility to revise the layout of the synthesized images. This paper proposes a system for generic interactive story visualization, capable of handling multiple novel characters and supporting the editing of layout and local structure. It is developed by leveraging the prior knowledge of large language and T2I models, trained on massive corpora. The system comprises four interconnected components: story-to-prompt generation (S2P), text-to-layout generation (T2L), controllable text-to-image generation (C-T2I), and image-to-video animation (I2V). First, the S2P module converts concise story information into detailed prompts required for subsequent stages. Next, T2L generates diverse and reasonable layouts based on the prompts, offering users the ability to adjust and refine the layout to their preference. The core component, C-T2I, enables the creation of images guided by layouts, sketches, and actor-specific identifiers to maintain consistency and detail across visualizations. Finally, I2V enriches the visualization process by animating the generated images. Extensive experiments and a user study are conducted to validate the effectiveness and flexibility of interactive editing of the proposed system.
SAIL: Search-Augmented Instruction Learning
May 24, 2023



Large language models (LLMs) have been significantly improved by instruction fine-tuning, but still lack transparency and the ability to utilize up-to-date knowledge and information. In this work, we propose search-augmented instruction learning (SAIL), which grounds the language generation and instruction following abilities on complex search results generated by in-house and external search engines. With an instruction tuning corpus, we collect search results for each training case from different search APIs and domains, and construct a new search-grounded training set containing \textit{(instruction, grounding information, response)} triplets. We then fine-tune the LLaMA-7B model on the constructed training set. Since the collected results contain unrelated and disputing languages, the model needs to learn to ground on trustworthy search results, filter out distracting passages, and generate the target response. The search result-denoising process entails explicit trustworthy information selection and multi-hop reasoning, since the retrieved passages might be informative but not contain the instruction-following answer. Experiments show that the fine-tuned SAIL-7B model has a strong instruction-following ability, and it performs significantly better on transparency-sensitive tasks, including open-ended question answering and fact checking.
Listen, Think, and Understand
May 18, 2023



The ability of artificial intelligence (AI) systems to perceive and comprehend audio signals is crucial for many applications. Although significant progress has been made in this area since the development of AudioSet, most existing models are designed to map audio inputs to pre-defined, discrete sound label sets. In contrast, humans possess the ability to not only classify sounds into coarse-grained categories, but also to listen to the details of the sounds, explain the reason for the predictions, think what the sound infers, and understand the scene and what action needs to be taken. Such capabilities beyond perception are not yet present in existing audio models. On the other hand, modern large language models (LLMs) exhibit emerging reasoning ability but they lack audio perception capabilities. Therefore, we ask the question: can we build an AI model that has both audio perception and a reasoning ability? In this paper, we propose a novel audio foundation model, called LTU (Listen, Think, and Understand). To train LTU, we created a new OpenAQA-5M dataset consisting of 1.9 million closed-ended and 3.7 million open-ended, diverse (audio, question, answer) tuples, and used an autoregressive training framework and a perception-to-understanding curriculum. LTU demonstrates strong performance and generalization ability on conventional audio tasks such as classification and captioning. Moreover, it exhibits remarkable reasoning and comprehension abilities in the audio domain. To the best of our knowledge, LTU is the first audio-enabled large language model that bridges audio perception with advanced reasoning.
3D GAN Inversion with Facial Symmetry Prior
Nov 30, 2022



Recently, a surge of high-quality 3D-aware GANs have been proposed, which leverage the generative power of neural rendering. It is natural to associate 3D GANs with GAN inversion methods to project a real image into the generator's latent space, allowing free-view consistent synthesis and editing, referred as 3D GAN inversion. Although with the facial prior preserved in pre-trained 3D GANs, reconstructing a 3D portrait with only one monocular image is still an ill-pose problem. The straightforward application of 2D GAN inversion methods focuses on texture similarity only while ignoring the correctness of 3D geometry shapes. It may raise geometry collapse effects, especially when reconstructing a side face under an extreme pose. Besides, the synthetic results in novel views are prone to be blurry. In this work, we propose a novel method to promote 3D GAN inversion by introducing facial symmetry prior. We design a pipeline and constraints to make full use of the pseudo auxiliary view obtained via image flipping, which helps obtain a robust and reasonable geometry shape during the inversion process. To enhance texture fidelity in unobserved viewpoints, pseudo labels from depth-guided 3D warping can provide extra supervision. We design constraints aimed at filtering out conflict areas for optimization in asymmetric situations. Comprehensive quantitative and qualitative evaluations on image reconstruction and editing demonstrate the superiority of our method.
MAP: Modality-Agnostic Uncertainty-Aware Vision-Language Pre-training Model
Oct 11, 2022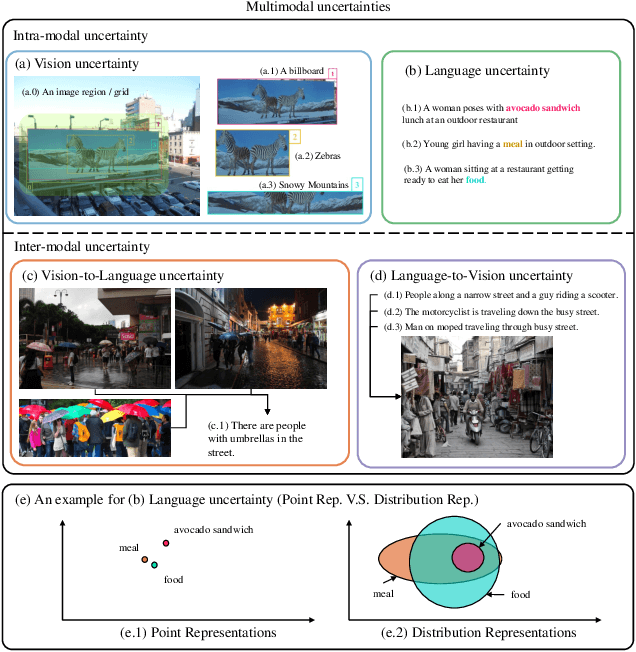
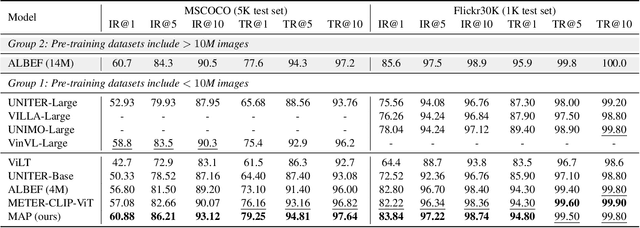
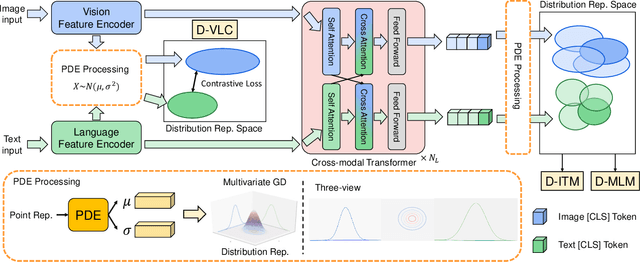
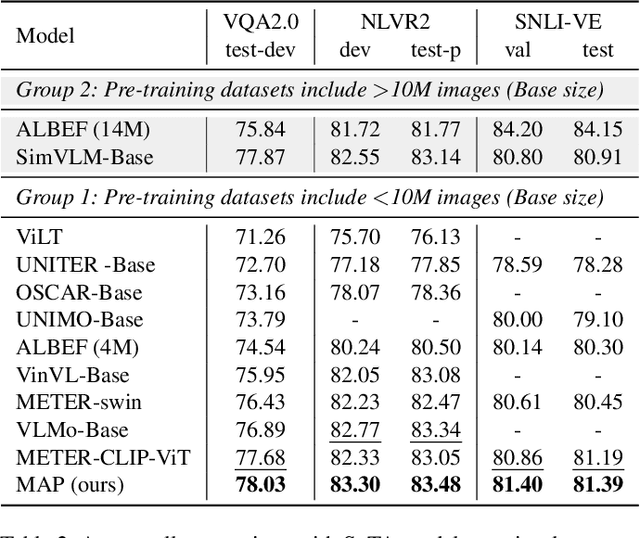
Multimodal semantic understanding often has to deal with uncertainty, which means the obtained message tends to refer to multiple targets. Such uncertainty is problematic for our interpretation, including intra-modal and inter-modal uncertainty. Little effort studies the modeling of this uncertainty, particularly in pre-training on unlabeled datasets and fine-tuning in task-specific downstream tasks. To address this, we project the representations of all modalities as probabilistic distributions via a Probability Distribution Encoder (PDE) by utilizing rich multimodal semantic information. Furthermore, we integrate uncertainty modeling with popular pre-training frameworks and propose suitable pre-training tasks: Distribution-based Vision-Language Contrastive learning (D-VLC), Distribution-based Masked Language Modeling (D-MLM), and Distribution-based Image-Text Matching (D-ITM). The fine-tuned models are applied to challenging downstream tasks, including image-text retrieval, visual question answering, visual reasoning, and visual entailment, and achieve state-of-the-art results. Code is released at https://github.com/IIGROUP/MAP.
Rethinking Knowledge Distillation via Cross-Entropy
Aug 22, 2022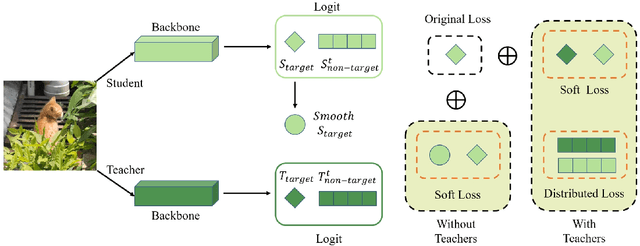
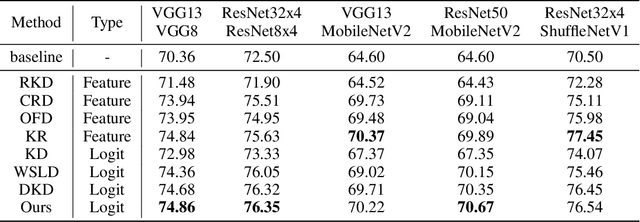
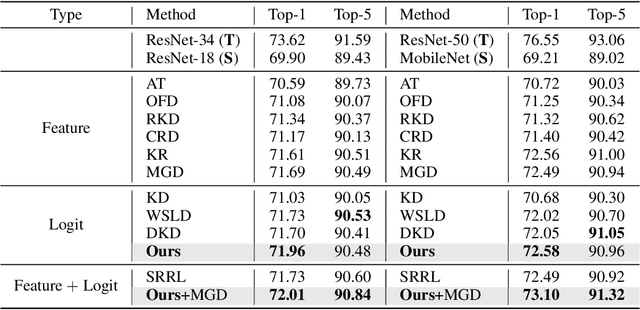
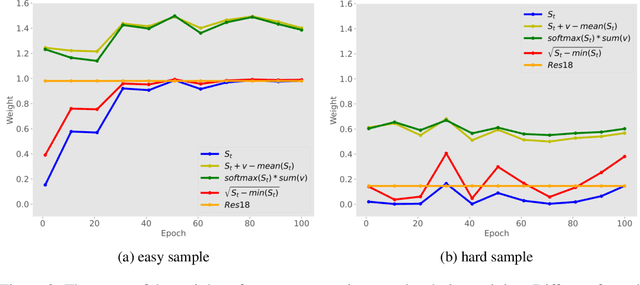
Knowledge Distillation (KD) has developed extensively and boosted various tasks. The classical KD method adds the KD loss to the original cross-entropy (CE) loss. We try to decompose the KD loss to explore its relation with the CE loss. Surprisingly, we find it can be regarded as a combination of the CE loss and an extra loss which has the identical form as the CE loss. However, we notice the extra loss forces the student's relative probability to learn the teacher's absolute probability. Moreover, the sum of the two probabilities is different, making it hard to optimize. To address this issue, we revise the formulation and propose a distributed loss. In addition, we utilize teachers' target output as the soft target, proposing the soft loss. Combining the soft loss and the distributed loss, we propose a new KD loss (NKD). Furthermore, we smooth students' target output to treat it as the soft target for training without teachers and propose a teacher-free new KD loss (tf-NKD). Our method achieves state-of-the-art performance on CIFAR-100 and ImageNet. For example, with ResNet-34 as the teacher, we boost the ImageNet Top-1 accuracy of ResNet18 from 69.90% to 71.96%. In training without teachers, MobileNet, ResNet-18 and SwinTransformer-Tiny achieve 70.04%, 70.76%, and 81.48%, which are 0.83%, 0.86%, and 0.30% higher than the baseline, respectively. The code is available at https://github.com/yzd-v/cls_KD.
UAVM: A Unified Model for Audio-Visual Learning
Jul 29, 2022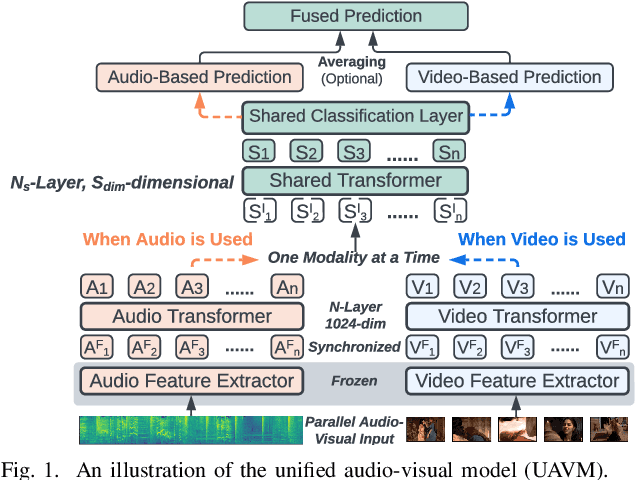
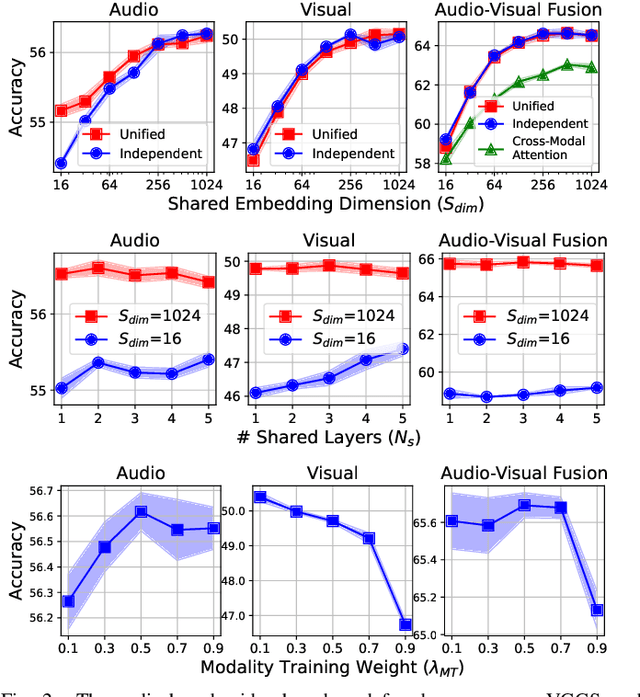
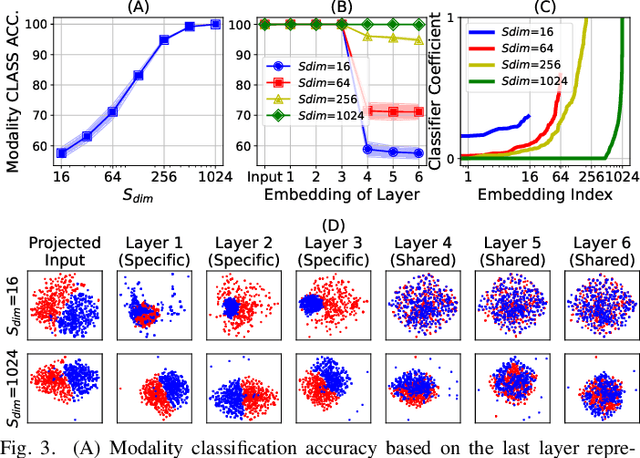
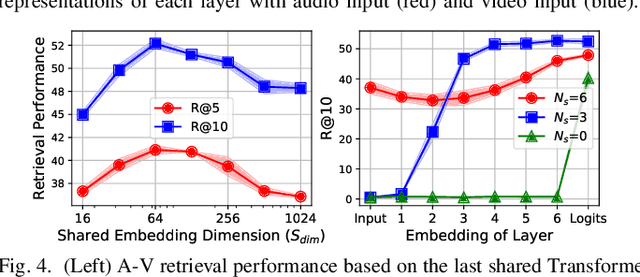
Conventional audio-visual models have independent audio and video branches. We design a unified model for audio and video processing called Unified Audio-Visual Model (UAVM). In this paper, we describe UAVM, report its new state-of-the-art audio-visual event classification accuracy of 65.8% on VGGSound, and describe the intriguing properties of the model.
Vocalsound: A Dataset for Improving Human Vocal Sounds Recognition
May 06, 2022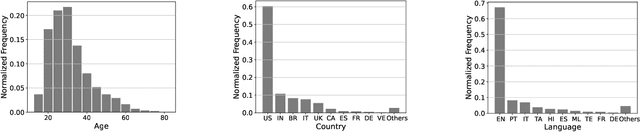
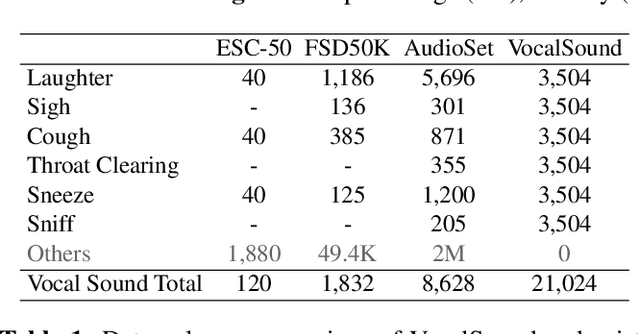
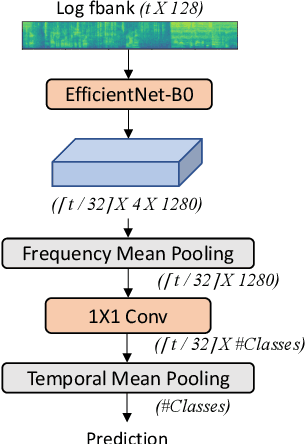
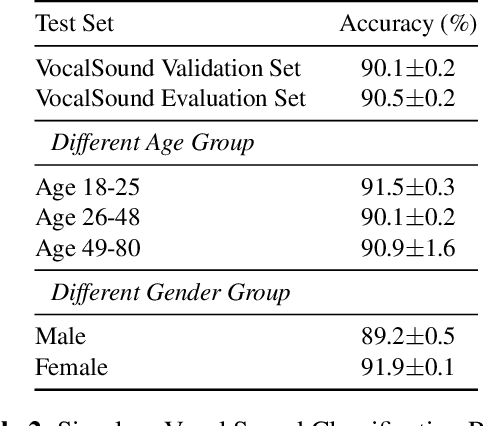
Recognizing human non-speech vocalizations is an important task and has broad applications such as automatic sound transcription and health condition monitoring. However, existing datasets have a relatively small number of vocal sound samples or noisy labels. As a consequence, state-of-the-art audio event classification models may not perform well in detecting human vocal sounds. To support research on building robust and accurate vocal sound recognition, we have created a VocalSound dataset consisting of over 21,000 crowdsourced recordings of laughter, sighs, coughs, throat clearing, sneezes, and sniffs from 3,365 unique subjects. Experiments show that the vocal sound recognition performance of a model can be significantly improved by 41.9% by adding VocalSound dataset to an existing dataset as training material. In addition, different from previous datasets, the VocalSound dataset contains meta information such as speaker age, gender, native language, country, and health condition.
Transformer-Based Multi-Aspect Multi-Granularity Non-Native English Speaker Pronunciation Assessment
May 06, 2022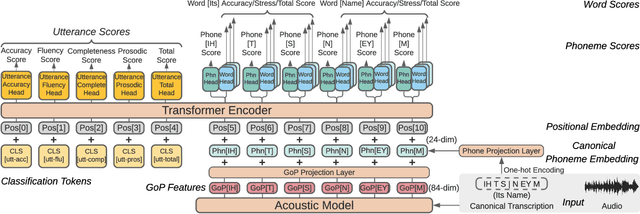
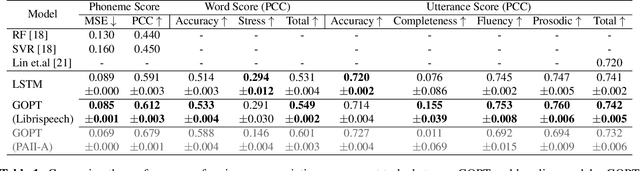
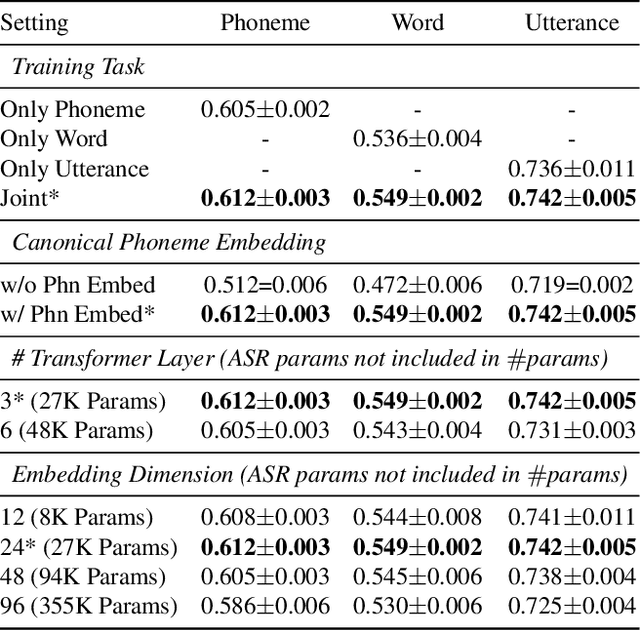

Automatic pronunciation assessment is an important technology to help self-directed language learners. While pronunciation quality has multiple aspects including accuracy, fluency, completeness, and prosody, previous efforts typically only model one aspect (e.g., accuracy) at one granularity (e.g., at the phoneme-level). In this work, we explore modeling multi-aspect pronunciation assessment at multiple granularities. Specifically, we train a Goodness Of Pronunciation feature-based Transformer (GOPT) with multi-task learning. Experiments show that GOPT achieves the best results on speechocean762 with a public automatic speech recognition (ASR) acoustic model trained on Librispeech.
Attentions Help CNNs See Better: Attention-based Hybrid Image Quality Assessment Network
Apr 22, 2022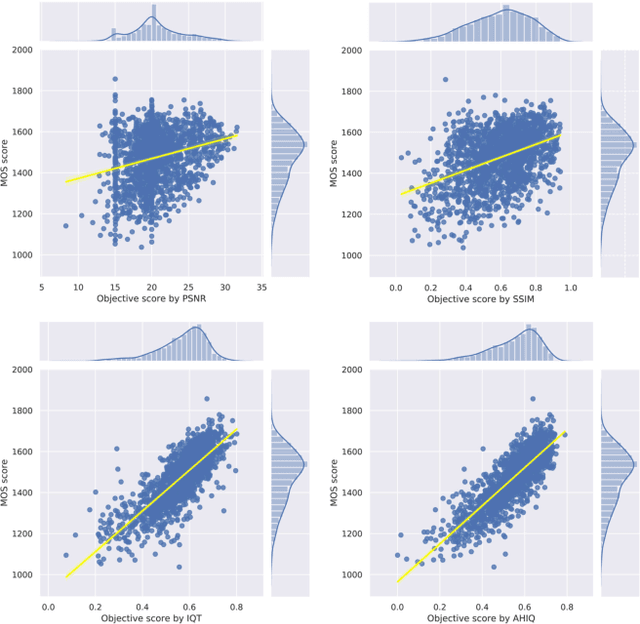

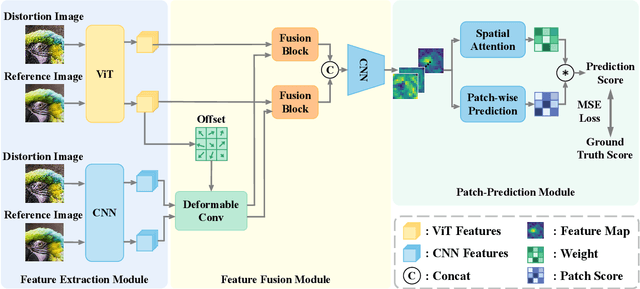
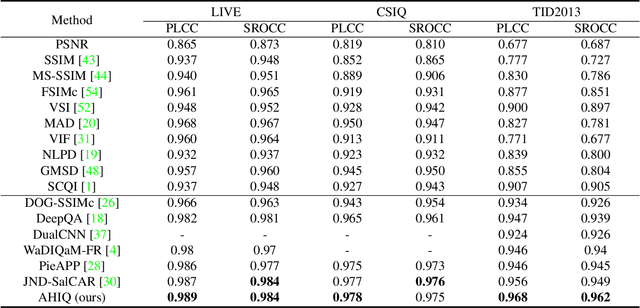
Image quality assessment (IQA) algorithm aims to quantify the human perception of image quality. Unfortunately, there is a performance drop when assessing the distortion images generated by generative adversarial network (GAN) with seemingly realistic texture. In this work, we conjecture that this maladaptation lies in the backbone of IQA models, where patch-level prediction methods use independent image patches as input to calculate their scores separately, but lack spatial relationship modeling among image patches. Therefore, we propose an Attention-based Hybrid Image Quality Assessment Network (AHIQ) to deal with the challenge and get better performance on the GAN-based IQA task. Firstly, we adopt a two-branch architecture, including a vision transformer (ViT) branch and a convolutional neural network (CNN) branch for feature extraction. The hybrid architecture combines interaction information among image patches captured by ViT and local texture details from CNN. To make the features from shallow CNN more focused on the visually salient region, a deformable convolution is applied with the help of semantic information from the ViT branch. Finally, we use a patch-wise score prediction module to obtain the final score. The experiments show that our model outperforms the state-of-the-art methods on four standard IQA datasets and AHIQ ranked first on the Full Reference (FR) track of the NTIRE 2022 Perceptual Image Quality Assessment Challenge.