 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaViC: Adapting Large Vision-Language Models to Visually-Aware Conversational Recommendation
Mar 30, 2025



Conversational recommender systems engage users in dialogues to refine their needs and provide more personalized suggestions. Although textual information suffices for many domains, visually driven categories such as fashion or home decor potentially require detailed visual information related to color, style, or design. To address this challenge, we propose LaViC (Large Vision-Language Conversational Recommendation Framework), a novel approach that integrates compact image representations into dialogue-based recommendation systems. LaViC leverages a large vision-language model in a two-stage process: (1) visual knowledge self-distillation, which condenses product images from hundreds of tokens into a small set of visual tokens in a self-distillation manner, significantly reducing computational overhead, and (2) recommendation prompt tuning, which enables the model to incorporate both dialogue context and distilled visual tokens, providing a unified mechanism for capturing textual and visual features. To support rigorous evaluation of visually-aware conversational recommendation, we construct a new dataset by aligning Reddit conversations with Amazon product listings across multiple visually oriented categories (e.g., fashion, beauty, and home). This dataset covers realistic user queries and product appearances in domains where visual details are crucial. Extensive experiments demonstrate that LaViC significantly outperforms text-only conversational recommendation methods and open-source vision-language baselines. Moreover, LaViC achieves competitive or superior accuracy compared to prominent proprietary baselines (e.g., GPT-3.5-turbo, GPT-4o-mini, and GPT-4o), demonstrating the necessity of explicitly using visual data for capturing product attributes and showing the effectiveness of our vision-language integration. Our code and dataset are available at https://github.com/jeon185/LaViC.
D3-Guard: Acoustic-based Drowsy Driving Detection Using Smartphones
Mar 30, 2025



Since the number of cars has grown rapidly in recent years, driving safety draws more and more public attention. Drowsy driving is one of the biggest threatens to driving safety. Therefore, a simple but robust system that can detect drowsy driving with commercial off-the-shelf devices (such as smartphones) is very necessary. With this motivation, we explore the feasibility of purely using acoustic sensors embedded in smartphones to detect drowsy driving. We first study characteristics of drowsy driving, and find some unique patterns of Doppler shift caused by three typical drowsy behaviors, i.e. nodding, yawning and operating steering wheel. We then validate our important findings through empirical analysis of the driving data collected from real driving environments. We further propose a real-time Drowsy Driving Detection system (D3-Guard) based on audio devices embedded in smartphones. In order to improve the performance of our system, we adopt an effective feature extraction method based on undersampling technique and FFT, and carefully design a high-accuracy detector based on LSTM networks for the early detection of drowsy driving. Through extensive experiments with 5 volunteer drivers in real driving environments, our system can distinguish drowsy driving actions with an average total accuracy of 93.31% in real-time. Over 80% drowsy driving actions can be detected within first 70% of action duration.
HearFit+: Personalized Fitness Monitoring via Audio Signals on Smart Speakers
Mar 30, 2025



Fitness can help to strengthen muscles, increase resistance to diseases, and improve body shape. Nowadays, a great number of people choose to exercise at home/office rather than at the gym due to lack of time. However, it is difficult for them to get good fitness effects without professional guidance. Motivated by this, we propose the first personalized fitness monitoring system, HearFit+, using smart speakers at home/office. We explore the feasibility of using acoustic sensing to monitor fitness. We design a fitness detection method based on Doppler shift and adopt the short time energy to segment fitness actions. Based on deep learning, HearFit+ can perform fitness classification and user identification at the same time. Combined with incremental learning, users can easily add new actions. We design 4 evaluation metrics (i.e., duration, intensity, continuity, and smoothness) to help users to improve fitness effects. Through extensive experiments including over 9,000 actions of 10 types of fitness from 12 volunteers, HearFit+ can achieve an average accuracy of 96.13% on fitness classification and 91% accuracy for user identification. All volunteers confirm that HearFit+ can help improve the fitness effect in various environments.
DiTFastAttnV2: Head-wise Attention Compression for Multi-Modality Diffusion Transformers
Mar 28, 2025
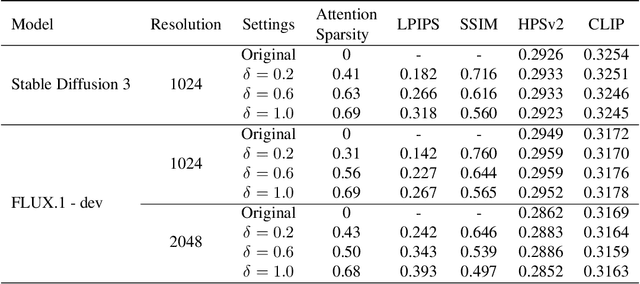
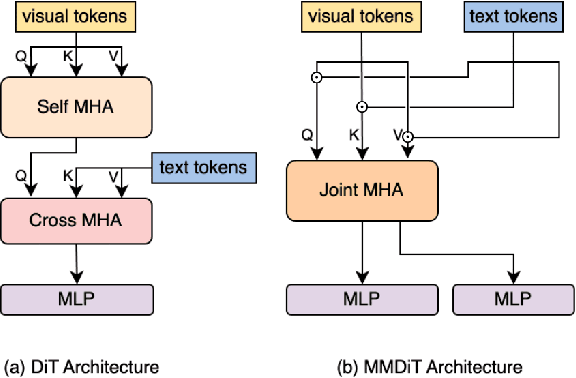
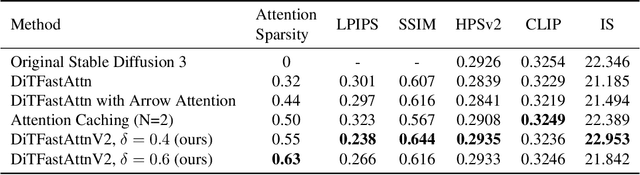
Text-to-image generation models, especially Multimodal Diffusion Transformers (MMDiT), have shown remarkable progress in generating high-quality images. However, these models often face significant computational bottlenecks, particularly in attention mechanisms, which hinder their scalability and efficiency. In this paper, we introduce DiTFastAttnV2, a post-training compression method designed to accelerate attention in MMDiT. Through an in-depth analysis of MMDiT's attention patterns, we identify key differences from prior DiT-based methods and propose head-wise arrow attention and caching mechanisms to dynamically adjust attention heads, effectively bridging this gap. We also design an Efficient Fused Kernel for further acceleration. By leveraging local metric methods and optimization techniques, our approach significantly reduces the search time for optimal compression schemes to just minutes while maintaining generation quality. Furthermore, with the customized kernel, DiTFastAttnV2 achieves a 68% reduction in attention FLOPs and 1.5x end-to-end speedup on 2K image generation without compromising visual fidelity.
AED: Automatic Discovery of Effective and Diverse Vulnerabilities for Autonomous Driving Policy with Large Language Models
Mar 24, 2025



Assessing the safety of autonomous driving policy is of great importance, and reinforcement learning (RL) has emerged as a powerful method for discovering critical vulnerabilities in driving policies. However, existing RL-based approaches often struggle to identify vulnerabilities that are both effective-meaning the autonomous vehicle is genuinely responsible for the accidents-and diverse-meaning they span various failure types. To address these challenges, we propose AED, a framework that uses large language models (LLMs) to automatically discover effective and diverse vulnerabilities in autonomous driving policies. We first utilize an LLM to automatically design reward functions for RL training. Then we let the LLM consider a diverse set of accident types and train adversarial policies for different accident types in parallel. Finally, we use preference-based learning to filter ineffective accidents and enhance the effectiveness of each vulnerability. Experiments across multiple simulated traffic scenarios and tested policies show that AED uncovers a broader range of vulnerabilities and achieves higher attack success rates compared with expert-designed rewards, thereby reducing the need for manual reward engineering and improving the diversity and effectiveness of vulnerability discovery.
Probabilistic Prompt Distribution Learning for Animal Pose Estimation
Mar 20, 2025



Multi-species animal pose estimation has emerged as a challenging yet critical task, hindered by substantial visual diversity and uncertainty. This paper challenges the problem by efficient prompt learning for Vision-Language Pretrained (VLP) models, \textit{e.g.} CLIP, aiming to resolve the cross-species generalization problem. At the core of the solution lies in the prompt designing, probabilistic prompt modeling and cross-modal adaptation, thereby enabling prompts to compensate for cross-modal information and effectively overcome large data variances under unbalanced data distribution. To this end, we propose a novel probabilistic prompting approach to fully explore textual descriptions, which could alleviate the diversity issues caused by long-tail property and increase the adaptability of prompts on unseen category instance. Specifically, we first introduce a set of learnable prompts and propose a diversity loss to maintain distinctiveness among prompts, thus representing diverse image attributes. Diverse textual probabilistic representations are sampled and used as the guidance for the pose estimation. Subsequently, we explore three different cross-modal fusion strategies at spatial level to alleviate the adverse impacts of visual uncertainty. Extensive experiments on multi-species animal pose benchmarks show that our method achieves the state-of-the-art performance under both supervised and zero-shot settings. The code is available at https://github.com/Raojiyong/PPAP.
Empowering GraphRAG with Knowledge Filtering and Integration
Mar 18, 2025In recent years, large language models (LLMs) have revolutionized the field of natural language processing. However, they often suffer from knowledge gaps and hallucinations. Graph retrieval-augmented generation (GraphRAG) enhances LLM reasoning by integrating structured knowledge from external graphs. However, we identify two key challenges that plague GraphRAG:(1) Retrieving noisy and irrelevant information can degrade performance and (2)Excessive reliance on external knowledge suppresses the model's intrinsic reasoning. To address these issues, we propose GraphRAG-FI (Filtering and Integration), consisting of GraphRAG-Filtering and GraphRAG-Integration. GraphRAG-Filtering employs a two-stage filtering mechanism to refine retrieved information. GraphRAG-Integration employs a logits-based selection strategy to balance external knowledge from GraphRAG with the LLM's intrinsic reasoning,reducing over-reliance on retrievals. Experiments on knowledge graph QA tasks demonstrate that GraphRAG-FI significantly improves reasoning performance across multiple backbone models, establishing a more reliable and effective GraphRAG framework.
MEET: A Million-Scale Dataset for Fine-Grained Geospatial Scene Classification with Zoom-Free Remote Sensing Imagery
Mar 14, 2025Accurate fine-grained geospatial scene classification using remote sensing imagery is essential for a wide range of applications. However, existing approaches often rely on manually zooming remote sensing images at different scales to create typical scene samples. This approach fails to adequately support the fixed-resolution image interpretation requirements in real-world scenarios. To address this limitation, we introduce the Million-scale finE-grained geospatial scEne classification dataseT (MEET), which contains over 1.03 million zoom-free remote sensing scene samples, manually annotated into 80 fine-grained categories. In MEET, each scene sample follows a scene-inscene layout, where the central scene serves as the reference, and auxiliary scenes provide crucial spatial context for finegrained classification. Moreover, to tackle the emerging challenge of scene-in-scene classification, we present the Context-Aware Transformer (CAT), a model specifically designed for this task, which adaptively fuses spatial context to accurately classify the scene samples. CAT adaptively fuses spatial context to accurately classify the scene samples by learning attentional features that capture the relationships between the center and auxiliary scenes. Based on MEET, we establish a comprehensive benchmark for fine-grained geospatial scene classification, evaluating CAT against 11 competitive baselines. The results demonstrate that CAT significantly outperforms these baselines, achieving a 1.88% higher balanced accuracy (BA) with the Swin-Large backbone, and a notable 7.87% improvement with the Swin-Huge backbone. Further experiments validate the effectiveness of each module in CAT and show the practical applicability of CAT in the urban functional zone mapping. The source code and dataset will be publicly available at https://jerrywyn.github.io/project/MEET.html.
RankPO: Preference Optimization for Job-Talent Matching
Mar 13, 2025Matching job descriptions (JDs) with suitable talent requires models capable of understanding not only textual similarities between JDs and candidate resumes but also contextual factors such as geographical location and academic seniority. To address this challenge, we propose a two-stage training framework for large language models (LLMs). In the first stage, a contrastive learning approach is used to train the model on a dataset constructed from real-world matching rules, such as geographical alignment and research area overlap. While effective, this model primarily learns patterns that defined by the matching rules. In the second stage, we introduce a novel preference-based fine-tuning method inspired by Direct Preference Optimization (DPO), termed Rank Preference Optimization (RankPO), to align the model with AI-curated pairwise preferences emphasizing textual understanding. Our experiments show that while the first-stage model achieves strong performance on rule-based data (nDCG@20 = 0.706), it lacks robust textual understanding (alignment with AI annotations = 0.46). By fine-tuning with RankPO, we achieve a balanced model that retains relatively good performance in the original tasks while significantly improving the alignment with AI preferences. The code and data are available at https://github.com/yflyzhang/RankPO.
Concept-Driven Deep Learning for Enhanced Protein-Specific Molecular Generation
Mar 11, 2025In recent years, deep learning techniques have made significant strides in molecular generation for specific targets, driving advancements in drug discovery. However, existing molecular generation methods present significant limitations: those operating at the atomic level often lack synthetic feasibility, drug-likeness, and interpretability, while fragment-based approaches frequently overlook comprehensive factors that influence protein-molecule interactions. To address these challenges, we propose a novel fragment-based molecular generation framework tailored for specific proteins. Our method begins by constructing a protein subpocket and molecular arm concept-based neural network, which systematically integrates interaction force information and geometric complementarity to sample molecular arms for specific protein subpockets. Subsequently, we introduce a diffusion model to generate molecular backbones that connect these arms, ensuring structural integrity and chemical diversity. Our approach significantly improves synthetic feasibility and binding affinity, with a 4% increase in drug-likeness and a 6% improvement in synthetic feasibility. Furthermore, by integrating explicit interaction data through a concept-based model, our framework enhances interpretability, offering valuable insights into the molecular design process.