 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOMA-SQL: Resolving Multi-Source Ambiguity in NL-to-SQL via Synthetic Log and Execution Probing
Jun 09, 2026Natural language interfaces to databases aim to translate user questions into executable SQL, yet remain brittle in real-world settings where questions are underspecified and schemas are large and ambiguous. Ambiguity across user questions, database schemas, and model interpretations are central failure modes in NL2SQL, leading to misaligned intent, incorrect schema grounding, and erroneous SQL generation. Existing approaches rely on human clarification or treat ambiguity as a schema representation problem, but these do not scale nor resolve ambiguity autonomously. We propose SOMA-SQL to automatically resolve ambiguity via targeted synthetic query log and ambiguity-driven probing. SOMA-SQL constructs synthetic query log to ground schema interpretation and guide candidate SQL generation; it then executes targeted probing queries, driven by a structured ambiguity taxonomy and candidate disagreements, to produce disambiguation evidence for final SQL selection and repair. This active approach to ambiguity discovery and resolution generalizes across unseen schemas and query distributions without human-in-the-loop. Experiments on six public benchmarks demonstrate that SOMA-SQL improves execution accuracy by 13.0% on average over state-of-the-art baselines, with gains of up to 16.7% on ambiguous questions.
DreamPRM: Domain-Reweighted Process Reward Model for Multimodal Reasoning
May 26, 2025Reasoning has substantially improved the performance of large language models (LLMs) on complicated tasks. Central to the current reasoning studies, Process Reward Models (PRMs) offer a fine-grained evaluation of intermediate reasoning steps and guide the reasoning process. However, extending PRMs to multimodal large language models (MLLMs) introduces challenges. Since multimodal reasoning covers a wider range of tasks compared to text-only scenarios, the resulting distribution shift from the training to testing sets is more severe, leading to greater generalization difficulty. Training a reliable multimodal PRM, therefore, demands large and diverse datasets to ensure sufficient coverage. However, current multimodal reasoning datasets suffer from a marked quality imbalance, which degrades PRM performance and highlights the need for an effective data selection strategy. To address the issues, we introduce DreamPRM, a domain-reweighted training framework for multimodal PRMs which employs bi-level optimization. In the lower-level optimization, DreamPRM performs fine-tuning on multiple datasets with domain weights, allowing the PRM to prioritize high-quality reasoning signals and alleviating the impact of dataset quality imbalance. In the upper-level optimization, the PRM is evaluated on a separate meta-learning dataset; this feedback updates the domain weights through an aggregation loss function, thereby improving the generalization capability of trained PRM. Extensive experiments on multiple multimodal reasoning benchmarks covering both mathematical and general reasoning show that test-time scaling with DreamPRM consistently improves the performance of state-of-the-art MLLMs. Further comparisons reveal that DreamPRM's domain-reweighting strategy surpasses other data selection methods and yields higher accuracy gains than existing test-time scaling approaches.
Improving the Language Understanding Capabilities of Large Language Models Using Reinforcement Learning
Oct 14, 2024Large language models (LLMs), built on decoder-only transformers, excel in natural language generation and adapt to diverse tasks using zero-shot and few-shot prompting. However, these prompting methods often struggle on natural language understanding (NLU) tasks, where encoder-only models like BERT-base outperform LLMs on benchmarks like GLUE and SuperGLUE. This paper explores two approaches-supervised fine-tuning (SFT) and proximal policy optimization (PPO)-to enhance LLMs' NLU abilities. To reduce the cost of full-model fine-tuning, we integrate low-rank adaptation (LoRA) layers, limiting updates to these layers during both SFT and PPO. In SFT, task-specific prompts are concatenated with input queries and ground-truth labels, optimizing with next-token prediction. Despite this, LLMs still underperform compared to models like BERT-base on several NLU tasks. To close this gap, we apply PPO, a reinforcement learning technique that treats each token generation as an action and uses a reward function based on alignment with ground-truth answers. PPO then updates the model to maximize these rewards, aligning outputs with correct labels. Our experiments with LLAMA2-7B show that PPO improves performance, with a 6.3-point gain over SFT on GLUE. PPO exceeds zero-shot by 38.7 points and few-shot by 26.1 points on GLUE, while surpassing these by 28.8 and 28.5 points on SuperGLUE. Additionally, PPO outperforms BERT-large by 2.7 points on GLUE and 9.3 points on SuperGLUE. The improvements are consistent across models like Qwen2.5-7B and MPT-7B, highlighting PPO's robustness in enhancing LLMs' NLU capabilities.
TapWeight: Reweighting Pretraining Objectives for Task-Adaptive Pretraining
Oct 13, 2024



Large-scale general domain pretraining followed by downstream-specific finetuning has become a predominant paradigm in machine learning. However, discrepancies between the pretraining and target domains can still lead to performance degradation in certain cases, underscoring the need for task-adaptive continued pretraining (TAP). TAP methods typically involve continued pretraining on task-specific unlabeled datasets or introducing additional unsupervised learning objectives to enhance model capabilities. While many TAP methods perform continued pretraining with multiple pretraining objectives, they often determine the tradeoff parameters between objectives manually, resulting in suboptimal outcomes and higher computational costs. In this paper, we propose TapWeight, a task-adaptive pretraining framework which automatically determines the optimal importance of each pretraining objective based on downstream feedback. TapWeight reweights each pretraining objective by solving a multi-level optimization problem. We applied TapWeight to both molecular property prediction and natural language understanding tasks, significantly surpassing baseline methods. Experimental results validate the effectiveness and generalizability of TapWeight.
Generalizable and Stable Finetuning of Pretrained Language Models on Low-Resource Texts
Mar 19, 2024Pretrained Language Models (PLMs) have advanced Natural Language Processing (NLP) tasks significantly, but finetuning PLMs on low-resource datasets poses significant challenges such as instability and overfitting. Previous methods tackle these issues by finetuning a strategically chosen subnetwork on a downstream task, while keeping the remaining weights fixed to the pretrained weights. However, they rely on a suboptimal criteria for sub-network selection, leading to suboptimal solutions. To address these limitations, we propose a regularization method based on attention-guided weight mixup for finetuning PLMs. Our approach represents each network weight as a mixup of task-specific weight and pretrained weight, controlled by a learnable attention parameter, providing finer control over sub-network selection. Furthermore, we employ a bi-level optimization (BLO) based framework on two separate splits of the training dataset, improving generalization and combating overfitting. We validate the efficacy of our proposed method through extensive experiments, demonstrating its superiority over previous methods, particularly in the context of finetuning PLMs on low-resource datasets.
AutoLoRA: Automatically Tuning Matrix Ranks in Low-Rank Adaptation Based on Meta Learning
Mar 17, 2024



Large-scale pretraining followed by task-specific finetuning has achieved great success in various NLP tasks. Since finetuning all parameters of large pretrained models poses substantial computational and memory challenges, several efficient finetuning methods have been developed. Among them, low-rank adaptation (LoRA), which finetunes low-rank incremental update matrices on top of frozen pretrained weights, has proven particularly effective. Nonetheless, LoRA's uniform rank assignment across all layers, along with its reliance on an exhaustive search to find the best rank, leads to high computation costs and suboptimal finetuning performance. To address these limitations, we introduce AutoLoRA, a meta learning based framework for automatically identifying the optimal rank of each LoRA layer. AutoLoRA associates each rank-1 matrix in a low-rank update matrix with a selection variable, which determines whether the rank-1 matrix should be discarded. A meta learning based method is developed to learn these selection variables. The optimal rank is determined by thresholding the values of these variables. Our comprehensive experiments on natural language understanding, generation, and sequence labeling demonstrate the effectiveness of AutoLoRA.
Token-Specific Watermarking with Enhanced Detectability and Semantic Coherence for Large Language Models
Mar 07, 2024



Large language models generate high-quality responses with potential misinformation, underscoring the need for regulation by distinguishing AI-generated and human-written texts. Watermarking is pivotal in this context, which involves embedding hidden markers in texts during the LLM inference phase, which is imperceptible to humans. Current watermarking algorithms, however, face the challenge of achieving both the detectability of inserted watermarks and the semantic integrity of generated texts, where enhancing one aspect often undermines the other. To overcome this, we introduce a novel multi-objective optimization (MOO) approach for watermarking that utilizes lightweight networks to generate token-specific watermarking logits and splitting ratios. By leveraging MOO to optimize for both detection and semantic objective functions, our method simultaneously achieves detectability and semantic integrity. Experimental results show that our method outperforms current watermarking techniques in enhancing the detectability of texts generated by LLMs while maintaining their semantic coherence. Our code is available at https://github.com/mignonjia/TS_watermark.
Downstream Task Guided Masking Learning in Masked Autoencoders Using Multi-Level Optimization
Feb 28, 2024



Masked Autoencoder (MAE) is a notable method for self-supervised pretraining in visual representation learning. It operates by randomly masking image patches and reconstructing these masked patches using the unmasked ones. A key limitation of MAE lies in its disregard for the varying informativeness of different patches, as it uniformly selects patches to mask. To overcome this, some approaches propose masking based on patch informativeness. However, these methods often do not consider the specific requirements of downstream tasks, potentially leading to suboptimal representations for these tasks. In response, we introduce the Multi-level Optimized Mask Autoencoder (MLO-MAE), a novel framework that leverages end-to-end feedback from downstream tasks to learn an optimal masking strategy during pretraining. Our experimental findings highlight MLO-MAE's significant advancements in visual representation learning. Compared to existing methods, it demonstrates remarkable improvements across diverse datasets and tasks, showcasing its adaptability and efficiency. Our code is available at: https://github.com/Alexiland/MLOMAE
Improving Differentiable Architecture Search with a Generative Model
Nov 30, 2021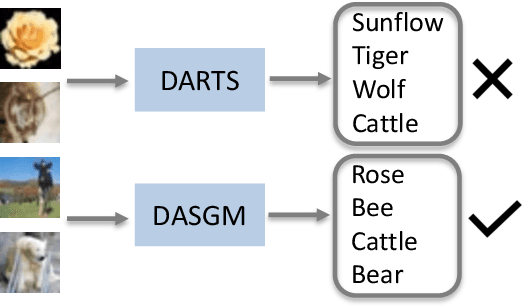


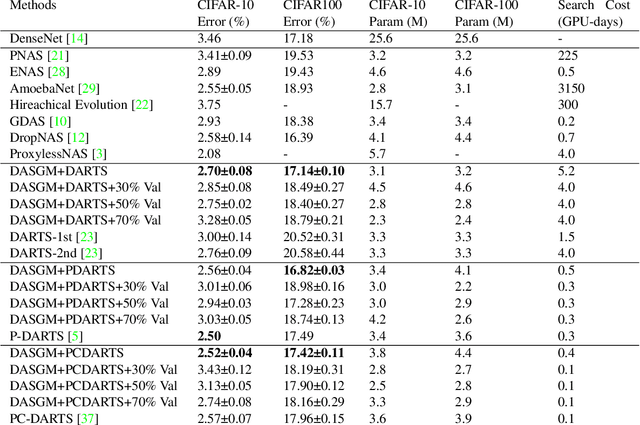
In differentiable neural architecture search (NAS) algorithms like DARTS, the training set used to update model weight and the validation set used to update model architectures are sampled from the same data distribution. Thus, the uncommon features in the dataset fail to receive enough attention during training. In this paper, instead of introducing more complex NAS algorithms, we explore the idea that adding quality synthesized datasets into training can help the classification model identify its weakness and improve recognition accuracy. We introduce a training strategy called ``Differentiable Architecture Search with a Generative Model(DASGM)." In DASGM, the training set is used to update the classification model weight, while a synthesized dataset is used to train its architecture. The generated images have different distributions from the training set, which can help the classification model learn better features to identify its weakness. We formulate DASGM into a multi-level optimization framework and develop an effective algorithm to solve it. Experiments on CIFAR-10, CIFAR-100, and ImageNet have demonstrated the effectiveness of DASGM. Code will be made available.