 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Contrastive Pre-Training for Efficient Video-Text Retrieval
Dec 05, 2022



We present a simple yet effective end-to-end Video-language Pre-training (VidLP) framework, Masked Contrastive Video-language Pretraining (MAC), for video-text retrieval tasks. Our MAC aims to reduce video representation's spatial and temporal redundancy in the VidLP model by a mask sampling mechanism to improve pre-training efficiency. Comparing conventional temporal sparse sampling, we propose to randomly mask a high ratio of spatial regions and only feed visible regions into the encoder as sparse spatial sampling. Similarly, we adopt the mask sampling technique for text inputs for consistency. Instead of blindly applying the mask-then-prediction paradigm from MAE, we propose a masked-then-alignment paradigm for efficient video-text alignment. The motivation is that video-text retrieval tasks rely on high-level alignment rather than low-level reconstruction, and multimodal alignment with masked modeling encourages the model to learn a robust and general multimodal representation from incomplete and unstable inputs. Coupling these designs enables efficient end-to-end pre-training: reduce FLOPs (60% off), accelerate pre-training (by 3x), and improve performance. Our MAC achieves state-of-the-art results on various video-text retrieval datasets, including MSR-VTT, DiDeMo, and ActivityNet. Our approach is omnivorous to input modalities. With minimal modifications, we achieve competitive results on image-text retrieval tasks.
Exploring Stochastic Autoregressive Image Modeling for Visual Representation
Dec 03, 2022



Autoregressive language modeling (ALM) have been successfully used in self-supervised pre-training in Natural language processing (NLP). However, this paradigm has not achieved comparable results with other self-supervised approach in computer vision (e.g., contrastive learning, mask image modeling). In this paper, we try to find the reason why autoregressive modeling does not work well on vision tasks. To tackle this problem, we fully analyze the limitation of visual autoregressive methods and proposed a novel stochastic autoregressive image modeling (named SAIM) by the two simple designs. First, we employ stochastic permutation strategy to generate effective and robust image context which is critical for vision tasks. Second, we create a parallel encoder-decoder training process in which the encoder serves a similar role to the standard vision transformer focus on learning the whole contextual information, and meanwhile the decoder predicts the content of the current position, so that the encoder and decoder can reinforce each other. By introducing stochastic prediction and the parallel encoder-decoder, SAIM significantly improve the performance of autoregressive image modeling. Our method achieves the best accuracy (83.9%) on the vanilla ViT-Base model among methods using only ImageNet-1K data. Transfer performance in downstream tasks also show that our model achieves competitive performance.
Obj2Seq: Formatting Objects as Sequences with Class Prompt for Visual Tasks
Sep 28, 2022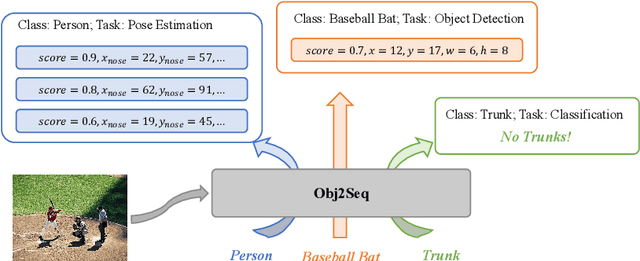
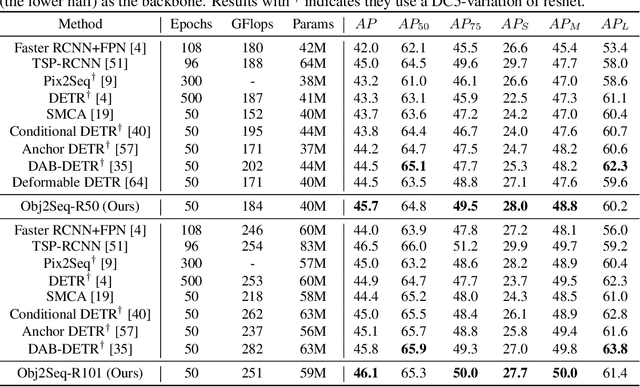
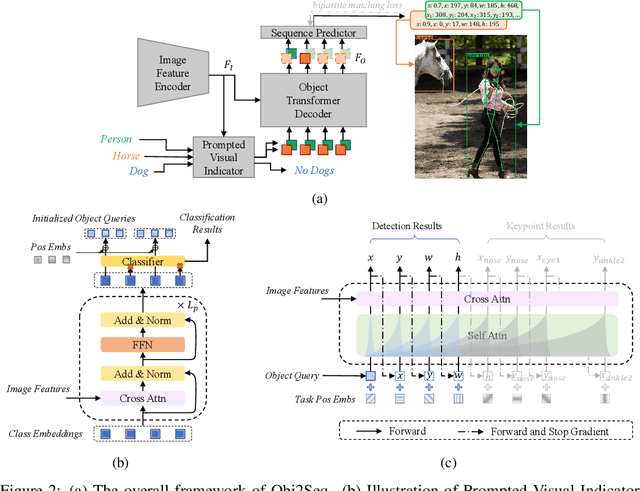
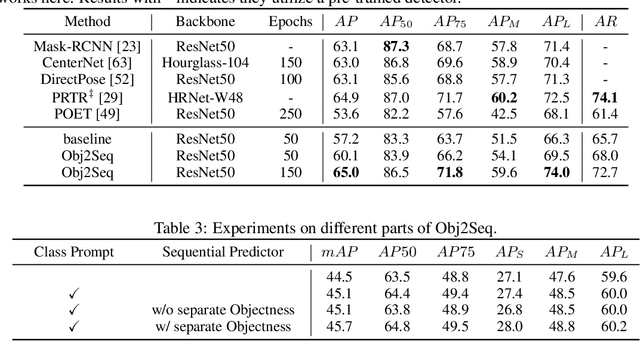
Visual tasks vary a lot in their output formats and concerned contents, therefore it is hard to process them with an identical structure. One main obstacle lies in the high-dimensional outputs in object-level visual tasks. In this paper, we propose an object-centric vision framework, Obj2Seq. Obj2Seq takes objects as basic units, and regards most object-level visual tasks as sequence generation problems of objects. Therefore, these visual tasks can be decoupled into two steps. First recognize objects of given categories, and then generate a sequence for each of these objects. The definition of the output sequences varies for different tasks, and the model is supervised by matching these sequences with ground-truth targets. Obj2Seq is able to flexibly determine input categories to satisfy customized requirements, and be easily extended to different visual tasks. When experimenting on MS COCO, Obj2Seq achieves 45.7% AP on object detection, 89.0% AP on multi-label classification and 65.0% AP on human pose estimation. These results demonstrate its potential to be generally applied to different visual tasks. Code has been made available at: https://github.com/CASIA-IVA-Lab/Obj2Seq.
UniVIP: A Unified Framework for Self-Supervised Visual Pre-training
Mar 14, 2022Self-supervised learning (SSL) holds promise in leveraging large amounts of unlabeled data. However, the success of popular SSL methods has limited on single-centric-object images like those in ImageNet and ignores the correlation among the scene and instances, as well as the semantic difference of instances in the scene. To address the above problems, we propose a Unified Self-supervised Visual Pre-training (UniVIP), a novel self-supervised framework to learn versatile visual representations on either single-centric-object or non-iconic dataset. The framework takes into account the representation learning at three levels: 1) the similarity of scene-scene, 2) the correlation of scene-instance, 3) the discrimination of instance-instance. During the learning, we adopt the optimal transport algorithm to automatically measure the discrimination of instances. Massive experiments show that UniVIP pre-trained on non-iconic COCO achieves state-of-the-art transfer performance on a variety of downstream tasks, such as image classification, semi-supervised learning, object detection and segmentation. Furthermore, our method can also exploit single-centric-object dataset such as ImageNet and outperforms BYOL by 2.5% with the same pre-training epochs in linear probing, and surpass current self-supervised object detection methods on COCO dataset, demonstrating its universality and potential.
Part-Aware Self-Supervised Pre-Training for Person Re-Identification
Mar 08, 2022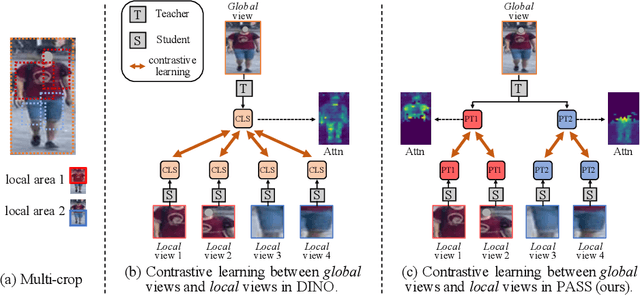
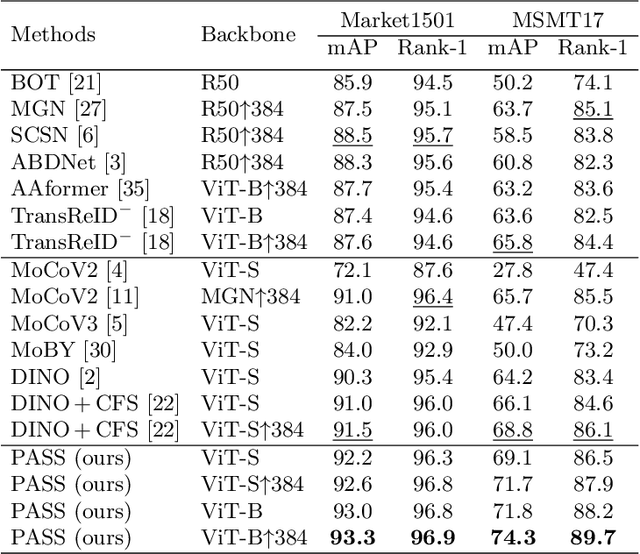
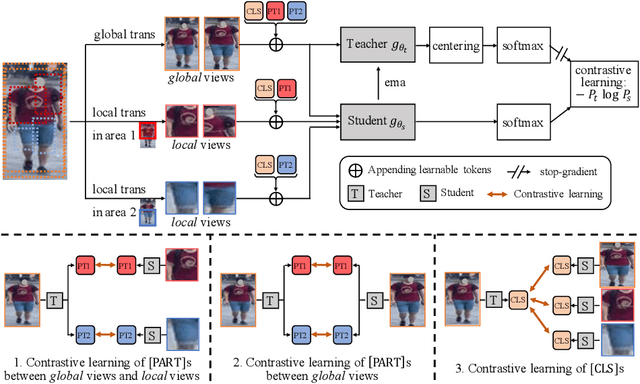
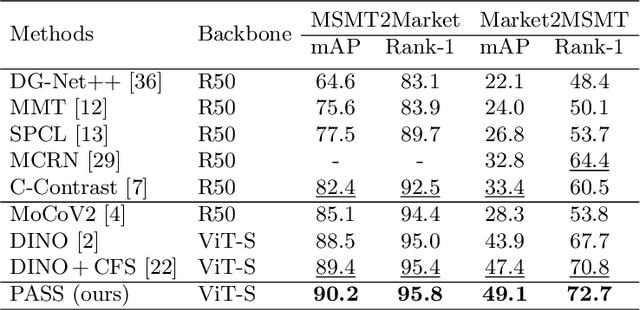
In person re-identification (ReID), very recent researches have validated pre-training the models on unlabelled person images is much better than on ImageNet. However, these researches directly apply the existing self-supervised learning (SSL) methods designed for image classification to ReID without any adaption in the framework. These SSL methods match the outputs of local views (e.g., red T-shirt, blue shorts) to those of the global views at the same time, losing lots of details. In this paper, we propose a ReID-specific pre-training method, Part-Aware Self-Supervised pre-training (PASS), which can generate part-level features to offer fine-grained information and is more suitable for ReID. PASS divides the images into several local areas, and the local views randomly cropped from each area are assigned with a specific learnable [PART] token. On the other hand, the [PART]s of all local areas are also appended to the global views. PASS learns to match the output of the local views and global views on the same [PART]. That is, the learned [PART] of the local views from a local area is only matched with the corresponding [PART] learned from the global views. As a result, each [PART] can focus on a specific local area of the image and extracts fine-grained information of this area. Experiments show PASS sets the new state-of-the-art performances on Market1501 and MSMT17 on various ReID tasks, e.g., vanilla ViT-S/16 pre-trained by PASS achieves 92.2\%/90.2\%/88.5\% mAP accuracy on Market1501 for supervised/UDA/USL ReID. Our codes are available at https://github.com/CASIA-IVA-Lab/PASS-reID.
DPT: Deformable Patch-based Transformer for Visual Recognition
Jul 30, 2021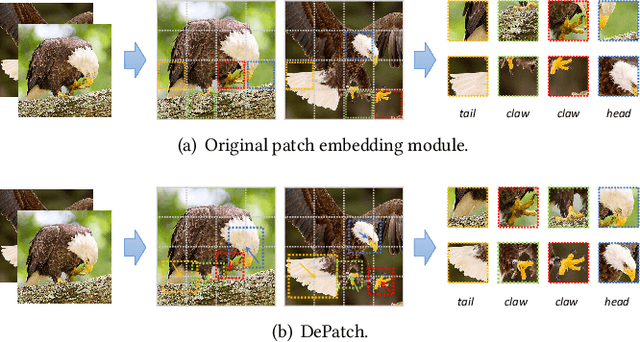
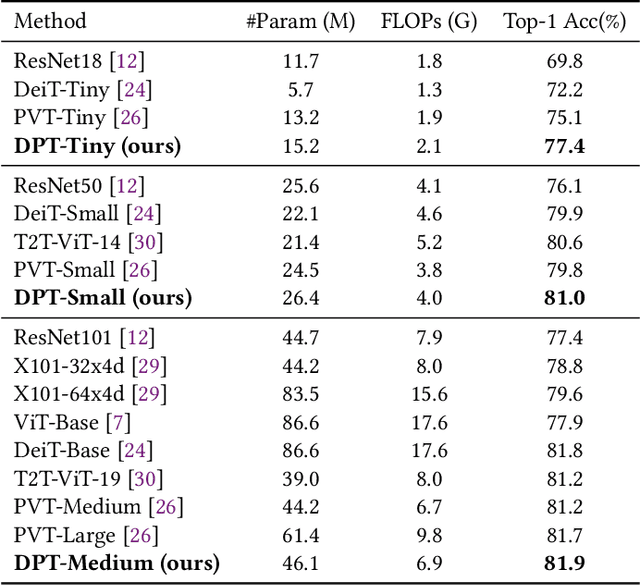
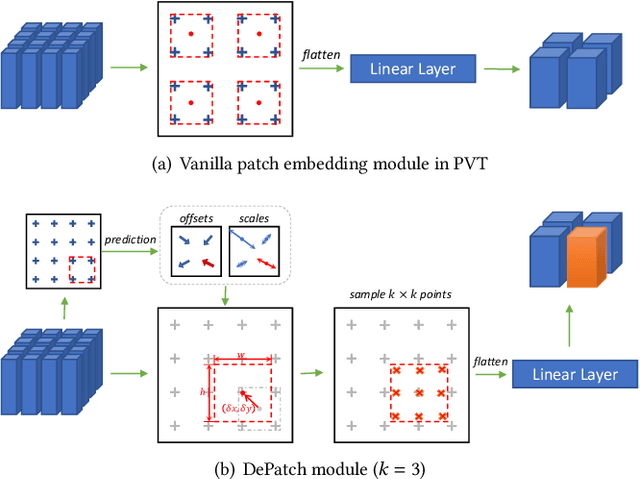
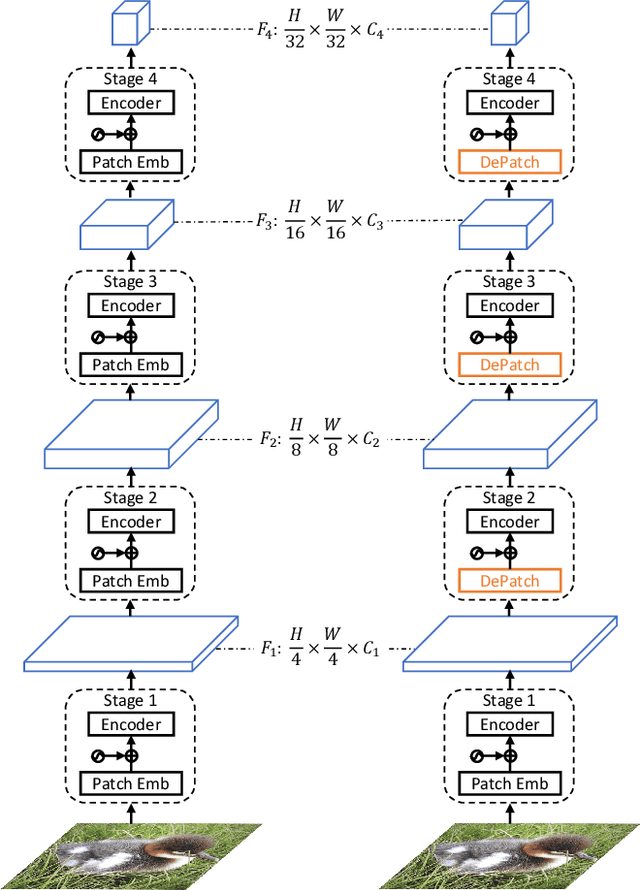
Transformer has achieved great success in computer vision, while how to split patches in an image remains a problem. Existing methods usually use a fixed-size patch embedding which might destroy the semantics of objects. To address this problem, we propose a new Deformable Patch (DePatch) module which learns to adaptively split the images into patches with different positions and scales in a data-driven way rather than using predefined fixed patches. In this way, our method can well preserve the semantics in patches. The DePatch module can work as a plug-and-play module, which can easily be incorporated into different transformers to achieve an end-to-end training. We term this DePatch-embedded transformer as Deformable Patch-based Transformer (DPT) and conduct extensive evaluations of DPT on image classification and object detection. Results show DPT can achieve 81.9% top-1 accuracy on ImageNet classification, and 43.7% box mAP with RetinaNet, 44.3% with Mask R-CNN on MSCOCO object detection. Code has been made available at: https://github.com/CASIA-IVA-Lab/DPT .
MST: Masked Self-Supervised Transformer for Visual Representation
Jun 10, 2021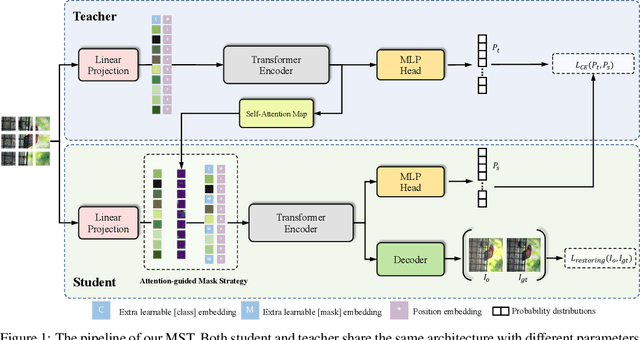
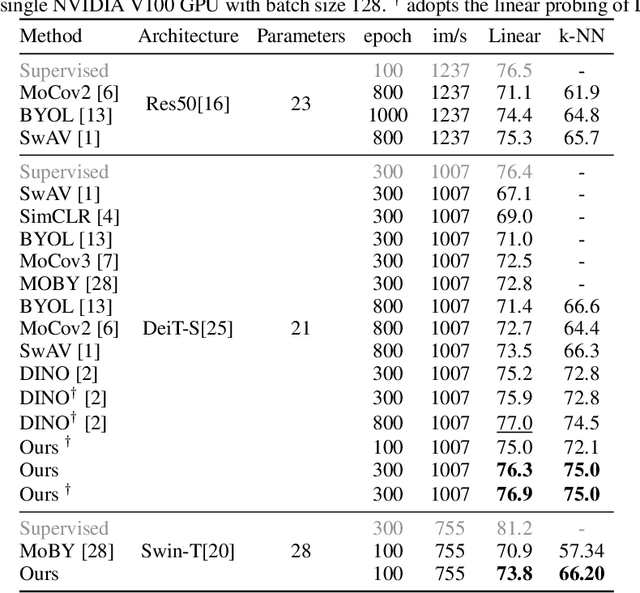

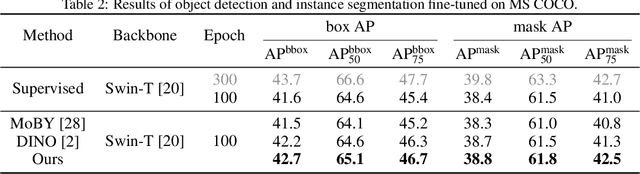
Transformer has been widely used for self-supervised pre-training in Natural Language Processing (NLP) and achieved great success. However, it has not been fully explored in visual self-supervised learning. Meanwhile, previous methods only consider the high-level feature and learning representation from a global perspective, which may fail to transfer to the downstream dense prediction tasks focusing on local features. In this paper, we present a novel Masked Self-supervised Transformer approach named MST, which can explicitly capture the local context of an image while preserving the global semantic information. Specifically, inspired by the Masked Language Modeling (MLM) in NLP, we propose a masked token strategy based on the multi-head self-attention map, which dynamically masks some tokens of local patches without damaging the crucial structure for self-supervised learning. More importantly, the masked tokens together with the remaining tokens are further recovered by a global image decoder, which preserves the spatial information of the image and is more friendly to the downstream dense prediction tasks. The experiments on multiple datasets demonstrate the effectiveness and generality of the proposed method. For instance, MST achieves Top-1 accuracy of 76.9% with DeiT-S only using 300-epoch pre-training by linear evaluation, which outperforms supervised methods with the same epoch by 0.4% and its comparable variant DINO by 1.0\%. For dense prediction tasks, MST also achieves 42.7% mAP on MS COCO object detection and 74.04% mIoU on Cityscapes segmentation only with 100-epoch pre-training.
Adaptive Class Suppression Loss for Long-Tail Object Detection
Apr 02, 2021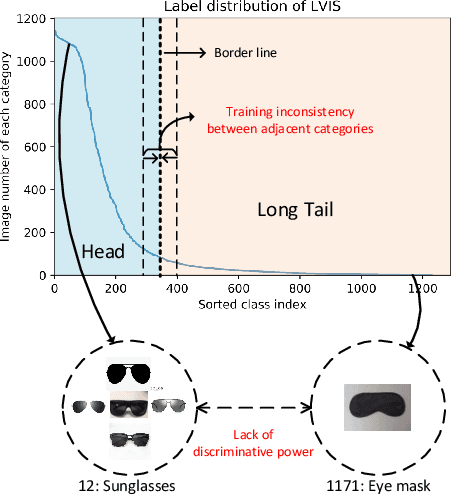
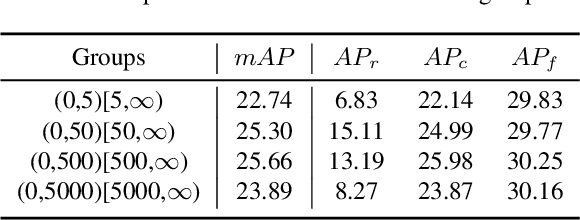
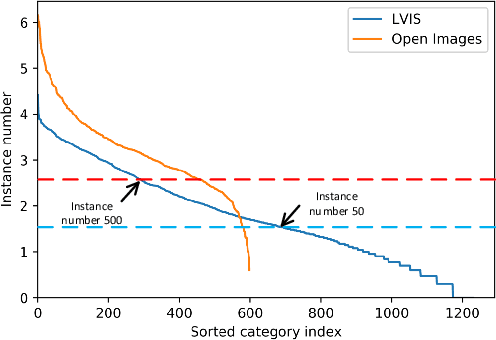
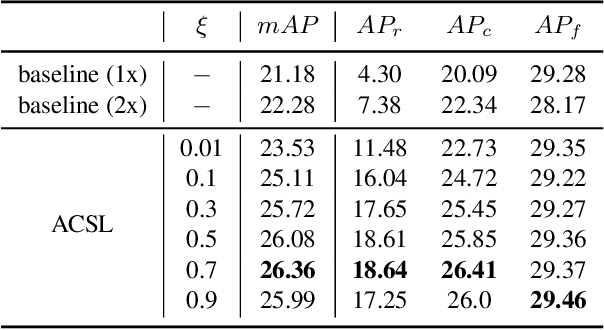
To address the problem of long-tail distribution for the large vocabulary object detection task, existing methods usually divide the whole categories into several groups and treat each group with different strategies. These methods bring the following two problems. One is the training inconsistency between adjacent categories of similar sizes, and the other is that the learned model is lack of discrimination for tail categories which are semantically similar to some of the head categories. In this paper, we devise a novel Adaptive Class Suppression Loss (ACSL) to effectively tackle the above problems and improve the detection performance of tail categories. Specifically, we introduce a statistic-free perspective to analyze the long-tail distribution, breaking the limitation of manual grouping. According to this perspective, our ACSL adjusts the suppression gradients for each sample of each class adaptively, ensuring the training consistency and boosting the discrimination for rare categories. Extensive experiments on long-tail datasets LVIS and Open Images show that the our ACSL achieves 5.18% and 5.2% improvements with ResNet50-FPN, and sets a new state of the art. Code and models are available at https://github.com/CASIA-IVA-Lab/ACSL.
Cross-Dataset Collaborative Learning for Semantic Segmentation
Mar 21, 2021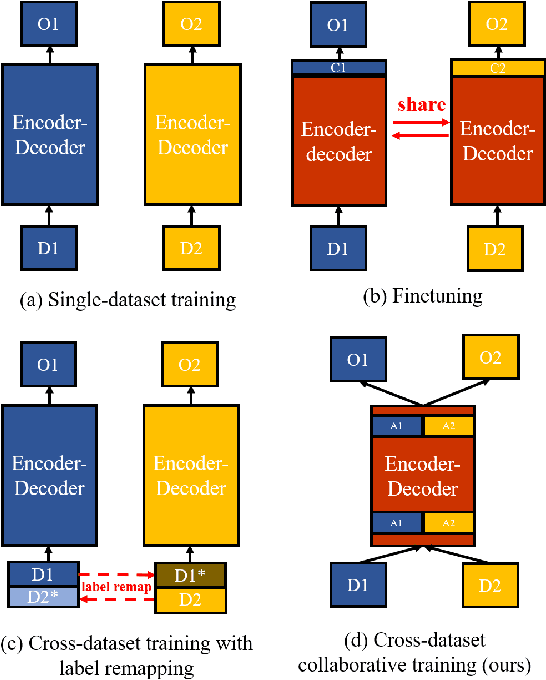
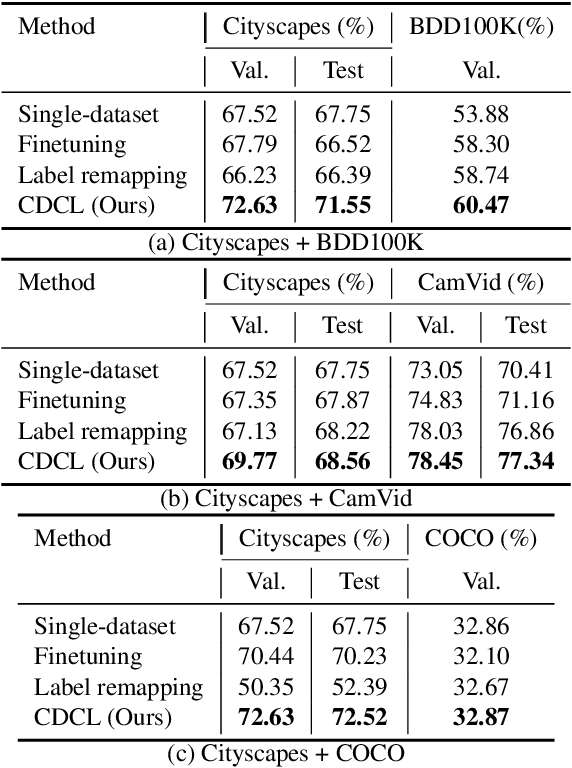
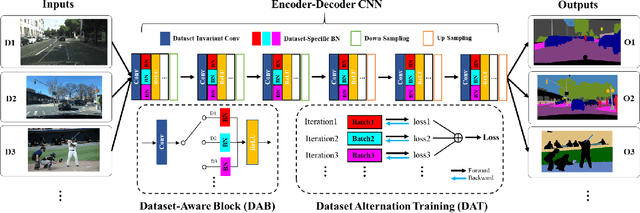

Recent work attempts to improve semantic segmentation performance by exploring well-designed architectures on a target dataset. However, it remains challenging to build a unified system that simultaneously learns from various datasets due to the inherent distribution shift across different datasets. In this paper, we present a simple, flexible, and general method for semantic segmentation, termed Cross-Dataset Collaborative Learning (CDCL). Given multiple labeled datasets, we aim to improve the generalization and discrimination of feature representations on each dataset. Specifically, we first introduce a family of Dataset-Aware Blocks (DAB) as the fundamental computing units of the network, which help capture homogeneous representations and heterogeneous statistics across different datasets. Second, we propose a Dataset Alternation Training (DAT) mechanism to efficiently facilitate the optimization procedure. We conduct extensive evaluations on four diverse datasets, i.e., Cityscapes, BDD100K, CamVid, and COCO Stuff, with single-dataset and cross-dataset settings. Experimental results demonstrate our method consistently achieves notable improvements over prior single-dataset and cross-dataset training methods without introducing extra FLOPs. Particularly, with the same architecture of PSPNet (ResNet-18), our method outperforms the single-dataset baseline by 5.65\%, 6.57\%, and 5.79\% of mIoU on the validation sets of Cityscapes, BDD100K, CamVid, respectively. Code and models will be released.
CoupleNet: Coupling Global Structure with Local Parts for Object Detection
Aug 09, 2017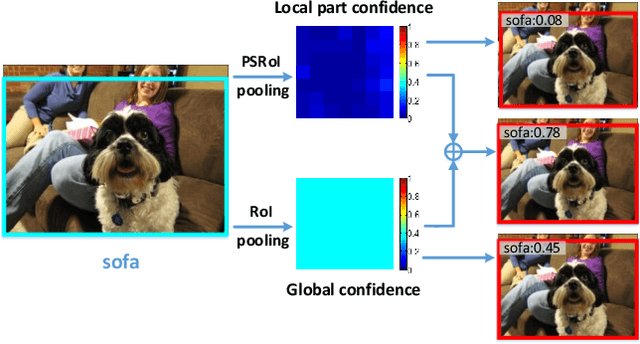

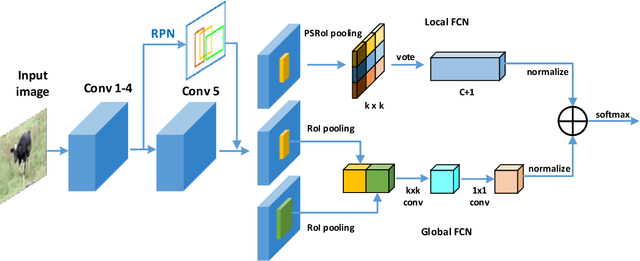
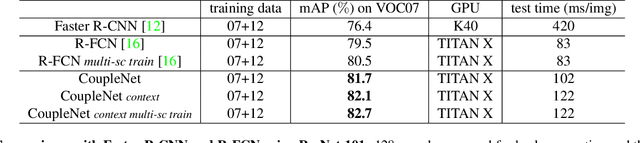
The region-based Convolutional Neural Network (CNN) detectors such as Faster R-CNN or R-FCN have already shown promising results for object detection by combining the region proposal subnetwork and the classification subnetwork together. Although R-FCN has achieved higher detection speed while keeping the detection performance, the global structure information is ignored by the position-sensitive score maps. To fully explore the local and global properties, in this paper, we propose a novel fully convolutional network, named as CoupleNet, to couple the global structure with local parts for object detection. Specifically, the object proposals obtained by the Region Proposal Network (RPN) are fed into the the coupling module which consists of two branches. One branch adopts the position-sensitive RoI (PSRoI) pooling to capture the local part information of the object, while the other employs the RoI pooling to encode the global and context information. Next, we design different coupling strategies and normalization ways to make full use of the complementary advantages between the global and local branches. Extensive experiments demonstrate the effectiveness of our approach. We achieve state-of-the-art results on all three challenging datasets, i.e. a mAP of 82.7% on VOC07, 80.4% on VOC12, and 34.4% on COCO. Codes will be made publicly available.