 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Generative Autoencoders
Jun 25, 2019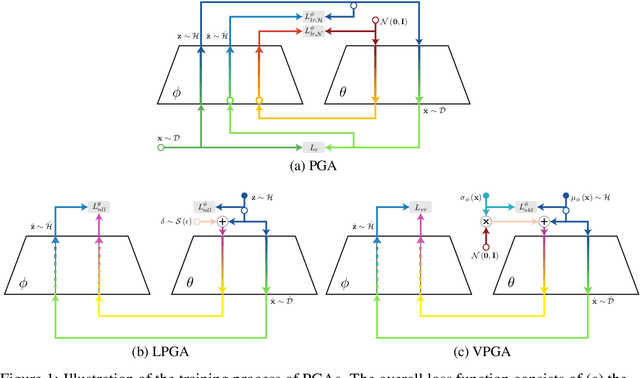
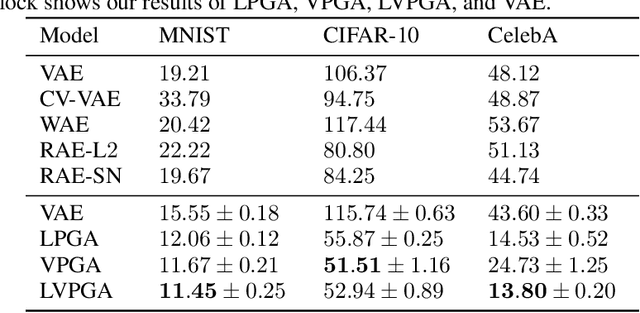


Modern generative models are usually designed to match target distributions directly in the data space, where the intrinsic dimensionality of data can be much lower than the ambient dimensionality. We argue that this discrepancy may contribute to the difficulties in training generative models. We therefore propose to map both the generated and target distributions to the latent space using the encoder of a standard autoencoder, and train the generator (or decoder) to match the target distribution in the latent space. The resulting method, perceptual generative autoencoder (PGA), is then incorporated with a maximum likelihood or variational autoencoder (VAE) objective to train the generative model. With maximum likelihood, PGAs generalize the idea of reversible generative models to unrestricted neural network architectures and arbitrary latent dimensionalities. When combined with VAEs, PGAs can generate sharper samples than vanilla VAEs. Compared to other autoencoder-based generative models using simple priors, PGAs achieve state-of-the-art FID scores on CIFAR-10 and CelebA.
Information matrices and generalization
Jun 18, 2019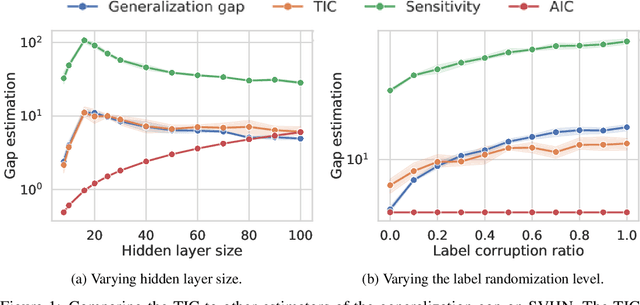
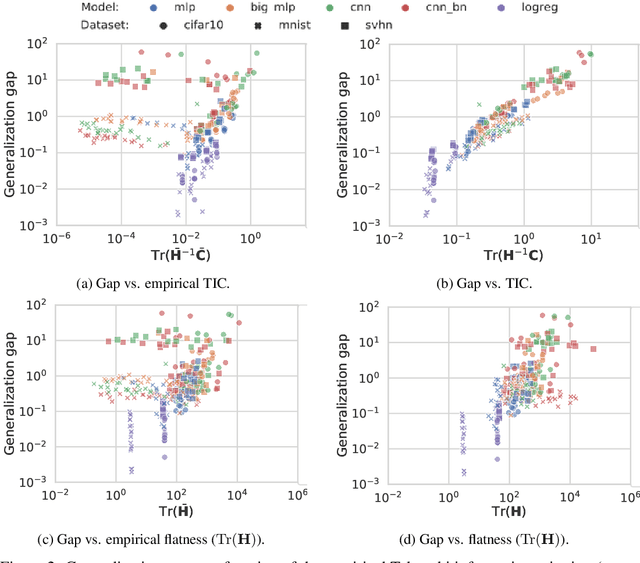
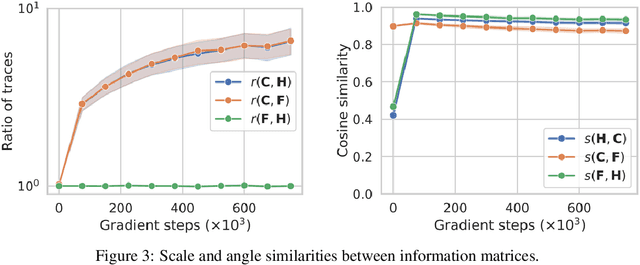
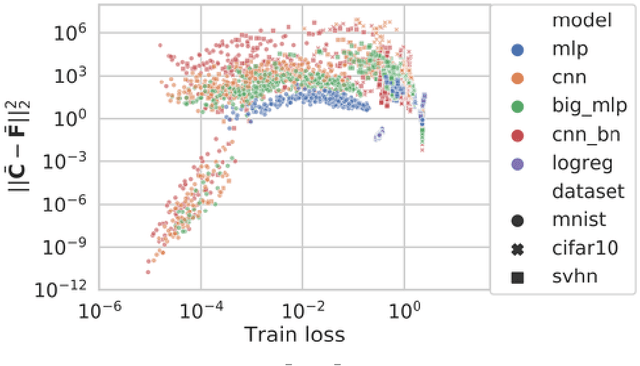
This work revisits the use of information criteria to characterize the generalization of deep learning models. In particular, we empirically demonstrate the effectiveness of the Takeuchi information criterion (TIC), an extension of the Akaike information criterion (AIC) for misspecified models, in estimating the generalization gap, shedding light on why quantities such as the number of parameters cannot quantify generalization. The TIC depends on both the Hessian of the loss H and the covariance of the gradients C. By exploring the similarities and differences between these two matrices as well as the Fisher information matrix F, we study the interplay between noise and curvature in deep models. We also address the question of whether C is a reasonable approximation to F, as is commonly assumed.
Conditional Computation for Continual Learning
Jun 16, 2019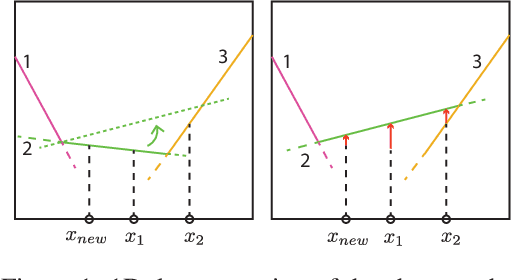
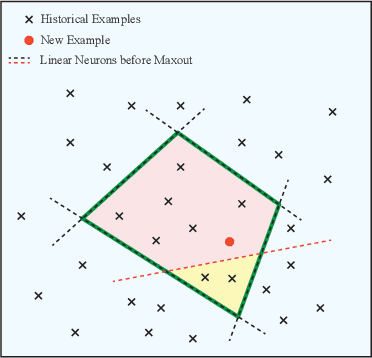
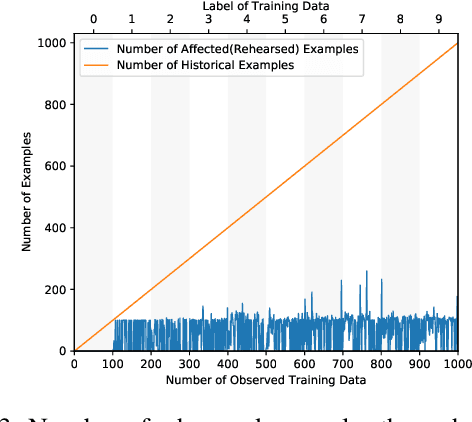
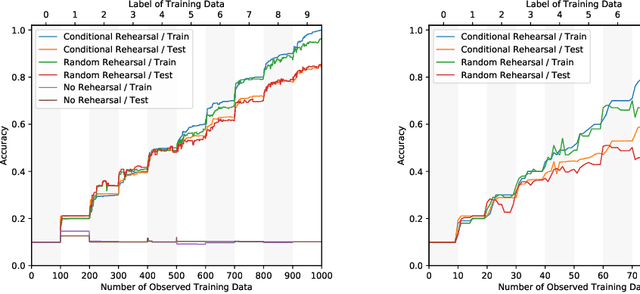
Catastrophic forgetting of connectionist neural networks is caused by the global sharing of parameters among all training examples. In this study, we analyze parameter sharing under the conditional computation framework where the parameters of a neural network are conditioned on each input example. At one extreme, if each input example uses a disjoint set of parameters, there is no sharing of parameters thus no catastrophic forgetting. At the other extreme, if the parameters are the same for every example, it reduces to the conventional neural network. We then introduce a clipped version of maxout networks which lies in the middle, i.e. parameters are shared partially among examples. Based on the parameter sharing analysis, we can locate a limited set of examples that are interfered when learning a new example. We propose to perform rehearsal on this set to prevent forgetting, which is termed as conditional rehearsal. Finally, we demonstrate the effectiveness of the proposed method in an online non-stationary setup, where updates are made after each new example and the distribution of the received example shifts over time.
Learning Powerful Policies by Using Consistent Dynamics Model
Jun 11, 2019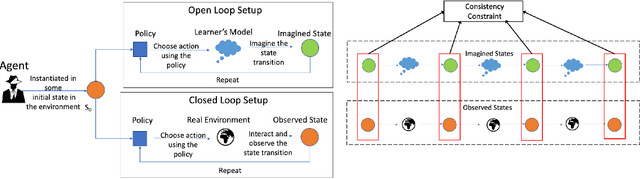
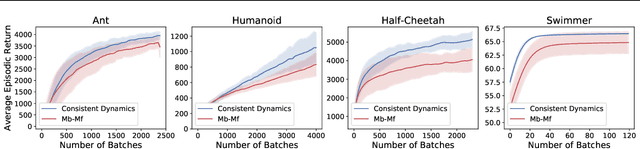
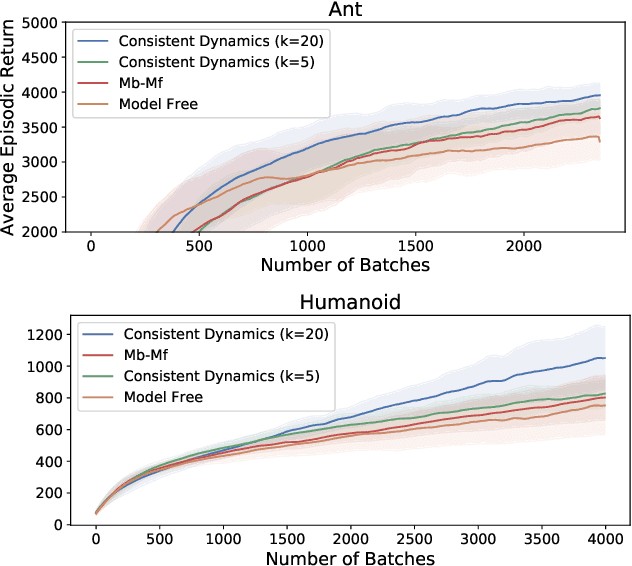
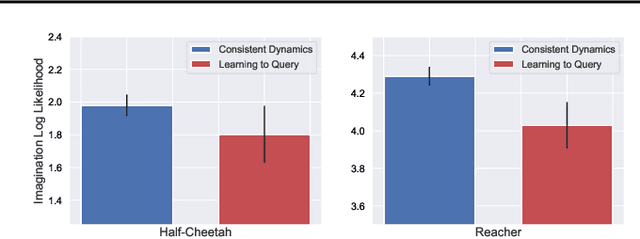
Model-based Reinforcement Learning approaches have the promise of being sample efficient. Much of the progress in learning dynamics models in RL has been made by learning models via supervised learning. But traditional model-based approaches lead to `compounding errors' when the model is unrolled step by step. Essentially, the state transitions that the learner predicts (by unrolling the model for multiple steps) and the state transitions that the learner experiences (by acting in the environment) may not be consistent. There is enough evidence that humans build a model of the environment, not only by observing the environment but also by interacting with the environment. Interaction with the environment allows humans to carry out experiments: taking actions that help uncover true causal relationships which can be used for building better dynamics models. Analogously, we would expect such interactions to be helpful for a learning agent while learning to model the environment dynamics. In this paper, we build upon this intuition by using an auxiliary cost function to ensure consistency between what the agent observes (by acting in the real world) and what it imagines (by acting in the `learned' world). We consider several tasks - Mujoco based control tasks and Atari games - and show that the proposed approach helps to train powerful policies and better dynamics models.
Tackling Climate Change with Machine Learning
Jun 10, 2019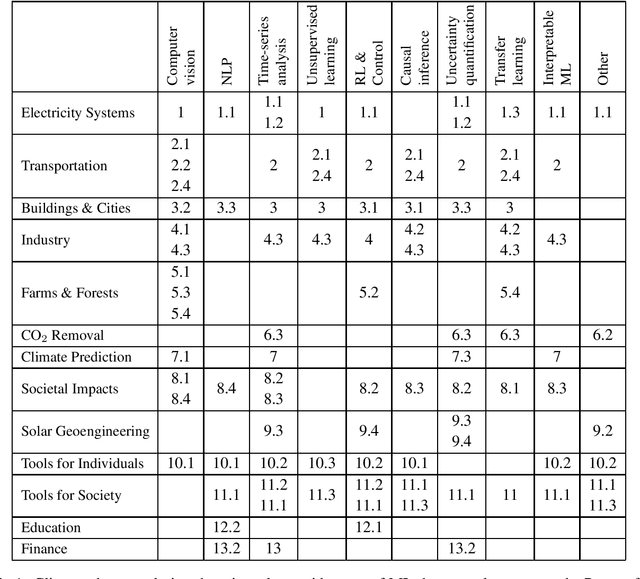
Climate change is one of the greatest challenges facing humanity, and we, as machine learning experts, may wonder how we can help. Here we describe how machine learning can be a powerful tool in reducing greenhouse gas emissions and helping society adapt to a changing climate. From smart grids to disaster management, we identify high impact problems where existing gaps can be filled by machine learning, in collaboration with other fields. Our recommendations encompass exciting research questions as well as promising business opportunities. We call on the machine learning community to join the global effort against climate change.
How to Initialize your Network? Robust Initialization for WeightNorm & ResNets
Jun 05, 2019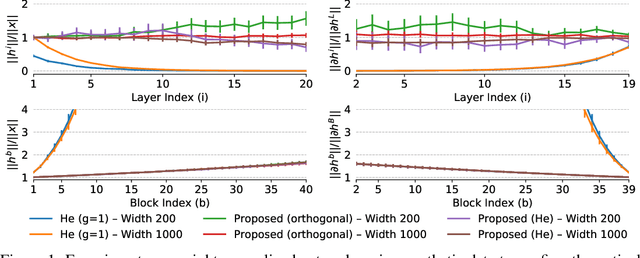
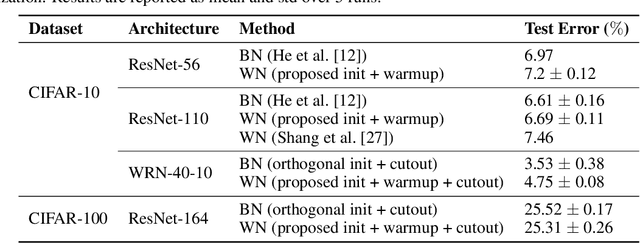
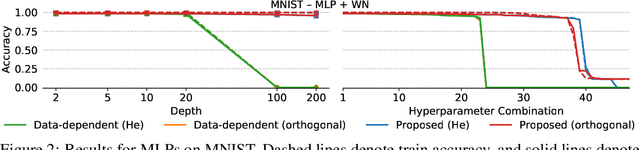

Residual networks (ResNet) and weight normalization play an important role in various deep learning applications. However, parameter initialization strategies have not been studied previously for weight normalized networks and, in practice, initialization methods designed for un-normalized networks are used as a proxy. Similarly, initialization for ResNets have also been studied for un-normalized networks and often under simplified settings ignoring the shortcut connection. To address these issues, we propose a novel parameter initialization strategy that avoids explosion/vanishment of information across layers for weight normalized networks with and without residual connections. The proposed strategy is based on a theoretical analysis using mean field approximation. We run over 2,500 experiments and evaluate our proposal on image datasets showing that the proposed initialization outperforms existing initialization methods in terms of generalization performance, robustness to hyper-parameter values and variance between seeds, especially when networks get deeper in which case existing methods fail to even start training. Finally, we show that using our initialization in conjunction with learning rate warmup is able to reduce the gap between the performance of weight normalized and batch normalized networks.
Do Neural Dialog Systems Use the Conversation History Effectively? An Empirical Study
Jun 04, 2019
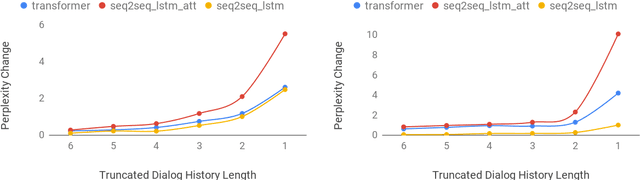
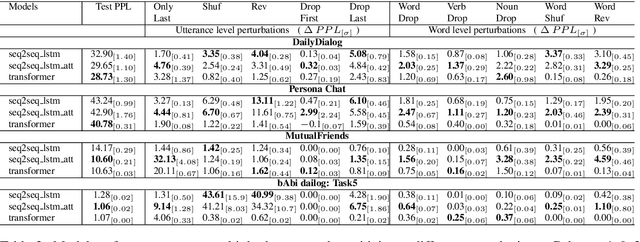
Neural generative models have been become increasingly popular when building conversational agents. They offer flexibility, can be easily adapted to new domains, and require minimal domain engineering. A common criticism of these systems is that they seldom understand or use the available dialog history effectively. In this paper, we take an empirical approach to understanding how these models use the available dialog history by studying the sensitivity of the models to artificially introduced unnatural changes or perturbations to their context at test time. We experiment with 10 different types of perturbations on 4 multi-turn dialog datasets and find that commonly used neural dialog architectures like recurrent and transformer-based seq2seq models are rarely sensitive to most perturbations such as missing or reordering utterances, shuffling words, etc. Also, by open-sourcing our code, we believe that it will serve as a useful diagnostic tool for evaluating dialog systems in the future.
Updates of Equilibrium Prop Match Gradients of Backprop Through Time in an RNN with Static Input
May 31, 2019
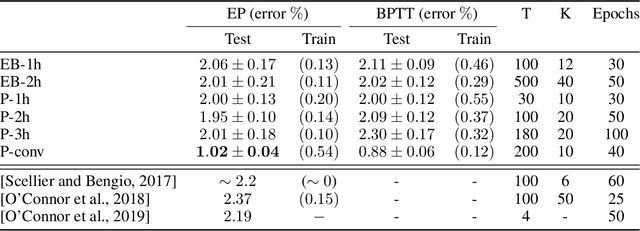
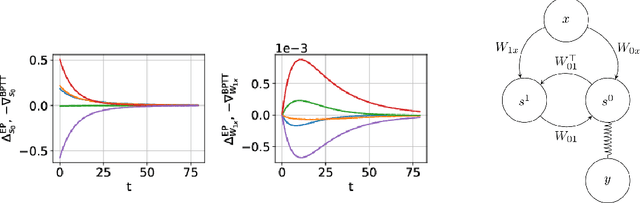
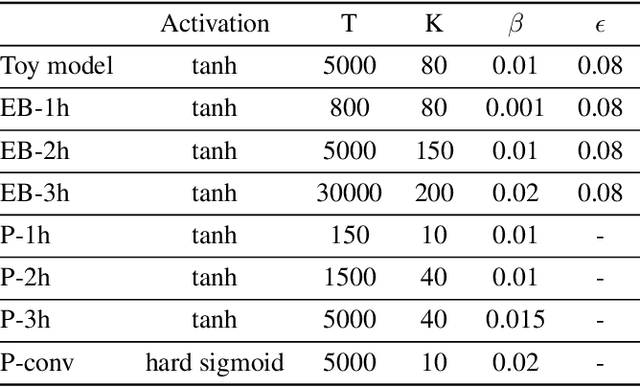
Equilibrium Propagation (EP) is a biologically inspired learning algorithm for convergent recurrent neural networks, i.e. RNNs that are fed by a static input x and settle to a steady state. Training convergent RNNs consists in adjusting the weights until the steady state of output neurons coincides with a target y. Convergent RNNs can also be trained with the more conventional Backpropagation Through Time (BPTT) algorithm. In its original formulation EP was described in the case of real-time neuronal dynamics, which is computationally costly. In this work, we introduce a discrete-time version of EP with simplified equations and with reduced simulation time, bringing EP closer to practical machine learning tasks. We first prove theoretically, as well as numerically that the neural and weight updates of EP, computed by forward-time dynamics, are step-by-step equal to the ones obtained by BPTT, with gradients computed backward in time. The equality is strict when the transition function of the dynamics derives from a primitive function and the steady state is maintained long enough. We then show for more standard discrete-time neural network dynamics that the same property is approximately respected and we subsequently demonstrate training with EP with equivalent performance to BPTT. In particular, we define the first convolutional architecture trained with EP achieving ~ 1% test error on MNIST, which is the lowest error reported with EP. These results can guide the development of deep neural networks trained with EP.
Attention Based Pruning for Shift Networks
May 29, 2019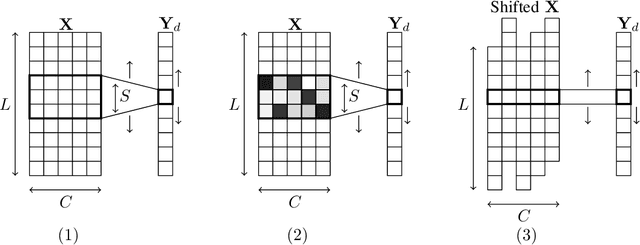
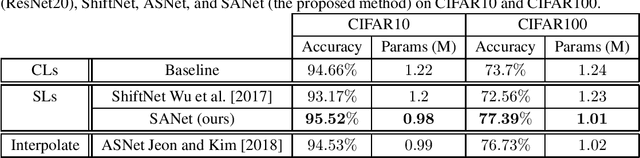
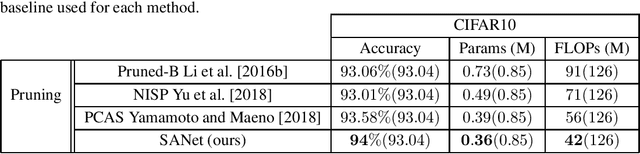
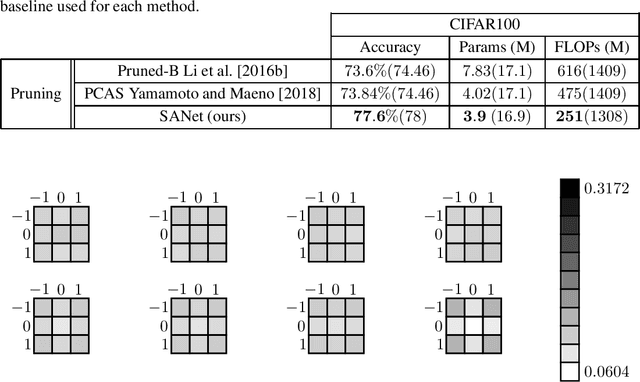
In many application domains such as computer vision, Convolutional Layers (CLs) are key to the accuracy of deep learning methods. However, it is often required to assemble a large number of CLs, each containing thousands of parameters, in order to reach state-of-the-art accuracy, thus resulting in complex and demanding systems that are poorly fitted to resource-limited devices. Recently, methods have been proposed to replace the generic convolution operator by the combination of a shift operation and a simpler 1x1 convolution. The resulting block, called Shift Layer (SL), is an efficient alternative to CLs in the sense it allows to reach similar accuracies on various tasks with faster computations and fewer parameters. In this contribution, we introduce Shift Attention Layers (SALs), which extend SLs by using an attention mechanism that learns which shifts are the best at the same time the network function is trained. We demonstrate SALs are able to outperform vanilla SLs (and CLs) on various object recognition benchmarks while significantly reducing the number of float operations and parameters for the inference.
Non-normal Recurrent Neural Network (nnRNN): learning long time dependencies while improving expressivity with transient dynamics
May 28, 2019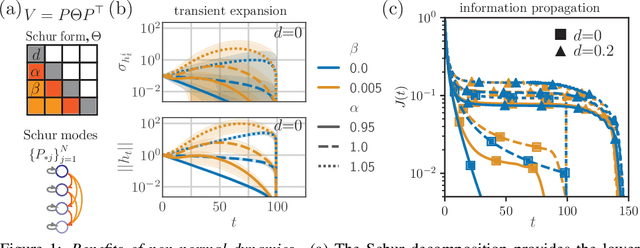

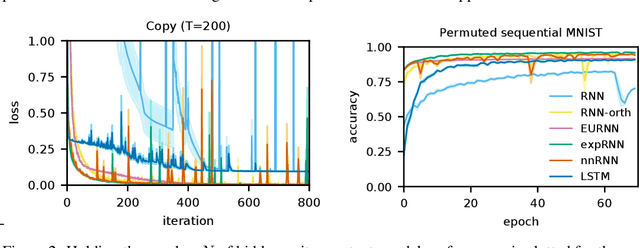
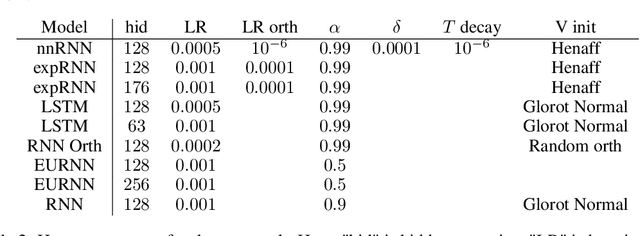
A recent strategy to circumvent the exploding and vanishing gradient problem in RNNs, and to allow the stable propagation of signals over long time scales, is to constrain recurrent connectivity matrices to be orthogonal or unitary. This ensures eigenvalues with unit norm and thus stable dynamics and training. However this comes at the cost of reduced expressivity due to the limited variety of orthogonal transformations. We propose a novel connectivity structure based on the Schur decomposition and a splitting of the Schur form into normal and non-normal parts. This allows to parametrize matrices with unit-norm eigenspectra without orthogonality constraints on eigenbases. The resulting architecture ensures access to a larger space of spectrally constrained matrices, of which orthogonal matrices are a subset. This crucial difference retains the stability advantages and training speed of orthogonal RNNs while enhancing expressivity, especially on tasks that require computations over ongoing input sequences.