 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD5P4: Partition Determinantal Point Process for Diversity in Parallel Discrete Diffusion Decoding
Mar 19, 2026Discrete diffusion models are promising alternatives to autoregressive approaches for text generation, yet their decoding methods remain under-studied. Standard decoding methods for autoregressive models, such as beam search, do not directly apply to iterative denoising, and existing diffusion decoding techniques provide limited control over in-batch diversity. To bridge this gap, we introduce a generalized beam-search framework for discrete diffusion that generates candidates in parallel and supports modular beam-selection objectives. As a diversity-focused instantiation, we propose D5P4, which formulates the selection step as MAP inference over a Determinantal Point Process. Leveraging a scalable greedy solver, D5P4 maintains multi-GPU compatibility and enables an explicit trade-off between model probability and target diversity with near-zero compute overhead. Experiments on free-form generation and question answering demonstrate that D5P4 improves diversity over strong baselines while maintaining competitive generation quality.
Inner Loop Inference for Pretrained Transformers: Unlocking Latent Capabilities Without Training
Feb 16, 2026Deep Learning architectures, and in particular Transformers, are conventionally viewed as a composition of layers. These layers are actually often obtained as the sum of two contributions: a residual path that copies the input and the output of a Transformer block. As a consequence, the inner representations (i.e. the input of these blocks) can be interpreted as iterative refinement of a propagated latent representation. Under this lens, many works suggest that the inner space is shared across layers, meaning that tokens can be decoded at early stages. Mechanistic interpretability even goes further by conjecturing that some layers act as refinement layers. Following this path, we propose inference-time inner looping, which prolongs refinement in pretrained off-the-shelf language models by repeatedly re-applying a selected block range. Across multiple benchmarks, inner looping yields modest but consistent accuracy improvements. Analyses of the resulting latent trajectories suggest more stable state evolution and continued semantic refinement. Overall, our results suggest that additional refinement can be obtained through simple test-time looping, extending computation in frozen pretrained models.
Residual Connections and the Causal Shift: Uncovering a Structural Misalignment in Transformers
Feb 16, 2026Large Language Models (LLMs) are trained with next-token prediction, implemented in autoregressive Transformers via causal masking for parallelism. This creates a subtle misalignment: residual connections tie activations to the current token, while supervision targets the next token, potentially propagating mismatched information if the current token is not the most informative for prediction. In this work, we empirically localize this input-output alignment shift in pretrained LLMs, using decoding trajectories over tied embedding spaces and similarity-based metrics. Our experiments reveal that the hidden token representations switch from input alignment to output alignment deep within the network. Motivated by this observation, we propose a lightweight residual-path mitigation based on residual attenuation, implemented either as a fixed-layer intervention or as a learnable gating mechanism. Experiments on multiple benchmarks show that these strategies alleviate the representation misalignment and yield improvements, providing an efficient and general architectural enhancement for autoregressive Transformers.
LLM meets Vision-Language Models for Zero-Shot One-Class Classification
Apr 02, 2024We consider the problem of zero-shot one-class visual classification. In this setting, only the label of the target class is available, and the goal is to discriminate between positive and negative query samples without requiring any validation example from the target task. We propose a two-step solution that first queries large language models for visually confusing objects and then relies on vision-language pre-trained models (e.g., CLIP) to perform classification. By adapting large-scale vision benchmarks, we demonstrate the ability of the proposed method to outperform adapted off-the-shelf alternatives in this setting. Namely, we propose a realistic benchmark where negative query samples are drawn from the same original dataset as positive ones, including a granularity-controlled version of iNaturalist, where negative samples are at a fixed distance in the taxonomy tree from the positive ones. Our work shows that it is possible to discriminate between a single category and other semantically related ones using only its label
SKILL: Similarity-aware Knowledge distILLation for Speech Self-Supervised Learning
Feb 26, 2024



Self-supervised learning (SSL) has achieved remarkable success across various speech-processing tasks. To enhance its efficiency, previous works often leverage the use of compression techniques. A notable recent attempt is DPHuBERT, which applies joint knowledge distillation (KD) and structured pruning to learn a significantly smaller SSL model. In this paper, we contribute to this research domain by introducing SKILL, a novel method that conducts distillation across groups of layers instead of distilling individual arbitrarily selected layers within the teacher network. The identification of the layers to distill is achieved through a hierarchical clustering procedure applied to layer similarity measures. Extensive experiments demonstrate that our distilled version of WavLM Base+ not only outperforms DPHuBERT but also achieves state-of-the-art results in the 30M parameters model class across several SUPERB tasks.
A Novel Benchmark for Few-Shot Semantic Segmentation in the Era of Foundation Models
Jan 20, 2024



In recent years, the rapid evolution of computer vision has seen the emergence of various vision foundation models, each tailored to specific data types and tasks. While large language models often share a common pretext task, the diversity in vision foundation models arises from their varying training objectives. In this study, we delve into the quest for identifying the most effective vision foundation models for few-shot semantic segmentation, a critical task in computer vision. Specifically, we conduct a comprehensive comparative analysis of four prominent foundation models: DINO V2, Segment Anything, CLIP, Masked AutoEncoders, and a straightforward ResNet50 pre-trained on the COCO dataset. Our investigation focuses on their adaptability to new semantic segmentation tasks, leveraging only a limited number of segmented images. Our experimental findings reveal that DINO V2 consistently outperforms the other considered foundation models across a diverse range of datasets and adaptation methods. This outcome underscores DINO V2's superior capability to adapt to semantic segmentation tasks compared to its counterparts. Furthermore, our observations indicate that various adapter methods exhibit similar performance, emphasizing the paramount importance of selecting a robust feature extractor over the intricacies of the adaptation technique itself. This insight sheds light on the critical role of feature extraction in the context of few-shot semantic segmentation. This research not only contributes valuable insights into the comparative performance of vision foundation models in the realm of few-shot semantic segmentation but also highlights the significance of a robust feature extractor in this domain.
Inferring Latent Class Statistics from Text for Robust Visual Few-Shot Learning
Nov 24, 2023



In the realm of few-shot learning, foundation models like CLIP have proven effective but exhibit limitations in cross-domain robustness especially in few-shot settings. Recent works add text as an extra modality to enhance the performance of these models. Most of these approaches treat text as an auxiliary modality without fully exploring its potential to elucidate the underlying class visual features distribution. In this paper, we present a novel approach that leverages text-derived statistics to predict the mean and covariance of the visual feature distribution for each class. This predictive framework enriches the latent space, yielding more robust and generalizable few-shot learning models. We demonstrate the efficacy of incorporating both mean and covariance statistics in improving few-shot classification performance across various datasets. Our method shows that we can use text to predict the mean and covariance of the distribution offering promising improvements in few-shot learning scenarios.
A Statistical Model for Predicting Generalization in Few-Shot Classification
Dec 13, 2022



The estimation of the generalization error of classifiers often relies on a validation set. Such a set is hardly available in few-shot learning scenarios, a highly disregarded shortcoming in the field. In these scenarios, it is common to rely on features extracted from pre-trained neural networks combined with distance-based classifiers such as nearest class mean. In this work, we introduce a Gaussian model of the feature distribution. By estimating the parameters of this model, we are able to predict the generalization error on new classification tasks with few samples. We observe that accurate distance estimates between class-conditional densities are the key to accurate estimates of the generalization performance. Therefore, we propose an unbiased estimator for these distances and integrate it in our numerical analysis. We show that our approach outperforms alternatives such as the leave-one-out cross-validation strategy in few-shot settings.
Quantization and Deployment of Deep Neural Networks on Microcontrollers
May 27, 2021

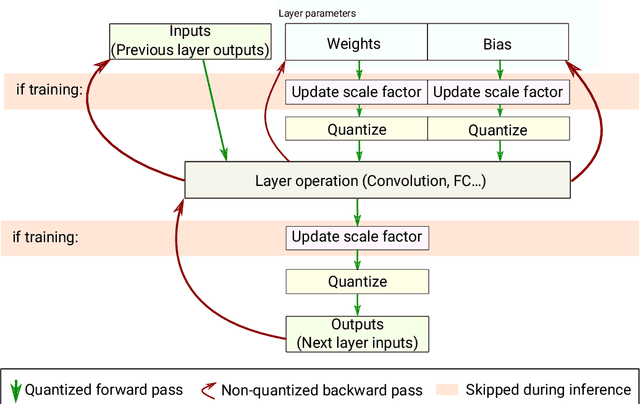
Embedding Artificial Intelligence onto low-power devices is a challenging task that has been partly overcome with recent advances in machine learning and hardware design. Presently, deep neural networks can be deployed on embedded targets to perform different tasks such as speech recognition,object detection or Human Activity Recognition. However, there is still room for optimization of deep neural networks onto embedded devices. These optimizations mainly address power consumption,memory and real-time constraints, but also an easier deployment at the edge. Moreover, there is still a need for a better understanding of what can be achieved for different use cases. This work focuses on quantization and deployment of deep neural networks onto low-power 32-bit microcontrollers. The quantization methods, relevant in the context of an embedded execution onto a microcontroller, are first outlined. Then, a new framework for end-to-end deep neural networks training, quantization and deployment is presented. This framework, called MicroAI, is designed as an alternative to existing inference engines (TensorFlow Lite for Microcontrollers and STM32Cube.AI). Our framework can indeed be easily adjusted and/or extended for specific use cases. Execution using single precision 32-bit floating-point as well as fixed-point on 8- and 16-bit integers are supported. The proposed quantization method is evaluated with three different datasets (UCI-HAR, Spoken MNIST and GTSRB). Finally, a comparison study between MicroAI and both existing embedded inference engines is provided in terms of memory and power efficiency. On-device evaluation is done using ARM Cortex-M4F-based microcontrollers (Ambiq Apollo3 and STM32L452RE).
* 36 pages, 14 figures. Published in MDPI Sensors 2021, special issue "Embedded Artificial Intelligence (AI) for Smart Sensing and IoT Applications": https://www.mdpi.com/1424-8220/21/9/2984
DNN Quantization with Attention
Mar 24, 2021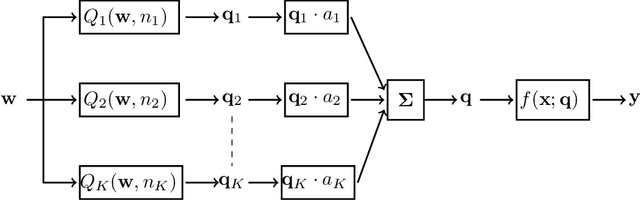
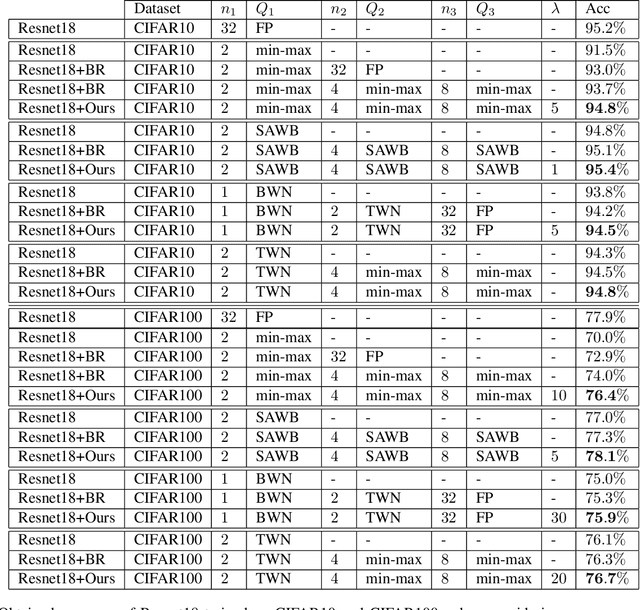
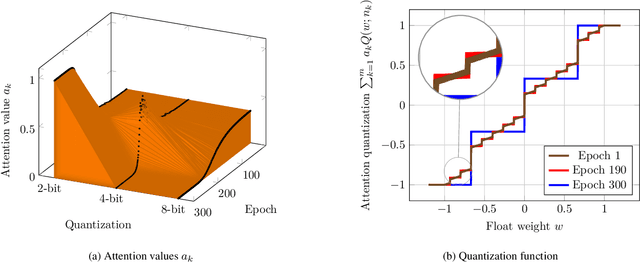
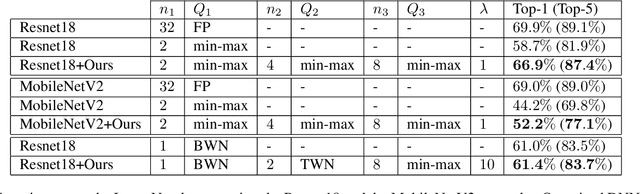
Low-bit quantization of network weights and activations can drastically reduce the memory footprint, complexity, energy consumption and latency of Deep Neural Networks (DNNs). However, low-bit quantization can also cause a considerable drop in accuracy, in particular when we apply it to complex learning tasks or lightweight DNN architectures. In this paper, we propose a training procedure that relaxes the low-bit quantization. We call this procedure \textit{DNN Quantization with Attention} (DQA). The relaxation is achieved by using a learnable linear combination of high, medium and low-bit quantizations. Our learning procedure converges step by step to a low-bit quantization using an attention mechanism with temperature scheduling. In experiments, our approach outperforms other low-bit quantization techniques on various object recognition benchmarks such as CIFAR10, CIFAR100 and ImageNet ILSVRC 2012, achieves almost the same accuracy as a full precision DNN, and considerably reduces the accuracy drop when quantizing lightweight DNN architectures.