 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutions with Radio-Frequency Spin-Diodes
Jan 27, 2025



The classification of radio-frequency (RF) signals is crucial for applications in robotics, traffic control, and medical devices. Spintronic devices, which respond to RF signals via ferromagnetic resonance, offer a promising solution. Recent studies have shown that a neural network of nanoscale magnetic tunnel junctions can classify RF signals without digitization. However, the complexity of these junctions poses challenges for rapid scaling. In this work, we demonstrate that simple spintronic devices, known as metallic spin-diodes, can effectively perform RF classification. These devices consist of NiFe/Pt bilayers and can implement weighted sums of RF inputs. We experimentally show that chains of four spin-diodes can execute 2x2 pixel filters, achieving high-quality convolutions on the Fashion-MNIST dataset. Integrating the hardware spin-diodes in a software network, we achieve a top-1 accuracy of 88 \% on the first 100 images, compared to 88.4 \% for full software with noise, and 90 \% without noise.
Self-Contrastive Forward-Forward Algorithm
Sep 17, 2024



The Forward-Forward (FF) algorithm is a recent, purely forward-mode learning method, that updates weights locally and layer-wise and supports supervised as well as unsupervised learning. These features make it ideal for applications such as brain-inspired learning, low-power hardware neural networks, and distributed learning in large models. However, while FF has shown promise on written digit recognition tasks, its performance on natural images and time-series remains a challenge. A key limitation is the need to generate high-quality negative examples for contrastive learning, especially in unsupervised tasks, where versatile solutions are currently lacking. To address this, we introduce the Self-Contrastive Forward-Forward (SCFF) method, inspired by self-supervised contrastive learning. SCFF generates positive and negative examples applicable across different datasets, surpassing existing local forward algorithms for unsupervised classification accuracy on MNIST (MLP: 98.7%), CIFAR-10 (CNN: 80.75%), and STL-10 (CNN: 77.3%). Additionally, SCFF is the first to enable FF training of recurrent neural networks, opening the door to more complex tasks and continuous-time video and text processing.
Training a multilayer dynamical spintronic network with standard machine learning tools to perform time series classification
Aug 07, 2024



The ability to process time-series at low energy cost is critical for many applications. Recurrent neural network, which can perform such tasks, are computationally expensive when implementing in software on conventional computers. Here we propose to implement a recurrent neural network in hardware using spintronic oscillators as dynamical neurons. Using numerical simulations, we build a multi-layer network and demonstrate that we can use backpropagation through time (BPTT) and standard machine learning tools to train this network. Leveraging the transient dynamics of the spintronic oscillators, we solve the sequential digits classification task with $89.83\pm2.91~\%$ accuracy, as good as the equivalent software network. We devise guidelines on how to choose the time constant of the oscillators as well as hyper-parameters of the network to adapt to different input time scales.
Training of Physical Neural Networks
Jun 05, 2024



Physical neural networks (PNNs) are a class of neural-like networks that leverage the properties of physical systems to perform computation. While PNNs are so far a niche research area with small-scale laboratory demonstrations, they are arguably one of the most underappreciated important opportunities in modern AI. Could we train AI models 1000x larger than current ones? Could we do this and also have them perform inference locally and privately on edge devices, such as smartphones or sensors? Research over the past few years has shown that the answer to all these questions is likely "yes, with enough research": PNNs could one day radically change what is possible and practical for AI systems. To do this will however require rethinking both how AI models work, and how they are trained - primarily by considering the problems through the constraints of the underlying hardware physics. To train PNNs at large scale, many methods including backpropagation-based and backpropagation-free approaches are now being explored. These methods have various trade-offs, and so far no method has been shown to scale to the same scale and performance as the backpropagation algorithm widely used in deep learning today. However, this is rapidly changing, and a diverse ecosystem of training techniques provides clues for how PNNs may one day be utilized to create both more efficient realizations of current-scale AI models, and to enable unprecedented-scale models.
Unsupervised End-to-End Training with a Self-Defined Bio-Inspired Target
Mar 18, 2024Current unsupervised learning methods depend on end-to-end training via deep learning techniques such as self-supervised learning, with high computational requirements, or employ layer-by-layer training using bio-inspired approaches like Hebbian learning, using local learning rules incompatible with supervised learning. Both approaches are problematic for edge AI hardware that relies on sparse computational resources and would strongly benefit from alternating between unsupervised and supervised learning phases - thus leveraging widely available unlabeled data from the environment as well as labeled training datasets. To solve this challenge, in this work, we introduce a 'self-defined target' that uses Winner-Take-All (WTA) selectivity at the network's final layer, complemented by regularization through biologically inspired homeostasis mechanism. This approach, framework-agnostic and compatible with both global (Backpropagation) and local (Equilibrium propagation) learning rules, achieves a 97.6% test accuracy on the MNIST dataset. Furthermore, we demonstrate that incorporating a hidden layer enhances classification accuracy and the quality of learned features across all training methods, showcasing the advantages of end-to-end unsupervised training. Extending to semi-supervised learning, our method dynamically adjusts the target according to data availability, reaching a 96.6% accuracy with just 600 labeled MNIST samples. This result highlights our 'unsupervised target' strategy's efficacy and flexibility in scenarios ranging from abundant to no labeled data availability.
RF signal classification in hardware with an RF spintronic neural network
Nov 02, 2022Extracting information from radiofrequency (RF) signals using artificial neural networks at low energy cost is a critical need for a wide range of applications. Here we show how to leverage the intrinsic dynamics of spintronic nanodevices called magnetic tunnel junctions to process multiple analogue RF inputs in parallel and perform synaptic operations. Furthermore, we achieve classification of RF signals with experimental data from magnetic tunnel junctions as neurons and synapses, with the same accuracy as an equivalent software neural network. These results are a key step for embedded radiofrequency artificial intelligence.
Quantum materials for energy-efficient neuromorphic computing
Apr 04, 2022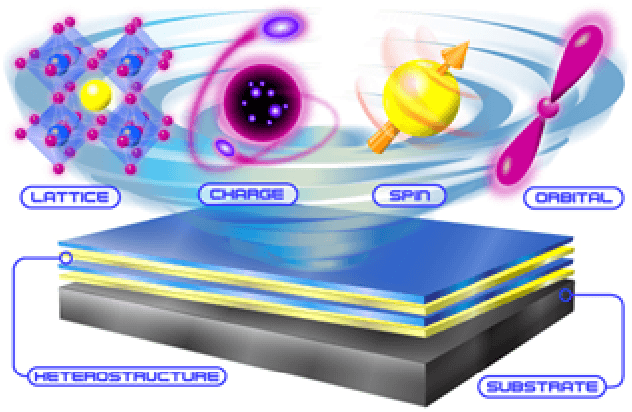
Neuromorphic computing approaches become increasingly important as we address future needs for efficiently processing massive amounts of data. The unique attributes of quantum materials can help address these needs by enabling new energy-efficient device concepts that implement neuromorphic ideas at the hardware level. In particular, strong correlations give rise to highly non-linear responses, such as conductive phase transitions that can be harnessed for short and long-term plasticity. Similarly, magnetization dynamics are strongly non-linear and can be utilized for data classification. This paper discusses select examples of these approaches, and provides a perspective for the current opportunities and challenges for assembling quantum-material-based devices for neuromorphic functionalities into larger emergent complex network systems.
Forecasting the outcome of spintronic experiments with Neural Ordinary Differential Equations
Jul 23, 2021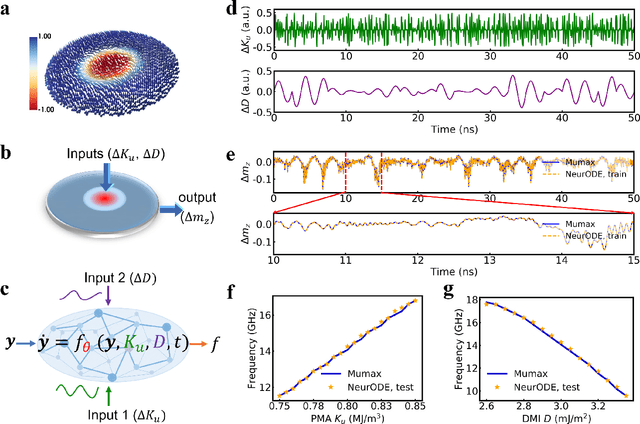
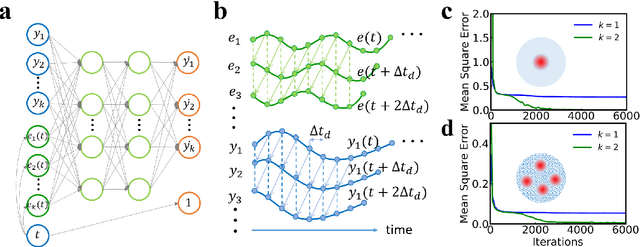
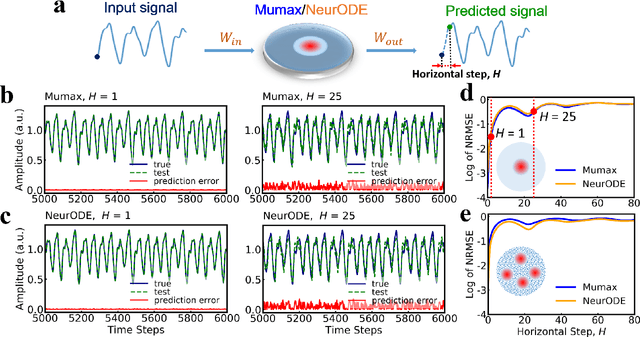
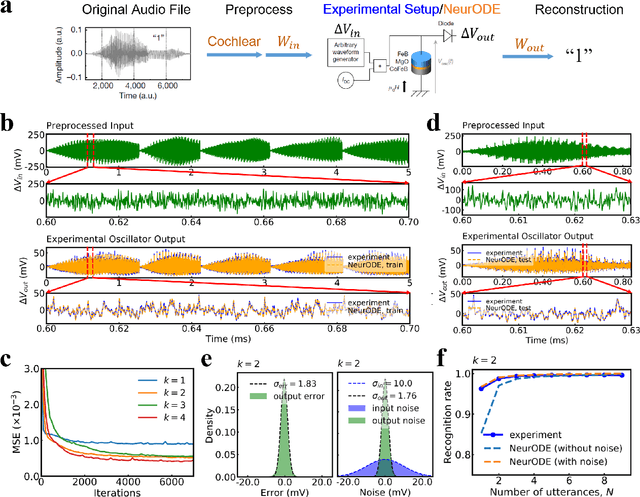
Deep learning has an increasing impact to assist research, allowing, for example, the discovery of novel materials. Until now, however, these artificial intelligence techniques have fallen short of discovering the full differential equation of an experimental physical system. Here we show that a dynamical neural network, trained on a minimal amount of data, can predict the behavior of spintronic devices with high accuracy and an extremely efficient simulation time, compared to the micromagnetic simulations that are usually employed to model them. For this purpose, we re-frame the formalism of Neural Ordinary Differential Equations (ODEs) to the constraints of spintronics: few measured outputs, multiple inputs and internal parameters. We demonstrate with Spin-Neural ODEs an acceleration factor over 200 compared to micromagnetic simulations for a complex problem -- the simulation of a reservoir computer made of magnetic skyrmions (20 minutes compared to three days). In a second realization, we show that we can predict the noisy response of experimental spintronic nano-oscillators to varying inputs after training Spin-Neural ODEs on five milliseconds of their measured response to different excitations. Spin-Neural ODE is a disruptive tool for developing spintronic applications in complement to micromagnetic simulations, which are time-consuming and cannot fit experiments when noise or imperfections are present. Spin-Neural ODE can also be generalized to other electronic devices involving dynamics.
Training Dynamical Binary Neural Networks with Equilibrium Propagation
Mar 16, 2021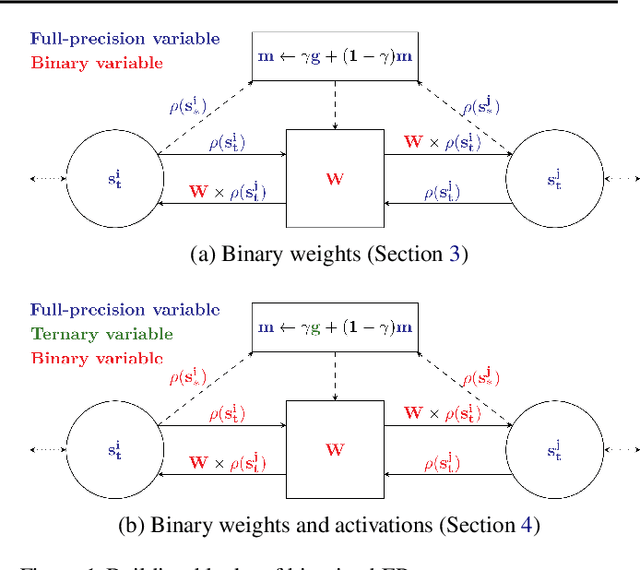
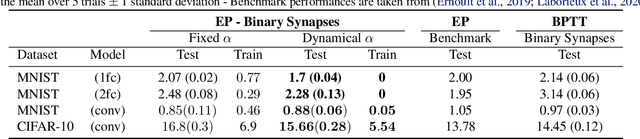
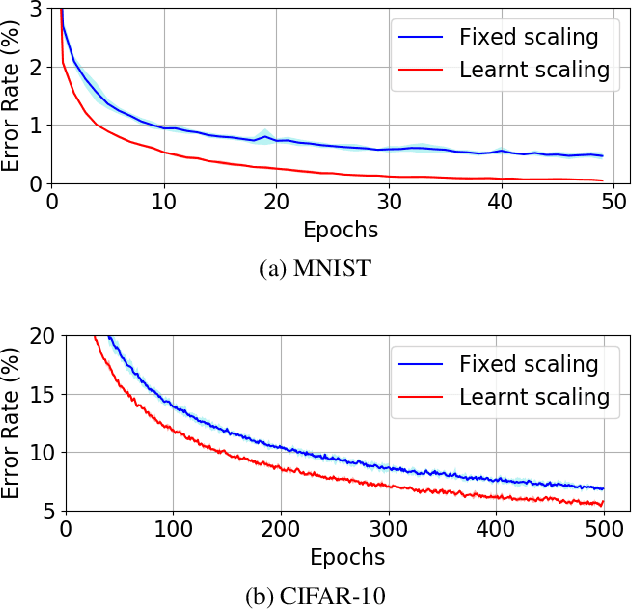
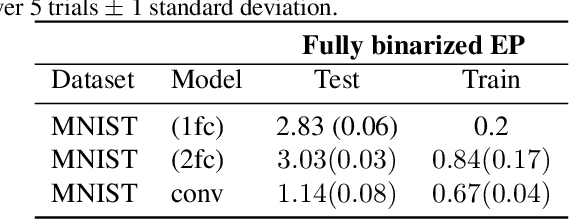
Equilibrium Propagation (EP) is an algorithm intrinsically adapted to the training of physical networks, in particular thanks to the local updates of weights given by the internal dynamics of the system. However, the construction of such a hardware requires to make the algorithm compatible with the existing neuromorphic CMOS technology, which generally exploits digital communication between neurons and offers a limited amount of local memory. In this work, we demonstrate that EP can train dynamical networks with binary activations and weights. We first train systems with binary weights and full-precision activations, achieving an accuracy equivalent to that of full-precision models trained by standard EP on MNIST, and losing only 1.9% accuracy on CIFAR-10 with equal architecture. We then extend our method to the training of models with binary activations and weights on MNIST, achieving an accuracy within 1% of the full-precision reference for fully connected architectures and reaching the full-precision reference accuracy for the convolutional architecture. Our extension of EP training to binary networks is consistent with the requirements of today's dynamic, brain-inspired hardware platforms and paves the way for very low-power end-to-end learning.
Scaling Equilibrium Propagation to Deep ConvNets by Drastically Reducing its Gradient Estimator Bias
Jan 14, 2021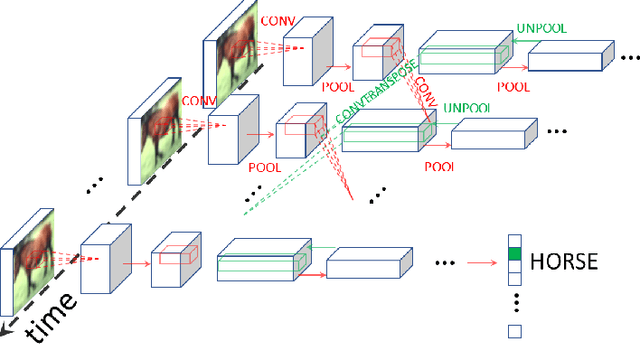
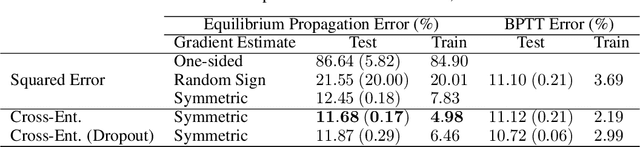
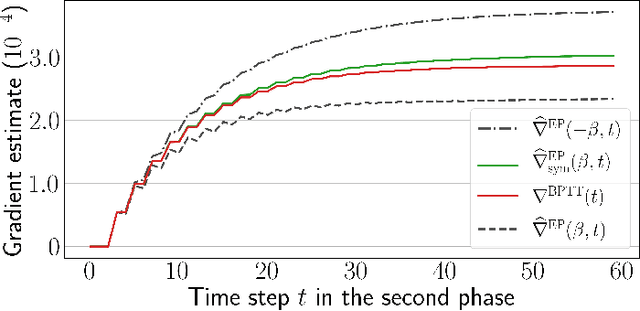

Equilibrium Propagation (EP) is a biologically-inspired counterpart of Backpropagation Through Time (BPTT) which, owing to its strong theoretical guarantees and the locality in space of its learning rule, fosters the design of energy-efficient hardware dedicated to learning. In practice, however, EP does not scale to visual tasks harder than MNIST. In this work, we show that a bias in the gradient estimate of EP, inherent in the use of finite nudging, is responsible for this phenomenon and that cancelling it allows training deep ConvNets by EP, including architectures with distinct forward and backward connections. These results highlight EP as a scalable approach to compute error gradients in deep neural networks, thereby motivating its hardware implementation.