 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Cyclic Diffusion for Inference Scaling
May 20, 2025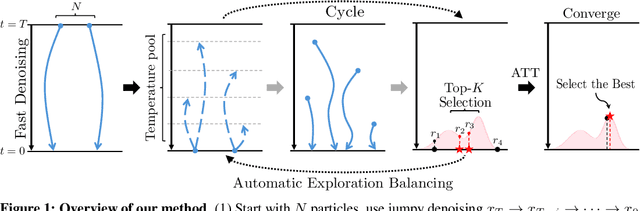

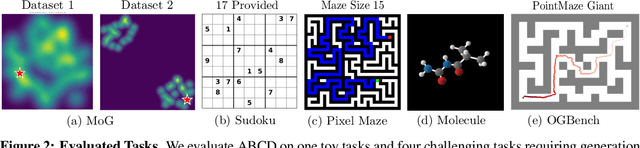
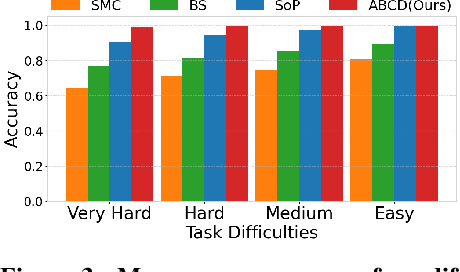
Diffusion models have demonstrated strong generative capabilities across domains ranging from image synthesis to complex reasoning tasks. However, most inference-time scaling methods rely on fixed denoising schedules, limiting their ability to allocate computation based on instance difficulty or task-specific demands adaptively. We introduce the challenge of adaptive inference-time scaling-dynamically adjusting computational effort during inference-and propose Adaptive Bi-directional Cyclic Diffusion (ABCD), a flexible, search-based inference framework. ABCD refines outputs through bi-directional diffusion cycles while adaptively controlling exploration depth and termination. It comprises three components: Cyclic Diffusion Search, Automatic Exploration-Exploitation Balancing, and Adaptive Thinking Time. Experiments show that ABCD improves performance across diverse tasks while maintaining computational efficiency.
Self-Evolving Curriculum for LLM Reasoning
May 20, 2025



Reinforcement learning (RL) has proven effective for fine-tuning large language models (LLMs), significantly enhancing their reasoning abilities in domains such as mathematics and code generation. A crucial factor influencing RL fine-tuning success is the training curriculum: the order in which training problems are presented. While random curricula serve as common baselines, they remain suboptimal; manually designed curricula often rely heavily on heuristics, and online filtering methods can be computationally prohibitive. To address these limitations, we propose Self-Evolving Curriculum (SEC), an automatic curriculum learning method that learns a curriculum policy concurrently with the RL fine-tuning process. Our approach formulates curriculum selection as a non-stationary Multi-Armed Bandit problem, treating each problem category (e.g., difficulty level or problem type) as an individual arm. We leverage the absolute advantage from policy gradient methods as a proxy measure for immediate learning gain. At each training step, the curriculum policy selects categories to maximize this reward signal and is updated using the TD(0) method. Across three distinct reasoning domains: planning, inductive reasoning, and mathematics, our experiments demonstrate that SEC significantly improves models' reasoning capabilities, enabling better generalization to harder, out-of-distribution test problems. Additionally, our approach achieves better skill balance when fine-tuning simultaneously on multiple reasoning domains. These findings highlight SEC as a promising strategy for RL fine-tuning of LLMs.
Search-Based Correction of Reasoning Chains for Language Models
May 17, 2025Chain-of-Thought (CoT) reasoning has advanced the capabilities and transparency of language models (LMs); however, reasoning chains can contain inaccurate statements that reduce performance and trustworthiness. To address this, we introduce a new self-correction framework that augments each reasoning step in a CoT with a latent variable indicating its veracity, enabling modeling of all possible truth assignments rather than assuming correctness throughout. To efficiently explore this expanded space, we introduce Search Corrector, a discrete search algorithm over boolean-valued veracity assignments. It efficiently performs otherwise intractable inference in the posterior distribution over veracity assignments by leveraging the LM's joint likelihood over veracity and the final answer as a proxy reward. This efficient inference-time correction method facilitates supervised fine-tuning of an Amortized Corrector by providing pseudo-labels for veracity. The Amortized Corrector generalizes self-correction, enabling accurate zero-shot veracity inference in novel contexts. Empirical results demonstrate that Search Corrector reliably identifies errors in logical (ProntoQA) and mathematical reasoning (GSM8K) benchmarks. The Amortized Corrector achieves comparable zero-shot accuracy and improves final answer accuracy by up to 25%.
Assessing SAM for Tree Crown Instance Segmentation from Drone Imagery
Mar 26, 2025The potential of tree planting as a natural climate solution is often undermined by inadequate monitoring of tree planting projects. Current monitoring methods involve measuring trees by hand for each species, requiring extensive cost, time, and labour. Advances in drone remote sensing and computer vision offer great potential for mapping and characterizing trees from aerial imagery, and large pre-trained vision models, such as the Segment Anything Model (SAM), may be a particularly compelling choice given limited labeled data. In this work, we compare SAM methods for the task of automatic tree crown instance segmentation in high resolution drone imagery of young tree plantations. We explore the potential of SAM for this task, and find that methods using SAM out-of-the-box do not outperform a custom Mask R-CNN, even with well-designed prompts, but that there is potential for methods which tune SAM further. We also show that predictions can be improved by adding Digital Surface Model (DSM) information as an input.
Extendable Long-Horizon Planning via Hierarchical Multiscale Diffusion
Mar 25, 2025



This paper tackles a novel problem, extendable long-horizon planning-enabling agents to plan trajectories longer than those in training data without compounding errors. To tackle this, we propose the Hierarchical Multiscale Diffuser (HM-Diffuser) and Progressive Trajectory Extension (PTE), an augmentation method that iteratively generates longer trajectories by stitching shorter ones. HM-Diffuser trains on these extended trajectories using a hierarchical structure, efficiently handling tasks across multiple temporal scales. Additionally, we introduce Adaptive Plan Pondering and the Recursive HM-Diffuser, which consolidate hierarchical layers into a single model to process temporal scales recursively. Experimental results demonstrate the effectiveness of our approach, advancing diffusion-based planners for scalable long-horizon planning.
A scalable gene network model of regulatory dynamics in single cells
Mar 25, 2025Single-cell data provide high-dimensional measurements of the transcriptional states of cells, but extracting insights into the regulatory functions of genes, particularly identifying transcriptional mechanisms affected by biological perturbations, remains a challenge. Many perturbations induce compensatory cellular responses, making it difficult to distinguish direct from indirect effects on gene regulation. Modeling how gene regulatory functions shape the temporal dynamics of these responses is key to improving our understanding of biological perturbations. Dynamical models based on differential equations offer a principled way to capture transcriptional dynamics, but their application to single-cell data has been hindered by computational constraints, stochasticity, sparsity, and noise. Existing methods either rely on low-dimensional representations or make strong simplifying assumptions, limiting their ability to model transcriptional dynamics at scale. We introduce a Functional and Learnable model of Cell dynamicS, FLeCS, that incorporates gene network structure into coupled differential equations to model gene regulatory functions. Given (pseudo)time-series single-cell data, FLeCS accurately infers cell dynamics at scale, provides improved functional insights into transcriptional mechanisms perturbed by gene knockouts, both in myeloid differentiation and K562 Perturb-seq experiments, and simulates single-cell trajectories of A549 cells following small-molecule perturbations.
Trajectory Balance with Asynchrony: Decoupling Exploration and Learning for Fast, Scalable LLM Post-Training
Mar 24, 2025Reinforcement learning (RL) is a critical component of large language model (LLM) post-training. However, existing on-policy algorithms used for post-training are inherently incompatible with the use of experience replay buffers, which can be populated scalably by distributed off-policy actors to enhance exploration as compute increases. We propose efficiently obtaining this benefit of replay buffers via Trajectory Balance with Asynchrony (TBA), a massively scalable LLM RL system. In contrast to existing approaches, TBA uses a larger fraction of compute on search, constantly generating off-policy data for a central replay buffer. A training node simultaneously samples data from this buffer based on reward or recency to update the policy using Trajectory Balance (TB), a diversity-seeking RL objective introduced for GFlowNets. TBA offers three key advantages: (1) decoupled training and search, speeding up training wall-clock time by 4x or more; (2) improved diversity through large-scale off-policy sampling; and (3) scalable search for sparse reward settings. On mathematical reasoning, preference-tuning, and automated red-teaming (diverse and representative post-training tasks), TBA produces speed and performance improvements over strong baselines.
Offline Model-Based Optimization: Comprehensive Review
Mar 21, 2025



Offline optimization is a fundamental challenge in science and engineering, where the goal is to optimize black-box functions using only offline datasets. This setting is particularly relevant when querying the objective function is prohibitively expensive or infeasible, with applications spanning protein engineering, material discovery, neural architecture search, and beyond. The main difficulty lies in accurately estimating the objective landscape beyond the available data, where extrapolations are fraught with significant epistemic uncertainty. This uncertainty can lead to objective hacking(reward hacking), exploiting model inaccuracies in unseen regions, or other spurious optimizations that yield misleadingly high performance estimates outside the training distribution. Recent advances in model-based optimization(MBO) have harnessed the generalization capabilities of deep neural networks to develop offline-specific surrogate and generative models. Trained with carefully designed strategies, these models are more robust against out-of-distribution issues, facilitating the discovery of improved designs. Despite its growing impact in accelerating scientific discovery, the field lacks a comprehensive review. To bridge this gap, we present the first thorough review of offline MBO. We begin by formalizing the problem for both single-objective and multi-objective settings and by reviewing recent benchmarks and evaluation metrics. We then categorize existing approaches into two key areas: surrogate modeling, which emphasizes accurate function approximation in out-of-distribution regions, and generative modeling, which explores high-dimensional design spaces to identify high-performing designs. Finally, we examine the key challenges and propose promising directions for advancement in this rapidly evolving field including safe control of superintelligent systems.
Solving Bayesian inverse problems with diffusion priors and off-policy RL
Mar 12, 2025This paper presents a practical application of Relative Trajectory Balance (RTB), a recently introduced off-policy reinforcement learning (RL) objective that can asymptotically solve Bayesian inverse problems optimally. We extend the original work by using RTB to train conditional diffusion model posteriors from pretrained unconditional priors for challenging linear and non-linear inverse problems in vision, and science. We use the objective alongside techniques such as off-policy backtracking exploration to improve training. Importantly, our results show that existing training-free diffusion posterior methods struggle to perform effective posterior inference in latent space due to inherent biases.
Learning Decision Trees as Amortized Structure Inference
Mar 10, 2025Building predictive models for tabular data presents fundamental challenges, notably in scaling consistently, i.e., more resources translating to better performance, and generalizing systematically beyond the training data distribution. Designing decision tree models remains especially challenging given the intractably large search space, and most existing methods rely on greedy heuristics, while deep learning inductive biases expect a temporal or spatial structure not naturally present in tabular data. We propose a hybrid amortized structure inference approach to learn predictive decision tree ensembles given data, formulating decision tree construction as a sequential planning problem. We train a deep reinforcement learning (GFlowNet) policy to solve this problem, yielding a generative model that samples decision trees from the Bayesian posterior. We show that our approach, DT-GFN, outperforms state-of-the-art decision tree and deep learning methods on standard classification benchmarks derived from real-world data, robustness to distribution shifts, and anomaly detection, all while yielding interpretable models with shorter description lengths. Samples from the trained DT-GFN model can be ensembled to construct a random forest, and we further show that the performance of scales consistently in ensemble size, yielding ensembles of predictors that continue to generalize systematically.