 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHSI-VAR: Rethinking Hyperspectral Restoration through Spatial-Spectral Visual Autoregression
Jan 31, 2026Hyperspectral images (HSIs) capture richer spatial-spectral information beyond RGB, yet real-world HSIs often suffer from a composite mix of degradations, such as noise, blur, and missing bands. Existing generative approaches for HSI restoration like diffusion models require hundreds of iterative steps, making them computationally impractical for high-dimensional HSIs. While regression models tend to produce oversmoothed results, failing to preserve critical structural details. We break this impasse by introducing HSI-VAR, rethinking HSI restoration as an autoregressive generation problem, where spectral and spatial dependencies can be progressively modeled rather than globally reconstructed. HSI-VAR incorporates three key innovations: (1) Latent-condition alignment, which couples semantic consistency between latent priors and conditional embeddings for precise reconstruction; (2) Degradation-aware guidance, which uniquely encodes mixed degradations as linear combinations in the embedding space for automatic control, remarkably achieving a nearly $50\%$ reduction in computational cost at inference; (3) A spatial-spectral adaptation module that refines details across both domains in the decoding phase. Extensive experiments on nine all-in-one HSI restoration benchmarks confirm HSI-VAR's state-of-the-art performance, achieving a 3.77 dB PSNR improvement on \textbf{\textit{ICVL}} and offering superior structure preservation with an inference speed-up of up to $95.5 \times$ compared with diffusion-based methods, making it a highly practical solution for real-world HSI restoration.
Vision-Language Controlled Deep Unfolding for Joint Medical Image Restoration and Segmentation
Jan 30, 2026We propose VL-DUN, a principled framework for joint All-in-One Medical Image Restoration and Segmentation (AiOMIRS) that bridges the gap between low-level signal recovery and high-level semantic understanding. While standard pipelines treat these tasks in isolation, our core insight is that they are fundamentally synergistic: restoration provides clean anatomical structures to improve segmentation, while semantic priors regularize the restoration process. VL-DUN resolves the sub-optimality of sequential processing through two primary innovations. (1) We formulate AiOMIRS as a unified optimization problem, deriving an interpretable joint unfolding mechanism where restoration and segmentation are mathematically coupled for mutual refinement. (2) We introduce a frequency-aware Mamba mechanism to capture long-range dependencies for global segmentation while preserving the high-frequency textures necessary for restoration. This allows for efficient global context modeling with linear complexity, effectively mitigating the spectral bias of standard architectures. As a pioneering work in the AiOMIRS task, VL-DUN establishes a new state-of-the-art across multi-modal benchmarks, improving PSNR by 0.92 dB and the Dice coefficient by 9.76\%. Our results demonstrate that joint collaborative learning offers a superior, more robust solution for complex clinical workflows compared to isolated task processing. The codes are provided in https://github.com/cipi666/VLDUN.
Binarized Mamba-Transformer for Lightweight Quad Bayer HybridEVS Demosaicing
Mar 20, 2025
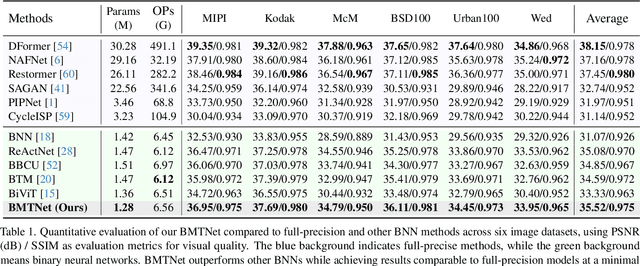
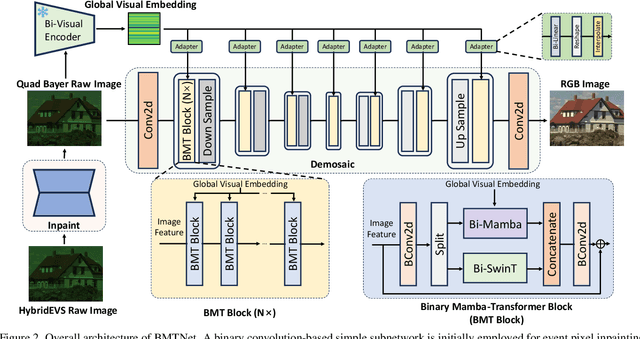

Quad Bayer demosaicing is the central challenge for enabling the widespread application of Hybrid Event-based Vision Sensors (HybridEVS). Although existing learning-based methods that leverage long-range dependency modeling have achieved promising results, their complexity severely limits deployment on mobile devices for real-world applications. To address these limitations, we propose a lightweight Mamba-based binary neural network designed for efficient and high-performing demosaicing of HybridEVS RAW images. First, to effectively capture both global and local dependencies, we introduce a hybrid Binarized Mamba-Transformer architecture that combines the strengths of the Mamba and Swin Transformer architectures. Next, to significantly reduce computational complexity, we propose a binarized Mamba (Bi-Mamba), which binarizes all projections while retaining the core Selective Scan in full precision. Bi-Mamba also incorporates additional global visual information to enhance global context and mitigate precision loss. We conduct quantitative and qualitative experiments to demonstrate the effectiveness of BMTNet in both performance and computational efficiency, providing a lightweight demosaicing solution suited for real-world edge devices. Our codes and models are available at https://github.com/Clausy9/BMTNet.
Generative Model-Assisted Demosaicing for Cross-multispectral Cameras
Mar 04, 2025As a crucial part of the spectral filter array (SFA)-based multispectral imaging process, spectral demosaicing has exploded with the proliferation of deep learning techniques. However, (1) bothering by the difficulty of capturing corresponding labels for real data or simulating the practical spectral imaging process, end-to-end networks trained in a supervised manner using simulated data often perform poorly on real data. (2) cross-camera spectral discrepancies make it difficult to apply pre-trained models to new cameras. (3) existing demosaicing networks are prone to introducing visual artifacts on hard cases due to the interpolation of unknown values. To address these issues, we propose a hybrid supervised training method with the assistance of the self-supervised generative model, which performs well on real data across different spectral cameras. Specifically, our approach consists of three steps: (1) Pre-Training step: training the end-to-end neural network on a large amount of simulated data; (2) Pseudo-Pairing step: generating pseudo-labels of real target data using the self-supervised generative model; (3) Fine-Tuning step: fine-tuning the pre-trained model on the pseudo data pairs obtained in (2). To alleviate artifacts, we propose a frequency-domain hard patch selection method that identifies artifact-prone regions by analyzing spectral discrepancies using Fourier transform and filtering techniques, allowing targeted fine-tuning to enhance demosaicing performance. Finally, we propose UniSpecTest, a real-world multispectral mosaic image dataset for testing. Ablation experiments have demonstrated the effectiveness of each training step, and extensive experiments on both synthetic and real datasets show that our method achieves significant performance gains compared to state-of-the-art techniques.
Global Graph Propagation with Hierarchical Information Transfer for Incomplete Contrastive Multi-view Clustering
Feb 26, 2025Incomplete multi-view clustering has become one of the important research problems due to the extensive missing multi-view data in the real world. Although the existing methods have made great progress, there are still some problems: 1) most methods cannot effectively mine the information hidden in the missing data; 2) most methods typically divide representation learning and clustering into two separate stages, but this may affect the clustering performance as the clustering results directly depend on the learned representation. To address these problems, we propose a novel incomplete multi-view clustering method with hierarchical information transfer. Firstly, we design the view-specific Graph Convolutional Networks (GCN) to obtain the representation encoding the graph structure, which is then fused into the consensus representation. Secondly, considering that one layer of GCN transfers one-order neighbor node information, the global graph propagation with the consensus representation is proposed to handle the missing data and learn deep representation. Finally, we design a weight-sharing pseudo-classifier with contrastive learning to obtain an end-to-end framework that combines view-specific representation learning, global graph propagation with hierarchical information transfer, and contrastive clustering for joint optimization. Extensive experiments conducted on several commonly-used datasets demonstrate the effectiveness and superiority of our method in comparison with other state-of-the-art approaches. The code is available at https://github.com/KelvinXuu/GHICMC.
OTLRM: Orthogonal Learning-based Low-Rank Metric for Multi-Dimensional Inverse Problems
Dec 15, 2024



In real-world scenarios, complex data such as multispectral images and multi-frame videos inherently exhibit robust low-rank property. This property is vital for multi-dimensional inverse problems, such as tensor completion, spectral imaging reconstruction, and multispectral image denoising. Existing tensor singular value decomposition (t-SVD) definitions rely on hand-designed or pre-given transforms, which lack flexibility for defining tensor nuclear norm (TNN). The TNN-regularized optimization problem is solved by the singular value thresholding (SVT) operator, which leverages the t-SVD framework to obtain the low-rank tensor. However, it is quite complicated to introduce SVT into deep neural networks due to the numerical instability problem in solving the derivatives of the eigenvectors. In this paper, we introduce a novel data-driven generative low-rank t-SVD model based on the learnable orthogonal transform, which can be naturally solved under its representation. Prompted by the linear algebra theorem of the Householder transformation, our learnable orthogonal transform is achieved by constructing an endogenously orthogonal matrix adaptable to neural networks, optimizing it as arbitrary orthogonal matrices. Additionally, we propose a low-rank solver as a generalization of SVT, which utilizes an efficient representation of generative networks to obtain low-rank structures. Extensive experiments highlight its significant restoration enhancements.
Random Sampling for Diffusion-based Adversarial Purification
Nov 28, 2024



Denoising Diffusion Probabilistic Models (DDPMs) have gained great attention in adversarial purification. Current diffusion-based works focus on designing effective condition-guided mechanisms while ignoring a fundamental problem, i.e., the original DDPM sampling is intended for stable generation, which may not be the optimal solution for adversarial purification. Inspired by the stability of the Denoising Diffusion Implicit Model (DDIM), we propose an opposite sampling scheme called random sampling. In brief, random sampling will sample from a random noisy space during each diffusion process, while DDPM and DDIM sampling will continuously sample from the adjacent or original noisy space. Thus, random sampling obtains more randomness and achieves stronger robustness against adversarial attacks. Correspondingly, we also introduce a novel mediator conditional guidance to guarantee the consistency of the prediction under the purified image and clean image input. To expand awareness of guided diffusion purification, we conduct a detailed evaluation with different sampling methods and our random sampling achieves an impressive improvement in multiple settings. Leveraging mediator-guided random sampling, we also establish a baseline method named DiffAP, which significantly outperforms state-of-the-art (SOTA) approaches in performance and defensive stability. Remarkably, under strong attack, our DiffAP even achieves a more than 20% robustness advantage with 10$\times$ sampling acceleration.
MambaSCI: Efficient Mamba-UNet for Quad-Bayer Patterned Video Snapshot Compressive Imaging
Oct 18, 2024



Color video snapshot compressive imaging (SCI) employs computational imaging techniques to capture multiple sequential video frames in a single Bayer-patterned measurement. With the increasing popularity of quad-Bayer pattern in mainstream smartphone cameras for capturing high-resolution videos, mobile photography has become more accessible to a wider audience. However, existing color video SCI reconstruction algorithms are designed based on the traditional Bayer pattern. When applied to videos captured by quad-Bayer cameras, these algorithms often result in color distortion and ineffective demosaicing, rendering them impractical for primary equipment. To address this challenge, we propose the MambaSCI method, which leverages the Mamba and UNet architectures for efficient reconstruction of quad-Bayer patterned color video SCI. To the best of our knowledge, our work presents the first algorithm for quad-Bayer patterned SCI reconstruction, and also the initial application of the Mamba model to this task. Specifically, we customize Residual-Mamba-Blocks, which residually connect the Spatial-Temporal Mamba (STMamba), Edge-Detail-Reconstruction (EDR) module, and Channel Attention (CA) module. Respectively, STMamba is used to model long-range spatial-temporal dependencies with linear complexity, EDR is for better edge-detail reconstruction, and CA is used to compensate for the missing channel information interaction in Mamba model. Experiments demonstrate that MambaSCI surpasses state-of-the-art methods with lower computational and memory costs. PyTorch style pseudo-code for the core modules is provided in the supplementary materials.
Empowering Snapshot Compressive Imaging: Spatial-Spectral State Space Model with Across-Scanning and Local Enhancement
Aug 01, 2024Snapshot Compressive Imaging (SCI) relies on decoding algorithms such as CNN or Transformer to reconstruct the hyperspectral image (HSI) from its compressed measurement. Although existing CNN and Transformer-based methods have proven effective, CNNs are limited by their inadequate modeling of long-range dependencies, while Transformer ones face high computational costs due to quadratic complexity. Recent Mamba models have demonstrated superior performance over CNN and Transformer-based architectures in some visual tasks, but these models have not fully utilized the local similarities in both spatial and spectral dimensions. Moreover, the long-sequence modeling capability of SSM may offer an advantage in processing the numerous spectral bands for HSI reconstruction, which has not yet been explored. In this paper, we introduce a State Space Model with Across-Scanning and Local Enhancement, named ASLE-SSM, that employs a Spatial-Spectral SSM for global-local balanced context encoding and cross-channel interaction promoting. Specifically, we introduce local scanning in the spatial dimension to balance the global and local receptive fields, and then propose our across-scanning method based on spatial-spectral local cubes to leverage local similarities between adjacent spectral bands and pixels to guide the reconstruction process. These two scanning mechanisms extract the HSI's local features while balancing the global perspective without any additional costs. Experimental results illustrate ASLE-SSM's superiority over existing state-of-the-art methods, with an inference speed 2.4 times faster than Transformer-based MST and saving 0.12 (M) of parameters, achieving the lowest computational cost and parameter count.
LLEMamba: Low-Light Enhancement via Relighting-Guided Mamba with Deep Unfolding Network
Jun 03, 2024Transformer-based low-light enhancement methods have yielded promising performance by effectively capturing long-range dependencies in a global context. However, their elevated computational demand limits the scalability of multiple iterations in deep unfolding networks, and hence they have difficulty in flexibly balancing interpretability and distortion. To address this issue, we propose a novel Low-Light Enhancement method via relighting-guided Mamba with a deep unfolding network (LLEMamba), whose theoretical interpretability and fidelity are guaranteed by Retinex optimization and Mamba deep priors, respectively. Specifically, our LLEMamba first constructs a Retinex model with deep priors, embedding the iterative optimization process based on the Alternating Direction Method of Multipliers (ADMM) within a deep unfolding network. Unlike Transformer, to assist the deep unfolding framework with multiple iterations, the proposed LLEMamba introduces a novel Mamba architecture with lower computational complexity, which not only achieves light-dependent global visual context for dark images during reflectance relight but also optimizes to obtain more stable closed-form solutions. Experiments on the benchmarks show that LLEMamba achieves superior quantitative evaluations and lower distortion visual results compared to existing state-of-the-art methods.