 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPC: A Unified Predictor-Corrector Framework for Fast Sampling of Diffusion Models
Feb 12, 2023



Diffusion probabilistic models (DPMs) have demonstrated a very promising ability in high-resolution image synthesis. However, sampling from a pre-trained DPM usually requires hundreds of model evaluations, which is computationally expensive. Despite recent progress in designing high-order solvers for DPMs, there still exists room for further speedup, especially in extremely few steps (e.g., 5~10 steps). Inspired by the predictor-corrector for ODE solvers, we develop a unified corrector (UniC) that can be applied after any existing DPM sampler to increase the order of accuracy without extra model evaluations, and derive a unified predictor (UniP) that supports arbitrary order as a byproduct. Combining UniP and UniC, we propose a unified predictor-corrector framework called UniPC for the fast sampling of DPMs, which has a unified analytical form for any order and can significantly improve the sampling quality over previous methods. We evaluate our methods through extensive experiments including both unconditional and conditional sampling using pixel-space and latent-space DPMs. Our UniPC can achieve 3.87 FID on CIFAR10 (unconditional) and 7.51 FID on ImageNet 256$\times$256 (conditional) with only 10 function evaluations. Code is available at https://github.com/wl-zhao/UniPC
AdaPoinTr: Diverse Point Cloud Completion with Adaptive Geometry-Aware Transformers
Jan 11, 2023



In this paper, we present a new method that reformulates point cloud completion as a set-to-set translation problem and design a new model, called PoinTr, which adopts a Transformer encoder-decoder architecture for point cloud completion. By representing the point cloud as a set of unordered groups of points with position embeddings, we convert the input data to a sequence of point proxies and employ the Transformers for generation. To facilitate Transformers to better leverage the inductive bias about 3D geometric structures of point clouds, we further devise a geometry-aware block that models the local geometric relationships explicitly. The migration of Transformers enables our model to better learn structural knowledge and preserve detailed information for point cloud completion. Taking a step towards more complicated and diverse situations, we further propose AdaPoinTr by developing an adaptive query generation mechanism and designing a novel denoising task during completing a point cloud. Coupling these two techniques enables us to train the model efficiently and effectively: we reduce training time (by 15x or more) and improve completion performance (over 20%). We also show our method can be extended to the scene-level point cloud completion scenario by designing a new geometry-enhanced semantic scene completion framework. Extensive experiments on the existing and newly-proposed datasets demonstrate the effectiveness of our method, which attains 6.53 CD on PCN, 0.81 CD on ShapeNet-55 and 0.392 MMD on real-world KITTI, surpassing other work by a large margin and establishing new state-of-the-arts on various benchmarks. Most notably, AdaPoinTr can achieve such promising performance with higher throughputs and fewer FLOPs compared with the previous best methods in practice. The code and datasets are available at https://github.com/yuxumin/PoinTr
FLAG3D: A 3D Fitness Activity Dataset with Language Instruction
Dec 09, 2022



With the continuously thriving popularity around the world, fitness activity analytic has become an emerging research topic in computer vision. While a variety of new tasks and algorithms have been proposed recently, there are growing hunger for data resources involved in high-quality data, fine-grained labels, and diverse environments. In this paper, we present FLAG3D, a large-scale 3D fitness activity dataset with language instruction containing 180K sequences of 60 categories. FLAG3D features the following three aspects: 1) accurate and dense 3D human pose captured from advanced MoCap system to handle the complex activity and large movement, 2) detailed and professional language instruction to describe how to perform a specific activity, 3) versatile video resources from a high-tech MoCap system, rendering software, and cost-effective smartphones in natural environments. Extensive experiments and in-depth analysis show that FLAG3D contributes great research value for various challenges, such as cross-domain human action recognition, dynamic human mesh recovery, and language-guided human action generation. Our dataset and source code will be publicly available at https://andytang15.github.io/FLAG3D.
Prompt Learning with Optimal Transport for Vision-Language Models
Oct 03, 2022

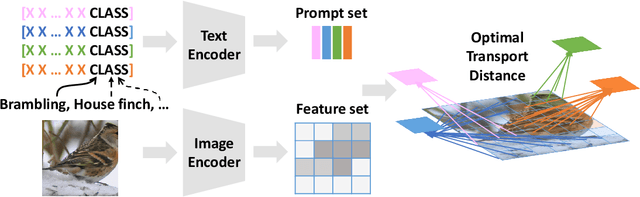
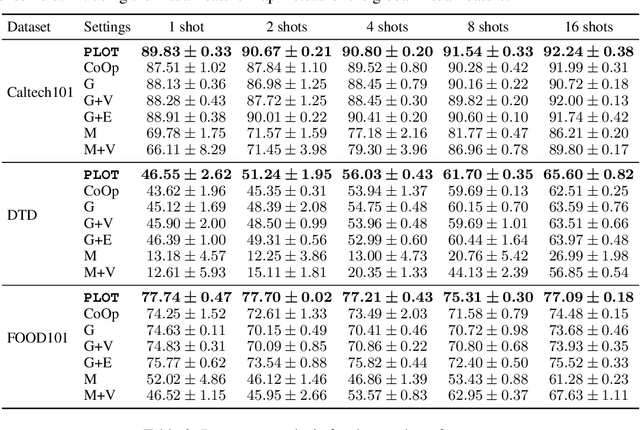
With the increasing attention to large vision-language models such as CLIP, there has been a significant amount of effort dedicated to building efficient prompts. Unlike conventional methods of only learning one single prompt, we propose to learn multiple comprehensive prompts to describe diverse characteristics of categories such as intrinsic attributes or extrinsic contexts. However, directly matching each prompt to the same visual feature is problematic, as it pushes the prompts to converge to one point. To solve this problem, we propose to apply optimal transport to match the vision and text modalities. Specifically, we first model images and the categories with visual and textual feature sets. Then, we apply a two-stage optimization strategy to learn the prompts. In the inner loop, we optimize the optimal transport distance to align visual features and prompts by the Sinkhorn algorithm, while in the outer loop, we learn the prompts by this distance from the supervised data. Extensive experiments are conducted on the few-shot recognition task and the improvement demonstrates the superiority of our method.
HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions
Aug 09, 2022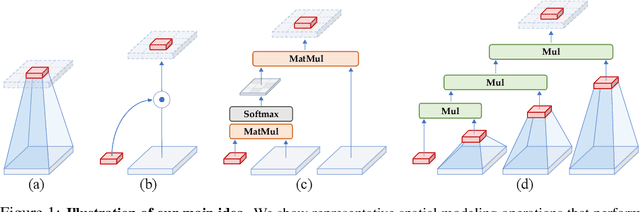
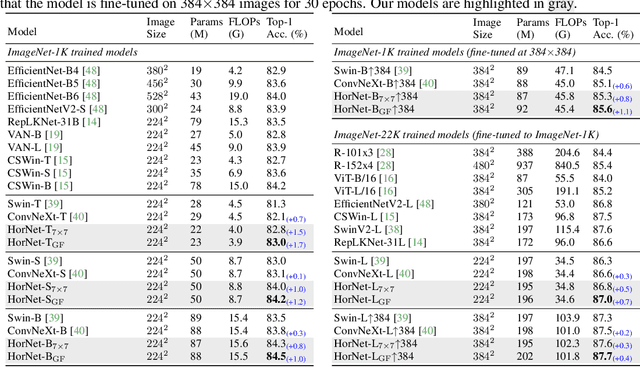
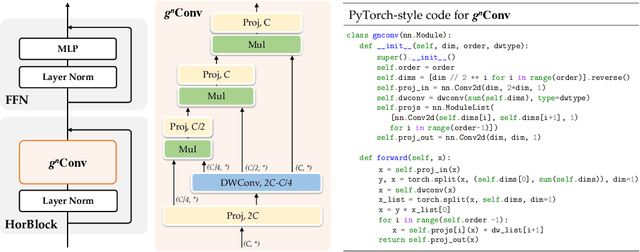
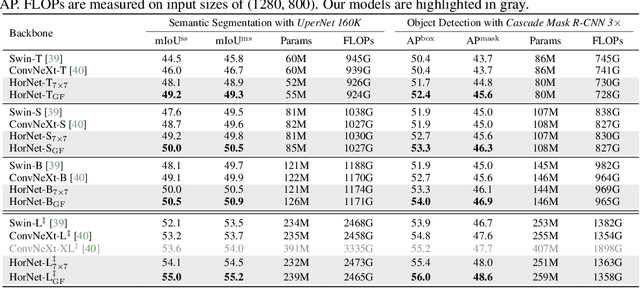
Recent progress in vision Transformers exhibits great success in various tasks driven by the new spatial modeling mechanism based on dot-product self-attention. In this paper, we show that the key ingredients behind the vision Transformers, namely input-adaptive, long-range and high-order spatial interactions, can also be efficiently implemented with a convolution-based framework. We present the Recursive Gated Convolution ($\textit{g}^\textit{n}$Conv) that performs high-order spatial interactions with gated convolutions and recursive designs. The new operation is highly flexible and customizable, which is compatible with various variants of convolution and extends the two-order interactions in self-attention to arbitrary orders without introducing significant extra computation. $\textit{g}^\textit{n}$Conv can serve as a plug-and-play module to improve various vision Transformers and convolution-based models. Based on the operation, we construct a new family of generic vision backbones named HorNet. Extensive experiments on ImageNet classification, COCO object detection and ADE20K semantic segmentation show HorNet outperform Swin Transformers and ConvNeXt by a significant margin with similar overall architecture and training configurations. HorNet also shows favorable scalability to more training data and a larger model size. Apart from the effectiveness in visual encoders, we also show $\textit{g}^\textit{n}$Conv can be applied to task-specific decoders and consistently improve dense prediction performance with less computation. Our results demonstrate that $\textit{g}^\textit{n}$Conv can be a new basic module for visual modeling that effectively combines the merits of both vision Transformers and CNNs. Code is available at https://github.com/raoyongming/HorNet
P2P: Tuning Pre-trained Image Models for Point Cloud Analysis with Point-to-Pixel Prompting
Aug 04, 2022
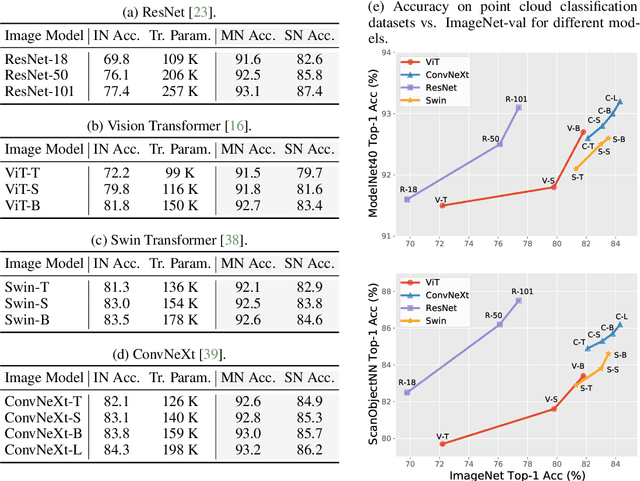
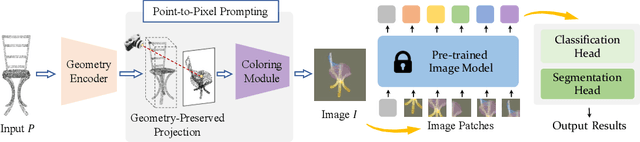
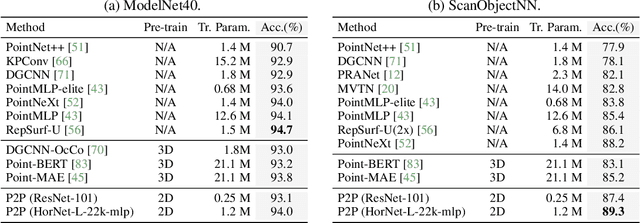
Nowadays, pre-training big models on large-scale datasets has become a crucial topic in deep learning. The pre-trained models with high representation ability and transferability achieve a great success and dominate many downstream tasks in natural language processing and 2D vision. However, it is non-trivial to promote such a pretraining-tuning paradigm to the 3D vision, given the limited training data that are relatively inconvenient to collect. In this paper, we provide a new perspective of leveraging pre-trained 2D knowledge in 3D domain to tackle this problem, tuning pre-trained image models with the novel Point-to-Pixel prompting for point cloud analysis at a minor parameter cost. Following the principle of prompting engineering, we transform point clouds into colorful images with geometry-preserved projection and geometry-aware coloring to adapt to pre-trained image models, whose weights are kept frozen during the end-to-end optimization of point cloud analysis tasks. We conduct extensive experiments to demonstrate that cooperating with our proposed Point-to-Pixel Prompting, better pre-trained image model will lead to consistently better performance in 3D vision. Enjoying prosperous development from image pre-training field, our method attains 89.3% accuracy on the hardest setting of ScanObjectNN, surpassing conventional point cloud models with much fewer trainable parameters. Our framework also exhibits very competitive performance on ModelNet classification and ShapeNet Part Segmentation. Code is available at https://github.com/wangzy22/P2P
Dynamic Spatial Sparsification for Efficient Vision Transformers and Convolutional Neural Networks
Jul 04, 2022
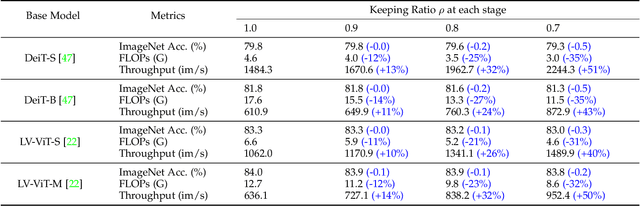
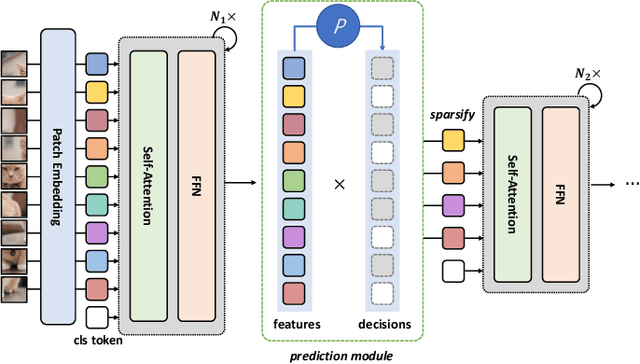
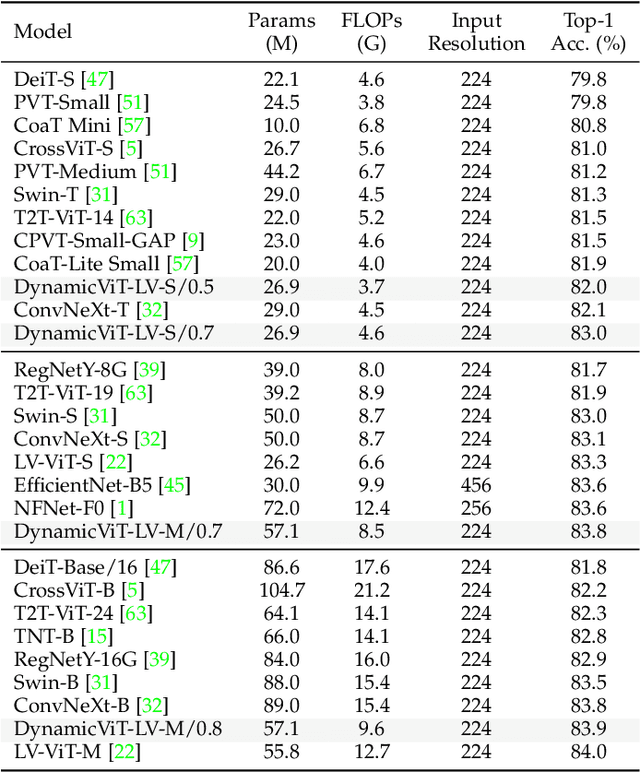
In this paper, we present a new approach for model acceleration by exploiting spatial sparsity in visual data. We observe that the final prediction in vision Transformers is only based on a subset of the most informative tokens, which is sufficient for accurate image recognition. Based on this observation, we propose a dynamic token sparsification framework to prune redundant tokens progressively and dynamically based on the input to accelerate vision Transformers. Specifically, we devise a lightweight prediction module to estimate the importance score of each token given the current features. The module is added to different layers to prune redundant tokens hierarchically. While the framework is inspired by our observation of the sparse attention in vision Transformers, we find the idea of adaptive and asymmetric computation can be a general solution for accelerating various architectures. We extend our method to hierarchical models including CNNs and hierarchical vision Transformers as well as more complex dense prediction tasks that require structured feature maps by formulating a more generic dynamic spatial sparsification framework with progressive sparsification and asymmetric computation for different spatial locations. By applying lightweight fast paths to less informative features and using more expressive slow paths to more important locations, we can maintain the structure of feature maps while significantly reducing the overall computations. Extensive experiments demonstrate the effectiveness of our framework on various modern architectures and different visual recognition tasks. Our results clearly demonstrate that dynamic spatial sparsification offers a new and more effective dimension for model acceleration. Code is available at https://github.com/raoyongming/DynamicViT
SemAffiNet: Semantic-Affine Transformation for Point Cloud Segmentation
May 26, 2022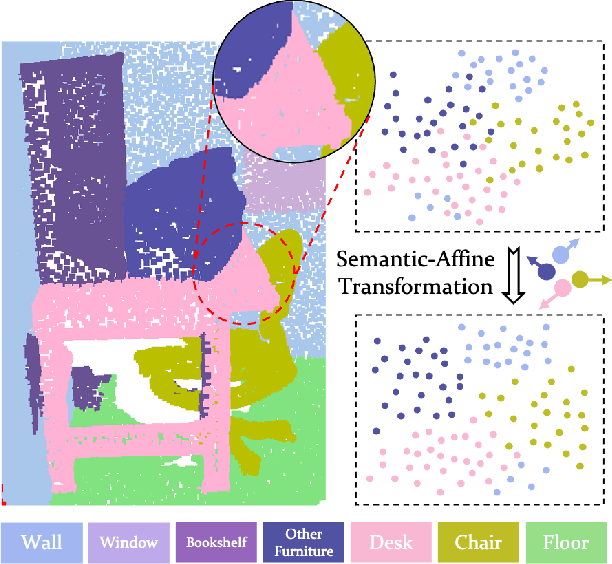
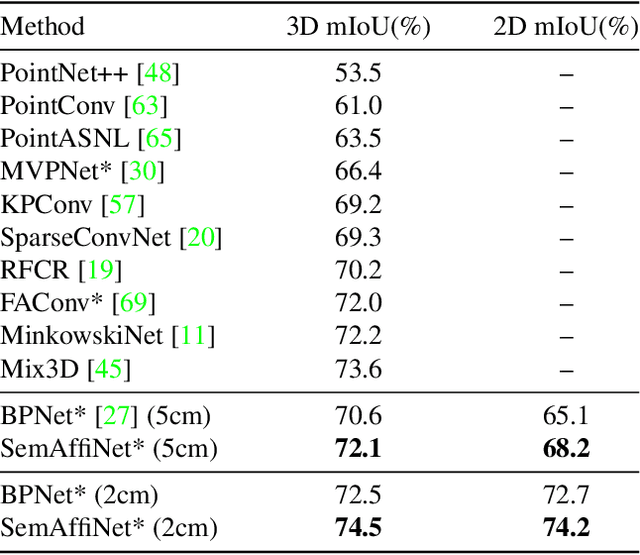
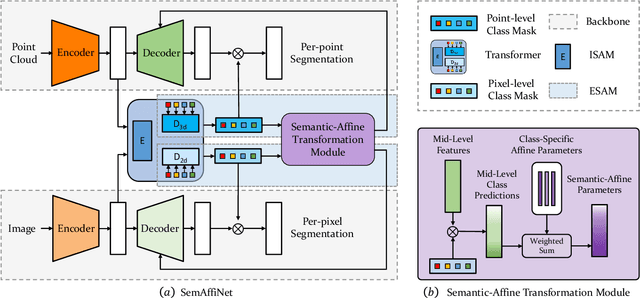
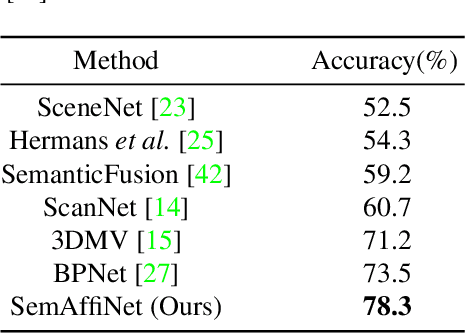
Conventional point cloud semantic segmentation methods usually employ an encoder-decoder architecture, where mid-level features are locally aggregated to extract geometric information. However, the over-reliance on these class-agnostic local geometric representations may raise confusion between local parts from different categories that are similar in appearance or spatially adjacent. To address this issue, we argue that mid-level features can be further enhanced with semantic information, and propose semantic-affine transformation that transforms features of mid-level points belonging to different categories with class-specific affine parameters. Based on this technique, we propose SemAffiNet for point cloud semantic segmentation, which utilizes the attention mechanism in the Transformer module to implicitly and explicitly capture global structural knowledge within local parts for overall comprehension of each category. We conduct extensive experiments on the ScanNetV2 and NYUv2 datasets, and evaluate semantic-affine transformation on various 3D point cloud and 2D image segmentation baselines, where both qualitative and quantitative results demonstrate the superiority and generalization ability of our proposed approach. Code is available at https://github.com/wangzy22/SemAffiNet.
FineDiving: A Fine-grained Dataset for Procedure-aware Action Quality Assessment
Apr 07, 2022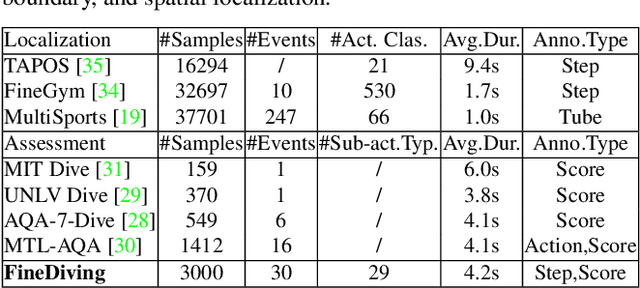
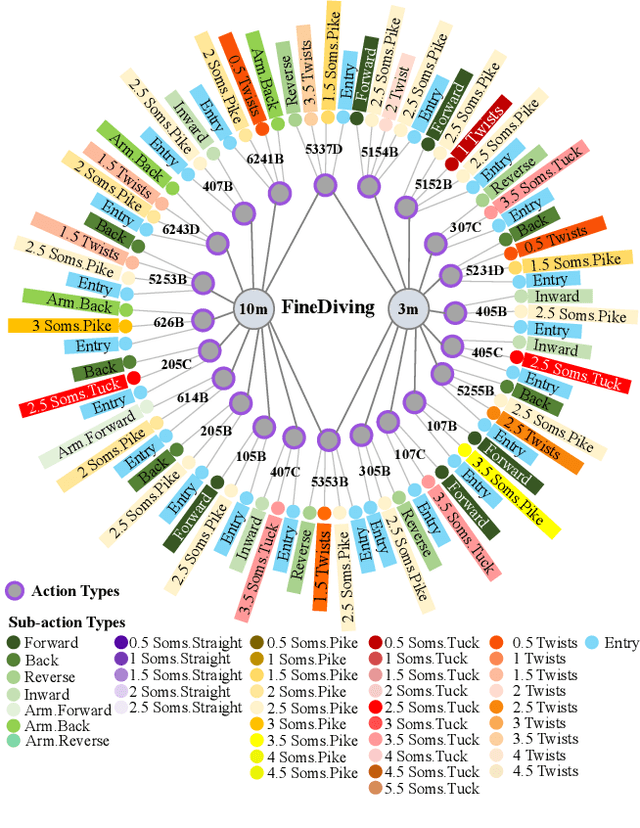
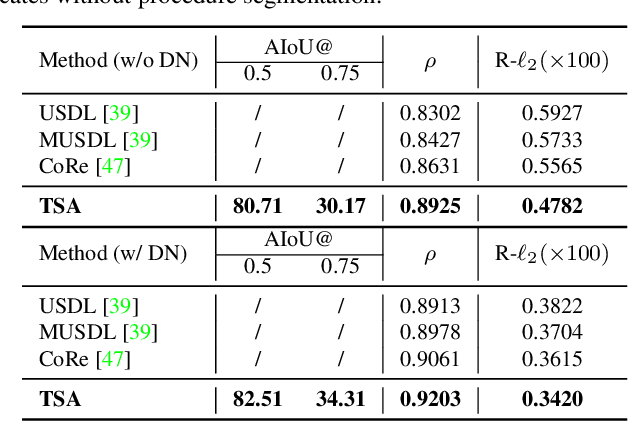
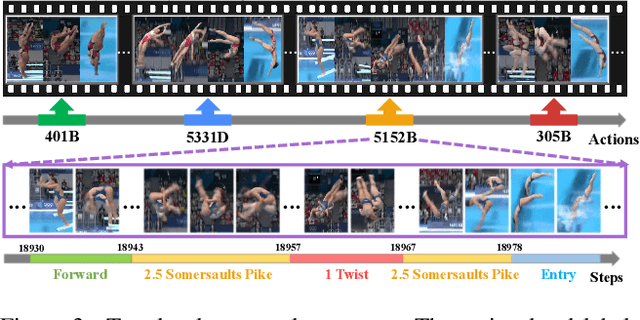
Most existing action quality assessment methods rely on the deep features of an entire video to predict the score, which is less reliable due to the non-transparent inference process and poor interpretability. We argue that understanding both high-level semantics and internal temporal structures of actions in competitive sports videos is the key to making predictions accurate and interpretable. Towards this goal, we construct a new fine-grained dataset, called FineDiving, developed on diverse diving events with detailed annotations on action procedures. We also propose a procedure-aware approach for action quality assessment, learned by a new Temporal Segmentation Attention module. Specifically, we propose to parse pairwise query and exemplar action instances into consecutive steps with diverse semantic and temporal correspondences. The procedure-aware cross-attention is proposed to learn embeddings between query and exemplar steps to discover their semantic, spatial, and temporal correspondences, and further serve for fine-grained contrastive regression to derive a reliable scoring mechanism. Extensive experiments demonstrate that our approach achieves substantial improvements over state-of-the-art methods with better interpretability. The dataset and code are available at \url{https://github.com/xujinglin/FineDiving}.
SurroundDepth: Entangling Surrounding Views for Self-Supervised Multi-Camera Depth Estimation
Apr 07, 2022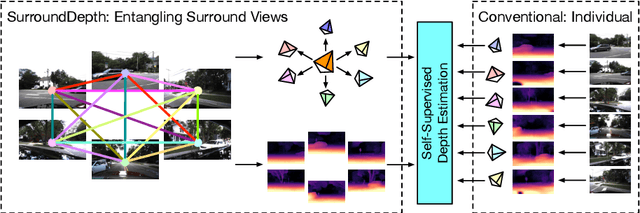
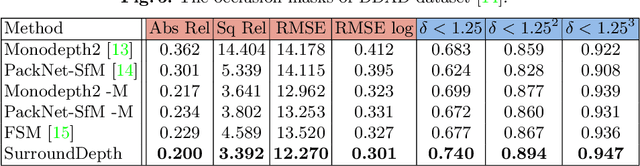
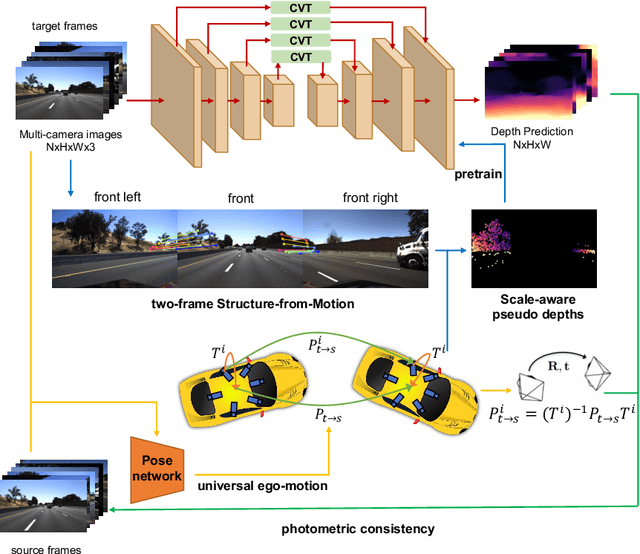

Depth estimation from images serves as the fundamental step of 3D perception for autonomous driving and is an economical alternative to expensive depth sensors like LiDAR. The temporal photometric consistency enables self-supervised depth estimation without labels, further facilitating its application. However, most existing methods predict the depth solely based on each monocular image and ignore the correlations among multiple surrounding cameras, which are typically available for modern self-driving vehicles. In this paper, we propose a SurroundDepth method to incorporate the information from multiple surrounding views to predict depth maps across cameras. Specifically, we employ a joint network to process all the surrounding views and propose a cross-view transformer to effectively fuse the information from multiple views. We apply cross-view self-attention to efficiently enable the global interactions between multi-camera feature maps. Different from self-supervised monocular depth estimation, we are able to predict real-world scales given multi-camera extrinsic matrices. To achieve this goal, we adopt structure-from-motion to extract scale-aware pseudo depths to pretrain the models. Further, instead of predicting the ego-motion of each individual camera, we estimate a universal ego-motion of the vehicle and transfer it to each view to achieve multi-view consistency. In experiments, our method achieves the state-of-the-art performance on the challenging multi-camera depth estimation datasets DDAD and nuScenes.