 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Test-time Adaptation via Adaptive Probabilistic Gaussian Calibration
Apr 21, 2026Multi-modal test-time adaptation (TTA) enhances the resilience of benchmark multi-modal models against distribution shifts by leveraging the unlabeled target data during inference. Despite the documented success, the advancement of multi-modal TTA methodologies has been impeded by a persistent limitation, i.e., the lack of explicit modeling of category-conditional distributions, which is crucial for yielding accurate predictions and reliable decision boundaries. Canonical Gaussian discriminant analysis (GDA) provides a vanilla modeling of category-conditional distributions and achieves moderate advancement in uni-modal contexts. However, in multi-modal TTA scenario, the inherent modality distribution asymmetry undermines the effectiveness of modeling the category-conditional distribution via the canonical GDA. To this end, we introduce a tailored probabilistic Gaussian model for multi-modal TTA to explicitly model the category-conditional distributions, and further propose an adaptive contrastive asymmetry rectification technique to counteract the adverse effects arising from modality asymmetry, thereby deriving calibrated predictions and reliable decision boundaries. Extensive experiments across diverse benchmarks demonstrate that our method achieves state-of-the-art performance under a wide range of distribution shifts. The code is available at https://github.com/XuJinglinn/AdaPGC.
WAT: Online Video Understanding Needs Watching Before Thinking
Mar 12, 2026Multimodal Large Language Models (MLLMs) have shown strong capabilities in image understanding, motivating recent efforts to extend them to video reasoning. However, existing Video LLMs struggle in online streaming scenarios, where long temporal context must be preserved under strict memory constraints. We propose WAT (Watching Before Thinking), a two-stage framework for online video reasoning. WAT separates processing into a query-independent watching stage and a query-triggered thinking stage. The watching stage builds a hierarchical memory system with a Short-Term Memory (STM) that buffers recent frames and a fixed-capacity Long-Term Memory (LTM) that maintains a diverse summary of historical content using a redundancy-aware eviction policy. In the thinking stage, a context-aware retrieval mechanism combines the query with the current STM context to retrieve relevant historical frames from the LTM for cross-temporal reasoning. To support training for online video tasks, we introduce WAT-85K, a dataset containing streaming-style annotations emphasizing real-time perception, backward tracing, and forecasting. Experiments show that WAT achieves state-of-the-art performance on online video benchmarks, including 77.7% accuracy on StreamingBench and 55.2% on OVO-Bench, outperforming existing open-source online Video LLMs while operating at real-time frame rates.
CausalFSFG: Rethinking Few-Shot Fine-Grained Visual Categorization from Causal Perspective
Dec 25, 2025Few-shot fine-grained visual categorization (FS-FGVC) focuses on identifying various subcategories within a common superclass given just one or few support examples. Most existing methods aim to boost classification accuracy by enriching the extracted features with discriminative part-level details. However, they often overlook the fact that the set of support samples acts as a confounding variable, which hampers the FS-FGVC performance by introducing biased data distribution and misguiding the extraction of discriminative features. To address this issue, we propose a new causal FS-FGVC (CausalFSFG) approach inspired by causal inference for addressing biased data distributions through causal intervention. Specifically, based on the structural causal model (SCM), we argue that FS-FGVC infers the subcategories (i.e., effect) from the inputs (i.e., cause), whereas both the few-shot condition disturbance and the inherent fine-grained nature (i.e., large intra-class variance and small inter-class variance) lead to unobservable variables that bring spurious correlations, compromising the final classification performance. To further eliminate the spurious correlations, our CausalFSFG approach incorporates two key components: (1) Interventional multi-scale encoder (IMSE) conducts sample-level interventions, (2) Interventional masked feature reconstruction (IMFR) conducts feature-level interventions, which together reveal real causalities from inputs to subcategories. Extensive experiments and thorough analyses on the widely-used public datasets, including CUB-200-2011, Stanford Dogs, and Stanford Cars, demonstrate that our CausalFSFG achieves new state-of-the-art performance. The code is available at https://github.com/PKU-ICST-MIPL/CausalFSFG_TMM.
DyFo: A Training-Free Dynamic Focus Visual Search for Enhancing LMMs in Fine-Grained Visual Understanding
Apr 21, 2025



Humans can effortlessly locate desired objects in cluttered environments, relying on a cognitive mechanism known as visual search to efficiently filter out irrelevant information and focus on task-related regions. Inspired by this process, we propose Dyfo (Dynamic Focus), a training-free dynamic focusing visual search method that enhances fine-grained visual understanding in large multimodal models (LMMs). Unlike existing approaches which require additional modules or data collection, Dyfo leverages a bidirectional interaction between LMMs and visual experts, using a Monte Carlo Tree Search (MCTS) algorithm to simulate human-like focus adjustments. This enables LMMs to focus on key visual regions while filtering out irrelevant content, without introducing additional training caused by vocabulary expansion or the integration of specialized localization modules. Experimental results demonstrate that Dyfo significantly improves fine-grained visual understanding and reduces hallucination issues in LMMs, achieving superior performance across both fixed and dynamic resolution models. The code is available at https://github.com/PKU-ICST-MIPL/DyFo_CVPR2025
Analyzing and Boosting the Power of Fine-Grained Visual Recognition for Multi-modal Large Language Models
Jan 25, 2025Multi-modal large language models (MLLMs) have shown remarkable abilities in various visual understanding tasks. However, MLLMs still struggle with fine-grained visual recognition (FGVR), which aims to identify subordinate-level categories from images. This can negatively impact more advanced capabilities of MLLMs, such as object-centric visual question answering and reasoning. In our study, we revisit three quintessential capabilities of MLLMs for FGVR, including object information extraction, category knowledge reserve, object-category alignment, and position of the root cause as a misalignment problem. To address this issue, we present Finedefics, an MLLM that enhances the model's FGVR capability by incorporating informative attribute descriptions of objects into the training phase. We employ contrastive learning on object-attribute pairs and attribute-category pairs simultaneously and use examples from similar but incorrect categories as hard negatives, naturally bringing representations of visual objects and category names closer. Extensive evaluations across multiple popular FGVR datasets demonstrate that Finedefics outperforms existing MLLMs of comparable parameter sizes, showcasing its remarkable efficacy. The code is available at https://github.com/PKU-ICST-MIPL/Finedefics_ICLR2025.
CountMamba: Exploring Multi-directional Selective State-Space Models for Plant Counting
Oct 10, 2024



Plant counting is essential in every stage of agriculture, including seed breeding, germination, cultivation, fertilization, pollination yield estimation, and harvesting. Inspired by the fact that humans count objects in high-resolution images by sequential scanning, we explore the potential of handling plant counting tasks via state space models (SSMs) for generating counting results. In this paper, we propose a new counting approach named CountMamba that constructs multiple counting experts to scan from various directions simultaneously. Specifically, we design a Multi-directional State-Space Group to process the image patch sequences in multiple orders and aim to simulate different counting experts. We also design Global-Local Adaptive Fusion to adaptively aggregate global features extracted from multiple directions and local features extracted from the CNN branch in a sample-wise manner. Extensive experiments demonstrate that the proposed CountMamba performs competitively on various plant counting tasks, including maize tassels, wheat ears, and sorghum head counting.
SIA-OVD: Shape-Invariant Adapter for Bridging the Image-Region Gap in Open-Vocabulary Detection
Oct 08, 2024



Open-vocabulary detection (OVD) aims to detect novel objects without instance-level annotations to achieve open-world object detection at a lower cost. Existing OVD methods mainly rely on the powerful open-vocabulary image-text alignment capability of Vision-Language Pretrained Models (VLM) such as CLIP. However, CLIP is trained on image-text pairs and lacks the perceptual ability for local regions within an image, resulting in the gap between image and region representations. Directly using CLIP for OVD causes inaccurate region classification. We find the image-region gap is primarily caused by the deformation of region feature maps during region of interest (RoI) extraction. To mitigate the inaccurate region classification in OVD, we propose a new Shape-Invariant Adapter named SIA-OVD to bridge the image-region gap in the OVD task. SIA-OVD learns a set of feature adapters for regions with different shapes and designs a new adapter allocation mechanism to select the optimal adapter for each region. The adapted region representations can align better with text representations learned by CLIP. Extensive experiments demonstrate that SIA-OVD effectively improves the classification accuracy for regions by addressing the gap between images and regions caused by shape deformation. SIA-OVD achieves substantial improvements over representative methods on the COCO-OVD benchmark. The code is available at https://github.com/PKU-ICST-MIPL/SIA-OVD_ACMMM2024.
FineParser: A Fine-grained Spatio-temporal Action Parser for Human-centric Action Quality Assessment
May 11, 2024Existing action quality assessment (AQA) methods mainly learn deep representations at the video level for scoring diverse actions. Due to the lack of a fine-grained understanding of actions in videos, they harshly suffer from low credibility and interpretability, thus insufficient for stringent applications, such as Olympic diving events. We argue that a fine-grained understanding of actions requires the model to perceive and parse actions in both time and space, which is also the key to the credibility and interpretability of the AQA technique. Based on this insight, we propose a new fine-grained spatial-temporal action parser named \textbf{FineParser}. It learns human-centric foreground action representations by focusing on target action regions within each frame and exploiting their fine-grained alignments in time and space to minimize the impact of invalid backgrounds during the assessment. In addition, we construct fine-grained annotations of human-centric foreground action masks for the FineDiving dataset, called \textbf{FineDiving-HM}. With refined annotations on diverse target action procedures, FineDiving-HM can promote the development of real-world AQA systems. Through extensive experiments, we demonstrate the effectiveness of FineParser, which outperforms state-of-the-art methods while supporting more tasks of fine-grained action understanding. Data and code are available at \url{https://github.com/PKU-ICST-MIPL/FineParser_CVPR2024}.
FinePOSE: Fine-Grained Prompt-Driven 3D Human Pose Estimation via Diffusion Models
May 08, 2024



The 3D Human Pose Estimation (3D HPE) task uses 2D images or videos to predict human joint coordinates in 3D space. Despite recent advancements in deep learning-based methods, they mostly ignore the capability of coupling accessible texts and naturally feasible knowledge of humans, missing out on valuable implicit supervision to guide the 3D HPE task. Moreover, previous efforts often study this task from the perspective of the whole human body, neglecting fine-grained guidance hidden in different body parts. To this end, we present a new Fine-Grained Prompt-Driven Denoiser based on a diffusion model for 3D HPE, named \textbf{FinePOSE}. It consists of three core blocks enhancing the reverse process of the diffusion model: (1) Fine-grained Part-aware Prompt learning (FPP) block constructs fine-grained part-aware prompts via coupling accessible texts and naturally feasible knowledge of body parts with learnable prompts to model implicit guidance. (2) Fine-grained Prompt-pose Communication (FPC) block establishes fine-grained communications between learned part-aware prompts and poses to improve the denoising quality. (3) Prompt-driven Timestamp Stylization (PTS) block integrates learned prompt embedding and temporal information related to the noise level to enable adaptive adjustment at each denoising step. Extensive experiments on public single-human pose estimation datasets show that FinePOSE outperforms state-of-the-art methods. We further extend FinePOSE to multi-human pose estimation. Achieving 34.3mm average MPJPE on the EgoHumans dataset demonstrates the potential of FinePOSE to deal with complex multi-human scenarios. Code is available at https://github.com/PKU-ICST-MIPL/FinePOSE_CVPR2024.
FineDiving: A Fine-grained Dataset for Procedure-aware Action Quality Assessment
Apr 07, 2022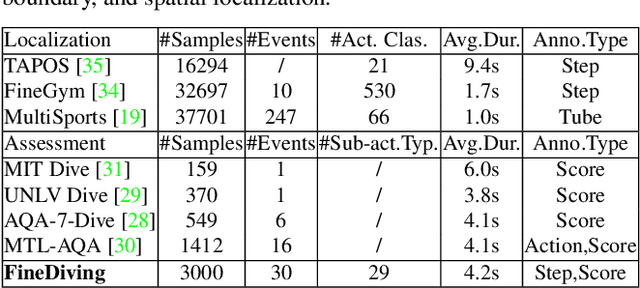
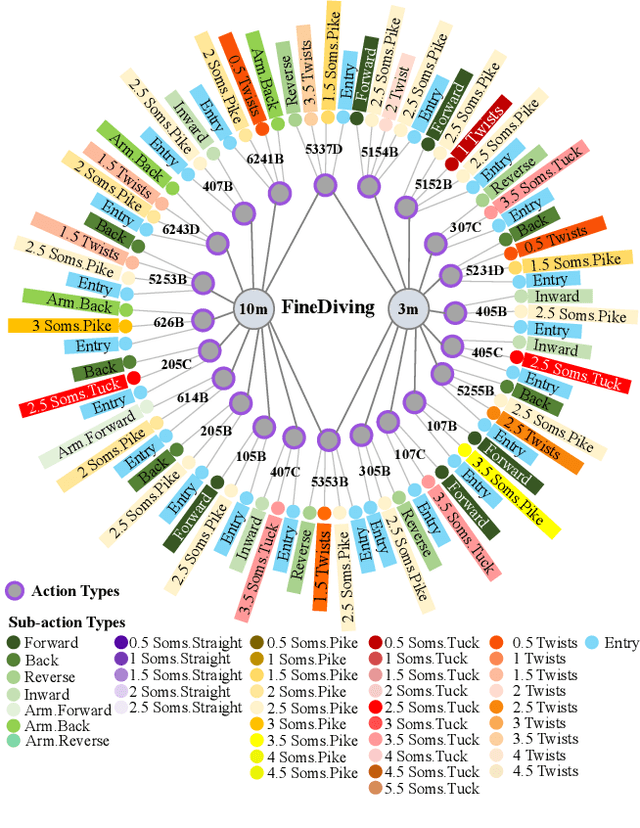
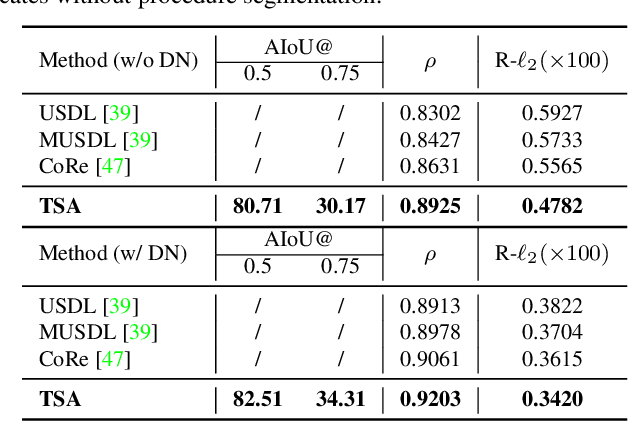
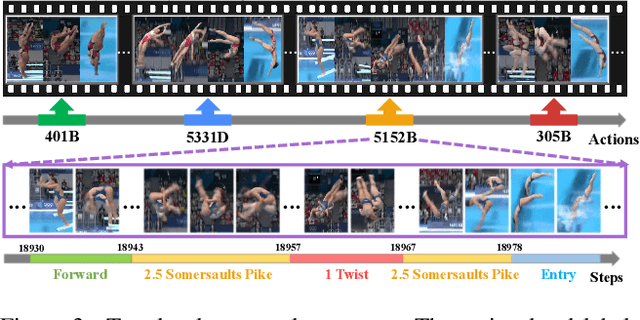
Most existing action quality assessment methods rely on the deep features of an entire video to predict the score, which is less reliable due to the non-transparent inference process and poor interpretability. We argue that understanding both high-level semantics and internal temporal structures of actions in competitive sports videos is the key to making predictions accurate and interpretable. Towards this goal, we construct a new fine-grained dataset, called FineDiving, developed on diverse diving events with detailed annotations on action procedures. We also propose a procedure-aware approach for action quality assessment, learned by a new Temporal Segmentation Attention module. Specifically, we propose to parse pairwise query and exemplar action instances into consecutive steps with diverse semantic and temporal correspondences. The procedure-aware cross-attention is proposed to learn embeddings between query and exemplar steps to discover their semantic, spatial, and temporal correspondences, and further serve for fine-grained contrastive regression to derive a reliable scoring mechanism. Extensive experiments demonstrate that our approach achieves substantial improvements over state-of-the-art methods with better interpretability. The dataset and code are available at \url{https://github.com/xujinglin/FineDiving}.