 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Apr 13, 2021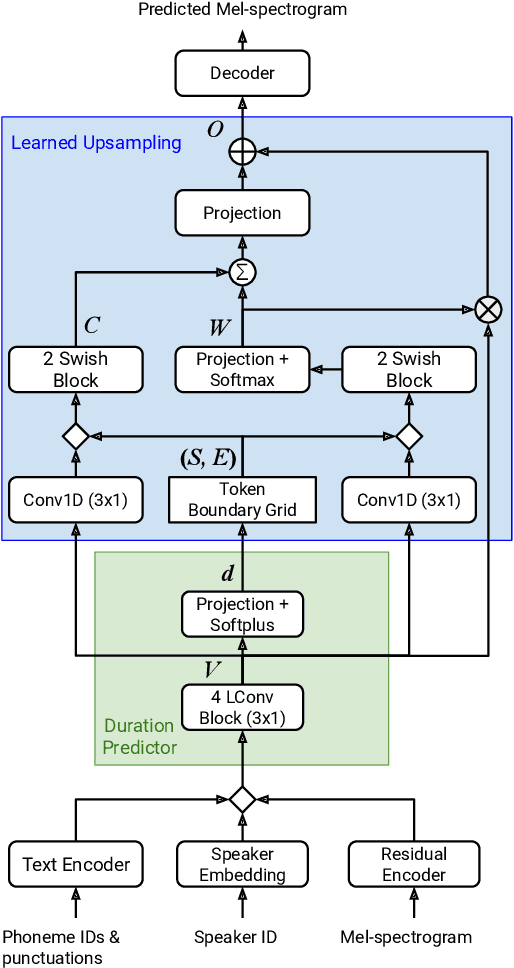
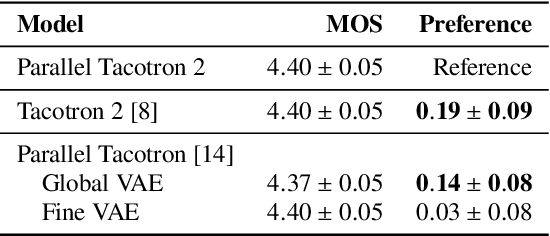
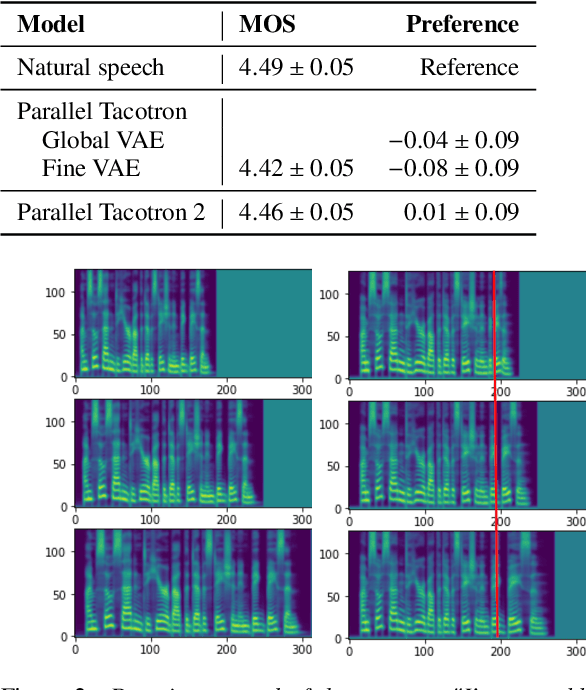

This paper introduces Parallel Tacotron 2, a non-autoregressive neural text-to-speech model with a fully differentiable duration model which does not require supervised duration signals. The duration model is based on a novel attention mechanism and an iterative reconstruction loss based on Soft Dynamic Time Warping, this model can learn token-frame alignments as well as token durations automatically. Experimental results show that Parallel Tacotron 2 outperforms baselines in subjective naturalness in several diverse multi speaker evaluations. Its duration control capability is also demonstrated.
PnG BERT: Augmented BERT on Phonemes and Graphemes for Neural TTS
Apr 02, 2021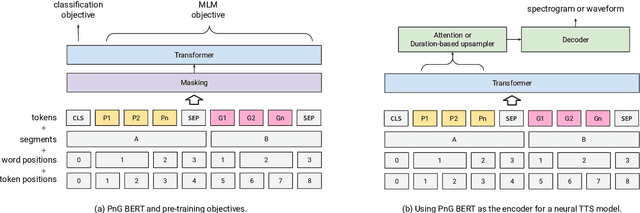
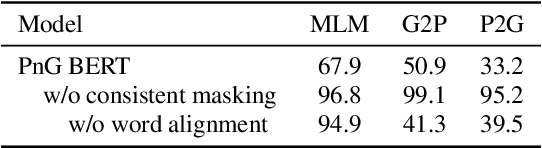
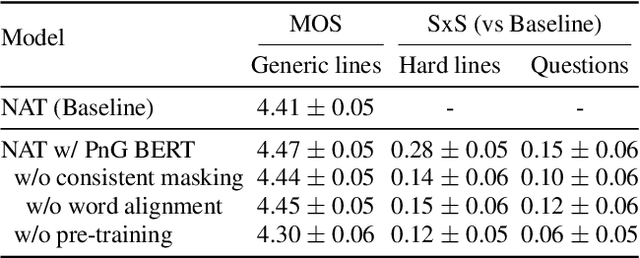
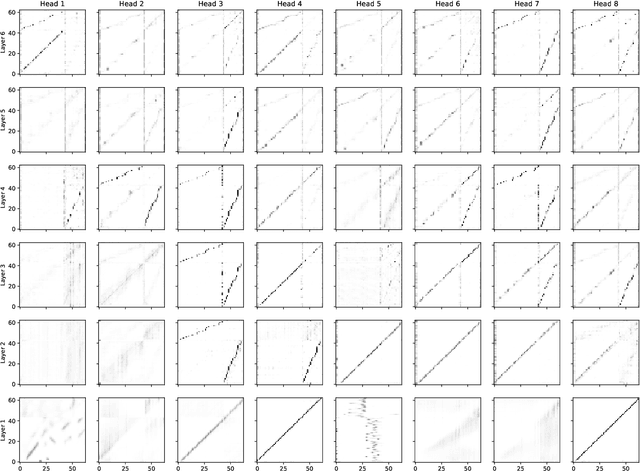
This paper introduces PnG BERT, a new encoder model for neural TTS. This model is augmented from the original BERT model, by taking both phoneme and grapheme representations of text as input, as well as the word-level alignment between them. It can be pre-trained on a large text corpus in a self-supervised manner, and fine-tuned in a TTS task. Experimental results show that a neural TTS model using a pre-trained PnG BERT as its encoder yields more natural prosody and more accurate pronunciation than a baseline model using only phoneme input with no pre-training. Subjective side-by-side preference evaluations show that raters have no statistically significant preference between the speech synthesized using a PnG BERT and ground truth recordings from professional speakers.
Improving Longer-range Dialogue State Tracking
Feb 27, 2021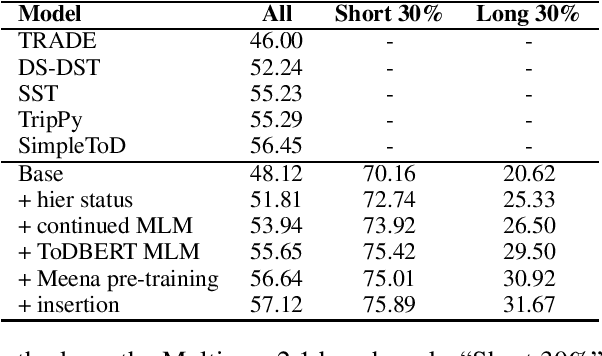
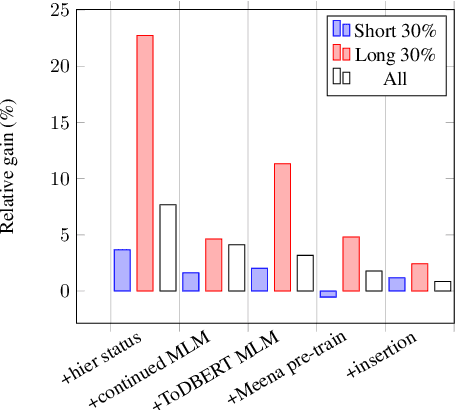
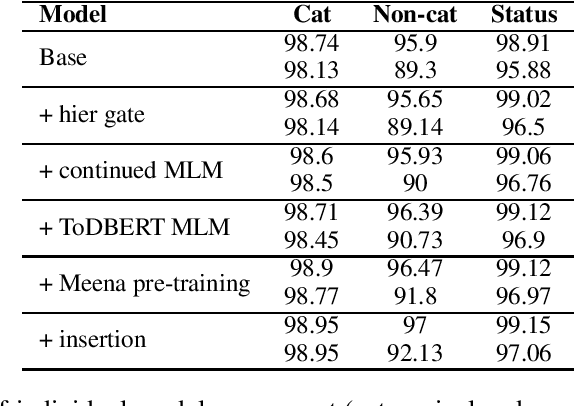

Dialogue state tracking (DST) is a pivotal component in task-oriented dialogue systems. While it is relatively easy for a DST model to capture belief states in short conversations, the task of DST becomes more challenging as the length of a dialogue increases due to the injection of more distracting contexts. In this paper, we aim to improve the overall performance of DST with a special focus on handling longer dialogues. We tackle this problem from three perspectives: 1) A model designed to enable hierarchical slot status prediction; 2) Balanced training procedure for generic and task-specific language understanding; 3) Data perturbation which enhances the model's ability in handling longer conversations. We conduct experiments on the MultiWOZ benchmark, and demonstrate the effectiveness of each component via a set of ablation tests, especially on longer conversations.
Distilling Interpretable Models into Human-Readable Code
Feb 09, 2021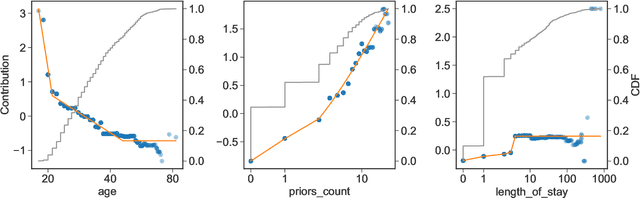
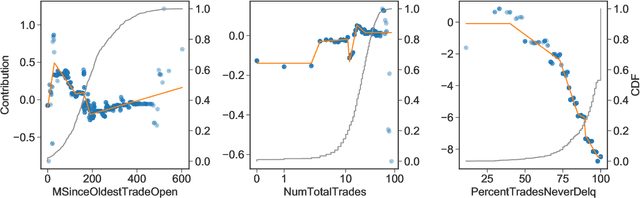
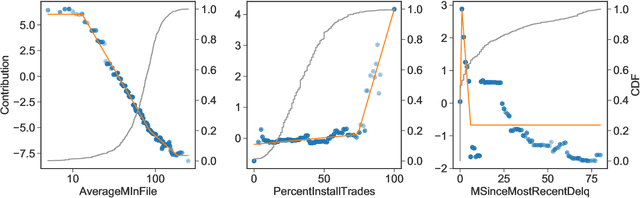
The goal of model distillation is to faithfully transfer teacher model knowledge to a model which is faster, more generalizable, more interpretable, or possesses other desirable characteristics. Human-readability is an important and desirable standard for machine-learned model interpretability. Readable models are transparent and can be reviewed, manipulated, and deployed like traditional source code. As a result, such models can be improved outside the context of machine learning and manually edited if desired. Given that directly training such models is difficult, we propose to train interpretable models using conventional methods, and then distill them into concise, human-readable code. The proposed distillation methodology approximates a model's univariate numerical functions with piecewise-linear curves in a localized manner. The resulting curve model representations are accurate, concise, human-readable, and well-regularized by construction. We describe a piecewise-linear curve-fitting algorithm that produces high-quality results efficiently and reliably across a broad range of use cases. We demonstrate the effectiveness of the overall distillation technique and our curve-fitting algorithm using four datasets across the tasks of classification, regression, and ranking.
FastEmit: Low-latency Streaming ASR with Sequence-level Emission Regularization
Oct 21, 2020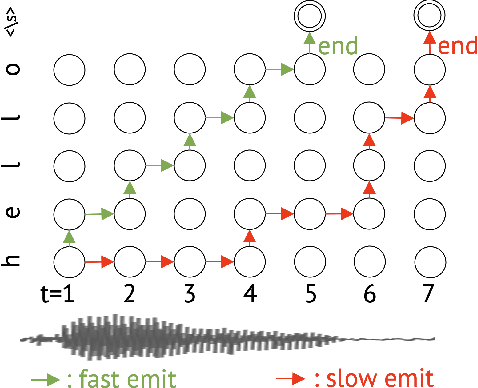
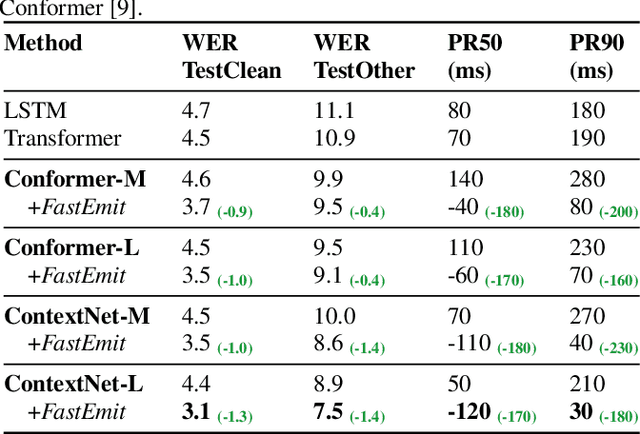

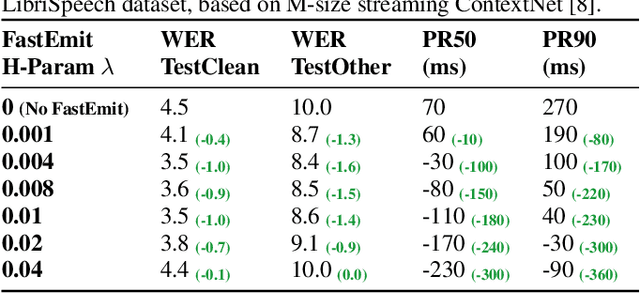
Streaming automatic speech recognition (ASR) aims to emit each hypothesized word as quickly and accurately as possible. However, emitting fast without degrading quality, as measured by word error rate (WER), is highly challenging. Existing approaches including Early and Late Penalties and Constrained Alignments penalize emission delay by manipulating per-token or per-frame probability prediction in sequence transducer models. While being successful in reducing delay, these approaches suffer from significant accuracy regression and also require additional word alignment information from an existing model. In this work, we propose a sequence-level emission regularization method, named FastEmit, that applies latency regularization directly on per-sequence probability in training transducer models, and does not require any alignment. We demonstrate that FastEmit is more suitable to the sequence-level optimization of transducer models for streaming ASR by applying it on various end-to-end streaming ASR networks including RNN-Transducer, Transformer-Transducer, ConvNet-Transducer and Conformer-Transducer. We achieve 150-300 ms latency reduction with significantly better accuracy over previous techniques on a Voice Search test set. FastEmit also improves streaming ASR accuracy from 4.4%/8.9% to 3.1%/7.5% WER, meanwhile reduces 90th percentile latency from 210 ms to only 30 ms on LibriSpeech.
Pushing the Limits of Semi-Supervised Learning for Automatic Speech Recognition
Oct 20, 2020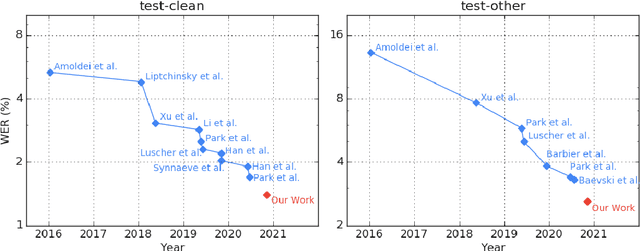

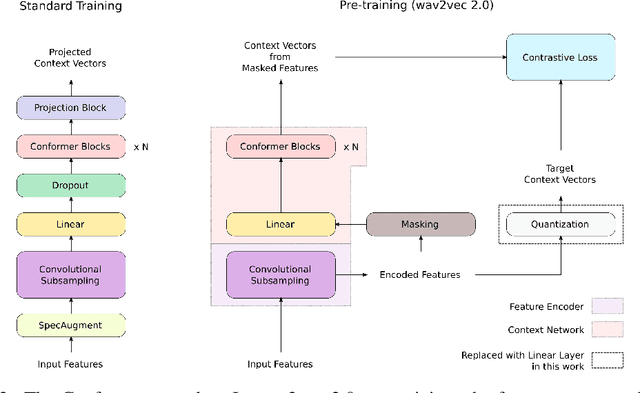
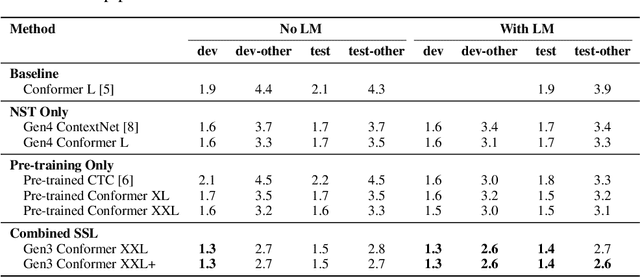
We employ a combination of recent developments in semi-supervised learning for automatic speech recognition to obtain state-of-the-art results on LibriSpeech utilizing the unlabeled audio of the Libri-Light dataset. More precisely, we carry out noisy student training with SpecAugment using giant Conformer models pre-trained using wav2vec 2.0 pre-training. By doing so, we are able to achieve word-error-rates (WERs) 1.4%/2.6% on the LibriSpeech test/test-other sets against the current state-of-the-art WERs 1.7%/3.3%.
Universal ASR: Unify and Improve Streaming ASR with Full-context Modeling
Oct 12, 2020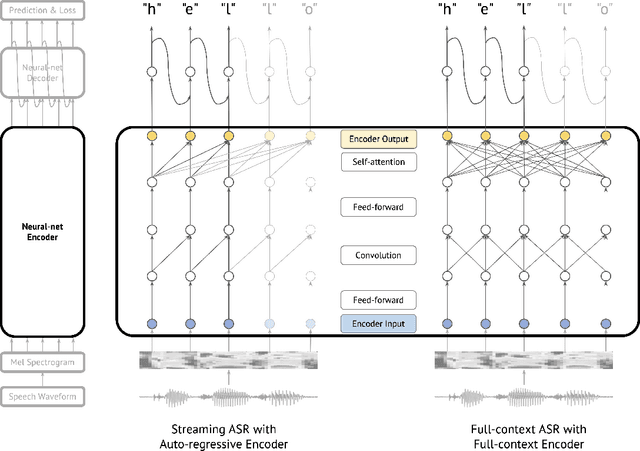
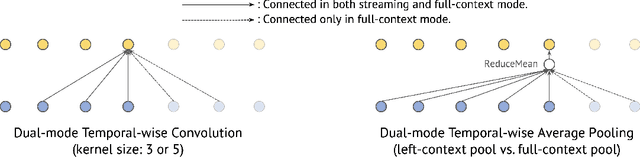
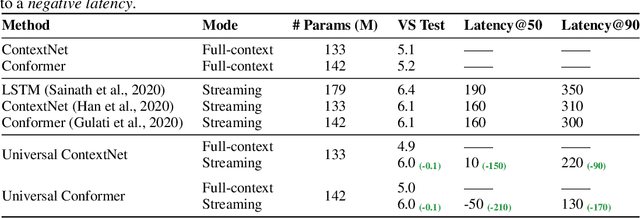
Streaming automatic speech recognition (ASR) aims to emit each hypothesized word as quickly and accurately as possible, while full-context ASR waits for the completion of a full speech utterance before emitting completed hypotheses. In this work, we propose a unified framework, Universal ASR, to train a single end-to-end ASR model with shared weights for both streaming and full-context speech recognition. We show that the latency and accuracy of streaming ASR significantly benefit from weight sharing and joint training of full-context ASR, especially with inplace knowledge distillation. The Universal ASR framework can be applied to recent state-of-the-art convolution-based and transformer-based ASR networks. We present extensive experiments with two state-of-the-art ASR networks, ContextNet and Conformer, on two datasets, a widely used public dataset LibriSpeech and an internal large-scale dataset MultiDomain. Experiments and ablation studies demonstrate that Universal ASR not only simplifies the workflow of training and deploying streaming and full-context ASR models, but also significantly improves both emission latency and recognition accuracy of streaming ASR. With Universal ASR, we achieve new state-of-the-art streaming ASR results on both LibriSpeech and MultiDomain in terms of accuracy and latency.
Non-Attentive Tacotron: Robust and Controllable Neural TTS Synthesis Including Unsupervised Duration Modeling
Oct 08, 2020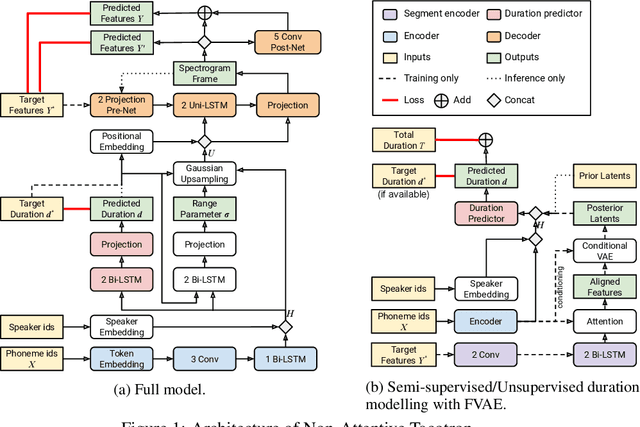

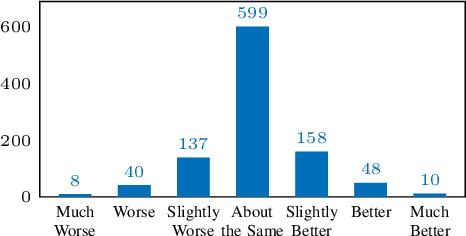

This paper presents Non-Attentive Tacotron based on the Tacotron 2 text-to-speech model, replacing the attention mechanism with an explicit duration predictor. This improves robustness significantly as measured by unaligned duration ratio and word deletion rate, two metrics introduced in this paper for large-scale robustness evaluation using a pre-trained speech recognition model. With the use of Gaussian upsampling, Non-Attentive Tacotron achieves a 5-scale mean opinion score for naturalness of 4.41, slightly outperforming Tacotron 2. The duration predictor enables both utterance-wide and per-phoneme control of duration at inference time. When accurate target durations are scarce or unavailable in the training data, we propose a method using a fine-grained variational auto-encoder to train the duration predictor in a semi-supervised or unsupervised manner, with results almost as good as supervised training.
Improved Noisy Student Training for Automatic Speech Recognition
May 19, 2020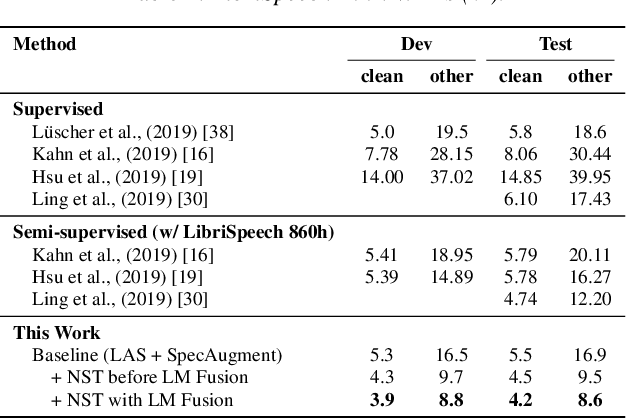
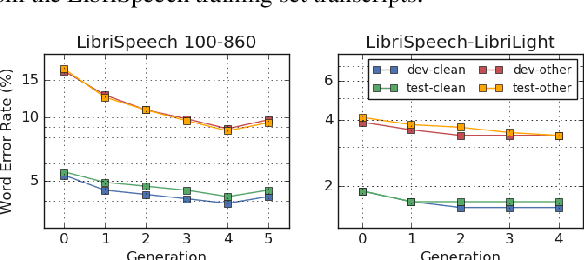
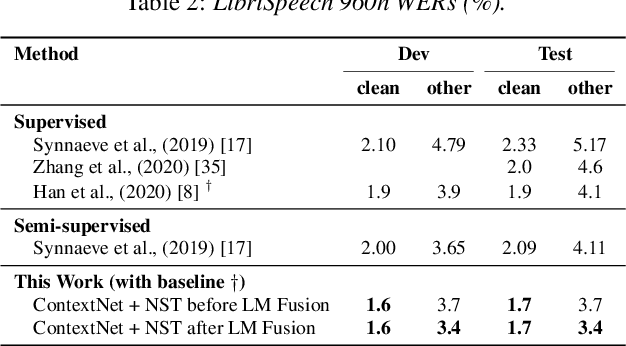
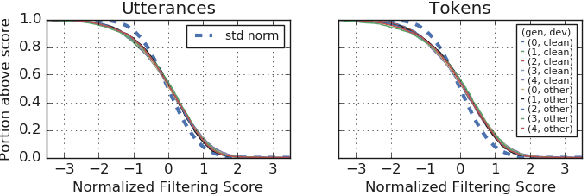
Recently, a semi-supervised learning method known as "noisy student training" has been shown to improve image classification performance of deep networks significantly. Noisy student training is an iterative self-training method that leverages augmentation to improve network performance. In this work, we adapt and improve noisy student training for automatic speech recognition, employing (adaptive) SpecAugment as the augmentation method. We find effective methods to filter, balance and augment the data generated in between self-training iterations. By doing so, we are able to obtain word error rates (WERs) 4.2%/8.6% on the clean/noisy LibriSpeech test sets by only using the clean 100h subset of LibriSpeech as the supervised set and the rest (860h) as the unlabeled set. Furthermore, we are able to achieve WERs 1.7%/3.4% on the clean/noisy LibriSpeech test sets by using the unlab-60k subset of LibriLight as the unlabeled set for LibriSpeech 960h. We are thus able to improve upon the previous state-of-the-art clean/noisy test WERs achieved on LibriSpeech 100h (4.74%/12.20%) and LibriSpeech (1.9%/4.1%).
RNN-T Models Fail to Generalize to Out-of-Domain Audio: Causes and Solutions
May 17, 2020
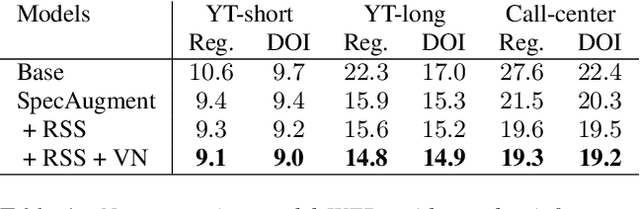
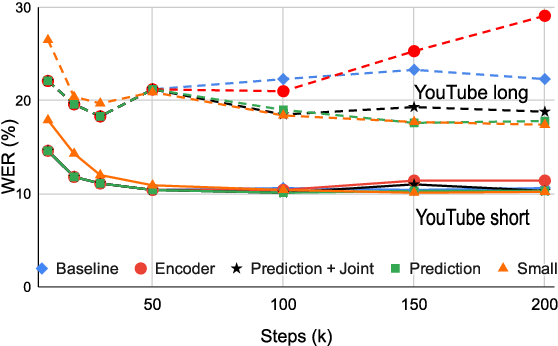
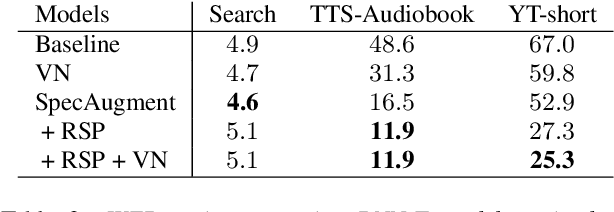
In recent years, all-neural end-to-end approaches have obtained state-of-the-art results on several challenging automatic speech recognition (ASR) tasks. However, most existing works focus on building ASR models where train and test data are drawn from the same domain. This results in poor generalization characteristics on mismatched-domains: e.g., end-to-end models trained on short segments perform poorly when evaluated on longer utterances. In this work, we analyze the generalization properties of streaming and non-streaming recurrent neural network transducer (RNN-T) based end-to-end models in order to identify model components that negatively affect generalization performance. We propose two solutions: combining multiple regularization techniques during training, and using dynamic overlapping inference. On a long-form YouTube test set, when the non-streaming RNN-T model is trained with shorter segments of data, the proposed combination improves word error rate (WER) from 22.3% to 14.8%; when the streaming RNN-T model trained on short Search queries, the proposed techniques improve WER on the YouTube set from 67.0% to 25.3%. Finally, when trained on Librispeech, we find that dynamic overlapping inference improves WER on YouTube from 99.8% to 33.0%.