 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIRT: Vision Instructed Transformer for Robotic Manipulation
Oct 09, 2024



Robotic manipulation, owing to its multi-modal nature, often faces significant training ambiguity, necessitating explicit instructions to clearly delineate the manipulation details in tasks. In this work, we highlight that vision instruction is naturally more comprehensible to recent robotic policies than the commonly adopted text instruction, as these policies are born with some vision understanding ability like human infants. Building on this premise and drawing inspiration from cognitive science, we introduce the robotic imagery paradigm, which realizes large-scale robotic data pre-training without text annotations. Additionally, we propose the robotic gaze strategy that emulates the human eye gaze mechanism, thereby guiding subsequent actions and focusing the attention of the policy on the manipulated object. Leveraging these innovations, we develop VIRT, a fully Transformer-based policy. We design comprehensive tasks using both a physical robot and simulated environments to assess the efficacy of VIRT. The results indicate that VIRT can complete very competitive tasks like ``opening the lid of a tightly sealed bottle'', and the proposed techniques boost the success rates of the baseline policy on diverse challenging tasks from nearly 0% to more than 65%.
Robust Loss Functions for Object Grasping under Limited Ground Truth
Sep 09, 2024Object grasping is a crucial technology enabling robots to perceive and interact with the environment sufficiently. However, in practical applications, researchers are faced with missing or noisy ground truth while training the convolutional neural network, which decreases the accuracy of the model. Therefore, different loss functions are proposed to deal with these problems to improve the accuracy of the neural network. For missing ground truth, a new predicted category probability method is defined for unlabeled samples, which works effectively in conjunction with the pseudo-labeling method. Furthermore, for noisy ground truth, a symmetric loss function is introduced to resist the corruption of label noises. The proposed loss functions are powerful, robust, and easy to use. Experimental results based on the typical grasping neural network show that our method can improve performance by 2 to 13 percent.
Variational Multi-Modal Hypergraph Attention Network for Multi-Modal Relation Extraction
Apr 18, 2024



Multi-modal relation extraction (MMRE) is a challenging task that aims to identify relations between entities in text leveraging image information. Existing methods are limited by their neglect of the multiple entity pairs in one sentence sharing very similar contextual information (ie, the same text and image), resulting in increased difficulty in the MMRE task. To address this limitation, we propose the Variational Multi-Modal Hypergraph Attention Network (VM-HAN) for multi-modal relation extraction. Specifically, we first construct a multi-modal hypergraph for each sentence with the corresponding image, to establish different high-order intra-/inter-modal correlations for different entity pairs in each sentence. We further design the Variational Hypergraph Attention Networks (V-HAN) to obtain representational diversity among different entity pairs using Gaussian distribution and learn a better hypergraph structure via variational attention. VM-HAN achieves state-of-the-art performance on the multi-modal relation extraction task, outperforming existing methods in terms of accuracy and efficiency.
Gotcha! Don't trick me with unanswerable questions! Self-aligning Large Language Models for Responding to Unknown Questions
Feb 23, 2024Despite the remarkable abilities of Large Language Models (LLMs) to answer questions, they often display a considerable level of overconfidence even when the question does not have a definitive answer. To avoid providing hallucinated answers to these unknown questions, existing studies typically investigate approaches to refusing to answer these questions. In this work, we propose a novel and scalable self-alignment method to utilize the LLM itself to enhance its response-ability to different types of unknown questions, being capable of not only refusing to answer but also providing explanation to the unanswerability of unknown questions. Specifically, the Self-Align method first employ a two-stage class-aware self-augmentation approach to generate a large amount of unknown question-response data. Then we conduct disparity-driven self-curation to select qualified data for fine-tuning the LLM itself for aligning the responses to unknown questions as desired. Experimental results on two datasets across four types of unknown questions validate the superiority of the Self-Align method over existing baselines in terms of three types of task formulation.
Conversational Crowdsensing: A Parallel Intelligence Powered Novel Sensing Approach
Feb 04, 2024The transition from CPS-based Industry 4.0 to CPSS-based Industry 5.0 brings new requirements and opportunities to current sensing approaches, especially in light of recent progress in Chatbots and Large Language Models (LLMs). Therefore, the advancement of parallel intelligence-powered Crowdsensing Intelligence (CSI) is witnessed, which is currently advancing towards linguistic intelligence. In this paper, we propose a novel sensing paradigm, namely conversational crowdsensing, for Industry 5.0. It can alleviate workload and professional requirements of individuals and promote the organization and operation of diverse workforce, thereby facilitating faster response and wider popularization of crowdsensing systems. Specifically, we design the architecture of conversational crowdsensing to effectively organize three types of participants (biological, robotic, and digital) from diverse communities. Through three levels of effective conversation (i.e., inter-human, human-AI, and inter-AI), complex interactions and service functionalities of different workers can be achieved to accomplish various tasks across three sensing phases (i.e., requesting, scheduling, and executing). Moreover, we explore the foundational technologies for realizing conversational crowdsensing, encompassing LLM-based multi-agent systems, scenarios engineering and conversational human-AI cooperation. Finally, we present potential industrial applications of conversational crowdsensing and discuss its implications. We envision that conversations in natural language will become the primary communication channel during crowdsensing process, enabling richer information exchange and cooperative problem-solving among humans, robots, and AI.
ONNXExplainer: an ONNX Based Generic Framework to Explain Neural Networks Using Shapley Values
Oct 03, 2023



Understanding why a neural network model makes certain decisions can be as important as the inference performance. Various methods have been proposed to help practitioners explain the prediction of a neural network model, of which Shapley values are most popular. SHAP package is a leading implementation of Shapley values to explain neural networks implemented in TensorFlow or PyTorch but lacks cross-platform support, one-shot deployment and is highly inefficient. To address these problems, we present the ONNXExplainer, which is a generic framework to explain neural networks using Shapley values in the ONNX ecosystem. In ONNXExplainer, we develop its own automatic differentiation and optimization approach, which not only enables One-Shot Deployment of neural networks inference and explanations, but also significantly improves the efficiency to compute explanation with less memory consumption. For fair comparison purposes, we also implement the same optimization in TensorFlow and PyTorch and measure its performance against the current state of the art open-source counterpart, SHAP. Extensive benchmarks demonstrate that the proposed optimization approach improves the explanation latency of VGG19, ResNet50, DenseNet201, and EfficientNetB0 by as much as 500%.
Improving Transformer-based Networks With Locality For Automatic Speaker Verification
Feb 28, 2023



Recently, Transformer-based architectures have been explored for speaker embedding extraction. Although the Transformer employs the self-attention mechanism to efficiently model the global interaction between token embeddings, it is inadequate for capturing short-range local context, which is essential for the accurate extraction of speaker information. In this study, we enhance the Transformer with the enhanced locality modeling in two directions. First, we propose the Locality-Enhanced Conformer (LE-Confomer) by introducing depth-wise convolution and channel-wise attention into the Conformer blocks. Second, we present the Speaker Swin Transformer (SST) by adapting the Swin Transformer, originally proposed for vision tasks, into speaker embedding network. We evaluate the proposed approaches on the VoxCeleb datasets and a large-scale Microsoft internal multilingual (MS-internal) dataset. The proposed models achieve 0.75% EER on VoxCeleb 1 test set, outperforming the previously proposed Transformer-based models and CNN-based models, such as ResNet34 and ECAPA-TDNN. When trained on the MS-internal dataset, the proposed models achieve promising results with 14.6% relative reduction in EER over the Res2Net50 model.
Learnable Blur Kernel for Single-Image Defocus Deblurring in the Wild
Nov 25, 2022Recent research showed that the dual-pixel sensor has made great progress in defocus map estimation and image defocus deblurring. However, extracting real-time dual-pixel views is troublesome and complex in algorithm deployment. Moreover, the deblurred image generated by the defocus deblurring network lacks high-frequency details, which is unsatisfactory in human perception. To overcome this issue, we propose a novel defocus deblurring method that uses the guidance of the defocus map to implement image deblurring. The proposed method consists of a learnable blur kernel to estimate the defocus map, which is an unsupervised method, and a single-image defocus deblurring generative adversarial network (DefocusGAN) for the first time. The proposed network can learn the deblurring of different regions and recover realistic details. We propose a defocus adversarial loss to guide this training process. Competitive experimental results confirm that with a learnable blur kernel, the generated defocus map can achieve results comparable to supervised methods. In the single-image defocus deblurring task, the proposed method achieves state-of-the-art results, especially significant improvements in perceptual quality, where PSNR reaches 25.56 dB and LPIPS reaches 0.111.
Physics Guided Generative Adversarial Networks for Generations of Crystal Materials with Symmetry Constraints
Mar 27, 2022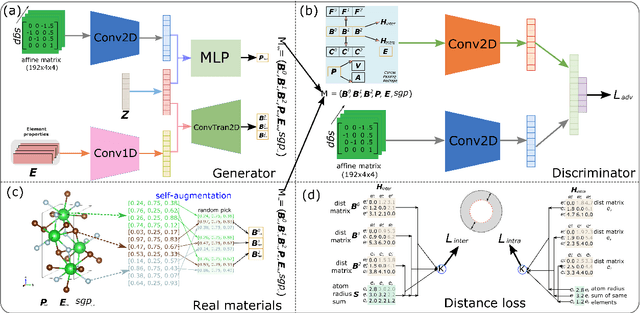
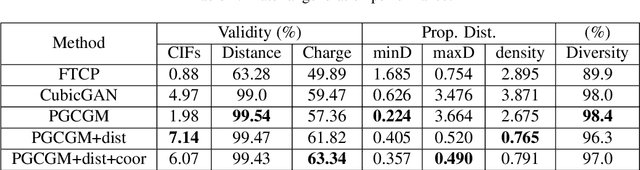

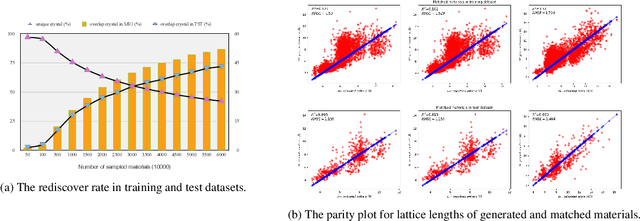
Discovering new materials is a long-standing challenging task that is critical to the progress of human society. Conventional approaches such as trial-and-error experiments and computational simulations are labor-intensive or costly with their success heavily depending on experts' heuristics. Recently deep generative models have been successfully proposed for materials generation by learning implicit knowledge from known materials datasets, with performance however limited by their confinement to a special material family or failing to incorporate physical rules into the model training process. Here we propose a Physics Guided Crystal Generative Model (PGCGM) for new materials generation, which captures and exploits the pairwise atomic distance constraints among neighbor atoms and symmetric geometric constraints. By augmenting the base atom sites of materials, our model can generates new materials of 20 space groups. With atom clustering and merging on generated crystal structures, our method increases the generator's validity by 8 times compared to one of the baselines and by 143\% compared to the previous CubicGAN along with its superiority in properties distribution and diversity. We further validated our generated candidates by Density Functional Theory (DFT) calculation, which successfully optimized/relaxed 1869 materials out of 2000, of which 39.6\% are with negative formation energy, indicating their stability.
Semi-supervised teacher-student deep neural network for materials discovery
Dec 12, 2021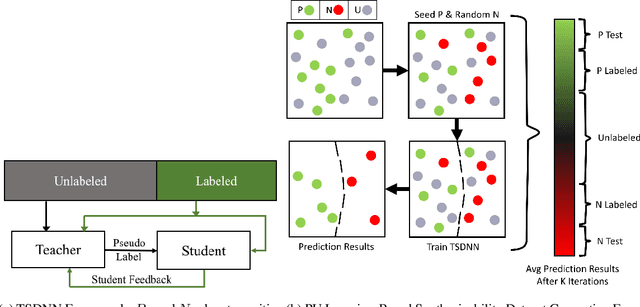
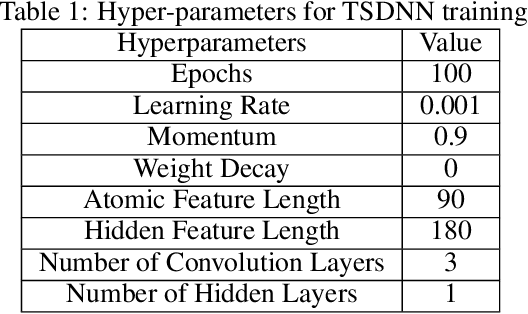


Data driven generative machine learning models have recently emerged as one of the most promising approaches for new materials discovery. While the generator models can generate millions of candidates, it is critical to train fast and accurate machine learning models to filter out stable, synthesizable materials with desired properties. However, such efforts to build supervised regression or classification screening models have been severely hindered by the lack of unstable or unsynthesizable samples, which usually are not collected and deposited in materials databases such as ICSD and Materials Project (MP). At the same time, there are a significant amount of unlabelled data available in these databases. Here we propose a semi-supervised deep neural network (TSDNN) model for high-performance formation energy and synthesizability prediction, which is achieved via its unique teacher-student dual network architecture and its effective exploitation of the large amount of unlabeled data. For formation energy based stability screening, our semi-supervised classifier achieves an absolute 10.3\% accuracy improvement compared to the baseline CGCNN regression model. For synthesizability prediction, our model significantly increases the baseline PU learning's true positive rate from 87.9\% to 97.9\% using 1/49 model parameters. To further prove the effectiveness of our models, we combined our TSDNN-energy and TSDNN-synthesizability models with our CubicGAN generator to discover novel stable cubic structures. Out of 1000 recommended candidate samples by our models, 512 of them have negative formation energies as validated by our DFT formation energy calculations. Our experimental results show that our semi-supervised deep neural networks can significantly improve the screening accuracy in large-scale generative materials design.