 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Channel Intragroup Sparsity Neural Network
Paper and Code
Oct 26, 2019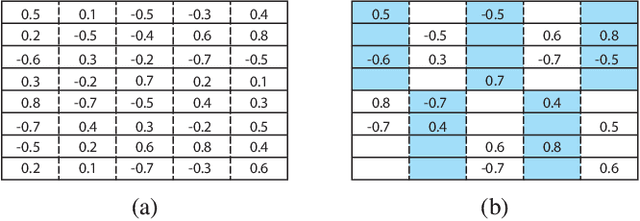
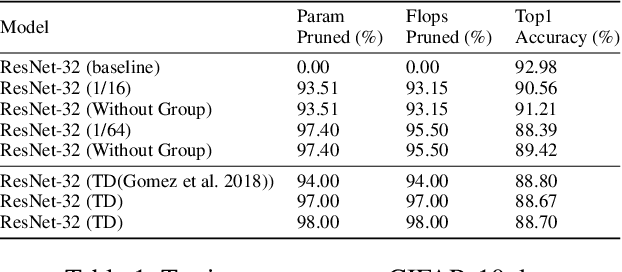
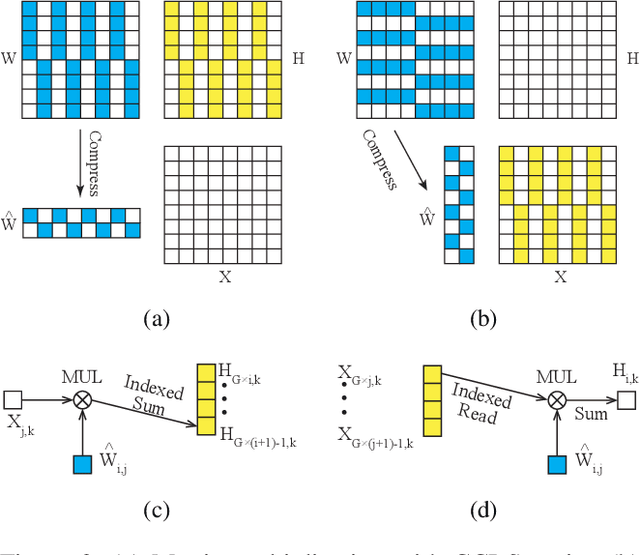
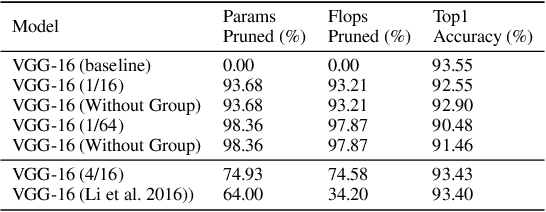
Modern deep neural network models generally build upon heavy over-parameterization for their exceptional performance. Network pruning is one often employed approach to obtain less demanding models for their deployment. Fine-grained pruning, while can achieve good model compression ratio, introduces irregularity in the computing data flow, often does not give improved model inference efficiency. Coarse-grained model pruning, while allows good inference speed through removing network weights in whole groups, for example, a whole filter, can lead to significant model performance deterioration. In this study, we introduce the cross-channel intragroup (CCI) sparsity structure that can avoid the inference inefficiency of fine-grained pruning while maintaining outstanding model performance.