 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining Scaling and Transfer of Language Model Architectures for Machine Translation
Feb 16, 2022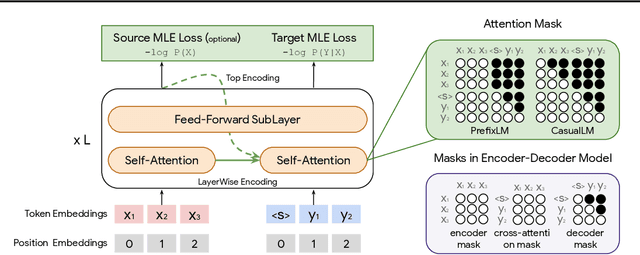

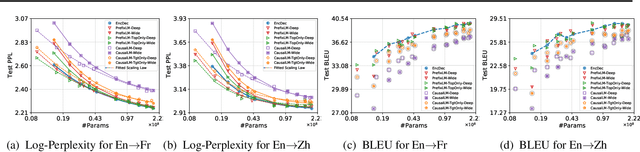
Natural language understanding and generation models follow one of the two dominant architectural paradigms: language models (LMs) that process concatenated sequences in a single stack of layers, and encoder-decoder models (EncDec) that utilize separate layer stacks for input and output processing. In machine translation, EncDec has long been the favoured approach, but with few studies investigating the performance of LMs. In this work, we thoroughly examine the role of several architectural design choices on the performance of LMs on bilingual, (massively) multilingual and zero-shot translation tasks, under systematic variations of data conditions and model sizes. Our results show that: (i) Different LMs have different scaling properties, where architectural differences often have a significant impact on model performance at small scales, but the performance gap narrows as the number of parameters increases, (ii) Several design choices, including causal masking and language-modeling objectives for the source sequence, have detrimental effects on translation quality, and (iii) When paired with full-visible masking for source sequences, LMs could perform on par with EncDec on supervised bilingual and multilingual translation tasks, and improve greatly on zero-shot directions by facilitating the reduction of off-target translations.
mSLAM: Massively multilingual joint pre-training for speech and text
Feb 03, 2022



We present mSLAM, a multilingual Speech and LAnguage Model that learns cross-lingual cross-modal representations of speech and text by pre-training jointly on large amounts of unlabeled speech and text in multiple languages. mSLAM combines w2v-BERT pre-training on speech with SpanBERT pre-training on character-level text, along with Connectionist Temporal Classification (CTC) losses on paired speech and transcript data, to learn a single model capable of learning from and representing both speech and text signals in a shared representation space. We evaluate mSLAM on several downstream speech understanding tasks and find that joint pre-training with text improves quality on speech translation, speech intent classification and speech language-ID while being competitive on multilingual ASR, when compared against speech-only pre-training. Our speech translation model demonstrates zero-shot text translation without seeing any text translation data, providing evidence for cross-modal alignment of representations. mSLAM also benefits from multi-modal fine-tuning, further improving the quality of speech translation by directly leveraging text translation data during the fine-tuning process. Our empirical analysis highlights several opportunities and challenges arising from large-scale multimodal pre-training, suggesting directions for future research.
Self-supervised and Supervised Joint Training for Resource-rich Machine Translation
Jun 08, 2021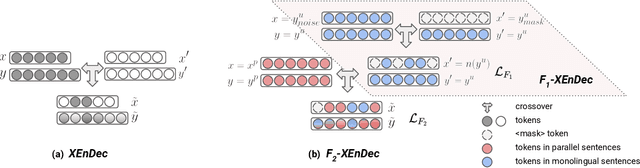

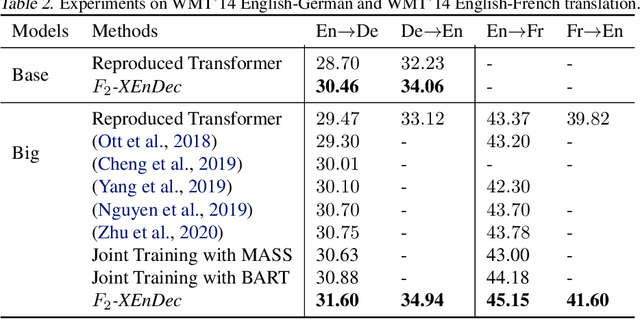
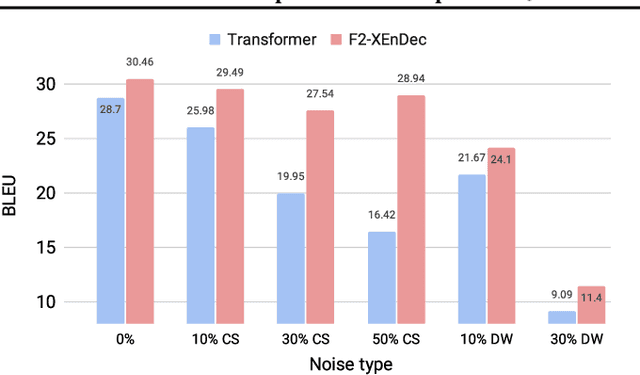
Self-supervised pre-training of text representations has been successfully applied to low-resource Neural Machine Translation (NMT). However, it usually fails to achieve notable gains on resource-rich NMT. In this paper, we propose a joint training approach, $F_2$-XEnDec, to combine self-supervised and supervised learning to optimize NMT models. To exploit complementary self-supervised signals for supervised learning, NMT models are trained on examples that are interbred from monolingual and parallel sentences through a new process called crossover encoder-decoder. Experiments on two resource-rich translation benchmarks, WMT'14 English-German and WMT'14 English-French, demonstrate that our approach achieves substantial improvements over several strong baseline methods and obtains a new state of the art of 46.19 BLEU on English-French when incorporating back translation. Results also show that our approach is capable of improving model robustness to input perturbations such as code-switching noise which frequently appears on social media.
AdvAug: Robust Adversarial Augmentation for Neural Machine Translation
Jul 03, 2020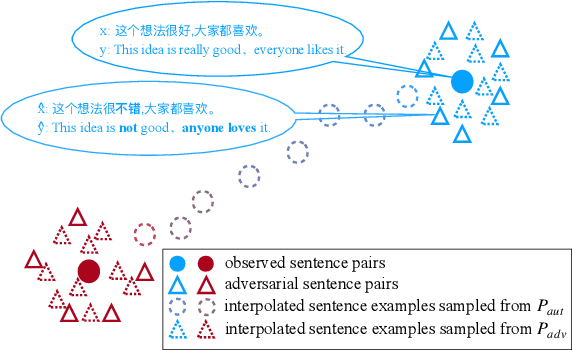
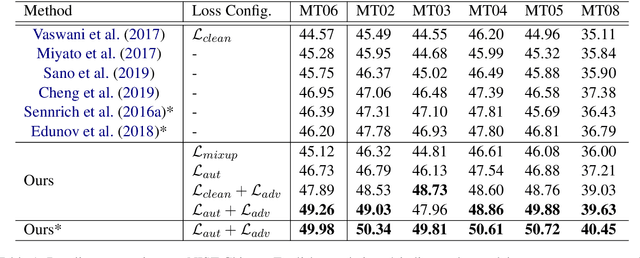
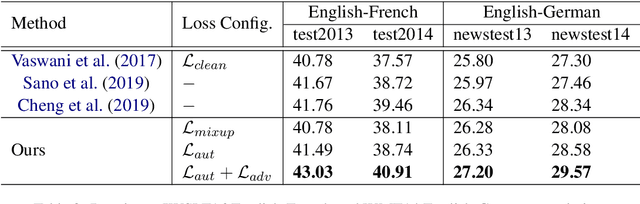
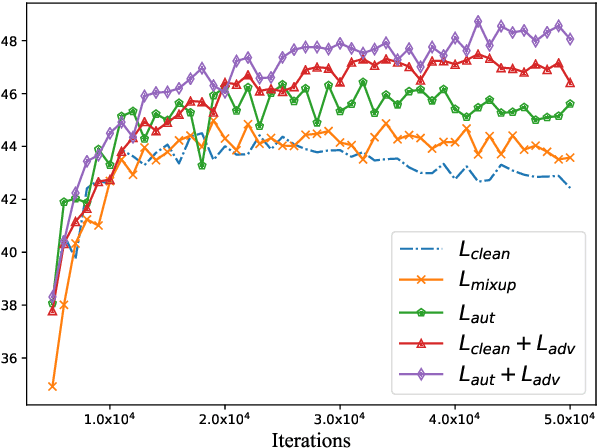
In this paper, we propose a new adversarial augmentation method for Neural Machine Translation (NMT). The main idea is to minimize the vicinal risk over virtual sentences sampled from two vicinity distributions, of which the crucial one is a novel vicinity distribution for adversarial sentences that describes a smooth interpolated embedding space centered around observed training sentence pairs. We then discuss our approach, AdvAug, to train NMT models using the embeddings of virtual sentences in sequence-to-sequence learning. Experiments on Chinese-English, English-French, and English-German translation benchmarks show that AdvAug achieves significant improvements over the Transformer (up to 4.9 BLEU points), and substantially outperforms other data augmentation techniques (e.g. back-translation) without using extra corpora.
Learning to Detect Malicious Clients for Robust Federated Learning
Feb 01, 2020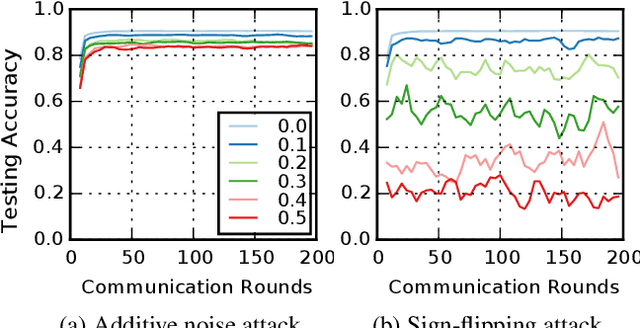
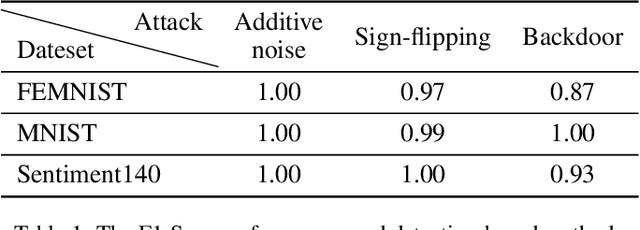
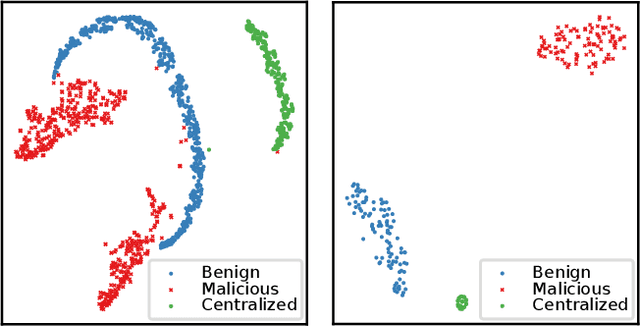
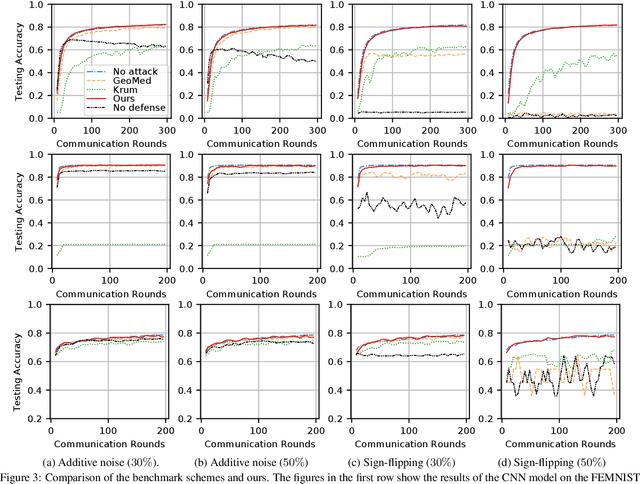
Federated learning systems are vulnerable to attacks from malicious clients. As the central server in the system cannot govern the behaviors of the clients, a rogue client may initiate an attack by sending malicious model updates to the server, so as to degrade the learning performance or enforce targeted model poisoning attacks (a.k.a. backdoor attacks). Therefore, timely detecting these malicious model updates and the underlying attackers becomes critically important. In this work, we propose a new framework for robust federated learning where the central server learns to detect and remove the malicious model updates using a powerful detection model, leading to targeted defense. We evaluate our solution in both image classification and sentiment analysis tasks with a variety of machine learning models. Experimental results show that our solution ensures robust federated learning that is resilient to both the Byzantine attacks and the targeted model poisoning attacks.
A Communication Efficient Vertical Federated Learning Framework
Dec 27, 2019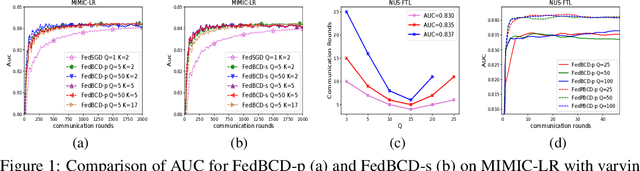
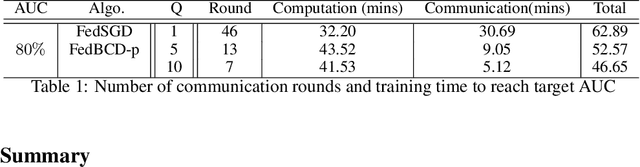
One critical challenge for applying today's Artificial Intelligence (AI) technologies to real-world applications is the common existence of data silos across different organizations. Due to legal, privacy and other practical constraints, data from different organizations cannot be easily integrated. Federated learning (FL), especially the vertical FL (VFL), allows multiple parties having different sets of attributes about the same user collaboratively build models while preserving user privacy. However, communication overhead is a principal bottleneck since the existing VFL protocols require per-iteration communications among all parties. In this paper, we propose the Federated Stochastic Block Coordinate Descent (FedBCD) to effectively reduce the communication rounds for VFL. We show that when the batch size, sample size, and the local iterations are selected appropriately, the algorithm requires $\mathcal{O}(\sqrt{T})$ communication rounds to achieve $\mathcal{O}(1/\sqrt{T})$ accuracy. Finally, we demonstrate the performance of FedBCD on several models and datasets, and on a large-scale industrial platform for VFL.
Abnormal Client Behavior Detection in Federated Learning
Oct 22, 2019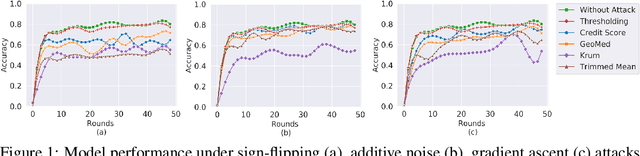
In federated learning systems, clients are autonomous in that their behaviors are not fully governed by the server. Consequently, a client may intentionally or unintentionally deviate from the prescribed course of federated model training, resulting in abnormal behaviors, such as turning into a malicious attacker or a malfunctioning client. Timely detecting those anomalous clients is therefore critical to minimize their adverse impacts. In this work, we propose to detect anomalous clients at the server side. In particular, we generate low-dimensional surrogates of model weight vectors and use them to perform anomaly detection. We evaluate our solution through experiments on image classification model training over the FEMNIST dataset. Experimental results show that the proposed detection-based approach significantly outperforms the conventional defense-based methods.
Robust Neural Machine Translation with Doubly Adversarial Inputs
Jun 06, 2019
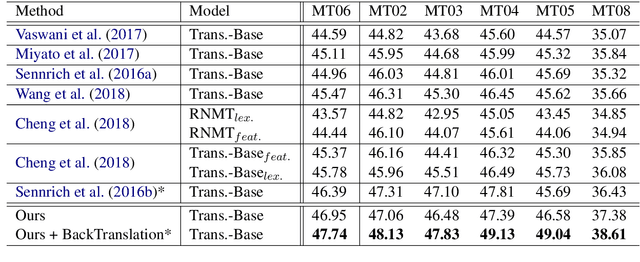

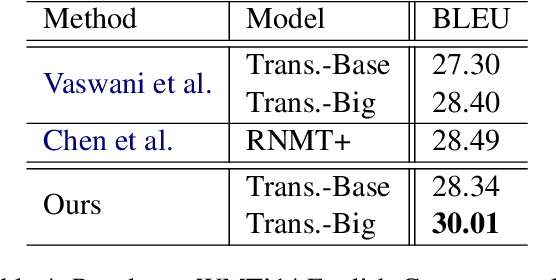
Neural machine translation (NMT) often suffers from the vulnerability to noisy perturbations in the input. We propose an approach to improving the robustness of NMT models, which consists of two parts: (1) attack the translation model with adversarial source examples; (2) defend the translation model with adversarial target inputs to improve its robustness against the adversarial source inputs.For the generation of adversarial inputs, we propose a gradient-based method to craft adversarial examples informed by the translation loss over the clean inputs.Experimental results on Chinese-English and English-German translation tasks demonstrate that our approach achieves significant improvements ($2.8$ and $1.6$ BLEU points) over Transformer on standard clean benchmarks as well as exhibiting higher robustness on noisy data.
Neural Machine Translation with Key-Value Memory-Augmented Attention
Jun 29, 2018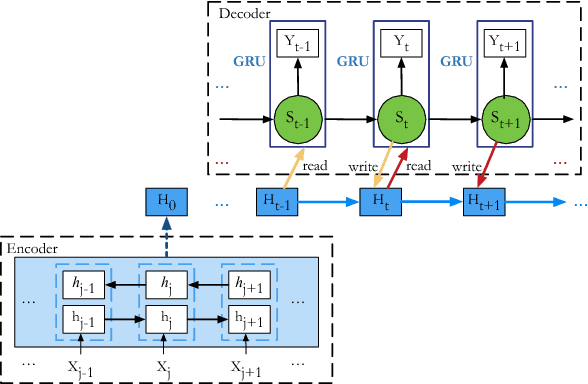
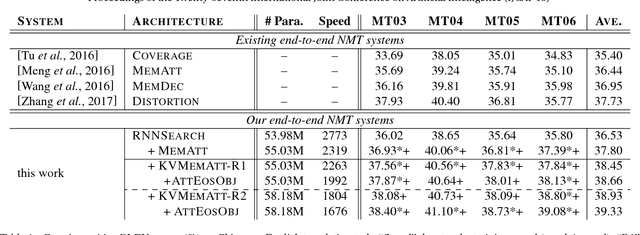
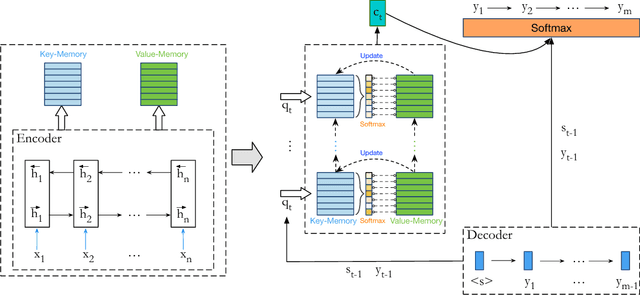
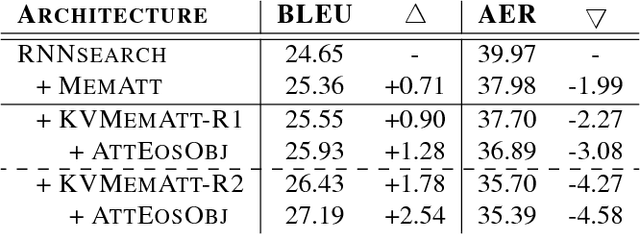
Although attention-based Neural Machine Translation (NMT) has achieved remarkable progress in recent years, it still suffers from issues of repeating and dropping translations. To alleviate these issues, we propose a novel key-value memory-augmented attention model for NMT, called KVMEMATT. Specifically, we maintain a timely updated keymemory to keep track of attention history and a fixed value-memory to store the representation of source sentence throughout the whole translation process. Via nontrivial transformations and iterative interactions between the two memories, the decoder focuses on more appropriate source word(s) for predicting the next target word at each decoding step, therefore can improve the adequacy of translations. Experimental results on Chinese=>English and WMT17 German<=>English translation tasks demonstrate the superiority of the proposed model.
Towards Robust Neural Machine Translation
May 16, 2018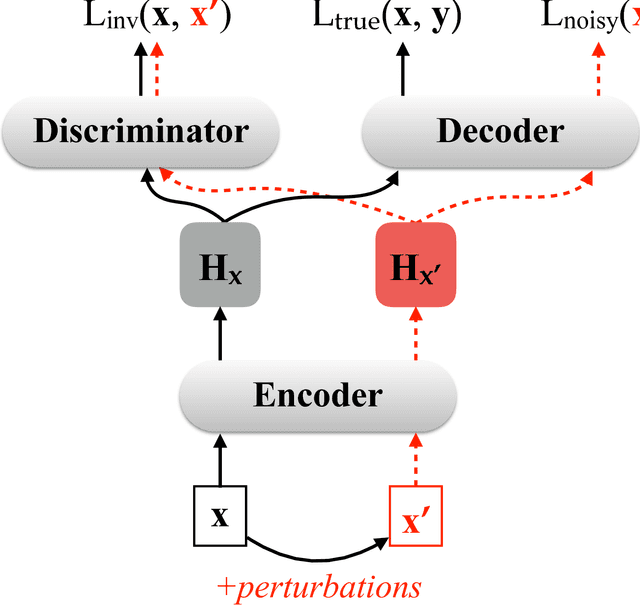
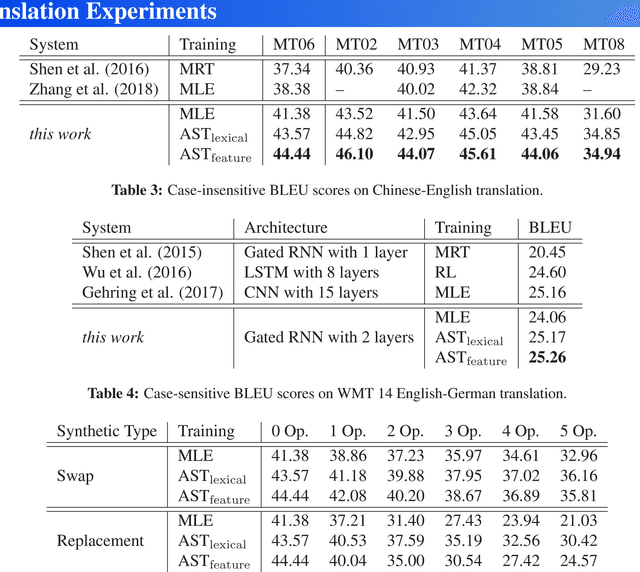
Small perturbations in the input can severely distort intermediate representations and thus impact translation quality of neural machine translation (NMT) models. In this paper, we propose to improve the robustness of NMT models with adversarial stability training. The basic idea is to make both the encoder and decoder in NMT models robust against input perturbations by enabling them to behave similarly for the original input and its perturbed counterpart. Experimental results on Chinese-English, English-German and English-French translation tasks show that our approaches can not only achieve significant improvements over strong NMT systems but also improve the robustness of NMT models.