 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Kinds of Recall
Mar 19, 2023It is an established assumption that pattern-based models are good at precision, while learning based models are better at recall. But is that really the case? I argue that there are two kinds of recall: d-recall, reflecting diversity, and e-recall, reflecting exhaustiveness. I demonstrate through experiments that while neural methods are indeed significantly better at d-recall, it is sometimes the case that pattern-based methods are still substantially better at e-recall. Ideal methods should aim for both kinds, and this ideal should in turn be reflected in our evaluations.
At Your Fingertips: Extracting Piano Fingering Instructions from Videos
Mar 07, 2023Piano fingering -- knowing which finger to use to play each note in a musical piece, is a hard and important skill to master when learning to play the piano. While some sheet music is available with expert-annotated fingering information, most pieces lack this information, and people often resort to learning the fingering from demonstrations in online videos. We consider the AI task of automating the extraction of fingering information from videos. This is a non-trivial task as fingers are often occluded by other fingers, and it is often not clear from the video which of the keys were pressed, requiring the synchronization of hand position information and knowledge about the notes that were played. We show how to perform this task with high-accuracy using a combination of deep-learning modules, including a GAN-based approach for fine-tuning on out-of-domain data. We extract the fingering information with an f1 score of 97\%. We run the resulting system on 90 videos, resulting in high-quality piano fingering information of 150K notes, the largest available dataset of piano-fingering to date.
Lexical Generalization Improves with Larger Models and Longer Training
Oct 25, 2022While fine-tuned language models perform well on many tasks, they were also shown to rely on superficial surface features such as lexical overlap. Excessive utilization of such heuristics can lead to failure on challenging inputs. We analyze the use of lexical overlap heuristics in natural language inference, paraphrase detection, and reading comprehension (using a novel contrastive dataset), and find that larger models are much less susceptible to adopting lexical overlap heuristics. We also find that longer training leads models to abandon lexical overlap heuristics. Finally, we provide evidence that the disparity between models size has its source in the pre-trained model
DALLE-2 is Seeing Double: Flaws in Word-to-Concept Mapping in Text2Image Models
Oct 19, 2022
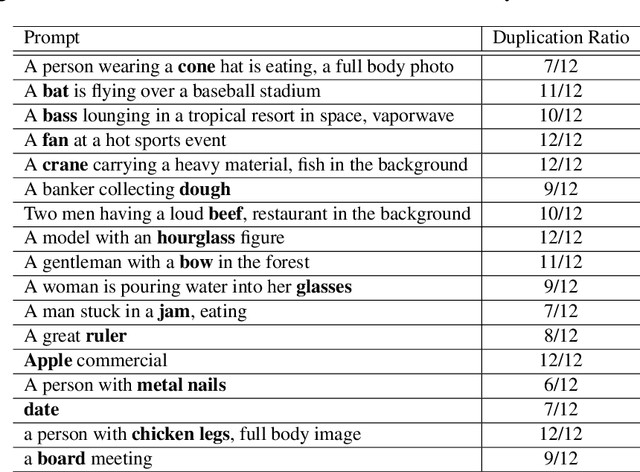

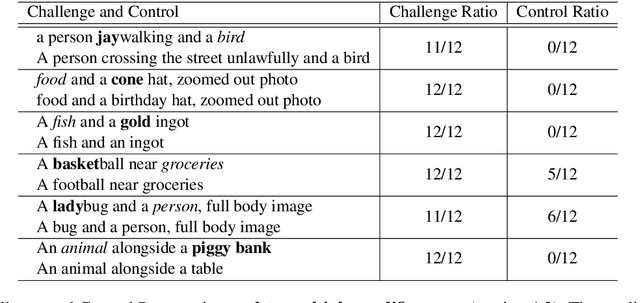
We study the way DALLE-2 maps symbols (words) in the prompt to their references (entities or properties of entities in the generated image). We show that in stark contrast to the way human process language, DALLE-2 does not follow the constraint that each word has a single role in the interpretation, and sometimes re-use the same symbol for different purposes. We collect a set of stimuli that reflect the phenomenon: we show that DALLE-2 depicts both senses of nouns with multiple senses at once; and that a given word can modify the properties of two distinct entities in the image, or can be depicted as one object and also modify the properties of another object, creating a semantic leakage of properties between entities. Taken together, our study highlights the differences between DALLE-2 and human language processing and opens an avenue for future study on the inductive biases of text-to-image models.
Linear Guardedness and its Implications
Oct 18, 2022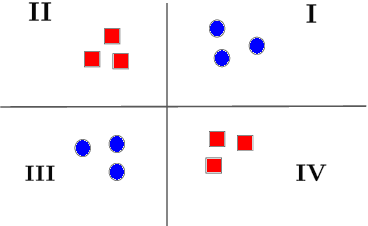
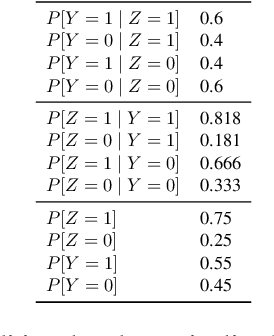
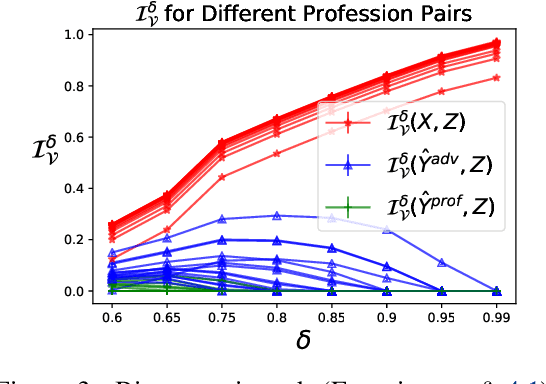
Previous work on concept identification in neural representations has focused on linear concept subspaces and their neutralization. In this work, we formulate the notion of linear guardedness -- the inability to directly predict a given concept from the representation -- and study its implications. We show that, in the binary case, the neutralized concept cannot be recovered by an additional linear layer. However, we point out that -- contrary to what was implicitly argued in previous works -- multiclass softmax classifiers can be constructed that indirectly recover the concept. Thus, linear guardedness does not guarantee that linear classifiers do not utilize the neutralized concepts, shedding light on theoretical limitations of linear information removal methods.
CIKQA: Learning Commonsense Inference with a Unified Knowledge-in-the-loop QA Paradigm
Oct 12, 2022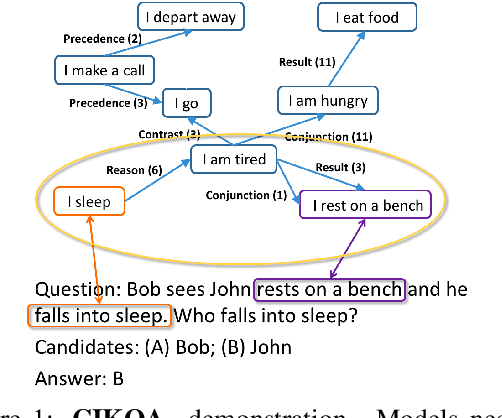
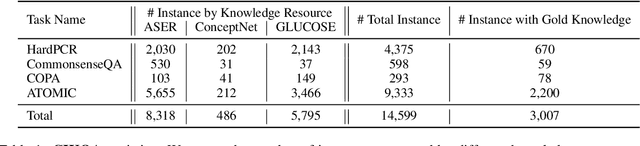

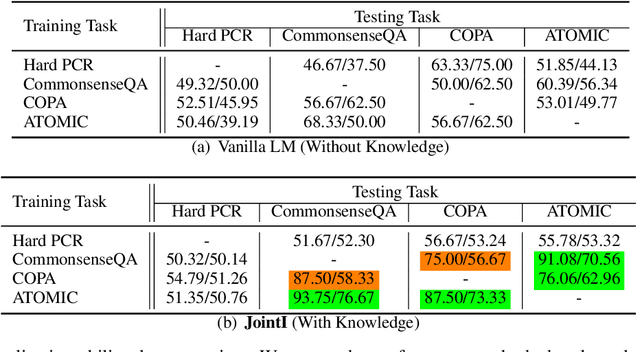
Recently, the community has achieved substantial progress on many commonsense reasoning benchmarks. However, it is still unclear what is learned from the training process: the knowledge, inference capability, or both? We argue that due to the large scale of commonsense knowledge, it is infeasible to annotate a large enough training set for each task to cover all commonsense for learning. Thus we should separate the commonsense knowledge acquisition and inference over commonsense knowledge as two separate tasks. In this work, we focus on investigating models' commonsense inference capabilities from two perspectives: (1) Whether models can know if the knowledge they have is enough to solve the task; (2) Whether models can develop commonsense inference capabilities that generalize across commonsense tasks. We first align commonsense tasks with relevant knowledge from commonsense knowledge bases and ask humans to annotate whether the knowledge is enough or not. Then, we convert different commonsense tasks into a unified question answering format to evaluate models' generalization capabilities. We name the benchmark as Commonsense Inference with Knowledge-in-the-loop Question Answering (CIKQA).
Understanding Transformer Memorization Recall Through Idioms
Oct 11, 2022
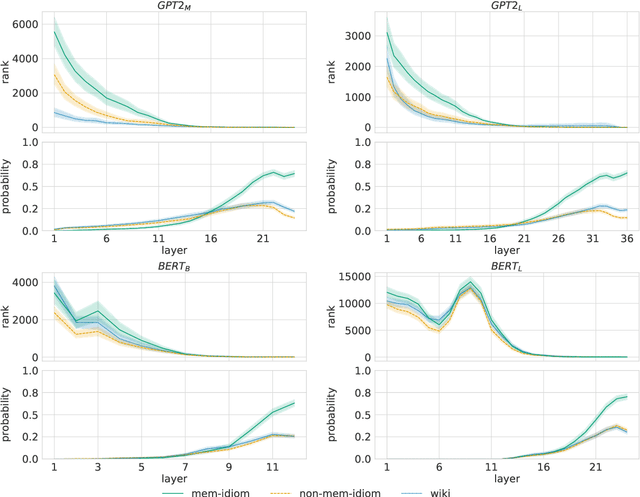
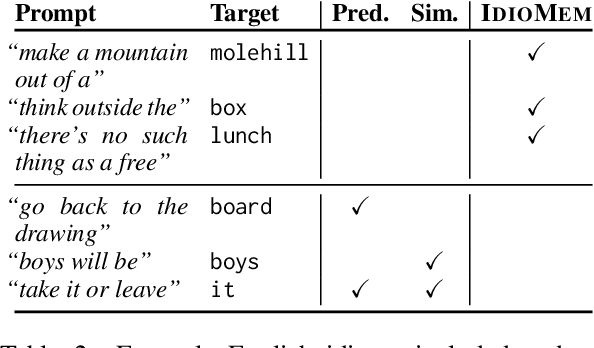
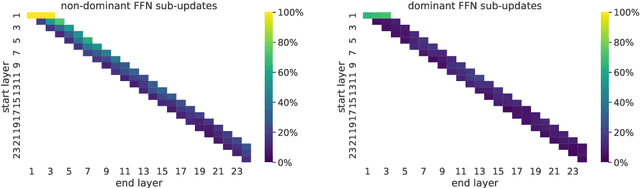
To produce accurate predictions, language models (LMs) must balance between generalization and memorization. Yet, little is known about the mechanism by which transformer LMs employ their memorization capacity. When does a model decide to output a memorized phrase, and how is this phrase then retrieved from memory? In this work, we offer the first methodological framework for probing and characterizing recall of memorized sequences in transformer LMs. First, we lay out criteria for detecting model inputs that trigger memory recall, and propose idioms as inputs that fulfill these criteria. Next, we construct a dataset of English idioms and use it to compare model behavior on memorized vs. non-memorized inputs. Specifically, we analyze the internal prediction construction process by interpreting the model's hidden representations as a gradual refinement of the output probability distribution. We find that across different model sizes and architectures, memorized predictions are a two-step process: early layers promote the predicted token to the top of the output distribution, and upper layers increase model confidence. This suggests that memorized information is stored and retrieved in the early layers of the network. Last, we demonstrate the utility of our methodology beyond idioms in memorized factual statements. Overall, our work makes a first step towards understanding memory recall, and provides a methodological basis for future studies of transformer memorization.
F-COREF: Fast, Accurate and Easy to Use Coreference Resolution
Sep 14, 2022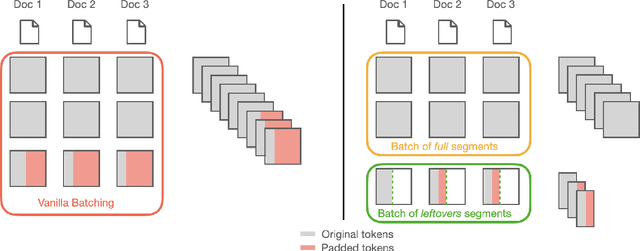
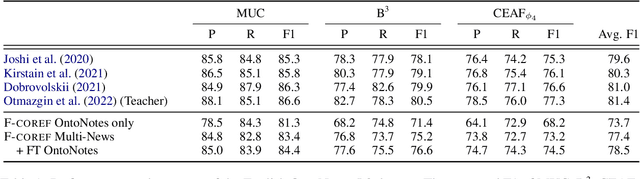
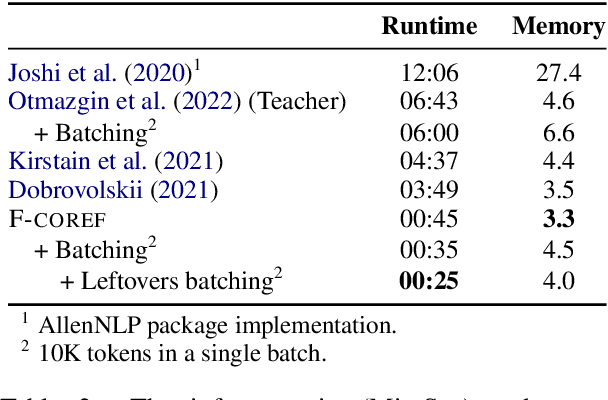
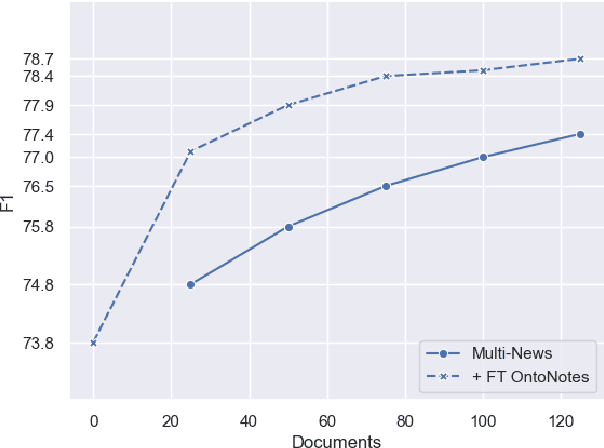
We introduce fastcoref, a python package for fast, accurate, and easy-to-use English coreference resolution. The package is pip-installable, and allows two modes: an accurate mode based on the LingMess architecture, providing state-of-the-art coreference accuracy, and a substantially faster model, F-coref, which is the focus of this work. F-coref allows to process 2.8K OntoNotes documents in 25 seconds on a V100 GPU (compared to 6 minutes for the LingMess model, and to 12 minutes of the popular AllenNLP coreference model) with only a modest drop in accuracy. The fast speed is achieved through a combination of distillation of a compact model from the LingMess model, and an efficient batching implementation using a technique we call leftover batching. Our code is available at https://github.com/shon-otmazgin/fastcoref
Measuring Causal Effects of Data Statistics on Language Model's `Factual' Predictions
Jul 28, 2022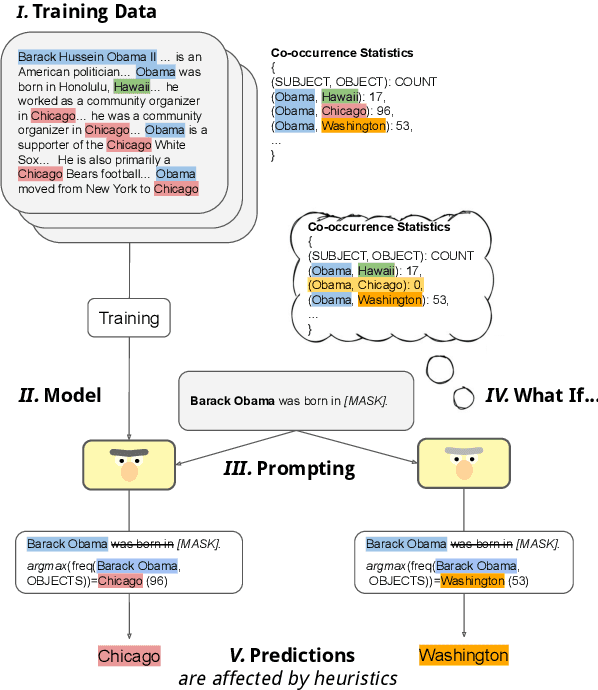

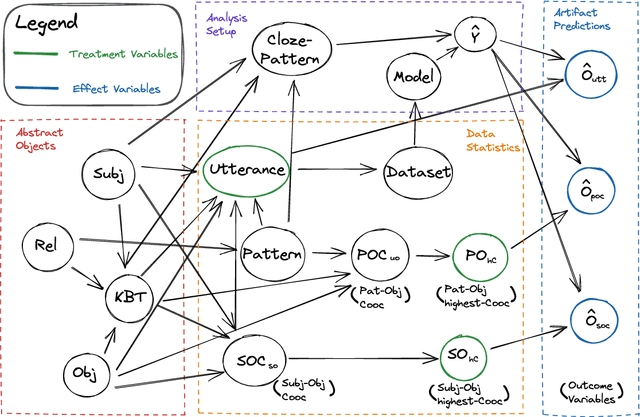

Large amounts of training data are one of the major reasons for the high performance of state-of-the-art NLP models. But what exactly in the training data causes a model to make a certain prediction? We seek to answer this question by providing a language for describing how training data influences predictions, through a causal framework. Importantly, our framework bypasses the need to retrain expensive models and allows us to estimate causal effects based on observational data alone. Addressing the problem of extracting factual knowledge from pretrained language models (PLMs), we focus on simple data statistics such as co-occurrence counts and show that these statistics do influence the predictions of PLMs, suggesting that such models rely on shallow heuristics. Our causal framework and our results demonstrate the importance of studying datasets and the benefits of causality for understanding NLP models.
Rivendell: Project-Based Academic Search Engine
Jun 26, 2022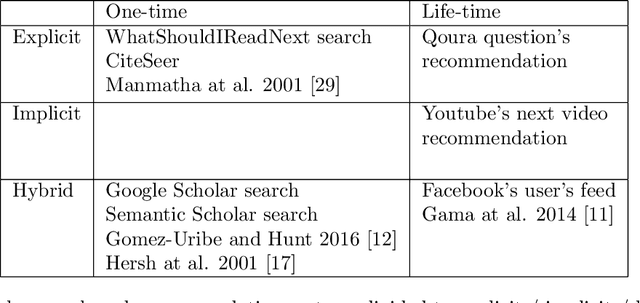

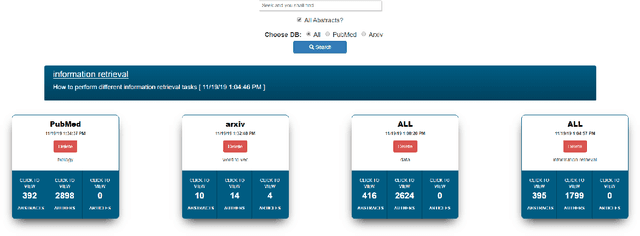

Finding relevant research literature in online databases is a familiar challenge to all researchers. General search approaches trying to tackle this challenge fall into two groups: one-time search and life-time search. We observe that both approaches ignore unique attributes of the research domain and are affected by concept drift. We posit that in searching for research papers, a combination of a life-time search engine with an explicitly-provided context (project) provides a solution to the concept drift problem. We developed and deployed a project-based meta-search engine for research papers called Rivendell. Using Rivendell, we conducted experiments with 199 subjects, comparing project-based search performance to one-time and life-time search engines, revealing an improvement of up to 12.8 percent in project-based search compared to life-time search.