 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Reinforcement Learning For Cooperative Swarms
May 06, 2026A cooperative robot swarm is a collective of computationally-limited robots that share a common goal. Each robot can only interact with a small subset of its peers, without knowing how this affects the collective utility. Recent advances in distributed multi-agent reinforcement learning have demonstrated that it is possible for robots to learn how to interact effectively with others, in a manner that is aligned with the common goal, despite each robot learning independently of others. However, this requires each robot to represent a potentially combinatorial number of interaction states, challenging the memory capabilities of the robots. This paper proposes an alternative approach for representing spatial interaction states for multi-robot reinforcement learning in swarms. A modular (decomposed) representation is used, where each feature of the state is handled by a separate learning procedure, and the results aggregated. We demonstrate the efficacy of the approach in numerous experiments with simulated robot swarms carrying out foraging.
A Harmonic Mean Formulation of Average Reward Reinforcement Learning in SMDPs
May 06, 2026Recent research has revived and amplified interest in algorithms for undiscounted average reward reinforcement learning in infinite-horizon, non-episodic (continuing) tasks. Semi-Markov decision processes (SMDPs) are of particular interest. In SMDPs, discrete actions stochastically generate both rewards and durations, and the objective is to optimize the average reward rate. Existing algorithms approach this by optimizing the ratio of rewards to durations. However, when rewards and durations are non-stationary (in the infinite horizon), this can be incorrect. This paper presents a novel modified harmonic mean operator that correctly computes reward rates even under such conditions. This yields model-free learning algorithms that can work with SMDPs, while maintaining robustness to non-stationary reward and duration distributions over time. We prove theoretical properties of the modified harmonic mean operator, and empirically demonstrate its efficacy in comparison to existing algorithms.
A Language for Describing Agentic LLM Contexts
May 03, 2026Large language models are increasingly used within larger systems ("LLM agents"). These make a sequence of LLM calls, each call providing the LLM with a combination of instructions, observations, and interaction history. The design of the encoded information and its structure play a central role in the quality of the resulting system, leading to efforts spent on context engineering. It is therefore critical to communicate the composition of the LLM context in a system, and how it evolves over time. Yet, no standard exists for doing so: context construction is typically conveyed through informal prose, ad hoc diagrams, or direct inspection of code, none of which precisely capture how a prompt evolves across interaction steps or how two context representation strategies differ. To remedy this, we introduce the Agentic Context Description Language (ACDL), a language for specifying the structure and dynamics of LLM input contexts in a precise, readable, and standard manner, along with visualizations. ACDL provides constructs for specifying context aspects such as role message sequences, dynamic content, time-indexed references, and conditional or iterative structure, capturing the full architecture of a prompt independently of any particular implementation. ACDL diagrams can be hand drawn on a whiteboard, or written in formal language which can then be rendered. We describe the language, demonstrate it by documenting several existing systems and their variants, and encourage the community to adopt it for describing LLM systems context, both in day-to-day communication and in papers. Tooling, examples and documentation are available at www.acdlang.org.
* 18 pages, 12 figures. Accepted at CAIS '26. Project page: www.acdlang.org
Personalized Medication Planning via Direct Domain Modeling and LLM-Generated Heuristics
Jan 07, 2026Personalized medication planning involves selecting medications and determining a dosing schedule to achieve medical goals specific to each individual patient. Previous work successfully demonstrated that automated planners, using general domain-independent heuristics, are able to generate personalized treatments, when the domain and problems are modeled using a general domain description language (\pddlp). Unfortunately, this process was limited in practice to consider no more than seven medications. In clinical terms, this is a non-starter. In this paper, we explore the use of automatically-generated domain- and problem-specific heuristics to be used with general search, as a method of scaling up medication planning to levels allowing closer work with clinicians. Specifically, we specify the domain programmatically (specifying an initial state and a successor generation procedure), and use an LLM to generate a problem specific heuristic that can be used by a fixed search algorithm (GBFS). The results indicate dramatic improvements in coverage and planning time, scaling up the number of medications to at least 28, and bringing medication planning one step closer to practical applications.
Bugs with Features: Vision-Based Fault-Tolerant Collective Motion Inspired by Nature
Dec 27, 2025In collective motion, perceptually-limited individuals move in an ordered manner, without centralized control. The perception of each individual is highly localized, as is its ability to interact with others. While natural collective motion is robust, most artificial swarms are brittle. This particularly occurs when vision is used as the sensing modality, due to ambiguities and information-loss inherent in visual perception. This paper presents mechanisms for robust collective motion inspired by studies of locusts. First, we develop a robust distance estimation method that combines visually perceived horizontal and vertical sizes of neighbors. Second, we introduce intermittent locomotion as a mechanism that allows robots to reliably detect peers that fail to keep up, and disrupt the motion of the swarm. We show how such faulty robots can be avoided in a manner that is robust to errors in classifying them as faulty. Through extensive physics-based simulation experiments, we show dramatic improvements to swarm resilience when using these techniques. We show these are relevant to both distance-based Avoid-Attract models, as well as to models relying on Alignment, in a wide range of experiment settings.
Tightest Admissible Shortest Path
Aug 15, 2023

The shortest path problem in graphs is fundamental to AI. Nearly all variants of the problem and relevant algorithms that solve them ignore edge-weight computation time and its common relation to weight uncertainty. This implies that taking these factors into consideration can potentially lead to a performance boost in relevant applications. Recently, a generalized framework for weighted directed graphs was suggested, where edge-weight can be computed (estimated) multiple times, at increasing accuracy and run-time expense. We build on this framework to introduce the problem of finding the tightest admissible shortest path (TASP); a path with the tightest suboptimality bound on the optimal cost. This is a generalization of the shortest path problem to bounded uncertainty, where edge-weight uncertainty can be traded for computational cost. We present a complete algorithm for solving TASP, with guarantees on solution quality. Empirical evaluation supports the effectiveness of this approach.
A Generalization of the Shortest Path Problem to Graphs with Multiple Edge-Cost Estimates
Aug 22, 2022The shortest path problem in graphs is a cornerstone for both theory and applications. Existing work accounts for edge weight access time, but generally ignores edge weight computation time. In this paper we present a generalized framework for weighted directed graphs, where each edge cost can be dynamically estimated by multiple estimators, that offer different cost bounds and run-times. This raises several generalized shortest path problems, that optimize different aspects of path cost while requiring guarantees on cost uncertainty, providing a better basis for modeling realistic problems. We present complete, anytime algorithms for solving these problems, and provide guarantees on the solution quality.
Rivendell: Project-Based Academic Search Engine
Jun 26, 2022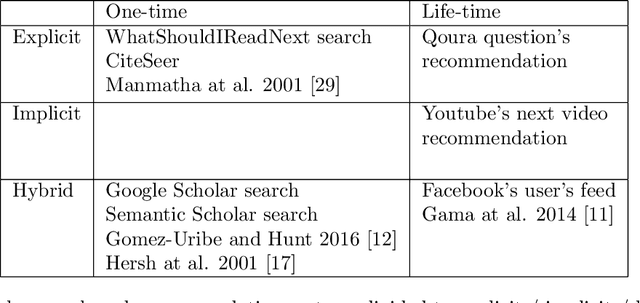


Finding relevant research literature in online databases is a familiar challenge to all researchers. General search approaches trying to tackle this challenge fall into two groups: one-time search and life-time search. We observe that both approaches ignore unique attributes of the research domain and are affected by concept drift. We posit that in searching for research papers, a combination of a life-time search engine with an explicitly-provided context (project) provides a solution to the concept drift problem. We developed and deployed a project-based meta-search engine for research papers called Rivendell. Using Rivendell, we conducted experiments with 199 subjects, comparing project-based search performance to one-time and life-time search engines, revealing an improvement of up to 12.8 percent in project-based search compared to life-time search.
Position Paper: Online Modeling for Offline Planning
Jun 20, 2022The definition and representation of planning problems is at the heart of AI planning research. A key part is the representation of action models. Decades of advances improving declarative action model representations resulted in numerous theoretical advances, and capable, working, domain-independent planners. However, despite the maturity of the field, AI planning technology is still rarely used outside the research community, suggesting that current representations fail to capture real-world requirements, such as utilizing complex mathematical functions and models learned from data. We argue that this is because the modeling process is assumed to have taken place and completed prior to the planning process, i.e., offline modeling for offline planning. There are several challenges inherent to this approach, including: limited expressiveness of declarative modeling languages; early commitment to modeling choices and computation, that preclude using the most appropriate resolution for each action model -- which can only be known during planning; and difficulty in reliably using non-declarative, learned, models. We therefore suggest to change the AI planning process, such that is carries out online modeling in offline planning, i.e., the use of action models that are computed or even generated as part of the planning process, as they are accessed. This generalizes the existing approach (offline modeling). The proposed definition admits novel planning processes, and we suggest one concrete implementation, demonstrating the approach. We sketch initial results that were obtained as part of a first attempt to follow this approach by planning with action cost estimators. We conclude by discussing open challenges.
Planning with Dynamically Estimated Action Costs
Jun 14, 2022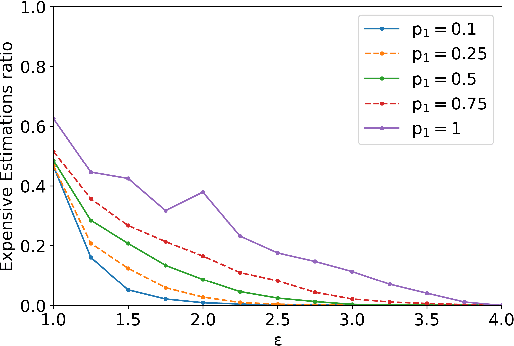

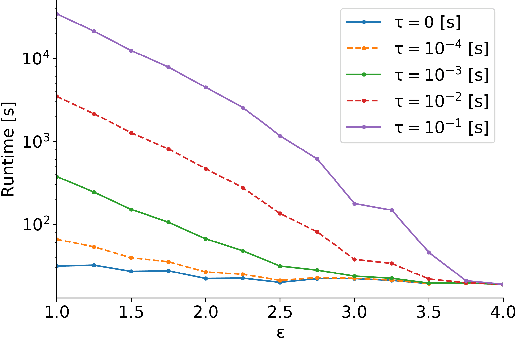
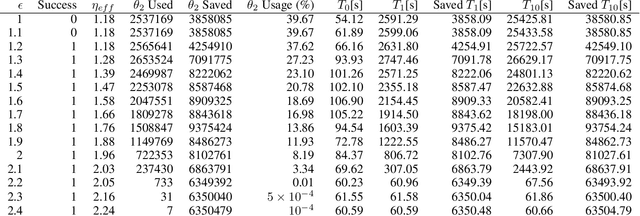
Information about action costs is critical for real-world AI planning applications. Rather than rely solely on declarative action models, recent approaches also use black-box external action cost estimators, often learned from data, that are applied during the planning phase. These, however, can be computationally expensive, and produce uncertain values. In this paper we suggest a generalization of deterministic planning with action costs that allows selecting between multiple estimators for action cost, to balance computation time against bounded estimation uncertainty. This enables a much richer -- and correspondingly more realistic -- problem representation. Importantly, it allows planners to bound plan accuracy, thereby increasing reliability, while reducing unnecessary computational burden, which is critical for scaling to large problems. We introduce a search algorithm, generalizing $A^*$, that solves such planning problems, and additional algorithmic extensions. In addition to theoretical guarantees, extensive experiments show considerable savings in runtime compared to alternatives.