 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Structured Referring Expression Reasoning in The Wild
Apr 19, 2020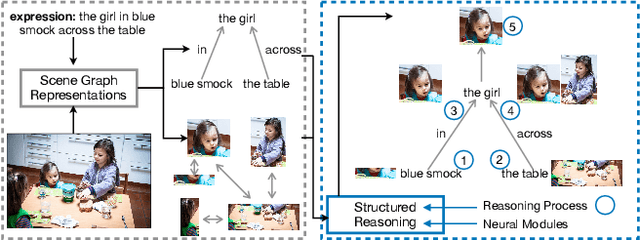
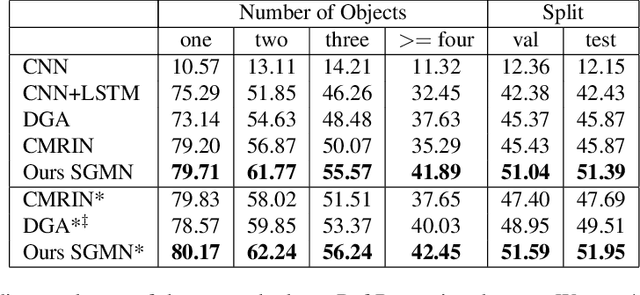

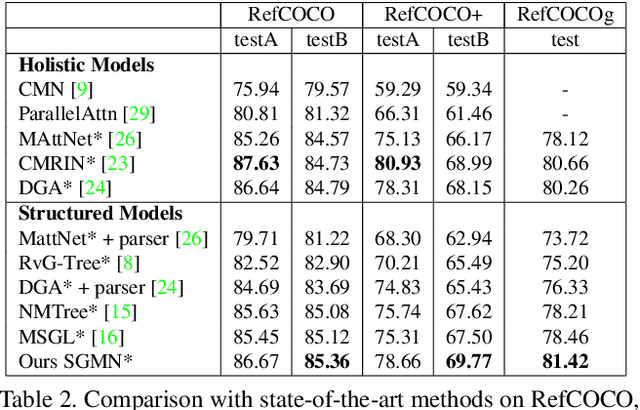
Grounding referring expressions aims to locate in an image an object referred to by a natural language expression. The linguistic structure of a referring expression provides a layout of reasoning over the visual contents, and it is often crucial to align and jointly understand the image and the referring expression. In this paper, we propose a scene graph guided modular network (SGMN), which performs reasoning over a semantic graph and a scene graph with neural modules under the guidance of the linguistic structure of the expression. In particular, we model the image as a structured semantic graph, and parse the expression into a language scene graph. The language scene graph not only decodes the linguistic structure of the expression, but also has a consistent representation with the image semantic graph. In addition to exploring structured solutions to grounding referring expressions, we also propose Ref-Reasoning, a large-scale real-world dataset for structured referring expression reasoning. We automatically generate referring expressions over the scene graphs of images using diverse expression templates and functional programs. This dataset is equipped with real-world visual contents as well as semantically rich expressions with different reasoning layouts. Experimental results show that our SGMN not only significantly outperforms existing state-of-the-art algorithms on the new Ref-Reasoning dataset, but also surpasses state-of-the-art structured methods on commonly used benchmark datasets. It can also provide interpretable visual evidences of reasoning. Data and code are available at https://github.com/sibeiyang/sgmn
When Relation Networks meet GANs: Relation GANs with Triplet Loss
Mar 17, 2020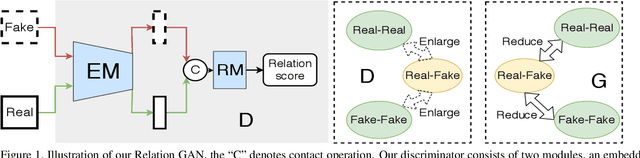
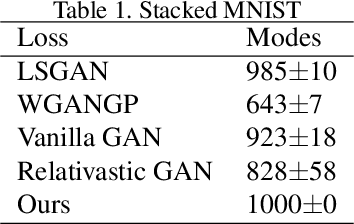
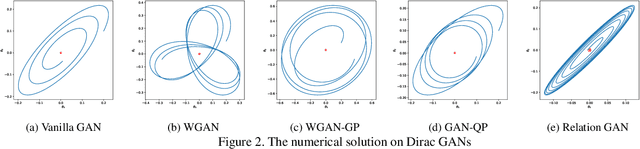
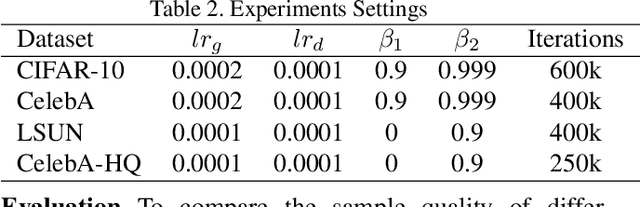
Though recent research has achieved remarkable progress in generating realistic images with generative adversarial networks (GANs), the lack of training stability is still a lingering concern of most GANs, especially on high-resolution inputs and complex datasets. Since the randomly generated distribution can hardly overlap with the real distribution, training GANs often suffers from the gradient vanishing problem. A number of approaches have been proposed to address this issue by constraining the discriminator's capabilities using empirical techniques, like weight clipping, gradient penalty, spectral normalization etc. In this paper, we provide a more principled approach as an alternative solution to this issue. Instead of training the discriminator to distinguish real and fake input samples, we investigate the relationship between paired samples by training the discriminator to separate paired samples from the same distribution and those from different distributions. To this end, we explore a relation network architecture for the discriminator and design a triplet loss which performs better generalization and stability. Extensive experiments on benchmark datasets show that the proposed relation discriminator and new loss can provide significant improvement on variable vision tasks including unconditional and conditional image generation and image translation.
Kernel Quantization for Efficient Network Compression
Mar 11, 2020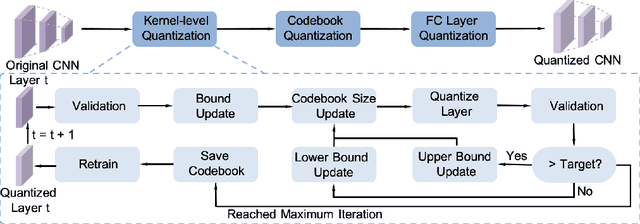
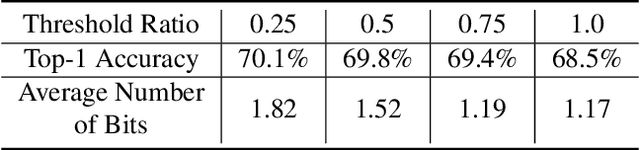
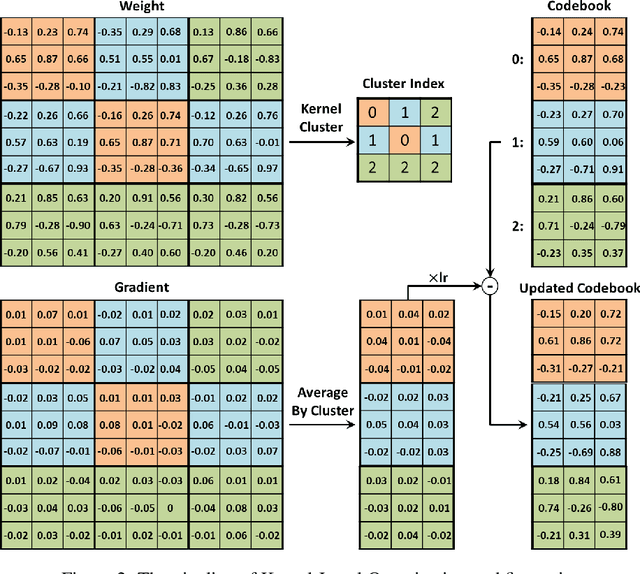
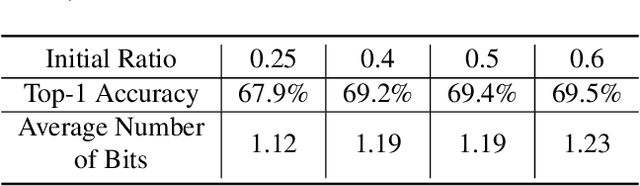
This paper presents a novel network compression framework Kernel Quantization (KQ), targeting to efficiently convert any pre-trained full-precision convolutional neural network (CNN) model into a low-precision version without significant performance loss. Unlike existing methods struggling with weight bit-length, KQ has the potential in improving the compression ratio by considering the convolution kernel as the quantization unit. Inspired by the evolution from weight pruning to filter pruning, we propose to quantize in both kernel and weight level. Instead of representing each weight parameter with a low-bit index, we learn a kernel codebook and replace all kernels in the convolution layer with corresponding low-bit indexes. Thus, KQ can represent the weight tensor in the convolution layer with low-bit indexes and a kernel codebook with limited size, which enables KQ to achieve significant compression ratio. Then, we conduct a 6-bit parameter quantization on the kernel codebook to further reduce redundancy. Extensive experiments on the ImageNet classification task prove that KQ needs 1.05 and 1.62 bits on average in VGG and ResNet18, respectively, to represent each parameter in the convolution layer and achieves the state-of-the-art compression ratio with little accuracy loss.
Segmentation-based Method combined with Dynamic Programming for Brain Midline Delineation
Feb 27, 2020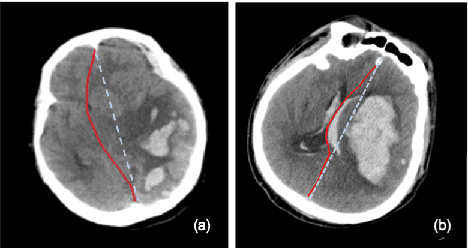

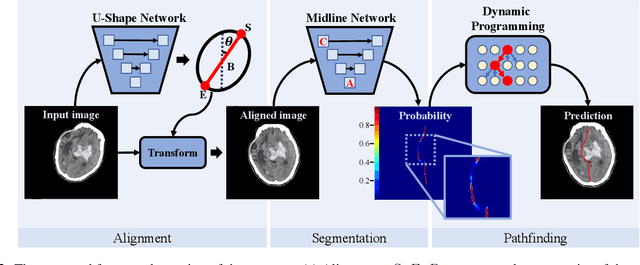
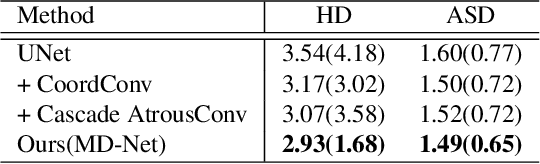
The midline related pathological image features are crucial for evaluating the severity of brain compression caused by stroke or traumatic brain injury (TBI). The automated midline delineation not only improves the assessment and clinical decision making for patients with stroke symptoms or head trauma but also reduces the time of diagnosis. Nevertheless, most of the previous methods model the midline by localizing the anatomical points, which are hard to detect or even missing in severe cases. In this paper, we formulate the brain midline delineation as a segmentation task and propose a three-stage framework. The proposed framework firstly aligns an input CT image into the standard space. Then, the aligned image is processed by a midline detection network (MD-Net) integrated with the CoordConv Layer and Cascade AtrousCconv Module to obtain the probability map. Finally, we formulate the optimal midline selection as a pathfinding problem to solve the problem of the discontinuity of midline delineation. Experimental results show that our proposed framework can achieve superior performance on one in-house dataset and one public dataset.
Depthwise Non-local Module for Fast Salient Object Detection Using a Single Thread
Jan 22, 2020
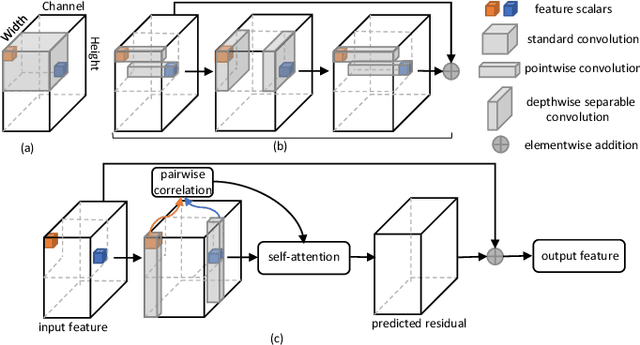
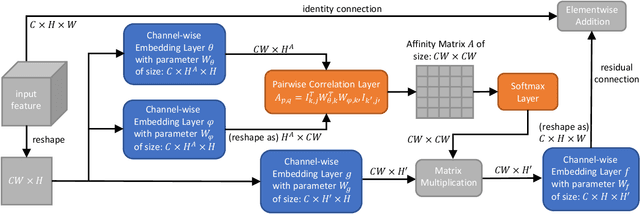
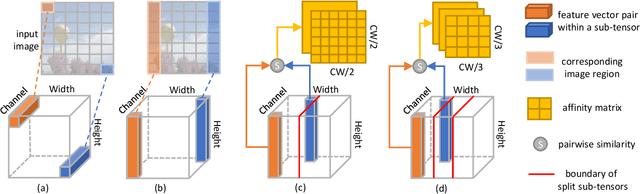
Recently deep convolutional neural networks have achieved significant success in salient object detection. However, existing state-of-the-art methods require high-end GPUs to achieve real-time performance, which makes them hard to adapt to low-cost or portable devices. Although generic network architectures have been proposed to speed up inference on mobile devices, they are tailored to the task of image classification or semantic segmentation, and struggle to capture intra-channel and inter-channel correlations that are essential for contrast modeling in salient object detection. Motivated by the above observations, we design a new deep learning algorithm for fast salient object detection. The proposed algorithm for the first time achieves competitive accuracy and high inference efficiency simultaneously with a single CPU thread. Specifically, we propose a novel depthwise non-local moudule (DNL), which implicitly models contrast via harvesting intra-channel and inter-channel correlations in a self-attention manner. In addition, we introduce a depthwise non-local network architecture that incorporates both depthwise non-local modules and inverted residual blocks. Experimental results show that our proposed network attains very competitive accuracy on a wide range of salient object detection datasets while achieving state-of-the-art efficiency among all existing deep learning based algorithms.
Globally Guided Progressive Fusion Network for 3D Pancreas Segmentation
Nov 23, 2019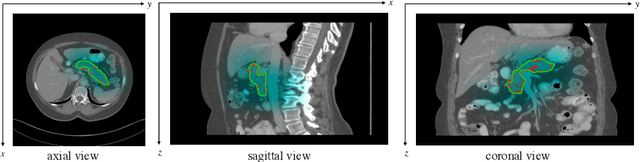
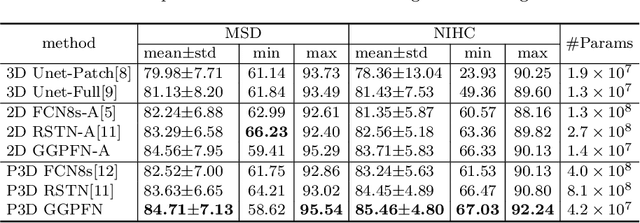
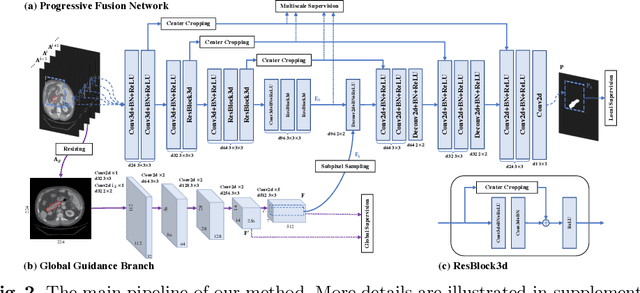
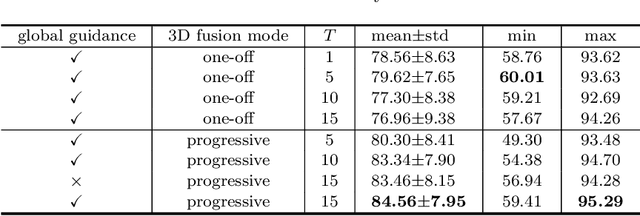
Recently 3D volumetric organ segmentation attracts much research interest in medical image analysis due to its significance in computer aided diagnosis. This paper aims to address the pancreas segmentation task in 3D computed tomography volumes. We propose a novel end-to-end network, Globally Guided Progressive Fusion Network, as an effective and efficient solution to volumetric segmentation, which involves both global features and complicated 3D geometric information. A progressive fusion network is devised to extract 3D information from a moderate number of neighboring slices and predict a probability map for the segmentation of each slice. An independent branch for excavating global features from downsampled slices is further integrated into the network. Extensive experimental results demonstrate that our method achieves state-of-the-art performance on two pancreas datasets.
Self-Enhanced Convolutional Network for Facial Video Hallucination
Nov 23, 2019
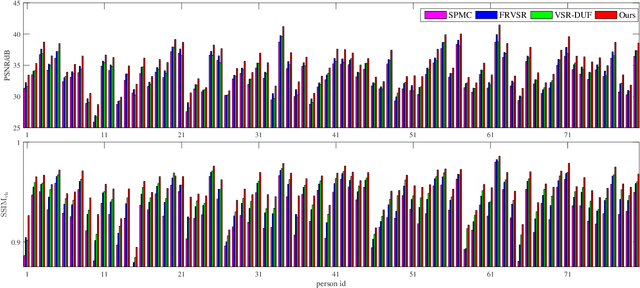
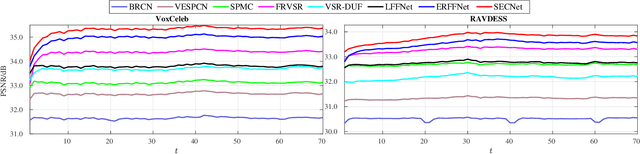
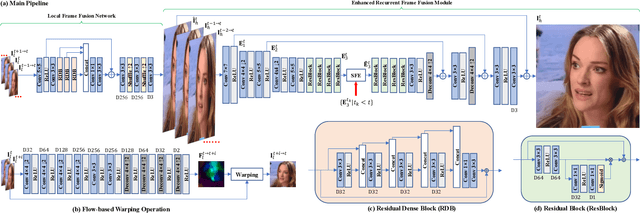
As a domain-specific super-resolution problem, facial image hallucination has enjoyed a series of breakthroughs thanks to the advances of deep convolutional neural networks. However, the direct migration of existing methods to video is still difficult to achieve good performance due to its lack of alignment and consistency modelling in temporal domain. Taking advantage of high inter-frame dependency in videos, we propose a self-enhanced convolutional network for facial video hallucination. It is implemented by making full usage of preceding super-resolved frames and a temporal window of adjacent low-resolution frames. Specifically, the algorithm first obtains the initial high-resolution inference of each frame by taking into consideration a sequence of consecutive low-resolution inputs through temporal consistency modelling. It further recurrently exploits the reconstructed results and intermediate features of a sequence of preceding frames to improve the initial super-resolution of the current frame by modelling the coherence of structural facial features across frames. Quantitative and qualitative evaluations demonstrate the superiority of the proposed algorithm against state-of-the-art methods. Moreover, our algorithm also achieves excellent performance in the task of general video super-resolution in a single-shot setting.
Motion Guided Attention for Video Salient Object Detection
Oct 03, 2019
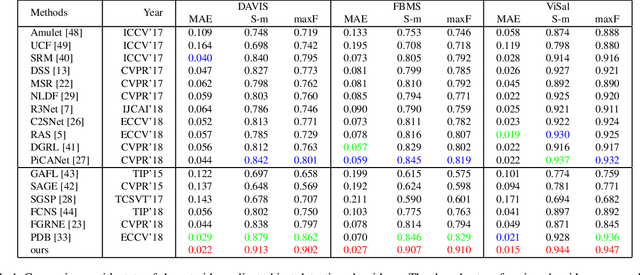
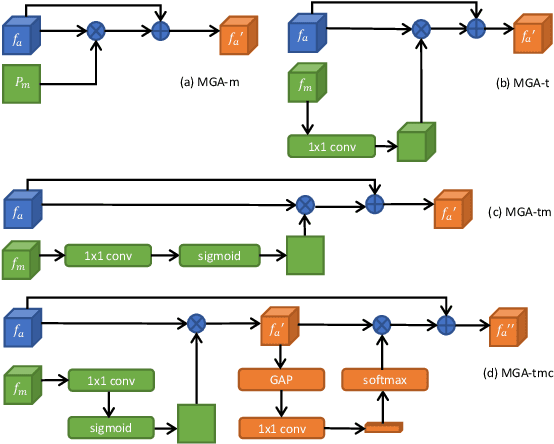
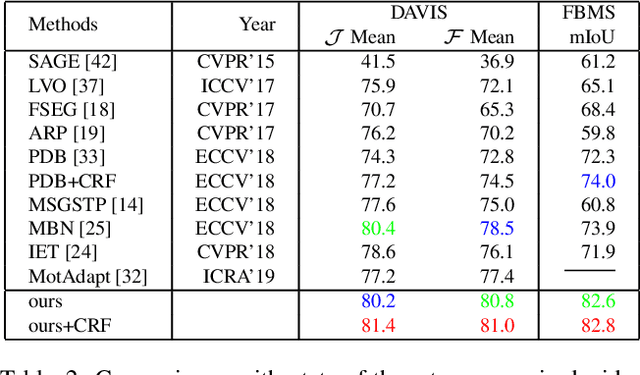
Video salient object detection aims at discovering the most visually distinctive objects in a video. How to effectively take object motion into consideration during video salient object detection is a critical issue. Existing state-of-the-art methods either do not explicitly model and harvest motion cues or ignore spatial contexts within optical flow images. In this paper, we develop a multi-task motion guided video salient object detection network, which learns to accomplish two sub-tasks using two sub-networks, one sub-network for salient object detection in still images and the other for motion saliency detection in optical flow images. We further introduce a series of novel motion guided attention modules, which utilize the motion saliency sub-network to attend and enhance the sub-network for still images. These two sub-networks learn to adapt to each other by end-to-end training. Experimental results demonstrate that the proposed method significantly outperforms existing state-of-the-art algorithms on a wide range of benchmarks. We hope our simple and effective approach will serve as a solid baseline and help ease future research in video salient object detection. Code and models will be made available.
Dynamic Graph Attention for Referring Expression Comprehension
Sep 18, 2019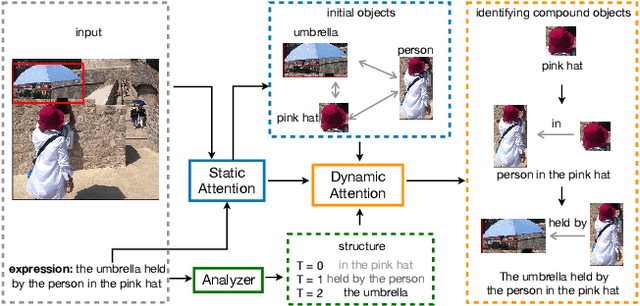
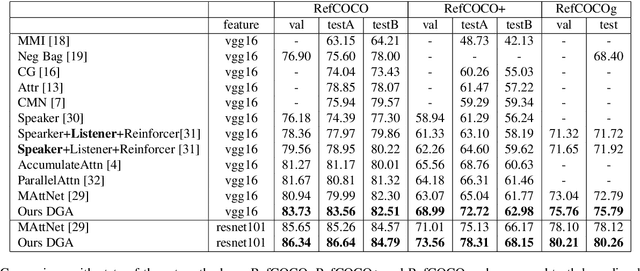
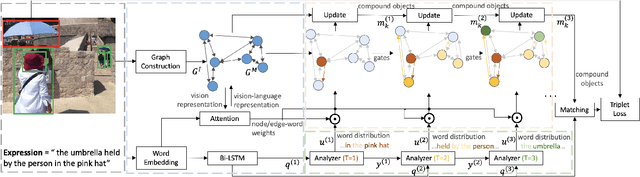
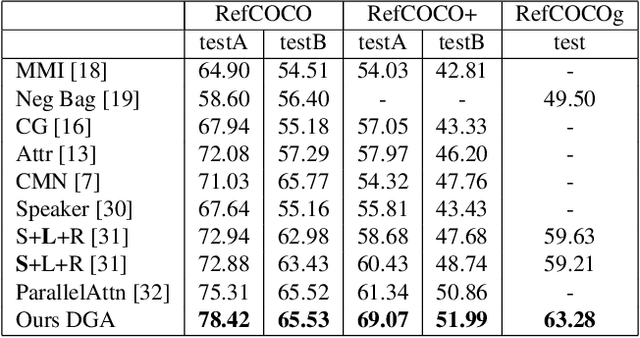
Referring expression comprehension aims to locate the object instance described by a natural language referring expression in an image. This task is compositional and inherently requires visual reasoning on top of the relationships among the objects in the image. Meanwhile, the visual reasoning process is guided by the linguistic structure of the referring expression. However, existing approaches treat the objects in isolation or only explore the first-order relationships between objects without being aligned with the potential complexity of the expression. Thus it is hard for them to adapt to the grounding of complex referring expressions. In this paper, we explore the problem of referring expression comprehension from the perspective of language-driven visual reasoning, and propose a dynamic graph attention network to perform multi-step reasoning by modeling both the relationships among the objects in the image and the linguistic structure of the expression. In particular, we construct a graph for the image with the nodes and edges corresponding to the objects and their relationships respectively, propose a differential analyzer to predict a language-guided visual reasoning process, and perform stepwise reasoning on top of the graph to update the compound object representation at every node. Experimental results demonstrate that the proposed method can not only significantly surpass all existing state-of-the-art algorithms across three common benchmark datasets, but also generate interpretable visual evidences for stepwisely locating the objects referred to in complex language descriptions.
MVP-Net: Multi-view FPN with Position-aware Attention for Deep Universal Lesion Detection
Sep 16, 2019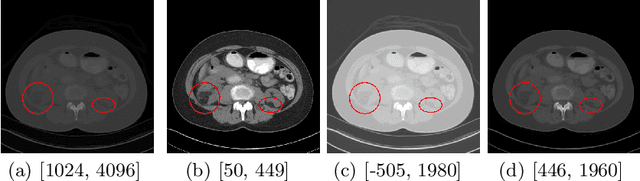
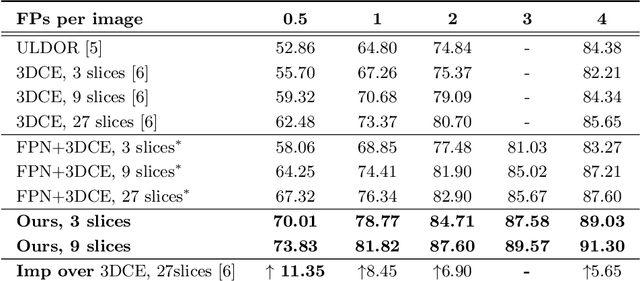
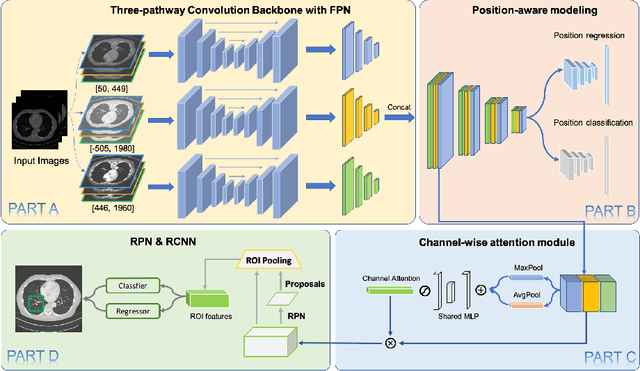
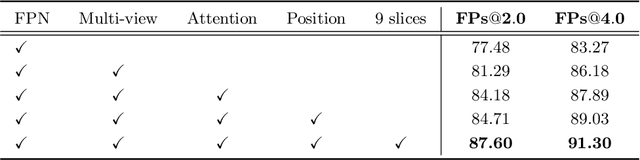
Universal lesion detection (ULD) on computed tomography (CT) images is an important but underdeveloped problem. Recently, deep learning-based approaches have been proposed for ULD, aiming to learn representative features from annotated CT data. However, the hunger for data of deep learning models and the scarcity of medical annotation hinders these approaches to advance further. In this paper, we propose to incorporate domain knowledge in clinical practice into the model design of universal lesion detectors. Specifically, as radiologists tend to inspect multiple windows for an accurate diagnosis, we explicitly model this process and propose a multi-view feature pyramid network (FPN), where multi-view features are extracted from images rendered with varied window widths and window levels; to effectively combine this multi-view information, we further propose a position-aware attention module. With the proposed model design, the data-hunger problem is relieved as the learning task is made easier with the correctly induced clinical practice prior. We show promising results with the proposed model, achieving an absolute gain of $\mathbf{5.65\%}$ (in the sensitivity of FPs@4.0) over the previous state-of-the-art on the NIH DeepLesion dataset.