 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
Telogenesis: Goal Is All U Need
Mar 10, 2026Goal-conditioned systems assume goals are provided externally. We ask whether attentional priorities can emerge endogenously from an agent's internal cognitive state. We propose a priority function that generates observation targets from three epistemic gaps: ignorance (posterior variance), surprise (prediction error), and staleness (temporal decay of confidence in unobserved variables). We validate this in two systems: a minimal attention-allocation environment (2,000 runs) and a modular, partially observable world (500 runs). Ablation shows each component is necessary. A key finding is metric-dependent reversal: under global prediction error, coverage-based rotation wins; under change detection latency, priority-guided allocation wins, with advantage growing monotonically with dimensionality (d = -0.95 at N=48, p < 10^-6). Detection latency follows a power law in attention budget, with a steeper exponent for priority-guided allocation (0.55 vs. 0.40). When the decay rate is made learnable per variable, the system spontaneously recovers environmental volatility structure without supervision (t = 22.5, p < 10^-6). We demonstrate that epistemic gaps alone, without external reward, suffice to generate adaptive priorities that outperform fixed strategies and recover latent environmental structure.
Driving with DINO: Vision Foundation Features as a Unified Bridge for Sim-to-Real Generation in Autonomous Driving
Feb 09, 2026Driven by the emergence of Controllable Video Diffusion, existing Sim2Real methods for autonomous driving video generation typically rely on explicit intermediate representations to bridge the domain gap. However, these modalities face a fundamental Consistency-Realism Dilemma. Low-level signals (e.g., edges, blurred images) ensure precise control but compromise realism by "baking in" synthetic artifacts, whereas high-level priors (e.g., depth, semantics, HDMaps) facilitate photorealism but lack the structural detail required for consistent guidance. In this work, we present Driving with DINO (DwD), a novel framework that leverages Vision Foundation Module (VFM) features as a unified bridge between the simulation and real-world domains. We first identify that these features encode a spectrum of information, from high-level semantics to fine-grained structure. To effectively utilize this, we employ Principal Subspace Projection to discard the high-frequency elements responsible for "texture baking," while concurrently introducing Random Channel Tail Drop to mitigate the structural loss inherent in rigid dimensionality reduction, thereby reconciling realism with control consistency. Furthermore, to fully leverage DINOv3's high-resolution capabilities for enhancing control precision, we introduce a learnable Spatial Alignment Module that adapts these high-resolution features to the diffusion backbone. Finally, we propose a Causal Temporal Aggregator employing causal convolutions to explicitly preserve historical motion context when integrating frame-wise DINO features, which effectively mitigates motion blur and guarantees temporal stability. Project page: https://albertchen98.github.io/DwD-project/
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi Linear: An Expressive, Efficient Attention Architecture
Oct 30, 2025We introduce Kimi Linear, a hybrid linear attention architecture that, for the first time, outperforms full attention under fair comparisons across various scenarios -- including short-context, long-context, and reinforcement learning (RL) scaling regimes. At its core lies Kimi Delta Attention (KDA), an expressive linear attention module that extends Gated DeltaNet with a finer-grained gating mechanism, enabling more effective use of limited finite-state RNN memory. Our bespoke chunkwise algorithm achieves high hardware efficiency through a specialized variant of the Diagonal-Plus-Low-Rank (DPLR) transition matrices, which substantially reduces computation compared to the general DPLR formulation while remaining more consistent with the classical delta rule. We pretrain a Kimi Linear model with 3B activated parameters and 48B total parameters, based on a layerwise hybrid of KDA and Multi-Head Latent Attention (MLA). Our experiments show that with an identical training recipe, Kimi Linear outperforms full MLA with a sizeable margin across all evaluated tasks, while reducing KV cache usage by up to 75% and achieving up to 6 times decoding throughput for a 1M context. These results demonstrate that Kimi Linear can be a drop-in replacement for full attention architectures with superior performance and efficiency, including tasks with longer input and output lengths. To support further research, we open-source the KDA kernel and vLLM implementations, and release the pre-trained and instruction-tuned model checkpoints.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024



This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
See, Hear, and Feel: Smart Sensory Fusion for Robotic Manipulation
Dec 08, 2022



Humans use all of their senses to accomplish different tasks in everyday activities. In contrast, existing work on robotic manipulation mostly relies on one, or occasionally two modalities, such as vision and touch. In this work, we systematically study how visual, auditory, and tactile perception can jointly help robots to solve complex manipulation tasks. We build a robot system that can see with a camera, hear with a contact microphone, and feel with a vision-based tactile sensor, with all three sensory modalities fused with a self-attention model. Results on two challenging tasks, dense packing and pouring, demonstrate the necessity and power of multisensory perception for robotic manipulation: vision displays the global status of the robot but can often suffer from occlusion, audio provides immediate feedback of key moments that are even invisible, and touch offers precise local geometry for decision making. Leveraging all three modalities, our robotic system significantly outperforms prior methods.
EDAssistant: Supporting Exploratory Data Analysis in Computational Notebooks with In-Situ Code Search and Recommendation
Dec 15, 2021
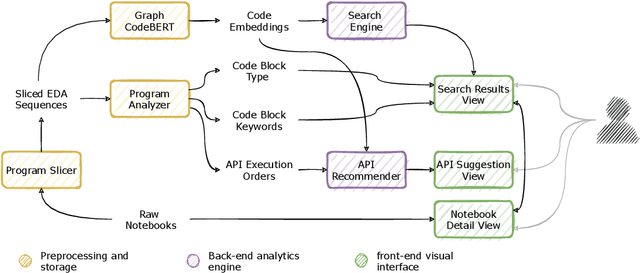
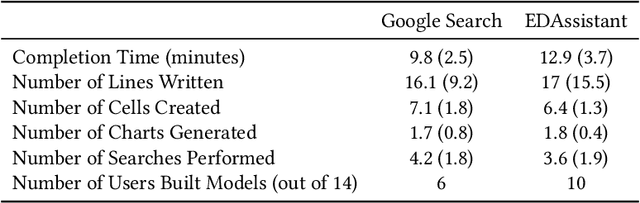
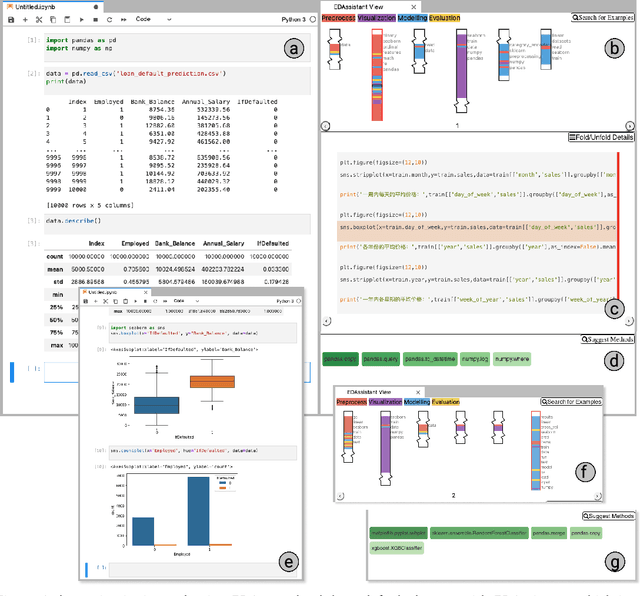
Using computational notebooks (e.g., Jupyter Notebook), data scientists rationalize their exploratory data analysis (EDA) based on their prior experience and external knowledge such as online examples. For novices or data scientists who lack specific knowledge about the dataset or problem to investigate, effectively obtaining and understanding the external information is critical to carry out EDA. This paper presents EDAssistant, a JupyterLab extension that supports EDA with in-situ search of example notebooks and recommendation of useful APIs, powered by novel interactive visualization of search results. The code search and recommendation are enabled by state-of-the-art machine learning models, trained on a large corpus of EDA notebooks collected online. A user study is conducted to investigate both EDAssistant and data scientists' current practice (i.e., using external search engines). The results demonstrate the effectiveness and usefulness of EDAssistant, and participants appreciated its smooth and in-context support of EDA. We also report several design implications regarding code recommendation tools.