 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYisong Yue
Towards Robust Data-Driven Control Synthesis for Nonlinear Systems with Actuation Uncertainty
Nov 21, 2020
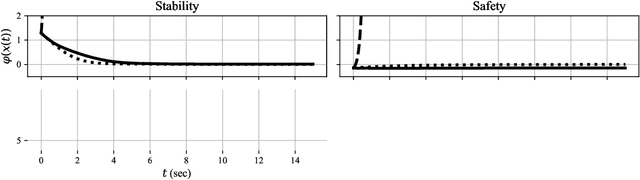
Modern nonlinear control theory seeks to endow systems with properties such as stability and safety, and has been deployed successfully across various domains. Despite this success, model uncertainty remains a significant challenge in ensuring that model-based controllers transfer to real world systems. This paper develops a data-driven approach to robust control synthesis in the presence of model uncertainty using Control Certificate Functions (CCFs), resulting in a convex optimization based controller for achieving properties like stability and safety. An important benefit of our framework is nuanced data-dependent guarantees, which in principle can yield sample-efficient data collection approaches that need not fully determine the input-to-state relationship. This work serves as a starting point for addressing important questions at the intersection of nonlinear control theory and non-parametric learning, both theoretical and in application. We validate the proposed method in simulation with an inverted pendulum in multiple experimental configurations.
On the Benefits of Early Fusion in Multimodal Representation Learning
Nov 14, 2020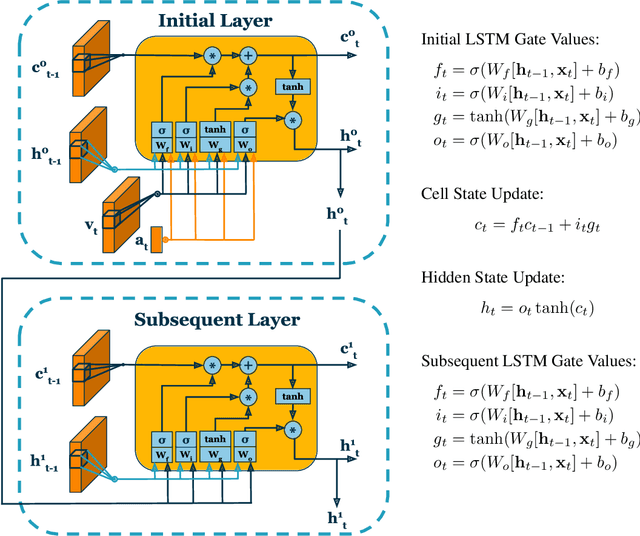
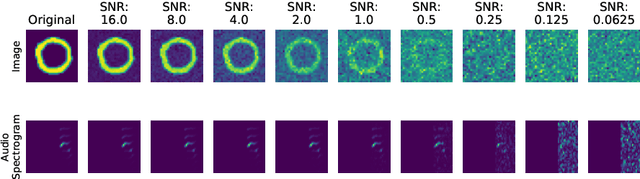
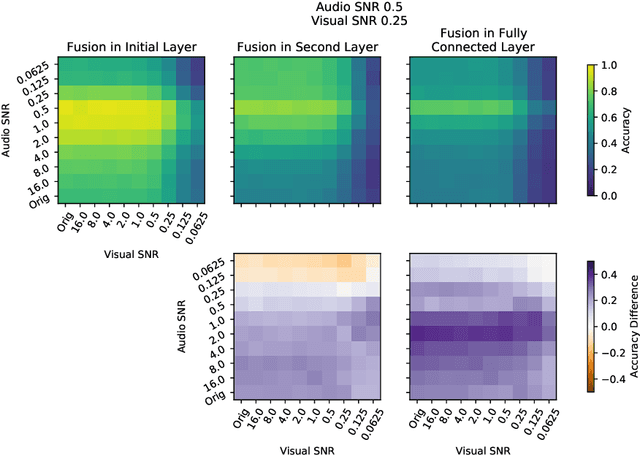
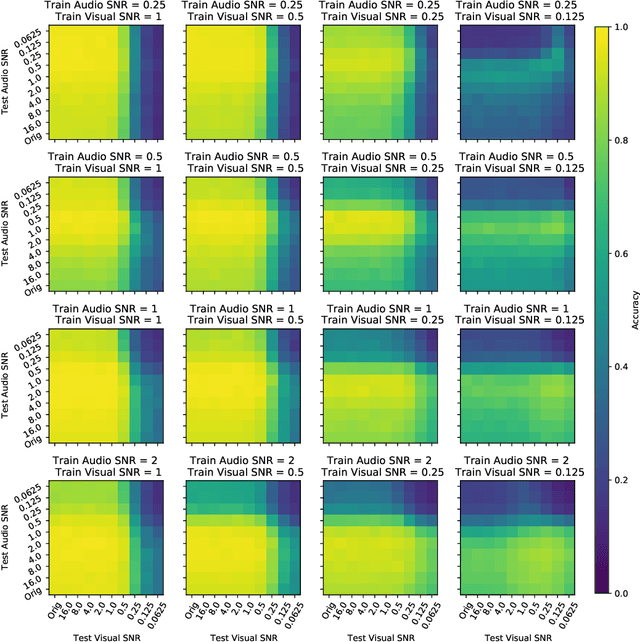
Intelligently reasoning about the world often requires integrating data from multiple modalities, as any individual modality may contain unreliable or incomplete information. Prior work in multimodal learning fuses input modalities only after significant independent processing. On the other hand, the brain performs multimodal processing almost immediately. This divide between conventional multimodal learning and neuroscience suggests that a detailed study of early multimodal fusion could improve artificial multimodal representations. To facilitate the study of early multimodal fusion, we create a convolutional LSTM network architecture that simultaneously processes both audio and visual inputs, and allows us to select the layer at which audio and visual information combines. Our results demonstrate that immediate fusion of audio and visual inputs in the initial C-LSTM layer results in higher performing networks that are more robust to the addition of white noise in both audio and visual inputs.
Machine Learning Based Path Planning for Improved Rover Navigation (Pre-Print Version)
Nov 11, 2020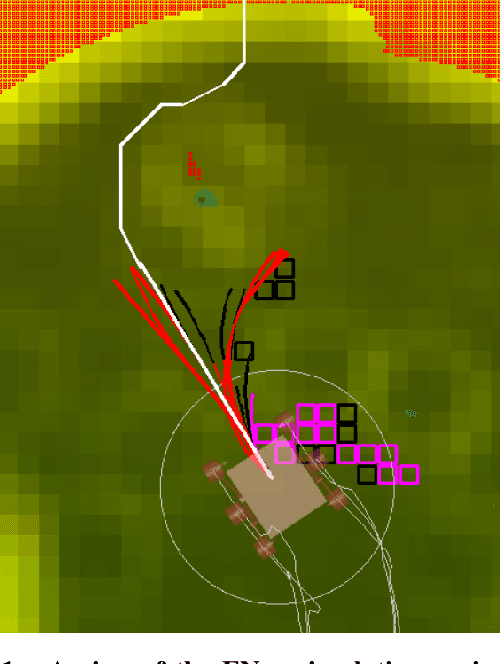
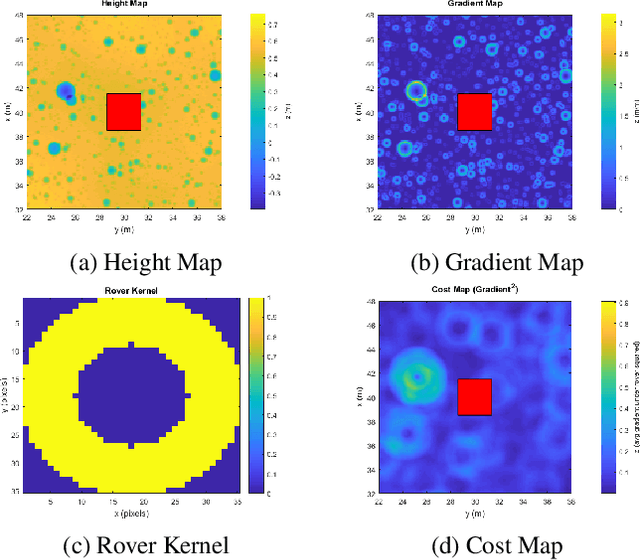

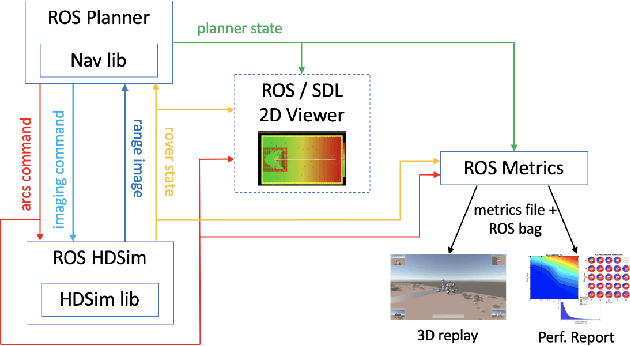
Enhanced AutoNav (ENav), the baseline surface navigation software for NASA's Perseverance rover, sorts a list of candidate paths for the rover to traverse, then uses the Approximate Clearance Evaluation (ACE) algorithm to evaluate whether the most highly ranked paths are safe. ACE is crucial for maintaining the safety of the rover, but is computationally expensive. If the most promising candidates in the list of paths are all found to be infeasible, ENav must continue to search the list and run time-consuming ACE evaluations until a feasible path is found. In this paper, we present two heuristics that, given a terrain heightmap around the rover, produce cost estimates that more effectively rank the candidate paths before ACE evaluation. The first heuristic uses Sobel operators and convolution to incorporate the cost of traversing high-gradient terrain. The second heuristic uses a machine learning (ML) model to predict areas that will be deemed untraversable by ACE. We used physics simulations to collect training data for the ML model and to run Monte Carlo trials to quantify navigation performance across a variety of terrains with various slopes and rock distributions. Compared to ENav's baseline performance, integrating the heuristics can lead to a significant reduction in ACE evaluations and average computation time per planning cycle, increase path efficiency, and maintain or improve the rate of successful traverses. This strategy of targeting specific bottlenecks with ML while maintaining the original ACE safety checks provides an example of how ML can be infused into planetary science missions and other safety-critical software.
ROIAL: Region of Interest Active Learning for Characterizing Exoskeleton Gait Preference Landscapes
Nov 09, 2020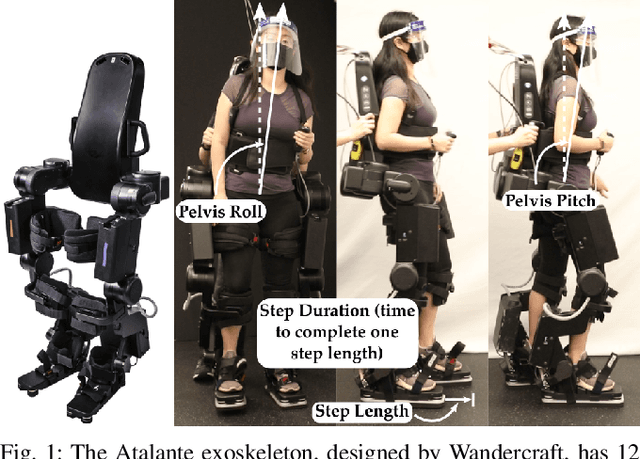

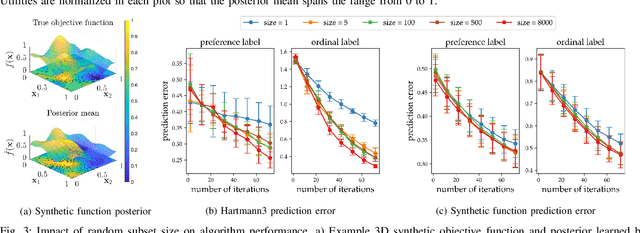
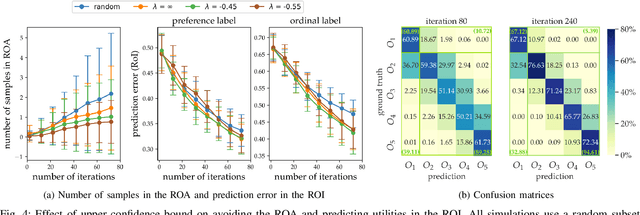
Characterizing what types of exoskeleton gaits are comfortable for users, and understanding the science of walking more generally, require recovering a user's utility landscape. Learning these landscapes is challenging, as walking trajectories are defined by numerous gait parameters, data collection from human trials is expensive, and user safety and comfort must be ensured. This work proposes the Region of Interest Active Learning (ROIAL) framework, which actively learns each user's underlying utility function over a region of interest that ensures safety and comfort. ROIAL learns from ordinal and preference feedback, which are more reliable feedback mechanisms than absolute numerical scores. The algorithm's performance is evaluated both in simulation and experimentally for three able-bodied subjects walking inside of a lower-body exoskeleton. ROIAL learns Bayesian posteriors that predict each exoskeleton user's utility landscape across four exoskeleton gait parameters. The algorithm discovers both commonalities and discrepancies across users' gait preferences and identifies the gait parameters that most influenced user feedback. These results demonstrate the feasibility of recovering gait utility landscapes from limited human trials.
Architecture Agnostic Neural Networks
Nov 05, 2020
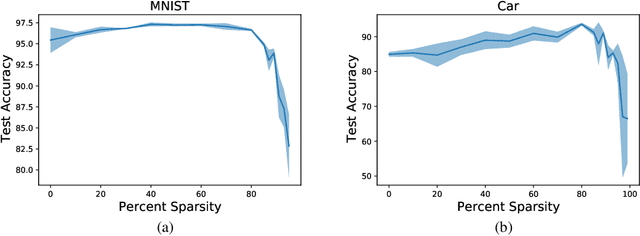
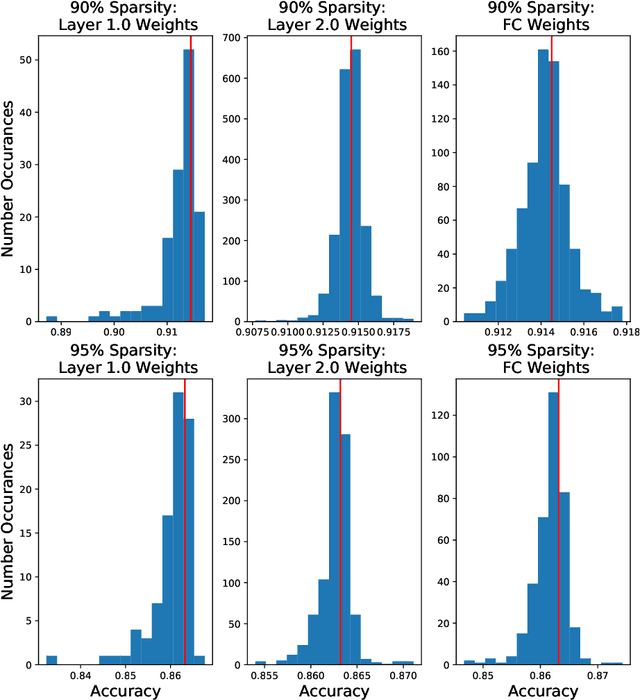

In this paper, we explore an alternate method for synthesizing neural network architectures, inspired by the brain's stochastic synaptic pruning. During a person's lifetime, numerous distinct neuronal architectures are responsible for performing the same tasks. This indicates that biological neural networks are, to some degree, architecture agnostic. However, artificial networks rely on their fine-tuned weights and hand-crafted architectures for their remarkable performance. This contrast begs the question: Can we build artificial architecture agnostic neural networks? To ground this study we utilize sparse, binary neural networks that parallel the brain's circuits. Within this sparse, binary paradigm we sample many binary architectures to create families of architecture agnostic neural networks not trained via backpropagation. These high-performing network families share the same sparsity, distribution of binary weights, and succeed in both static and dynamic tasks. In summation, we create an architecture manifold search procedure to discover families or architecture agnostic neural networks.
Iterative Amortized Policy Optimization
Oct 20, 2020


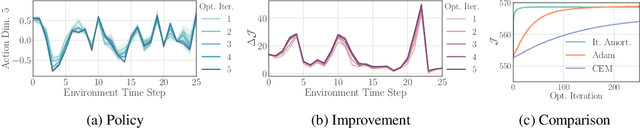
Policy networks are a central feature of deep reinforcement learning (RL) algorithms for continuous control, enabling the estimation and sampling of high-value actions. From the variational inference perspective on RL, policy networks, when employed with entropy or KL regularization, are a form of amortized optimization, optimizing network parameters rather than the policy distributions directly. However, this direct amortized mapping can empirically yield suboptimal policy estimates. Given this perspective, we consider the more flexible class of iterative amortized optimizers. We demonstrate that the resulting technique, iterative amortized policy optimization, yields performance improvements over conventional direct amortization methods on benchmark continuous control tasks.
Distributionally Robust Learning for Unsupervised Domain Adaptation
Oct 08, 2020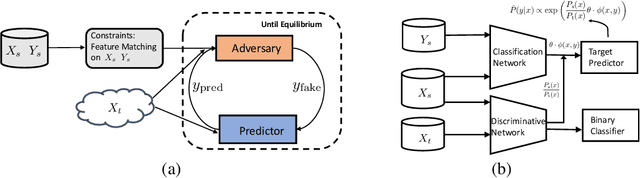
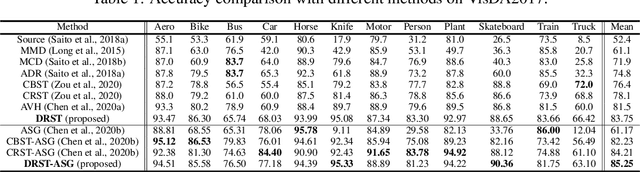
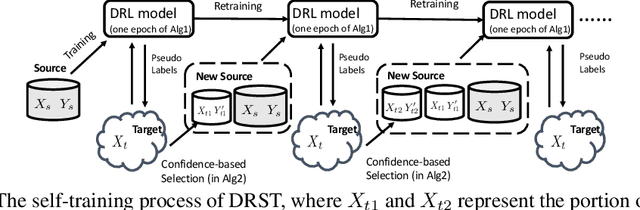
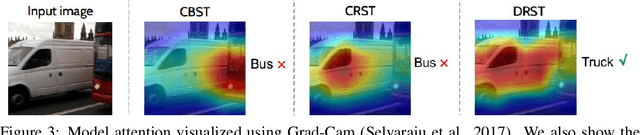
We propose a distributionally robust learning (DRL) method for unsupervised domain adaptation (UDA) that scales to modern computer vision benchmarks. DRL can be naturally formulated as a competitive two-player game between a predictor and an adversary that is allowed to corrupt the labels, subject to certain constraints, and reduces to incorporating a density ratio between the source and target domains (under the standard log loss). This formulation motivates the use of two neural networks that are jointly trained - a discriminative network between the source and target domains for density-ratio estimation, in addition to the standard classification network. The use of a density ratio in DRL prevents the model from being overconfident on target inputs far away from the source domain. Thus, DRL provides conservative confidence estimation in the target domain, even when the target labels are not available. This conservatism motivates the use of DRL in self-training for sample selection, and we term the approach distributionally robust self-training (DRST). In our experiments, DRST generates more calibrated probabilities and achieves state-of-the-art self-training accuracy on benchmark datasets. We demonstrate that DRST captures shape features more effectively, and reduces the extent of distributional shift during self-training.
Learning Differentiable Programs with Admissible Neural Heuristics
Jul 26, 2020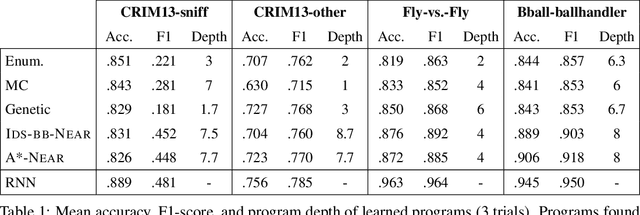
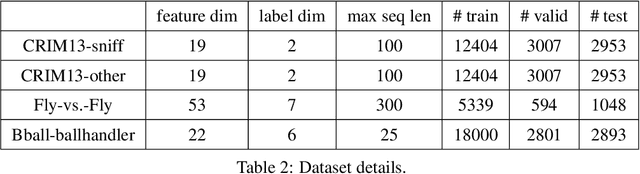
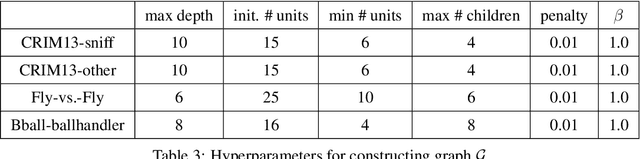
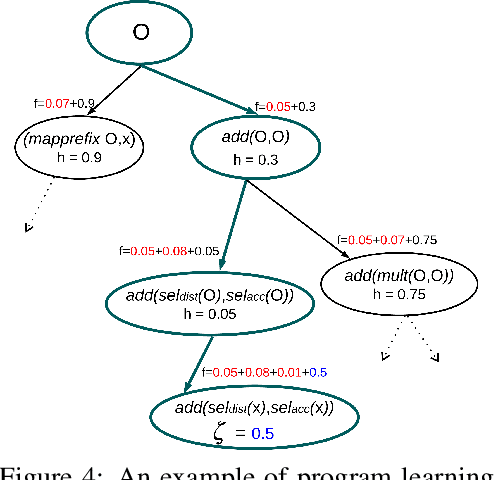
We study the problem of learning differentiable functions expressed as programs in a domain-specific language. Such programmatic models can offer benefits such as composability and interpretability; however, learning them requires optimizing over a combinatorial space of program "architectures". We frame this optimization problem as a search in a weighted graph whose paths encode top-down derivations of program syntax. Our key innovation is to view various classes of neural networks as continuous relaxations over the space of programs, which can then be used to complete any partial program. This relaxed program is differentiable and can be trained end-to-end, and the resulting training loss is an approximately admissible heuristic that can guide the combinatorial search. We instantiate our approach on top of the A-star algorithm and an iteratively deepened branch-and-bound search, and use these algorithms to learn programmatic classifiers in three sequence classification tasks. Our experiments show that the algorithms outperform state-of-the-art methods for program learning, and that they discover programmatic classifiers that yield natural interpretations and achieve competitive accuracy.
Active Learning under Label Shift
Jul 16, 2020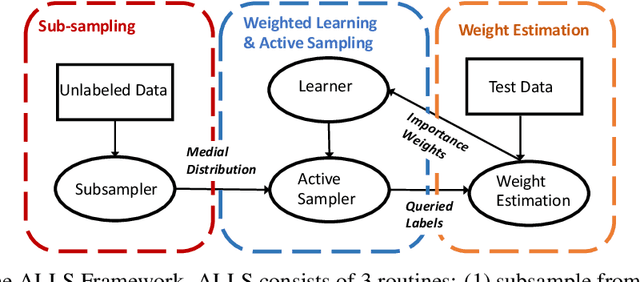
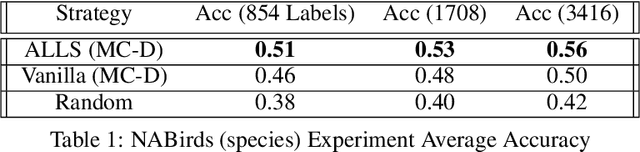
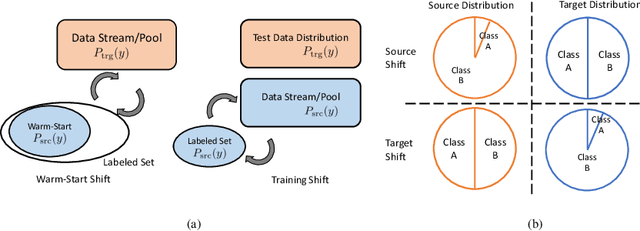
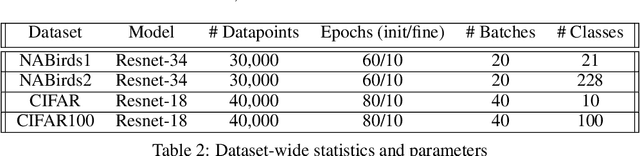
Distribution shift poses a challenge for active data collection in the real world. We address the problem of active learning under label shift and propose ALLS, the first framework for active learning under label shift. ALLS builds on label shift estimation techniques to correct for label shift with a balance of importance weighting and class-balanced sampling. We show a bias-variance trade-off between these two techniques and prove error and sample complexity bounds for a disagreement-based algorithm under ALLS. Experiments across a range of label shift settings demonstrate ALLS consistently improves performance, often reducing sample complexity by more than half an order of magnitude. Ablation studies corroborate the bias-variance trade-off revealed by our theory