 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Learning for Unsupervised Domain Adaptation
Oct 08, 2020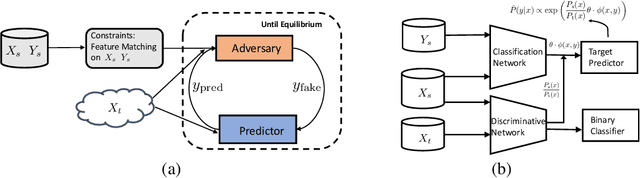
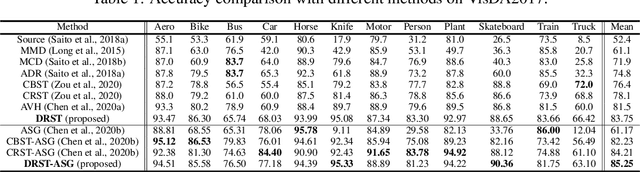
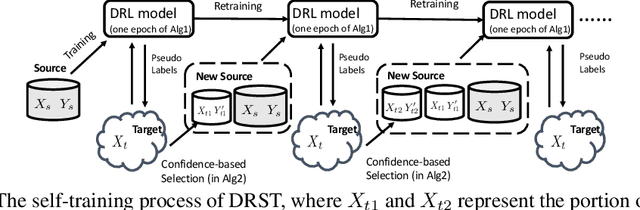
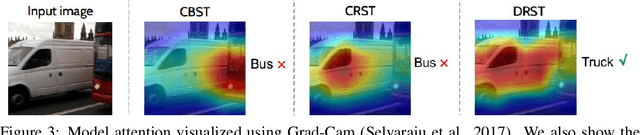
We propose a distributionally robust learning (DRL) method for unsupervised domain adaptation (UDA) that scales to modern computer vision benchmarks. DRL can be naturally formulated as a competitive two-player game between a predictor and an adversary that is allowed to corrupt the labels, subject to certain constraints, and reduces to incorporating a density ratio between the source and target domains (under the standard log loss). This formulation motivates the use of two neural networks that are jointly trained - a discriminative network between the source and target domains for density-ratio estimation, in addition to the standard classification network. The use of a density ratio in DRL prevents the model from being overconfident on target inputs far away from the source domain. Thus, DRL provides conservative confidence estimation in the target domain, even when the target labels are not available. This conservatism motivates the use of DRL in self-training for sample selection, and we term the approach distributionally robust self-training (DRST). In our experiments, DRST generates more calibrated probabilities and achieves state-of-the-art self-training accuracy on benchmark datasets. We demonstrate that DRST captures shape features more effectively, and reduces the extent of distributional shift during self-training.
Learning Differentiable Programs with Admissible Neural Heuristics
Jul 26, 2020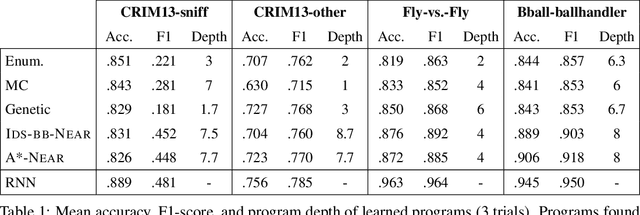
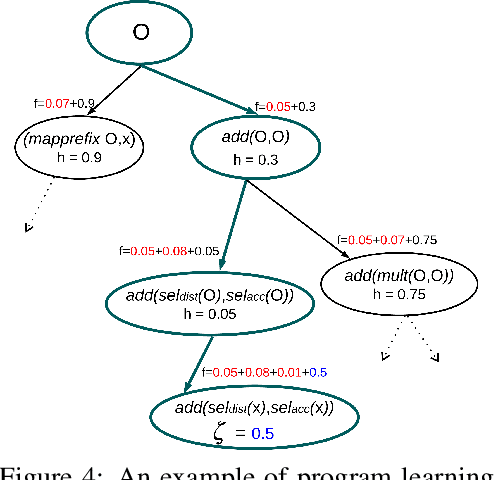
We study the problem of learning differentiable functions expressed as programs in a domain-specific language. Such programmatic models can offer benefits such as composability and interpretability; however, learning them requires optimizing over a combinatorial space of program "architectures". We frame this optimization problem as a search in a weighted graph whose paths encode top-down derivations of program syntax. Our key innovation is to view various classes of neural networks as continuous relaxations over the space of programs, which can then be used to complete any partial program. This relaxed program is differentiable and can be trained end-to-end, and the resulting training loss is an approximately admissible heuristic that can guide the combinatorial search. We instantiate our approach on top of the A-star algorithm and an iteratively deepened branch-and-bound search, and use these algorithms to learn programmatic classifiers in three sequence classification tasks. Our experiments show that the algorithms outperform state-of-the-art methods for program learning, and that they discover programmatic classifiers that yield natural interpretations and achieve competitive accuracy.
Active Learning under Label Shift
Jul 16, 2020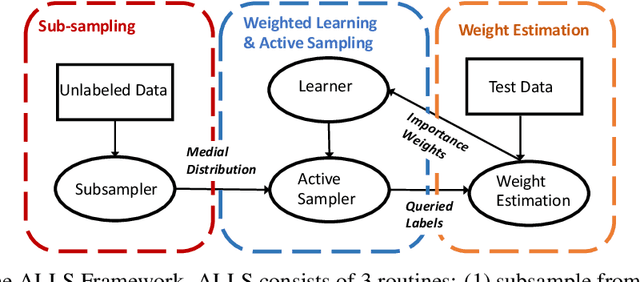
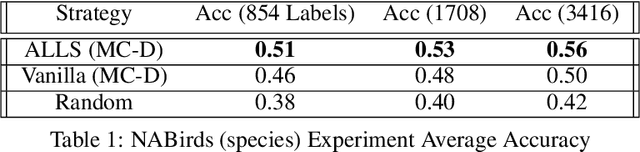
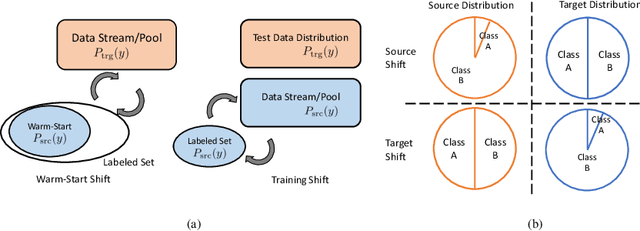
Distribution shift poses a challenge for active data collection in the real world. We address the problem of active learning under label shift and propose ALLS, the first framework for active learning under label shift. ALLS builds on label shift estimation techniques to correct for label shift with a balance of importance weighting and class-balanced sampling. We show a bias-variance trade-off between these two techniques and prove error and sample complexity bounds for a disagreement-based algorithm under ALLS. Experiments across a range of label shift settings demonstrate ALLS consistently improves performance, often reducing sample complexity by more than half an order of magnitude. Ablation studies corroborate the bias-variance trade-off revealed by our theory
Graph Neural Networks for the Prediction of Substrate-Specific Organic Reaction Conditions
Jul 09, 2020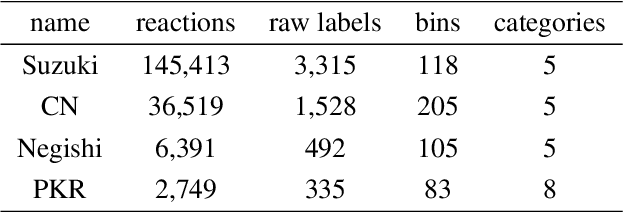
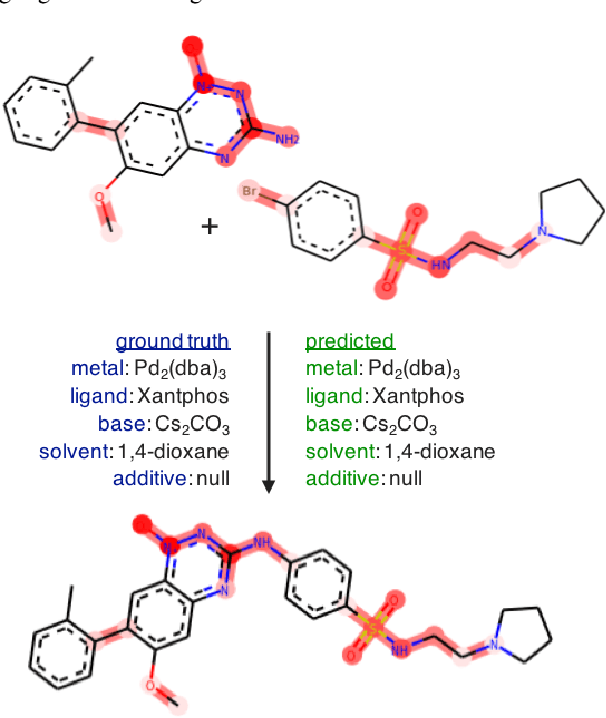
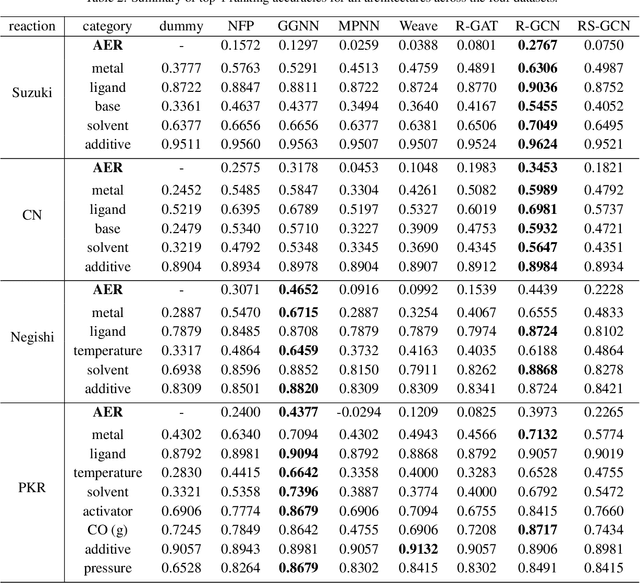
We present a systematic investigation using graph neural networks (GNNs) to model organic chemical reactions. To do so, we prepared a dataset collection of four ubiquitous reactions from the organic chemistry literature. We evaluate seven different GNN architectures for classification tasks pertaining to the identification of experimental reagents and conditions. We find that models are able to identify specific graph features that affect reaction conditions and lead to accurate predictions. The results herein show great promise in advancing molecular machine learning.
Deep Bayesian Quadrature Policy Optimization
Jun 28, 2020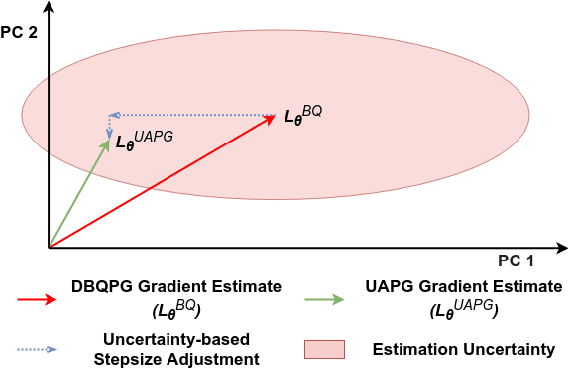

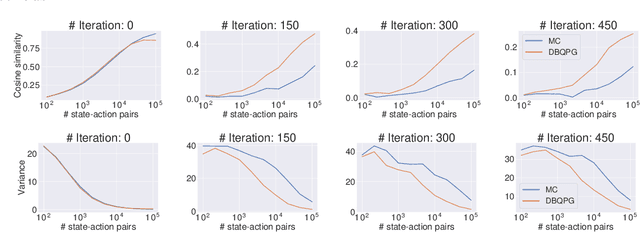
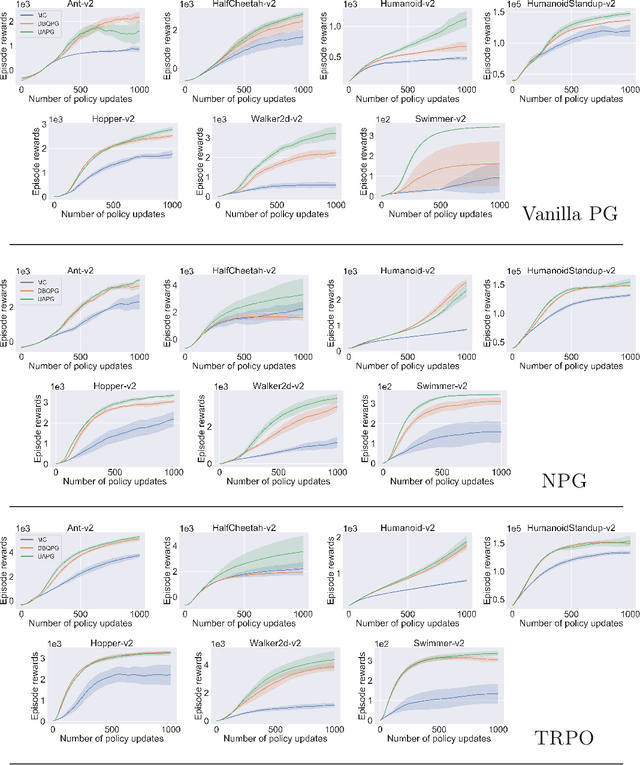
We study the problem of obtaining accurate policy gradient estimates. This challenge manifests in how best to estimate the policy gradient integral equation using a finite number of samples. Monte-Carlo methods have been the default choice for this purpose, despite suffering from high variance in the gradient estimates. On the other hand, more sample efficient alternatives like Bayesian quadrature methods are less scalable due to their high computational complexity. In this work, we propose deep Bayesian quadrature policy gradient (DBQPG), a computationally efficient high-dimensional generalization of Bayesian quadrature, to estimate the policy gradient integral equation. We show that DBQPG can substitute Monte-Carlo estimation in policy gradient methods, and demonstrate its effectiveness on a set of continuous control benchmarks for robotic locomotion. In comparison to Monte-Carlo estimation, DBQPG provides (i) more accurate gradient estimates with a significantly lower variance, (ii) a consistent improvement in the sample complexity and average return for several on-policy deep policy gradient algorithms, and, (iii) a methodological way to quantify the uncertainty in gradient estimation that can be incorporated to further improve the performance.
Average-case Complexity of Teaching Convex Polytopes via Halfspace Queries
Jun 25, 2020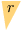

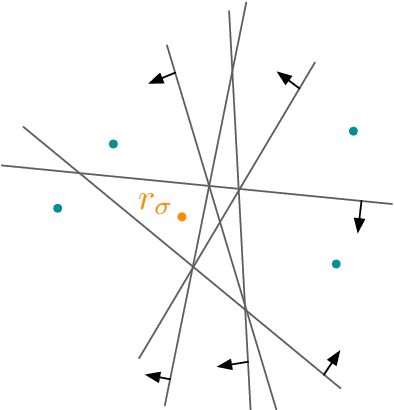
We examine the task of locating a target region among those induced by intersections of $n$ halfspaces in $\mathbb{R}^d$. This generic task connects to fundamental machine learning problems, such as training a perceptron and learning a $\phi$-separable dichotomy. We investigate the average teaching complexity of the task, i.e., the minimal number of samples (halfspace queries) required by a teacher to help a version-space learner in locating a randomly selected target. As our main result, we show that the average-case teaching complexity is $\Theta(d)$, which is in sharp contrast to the worst-case teaching complexity of $\Theta(n)$. If instead, we consider the average-case learning complexity, the bounds have a dependency on $n$ as $\Theta(n)$ for i.i.d. queries and $\Theta(d \log(n))$ for actively chosen queries by the learner. Our proof techniques are based on novel insights from computational geometry, which allow us to count the number of convex polytopes and faces in a Euclidean space depending on the arrangement of halfspaces. Our insights allow us to establish a tight bound on the average-case complexity for $\phi$-separable dichotomies, which generalizes the known $\mathcal{O}(d)$ bound on the average number of "extreme patterns" in the classical computational geometry literature (Cover, 1965).
Learning compositional functions via multiplicative weight updates
Jun 25, 2020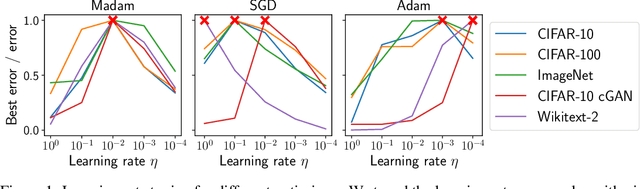
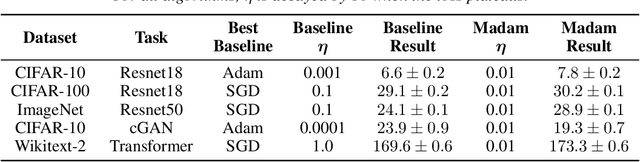

Compositionality is a basic structural feature of both biological and artificial neural networks. Learning compositional functions via gradient descent incurs well known problems like vanishing and exploding gradients, making careful learning rate tuning essential for real-world applications. This paper proves that multiplicative weight updates satisfy a descent lemma tailored to compositional functions. Based on this lemma, we derive Madam---a multiplicative version of the Adam optimiser---and show that it can train state of the art neural network architectures without learning rate tuning. We further show that Madam is easily adapted to train natively compressed neural networks by representing their weights in a logarithmic number system. We conclude by drawing connections between multiplicative weight updates and recent findings about synapses in biology.
Competitive Policy Optimization
Jun 18, 2020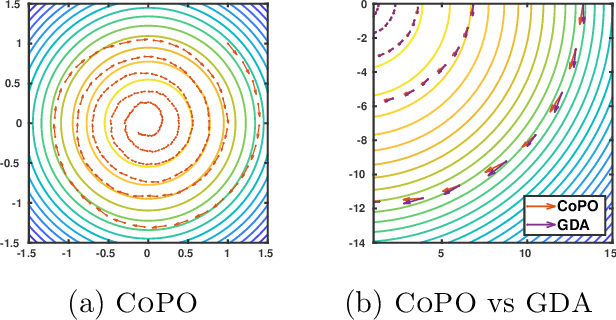

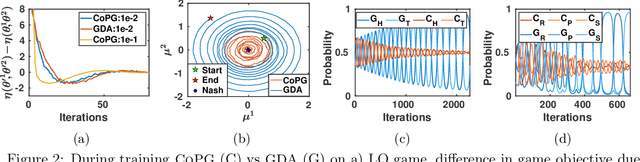

A core challenge in policy optimization in competitive Markov decision processes is the design of efficient optimization methods with desirable convergence and stability properties. To tackle this, we propose competitive policy optimization (CoPO), a novel policy gradient approach that exploits the game-theoretic nature of competitive games to derive policy updates. Motivated by the competitive gradient optimization method, we derive a bilinear approximation of the game objective. In contrast, off-the-shelf policy gradient methods utilize only linear approximations, and hence do not capture interactions among the players. We instantiate CoPO in two ways:(i) competitive policy gradient, and (ii) trust-region competitive policy optimization. We theoretically study these methods, and empirically investigate their behavior on a set of comprehensive, yet challenging, competitive games. We observe that they provide stable optimization, convergence to sophisticated strategies, and higher scores when played against baseline policy gradient methods.
Chance-Constrained Trajectory Optimization for Safe Exploration and Learning of Nonlinear Systems
May 09, 2020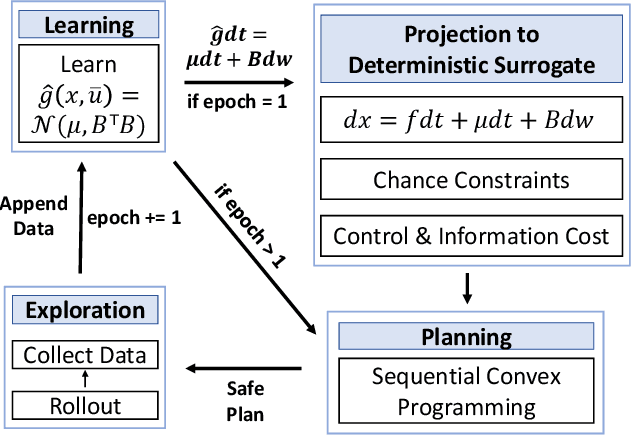
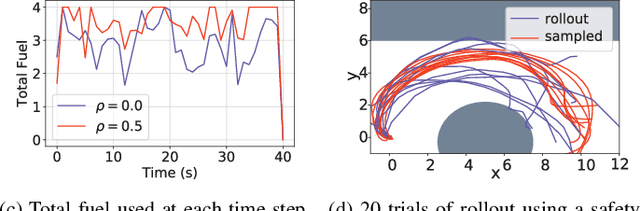
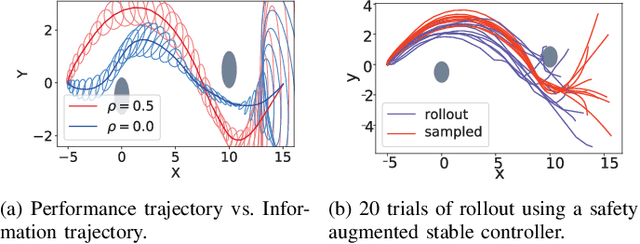
Learning-based control algorithms require collection of abundant supervision for training. Safe exploration algorithms enable this data collection to proceed safely even when only partial knowledge is available. In this paper, we present a new episodic framework to design a sub-optimal pool of motion plans that aid exploration for learning unknown residual dynamics under safety constraints. We derive an iterative convex optimization algorithm that solves an information-cost Stochastic Nonlinear Optimal Control problem (Info-SNOC), subject to chance constraints and approximated dynamics to compute a safe trajectory. The optimization objective encodes both performance and exploration, and the safety is incorporated as distributionally robust chance constraints. The dynamics are predicted from a robust learning model. We prove the safety of rollouts from our exploration method and reduction in uncertainty over epochs ensuring consistency of our learning method. We validate the effectiveness of Info-SNOC by designing and implementing a pool of safe trajectories for a planar robot.
A General Large Neighborhood Search Framework for Solving Integer Programs
Mar 29, 2020
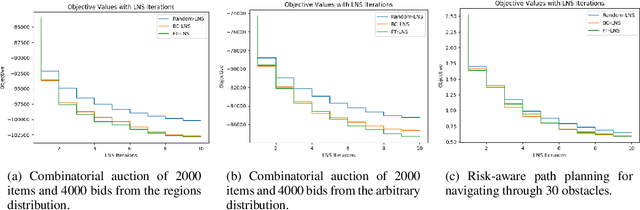
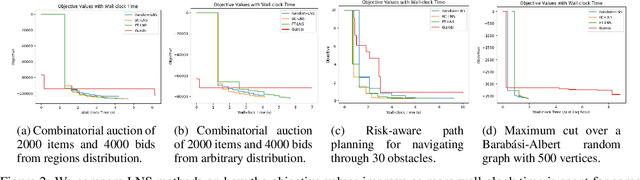

This paper studies how to design abstractions of large-scale combinatorial optimization problems that can leverage existing state-of-the-art solvers in general purpose ways, and that are amenable to data-driven design. The goal is to arrive at new approaches that can reliably outperform existing solvers in wall-clock time. We focus on solving integer programs, and ground our approach in the large neighborhood search (LNS) paradigm, which iteratively chooses a subset of variables to optimize while leaving the remainder fixed. The appeal of LNS is that it can easily use any existing solver as a subroutine, and thus can inherit the benefits of carefully engineered heuristic approaches and their software implementations. We also show that one can learn a good neighborhood selector from training data. Through an extensive empirical validation, we demonstrate that our LNS framework can significantly outperform, in wall-clock time, compared to state-of-the-art commercial solvers such as Gurobi.