 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Them Ask and Answer: Jailbreaking Large Language Models in Few Queries via Disguise and Reconstruction
Feb 28, 2024



In recent years, large language models (LLMs) have demonstrated notable success across various tasks, but the trustworthiness of LLMs is still an open problem. One specific threat is the potential to generate toxic or harmful responses. Attackers can craft adversarial prompts that induce harmful responses from LLMs. In this work, we pioneer a theoretical foundation in LLMs security by identifying bias vulnerabilities within the safety fine-tuning and design a black-box jailbreak method named DRA (Disguise and Reconstruction Attack), which conceals harmful instructions through disguise and prompts the model to reconstruct the original harmful instruction within its completion. We evaluate DRA across various open-source and close-source models, showcasing state-of-the-art jailbreak success rates and attack efficiency. Notably, DRA boasts a 90\% attack success rate on LLM chatbots GPT-4.
BSPA: Exploring Black-box Stealthy Prompt Attacks against Image Generators
Feb 23, 2024Extremely large image generators offer significant transformative potential across diverse sectors. It allows users to design specific prompts to generate realistic images through some black-box APIs. However, some studies reveal that image generators are notably susceptible to attacks and generate Not Suitable For Work (NSFW) contents by manually designed toxin texts, especially imperceptible to human observers. We urgently need a multitude of universal and transferable prompts to improve the safety of image generators, especially black-box-released APIs. Nevertheless, they are constrained by labor-intensive design processes and heavily reliant on the quality of the given instructions. To achieve this, we introduce a black-box stealthy prompt attack (BSPA) that adopts a retriever to simulate attacks from API users. It can effectively harness filter scores to tune the retrieval space of sensitive words for matching the input prompts, thereby crafting stealthy prompts tailored for image generators. Significantly, this approach is model-agnostic and requires no internal access to the model's features, ensuring its applicability to a wide range of image generators. Building on BSPA, we have constructed an automated prompt tool and a comprehensive prompt attack dataset (NSFWeval). Extensive experiments demonstrate that BSPA effectively explores the security vulnerabilities in a variety of state-of-the-art available black-box models, including Stable Diffusion XL, Midjourney, and DALL-E 2/3. Furthermore, we develop a resilient text filter and offer targeted recommendations to ensure the security of image generators against prompt attacks in the future.
Your Diffusion Model is Secretly a Certifiably Robust Classifier
Feb 13, 2024



Diffusion models are recently employed as generative classifiers for robust classification. However, a comprehensive theoretical understanding of the robustness of diffusion classifiers is still lacking, leading us to question whether they will be vulnerable to future stronger attacks. In this study, we propose a new family of diffusion classifiers, named Noised Diffusion Classifiers~(NDCs), that possess state-of-the-art certified robustness. Specifically, we generalize the diffusion classifiers to classify Gaussian-corrupted data by deriving the evidence lower bounds (ELBOs) for these distributions, approximating the likelihood using the ELBO, and calculating classification probabilities via Bayes' theorem. We integrate these generalized diffusion classifiers with randomized smoothing to construct smoothed classifiers possessing non-constant Lipschitzness. Experimental results demonstrate the superior certified robustness of our proposed NDCs. Notably, we are the first to achieve 80\%+ and 70\%+ certified robustness on CIFAR-10 under adversarial perturbations with $\ell_2$ norm less than 0.25 and 0.5, respectively, using a single off-the-shelf diffusion model without any additional data.
Discovering Universal Semantic Triggers for Text-to-Image Synthesis
Feb 12, 2024



Recently text-to-image models have gained widespread attention in the community due to their controllable and high-quality generation ability. However, the robustness of such models and their potential ethical issues have not been fully explored. In this paper, we introduce Universal Semantic Trigger, a meaningless token sequence that can be added at any location within the input text yet can induce generated images towards a preset semantic target.To thoroughly investigate it, we propose Semantic Gradient-based Search (SGS) framework. SGS automatically discovers the potential universal semantic triggers based on the given semantic targets. Furthermore, we design evaluation metrics to comprehensively evaluate semantic shift of images caused by these triggers. And our empirical analyses reveal that the mainstream open-source text-to-image models are vulnerable to our triggers, which could pose significant ethical threats. Our work contributes to a further understanding of text-to-image synthesis and helps users to automatically auditing their models before deployment.
Towards Transferable Targeted 3D Adversarial Attack in the Physical World
Dec 15, 2023



Compared with transferable untargeted attacks, transferable targeted adversarial attacks could specify the misclassification categories of adversarial samples, posing a greater threat to security-critical tasks. In the meanwhile, 3D adversarial samples, due to their potential of multi-view robustness, can more comprehensively identify weaknesses in existing deep learning systems, possessing great application value. However, the field of transferable targeted 3D adversarial attacks remains vacant. The goal of this work is to develop a more effective technique that could generate transferable targeted 3D adversarial examples, filling the gap in this field. To achieve this goal, we design a novel framework named TT3D that could rapidly reconstruct from few multi-view images into Transferable Targeted 3D textured meshes. While existing mesh-based texture optimization methods compute gradients in the high-dimensional mesh space and easily fall into local optima, leading to unsatisfactory transferability and distinct distortions, TT3D innovatively performs dual optimization towards both feature grid and Multi-layer Perceptron (MLP) parameters in the grid-based NeRF space, which significantly enhances black-box transferability while enjoying naturalness. Experimental results show that TT3D not only exhibits superior cross-model transferability but also maintains considerable adaptability across different renders and vision tasks. More importantly, we produce 3D adversarial examples with 3D printing techniques in the real world and verify their robust performance under various scenarios.
Focus on Hiders: Exploring Hidden Threats for Enhancing Adversarial Training
Dec 12, 2023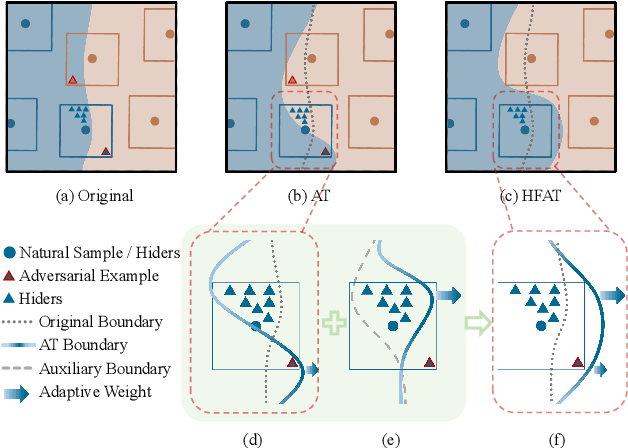
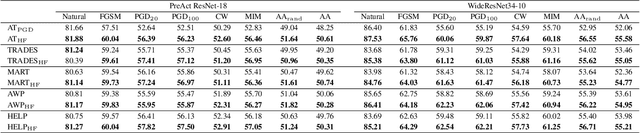
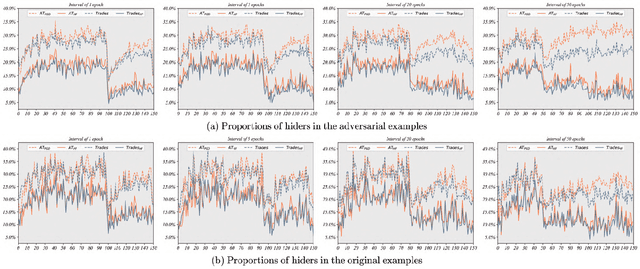
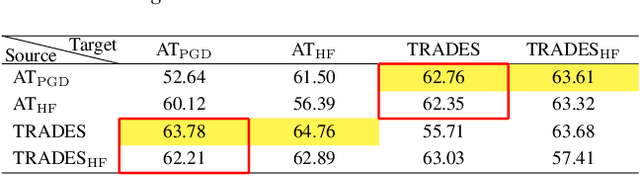
Adversarial training is often formulated as a min-max problem, however, concentrating only on the worst adversarial examples causes alternating repetitive confusion of the model, i.e., previously defended or correctly classified samples are not defensible or accurately classifiable in subsequent adversarial training. We characterize such non-ignorable samples as "hiders", which reveal the hidden high-risk regions within the secure area obtained through adversarial training and prevent the model from finding the real worst cases. We demand the model to prevent hiders when defending against adversarial examples for improving accuracy and robustness simultaneously. By rethinking and redefining the min-max optimization problem for adversarial training, we propose a generalized adversarial training algorithm called Hider-Focused Adversarial Training (HFAT). HFAT introduces the iterative evolution optimization strategy to simplify the optimization problem and employs an auxiliary model to reveal hiders, effectively combining the optimization directions of standard adversarial training and prevention hiders. Furthermore, we introduce an adaptive weighting mechanism that facilitates the model in adaptively adjusting its focus between adversarial examples and hiders during different training periods. We demonstrate the effectiveness of our method based on extensive experiments, and ensure that HFAT can provide higher robustness and accuracy.
Machine Vision Therapy: Multimodal Large Language Models Can Enhance Visual Robustness via Denoising In-Context Learning
Dec 05, 2023



Although vision models such as Contrastive Language-Image Pre-Training (CLIP) show impressive generalization performance, their zero-shot robustness is still limited under Out-of-Distribution (OOD) scenarios without fine-tuning. Instead of undesirably providing human supervision as commonly done, it is possible to take advantage of Multi-modal Large Language Models (MLLMs) that hold powerful visual understanding abilities. However, MLLMs are shown to struggle with vision problems due to the incompatibility of tasks, thus hindering their utilization. In this paper, we propose to effectively leverage MLLMs to conduct Machine Vision Therapy which aims to rectify the noisy predictions from vision models. By fine-tuning with the denoised labels, the learning model performance can be boosted in an unsupervised manner. To solve the incompatibility issue, we propose a novel Denoising In-Context Learning (DICL) strategy to align vision tasks with MLLMs. Concretely, by estimating a transition matrix that captures the probability of one class being confused with another, an instruction containing a correct exemplar and an erroneous one from the most probable noisy class can be constructed. Such an instruction can help any MLLMs with ICL ability to detect and rectify incorrect predictions of vision models. Through extensive experiments on ImageNet, WILDS, DomainBed, and other OOD datasets, we carefully validate the quantitative and qualitative effectiveness of our method. Our code is available at https://github.com/tmllab/Machine_Vision_Therapy.
Evil Geniuses: Delving into the Safety of LLM-based Agents
Nov 20, 2023



The rapid advancements in large language models (LLMs) have led to a resurgence in LLM-based agents, which demonstrate impressive human-like behaviors and cooperative capabilities in various interactions and strategy formulations. However, evaluating the safety of LLM-based agents remains a complex challenge. This paper elaborately conducts a series of manual jailbreak prompts along with a virtual chat-powered evil plan development team, dubbed Evil Geniuses, to thoroughly probe the safety aspects of these agents. Our investigation reveals three notable phenomena: 1) LLM-based agents exhibit reduced robustness against malicious attacks. 2) the attacked agents could provide more nuanced responses. 3) the detection of the produced improper responses is more challenging. These insights prompt us to question the effectiveness of LLM-based attacks on agents, highlighting vulnerabilities at various levels and within different role specializations within the system/agent of LLM-based agents. Extensive evaluation and discussion reveal that LLM-based agents face significant challenges in safety and yield insights for future research. Our code is available at https://github.com/T1aNS1R/Evil-Geniuses.
How Robust is Google's Bard to Adversarial Image Attacks?
Sep 21, 2023



Multimodal Large Language Models (MLLMs) that integrate text and other modalities (especially vision) have achieved unprecedented performance in various multimodal tasks. However, due to the unsolved adversarial robustness problem of vision models, MLLMs can have more severe safety and security risks by introducing the vision inputs. In this work, we study the adversarial robustness of Google's Bard, a competitive chatbot to ChatGPT that released its multimodal capability recently, to better understand the vulnerabilities of commercial MLLMs. By attacking white-box surrogate vision encoders or MLLMs, the generated adversarial examples can mislead Bard to output wrong image descriptions with a 22% success rate based solely on the transferability. We show that the adversarial examples can also attack other MLLMs, e.g., a 26% attack success rate against Bing Chat and a 86% attack success rate against ERNIE bot. Moreover, we identify two defense mechanisms of Bard, including face detection and toxicity detection of images. We design corresponding attacks to evade these defenses, demonstrating that the current defenses of Bard are also vulnerable. We hope this work can deepen our understanding on the robustness of MLLMs and facilitate future research on defenses. Our code is available at https://github.com/thu-ml/Attack-Bard.
Robustness and Generalizability of Deepfake Detection: A Study with Diffusion Models
Sep 05, 2023The rise of deepfake images, especially of well-known personalities, poses a serious threat to the dissemination of authentic information. To tackle this, we present a thorough investigation into how deepfakes are produced and how they can be identified. The cornerstone of our research is a rich collection of artificial celebrity faces, titled DeepFakeFace (DFF). We crafted the DFF dataset using advanced diffusion models and have shared it with the community through online platforms. This data serves as a robust foundation to train and test algorithms designed to spot deepfakes. We carried out a thorough review of the DFF dataset and suggest two evaluation methods to gauge the strength and adaptability of deepfake recognition tools. The first method tests whether an algorithm trained on one type of fake images can recognize those produced by other methods. The second evaluates the algorithm's performance with imperfect images, like those that are blurry, of low quality, or compressed. Given varied results across deepfake methods and image changes, our findings stress the need for better deepfake detectors. Our DFF dataset and tests aim to boost the development of more effective tools against deepfakes.