 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepthShrinker: A New Compression Paradigm Towards Boosting Real-Hardware Efficiency of Compact Neural Networks
Jun 02, 2022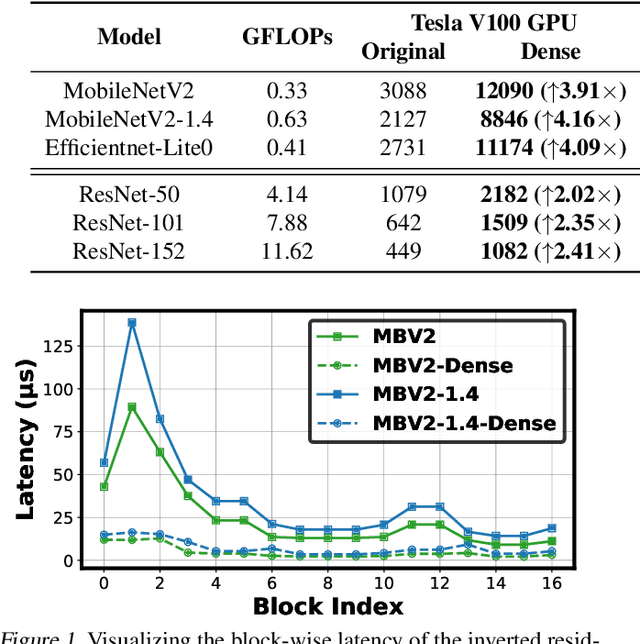
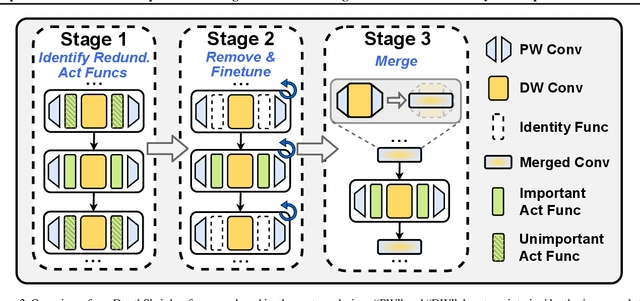
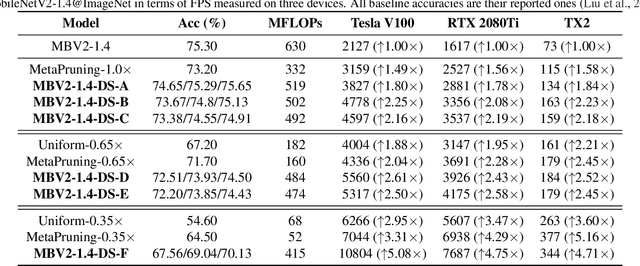
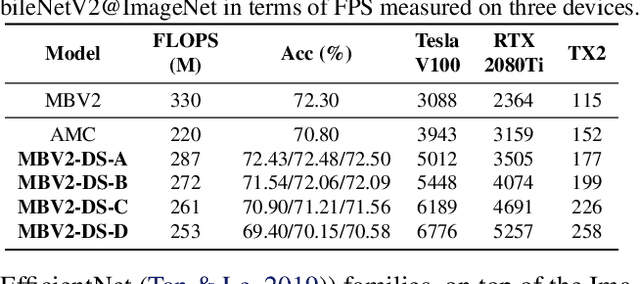
Efficient deep neural network (DNN) models equipped with compact operators (e.g., depthwise convolutions) have shown great potential in reducing DNNs' theoretical complexity (e.g., the total number of weights/operations) while maintaining a decent model accuracy. However, existing efficient DNNs are still limited in fulfilling their promise in boosting real-hardware efficiency, due to their commonly adopted compact operators' low hardware utilization. In this work, we open up a new compression paradigm for developing real-hardware efficient DNNs, leading to boosted hardware efficiency while maintaining model accuracy. Interestingly, we observe that while some DNN layers' activation functions help DNNs' training optimization and achievable accuracy, they can be properly removed after training without compromising the model accuracy. Inspired by this observation, we propose a framework dubbed DepthShrinker, which develops hardware-friendly compact networks via shrinking the basic building blocks of existing efficient DNNs that feature irregular computation patterns into dense ones with much improved hardware utilization and thus real-hardware efficiency. Excitingly, our DepthShrinker framework delivers hardware-friendly compact networks that outperform both state-of-the-art efficient DNNs and compression techniques, e.g., a 3.06\% higher accuracy and 1.53$\times$ throughput on Tesla V100 over SOTA channel-wise pruning method MetaPruning. Our codes are available at: https://github.com/RICE-EIC/DepthShrinker.
ShiftAddNAS: Hardware-Inspired Search for More Accurate and Efficient Neural Networks
May 17, 2022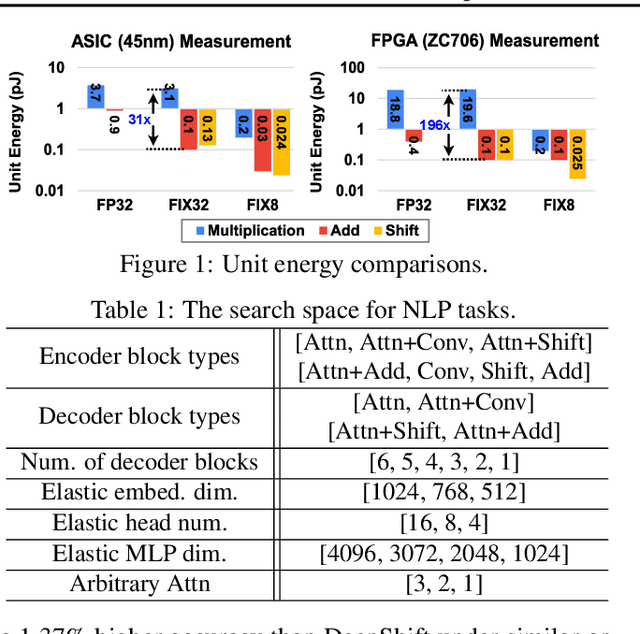
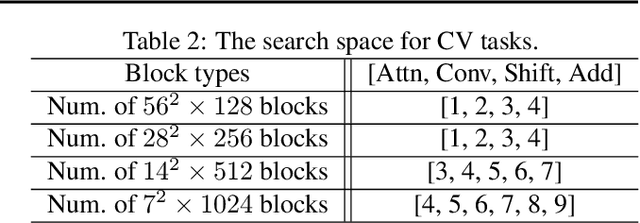
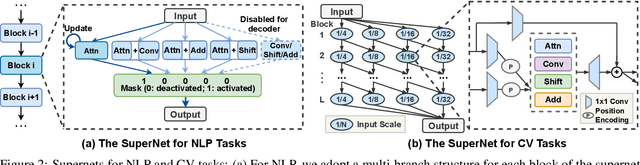
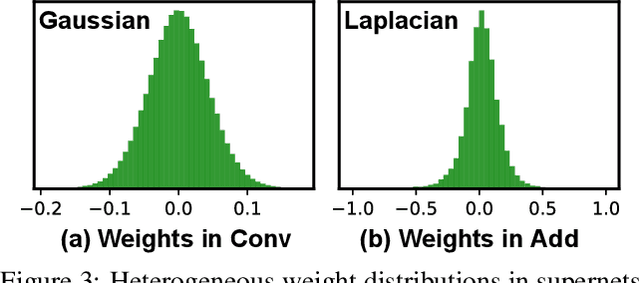
Neural networks (NNs) with intensive multiplications (e.g., convolutions and transformers) are capable yet power hungry, impeding their more extensive deployment into resource-constrained devices. As such, multiplication-free networks, which follow a common practice in energy-efficient hardware implementation to parameterize NNs with more efficient operators (e.g., bitwise shifts and additions), have gained growing attention. However, multiplication-free networks usually under-perform their vanilla counterparts in terms of the achieved accuracy. To this end, this work advocates hybrid NNs that consist of both powerful yet costly multiplications and efficient yet less powerful operators for marrying the best of both worlds, and proposes ShiftAddNAS, which can automatically search for more accurate and more efficient NNs. Our ShiftAddNAS highlights two enablers. Specifically, it integrates (1) the first hybrid search space that incorporates both multiplication-based and multiplication-free operators for facilitating the development of both accurate and efficient hybrid NNs; and (2) a novel weight sharing strategy that enables effective weight sharing among different operators that follow heterogeneous distributions (e.g., Gaussian for convolutions vs. Laplacian for add operators) and simultaneously leads to a largely reduced supernet size and much better searched networks. Extensive experiments and ablation studies on various models, datasets, and tasks consistently validate the efficacy of ShiftAddNAS, e.g., achieving up to a +7.7% higher accuracy or a +4.9 better BLEU score compared to state-of-the-art NN, while leading to up to 93% or 69% energy and latency savings, respectively. Codes and pretrained models are available at https://github.com/RICE-EIC/ShiftAddNAS.
Patch-Fool: Are Vision Transformers Always Robust Against Adversarial Perturbations?
Apr 05, 2022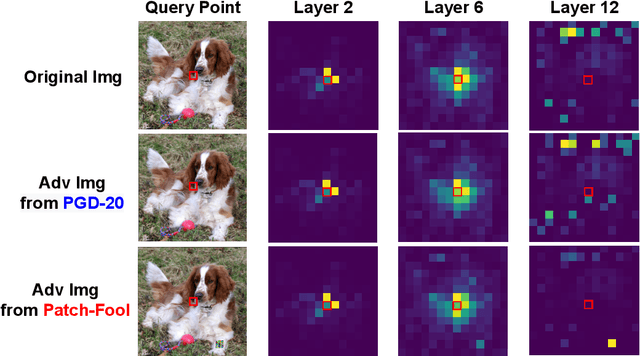
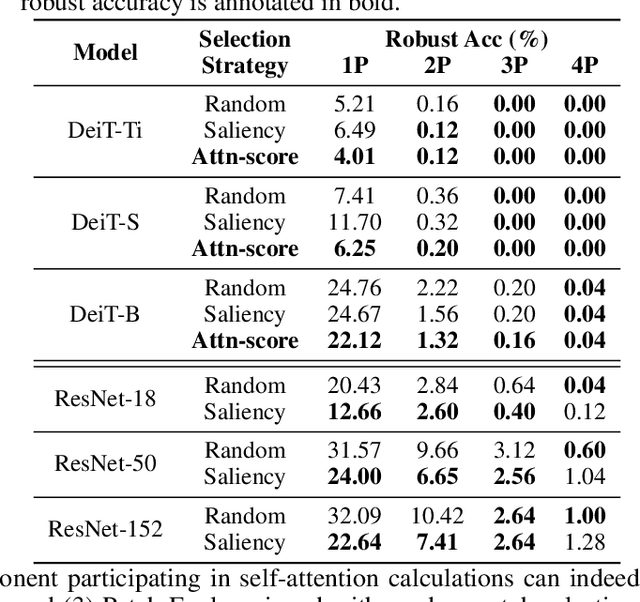
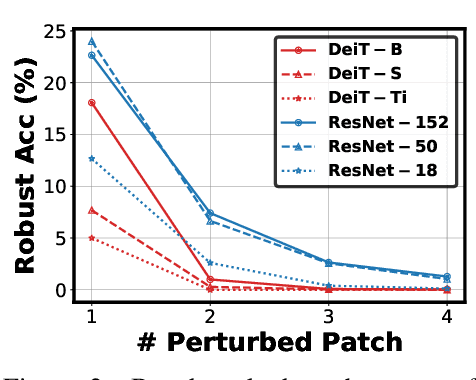
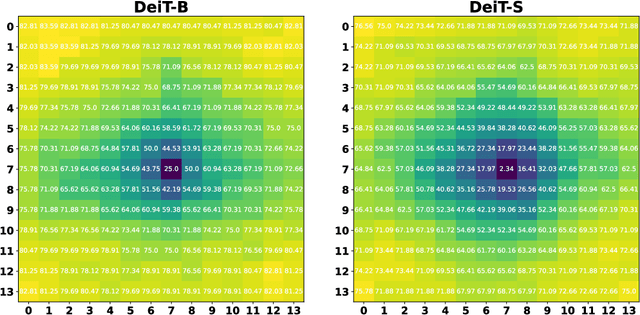
Vision transformers (ViTs) have recently set off a new wave in neural architecture design thanks to their record-breaking performance in various vision tasks. In parallel, to fulfill the goal of deploying ViTs into real-world vision applications, their robustness against potential malicious attacks has gained increasing attention. In particular, recent works show that ViTs are more robust against adversarial attacks as compared with convolutional neural networks (CNNs), and conjecture that this is because ViTs focus more on capturing global interactions among different input/feature patches, leading to their improved robustness to local perturbations imposed by adversarial attacks. In this work, we ask an intriguing question: "Under what kinds of perturbations do ViTs become more vulnerable learners compared to CNNs?" Driven by this question, we first conduct a comprehensive experiment regarding the robustness of both ViTs and CNNs under various existing adversarial attacks to understand the underlying reason favoring their robustness. Based on the drawn insights, we then propose a dedicated attack framework, dubbed Patch-Fool, that fools the self-attention mechanism by attacking its basic component (i.e., a single patch) with a series of attention-aware optimization techniques. Interestingly, our Patch-Fool framework shows for the first time that ViTs are not necessarily more robust than CNNs against adversarial perturbations. In particular, we find that ViTs are more vulnerable learners compared with CNNs against our Patch-Fool attack which is consistent across extensive experiments, and the observations from Sparse/Mild Patch-Fool, two variants of Patch-Fool, indicate an intriguing insight that the perturbation density and strength on each patch seem to be the key factors that influence the robustness ranking between ViTs and CNNs.
BNS-GCN: Efficient Full-Graph Training of Graph Convolutional Networks with Partition-Parallelism and Random Boundary Node Sampling
Mar 26, 2022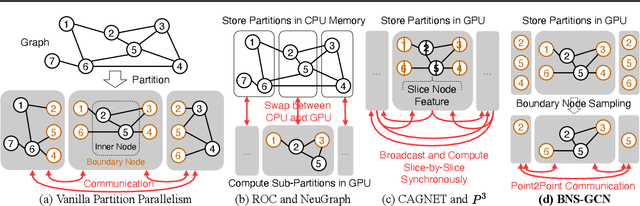

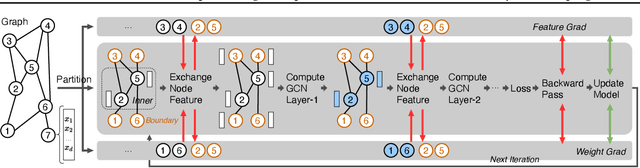

Graph Convolutional Networks (GCNs) have emerged as the state-of-the-art method for graph-based learning tasks. However, training GCNs at scale is still challenging, hindering both the exploration of more sophisticated GCN architectures and their applications to real-world large graphs. While it might be natural to consider graph partition and distributed training for tackling this challenge, this direction has only been slightly scratched the surface in the previous works due to the limitations of existing designs. In this work, we first analyze why distributed GCN training is ineffective and identify the underlying cause to be the excessive number of boundary nodes of each partitioned subgraph, which easily explodes the memory and communication costs for GCN training. Furthermore, we propose a simple yet effective method dubbed BNS-GCN that adopts random Boundary-Node-Sampling to enable efficient and scalable distributed GCN training. Experiments and ablation studies consistently validate the effectiveness of BNS-GCN, e.g., boosting the throughput by up to 16.2x and reducing the memory usage by up to 58%, while maintaining a full-graph accuracy. Furthermore, both theoretical and empirical analysis show that BNS-GCN enjoys a better convergence than existing sampling-based methods. We believe that our BNS-GCN has opened up a new paradigm for enabling GCN training at scale. The code is available at https://github.com/RICE-EIC/BNS-GCN.
PipeGCN: Efficient Full-Graph Training of Graph Convolutional Networks with Pipelined Feature Communication
Mar 20, 2022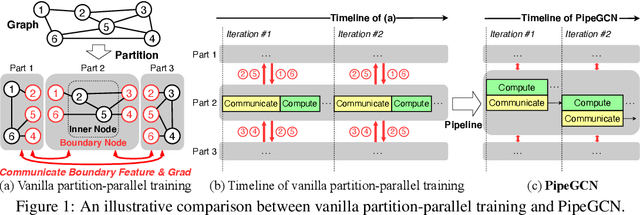

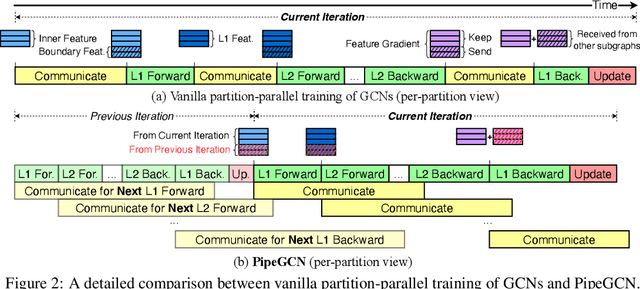

Graph Convolutional Networks (GCNs) is the state-of-the-art method for learning graph-structured data, and training large-scale GCNs requires distributed training across multiple accelerators such that each accelerator is able to hold a partitioned subgraph. However, distributed GCN training incurs prohibitive overhead of communicating node features and feature gradients among partitions for every GCN layer during each training iteration, limiting the achievable training efficiency and model scalability. To this end, we propose PipeGCN, a simple yet effective scheme that hides the communication overhead by pipelining inter-partition communication with intra-partition computation. It is non-trivial to pipeline for efficient GCN training, as communicated node features/gradients will become stale and thus can harm the convergence, negating the pipeline benefit. Notably, little is known regarding the convergence rate of GCN training with both stale features and stale feature gradients. This work not only provides a theoretical convergence analysis but also finds the convergence rate of PipeGCN to be close to that of the vanilla distributed GCN training without any staleness. Furthermore, we develop a smoothing method to further improve PipeGCN's convergence. Extensive experiments show that PipeGCN can largely boost the training throughput (1.7x~28.5x) while achieving the same accuracy as its vanilla counterpart and existing full-graph training methods. The code is available at https://github.com/RICE-EIC/PipeGCN.
LDP: Learnable Dynamic Precision for Efficient Deep Neural Network Training and Inference
Mar 15, 2022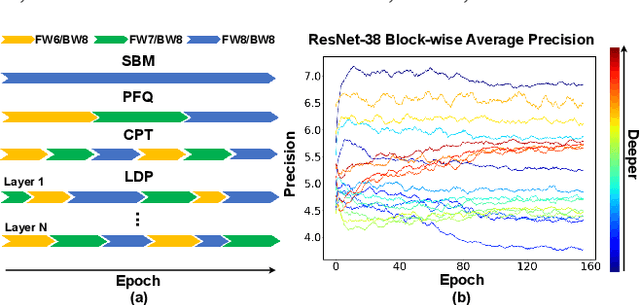

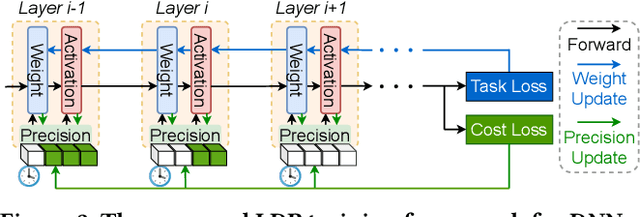

Low precision deep neural network (DNN) training is one of the most effective techniques for boosting DNNs' training efficiency, as it trims down the training cost from the finest bit level. While existing works mostly fix the model precision during the whole training process, a few pioneering works have shown that dynamic precision schedules help DNNs converge to a better accuracy while leading to a lower training cost than their static precision training counterparts. However, existing dynamic low precision training methods rely on manually designed precision schedules to achieve advantageous efficiency and accuracy trade-offs, limiting their more comprehensive practical applications and achievable performance. To this end, we propose LDP, a Learnable Dynamic Precision DNN training framework that can automatically learn a temporally and spatially dynamic precision schedule during training towards optimal accuracy and efficiency trade-offs. It is worth noting that LDP-trained DNNs are by nature efficient during inference. Furthermore, we visualize the resulting temporal and spatial precision schedule and distribution of LDP trained DNNs on different tasks to better understand the corresponding DNNs' characteristics at different training stages and DNN layers both during and after training, drawing insights for promoting further innovations. Extensive experiments and ablation studies (seven networks, five datasets, and three tasks) show that the proposed LDP consistently outperforms state-of-the-art (SOTA) low precision DNN training techniques in terms of training efficiency and achieved accuracy trade-offs. For example, in addition to having the advantage of being automated, our LDP achieves a 0.31\% higher accuracy with a 39.1\% lower computational cost when training ResNet-20 on CIFAR-10 as compared with the best SOTA method.
I-GCN: A Graph Convolutional Network Accelerator with Runtime Locality Enhancement through Islandization
Mar 07, 2022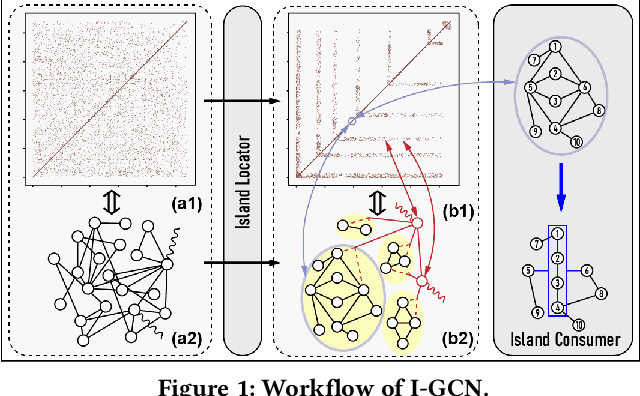
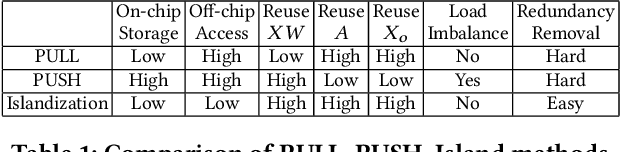

Graph Convolutional Networks (GCNs) have drawn tremendous attention in the past three years. Compared with other deep learning modalities, high-performance hardware acceleration of GCNs is as critical but even more challenging. The hurdles arise from the poor data locality and redundant computation due to the large size, high sparsity, and irregular non-zero distribution of real-world graphs. In this paper we propose a novel hardware accelerator for GCN inference, called I-GCN, that significantly improves data locality and reduces unnecessary computation. The mechanism is a new online graph restructuring algorithm we refer to as islandization. The proposed algorithm finds clusters of nodes with strong internal but weak external connections. The islandization process yields two major benefits. First, by processing islands rather than individual nodes, there is better on-chip data reuse and fewer off-chip memory accesses. Second, there is less redundant computation as aggregation for common/shared neighbors in an island can be reused. The parallel search, identification, and leverage of graph islands are all handled purely in hardware at runtime working in an incremental pipeline. This is done without any preprocessing of the graph data or adjustment of the GCN model structure. Experimental results show that I-GCN can significantly reduce off-chip accesses and prune 38% of aggregation operations, leading to performance speedups over CPUs, GPUs, the prior art GCN accelerators of 5549x, 403x, and 5.7x on average, respectively.
GCoD: Graph Convolutional Network Acceleration via Dedicated Algorithm and Accelerator Co-Design
Dec 22, 2021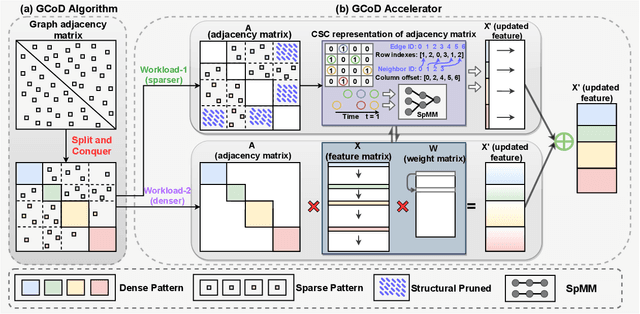
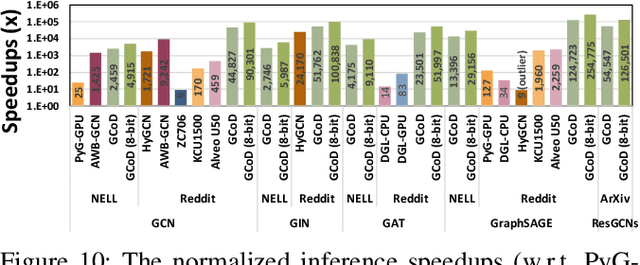

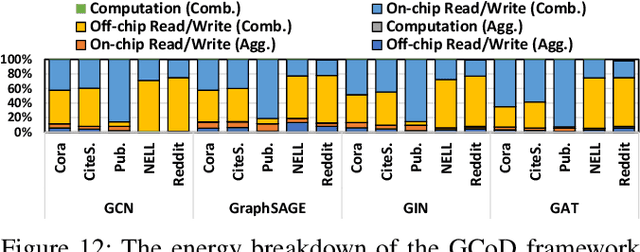
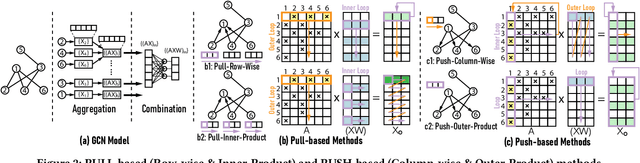
Graph Convolutional Networks (GCNs) have emerged as the state-of-the-art graph learning model. However, it can be notoriously challenging to inference GCNs over large graph datasets, limiting their application to large real-world graphs and hindering the exploration of deeper and more sophisticated GCN graphs. This is because real-world graphs can be extremely large and sparse. Furthermore, the node degree of GCNs tends to follow the power-law distribution and therefore have highly irregular adjacency matrices, resulting in prohibitive inefficiencies in both data processing and movement and thus substantially limiting the achievable GCN acceleration efficiency. To this end, this paper proposes a GCN algorithm and accelerator Co-Design framework dubbed GCoD which can largely alleviate the aforementioned GCN irregularity and boost GCNs' inference efficiency. Specifically, on the algorithm level, GCoD integrates a split and conquer GCN training strategy that polarizes the graphs to be either denser or sparser in local neighborhoods without compromising the model accuracy, resulting in graph adjacency matrices that (mostly) have merely two levels of workload and enjoys largely enhanced regularity and thus ease of acceleration. On the hardware level, we further develop a dedicated two-pronged accelerator with a separated engine to process each of the aforementioned denser and sparser workloads, further boosting the overall utilization and acceleration efficiency. Extensive experiments and ablation studies validate that our GCoD consistently reduces the number of off-chip accesses, leading to speedups of 15286x, 294x, 7.8x, and 2.5x as compared to CPUs, GPUs, and prior-art GCN accelerators including HyGCN and AWB-GCN, respectively, while maintaining or even improving the task accuracy.
MIA-Former: Efficient and Robust Vision Transformers via Multi-grained Input-Adaptation
Dec 21, 2021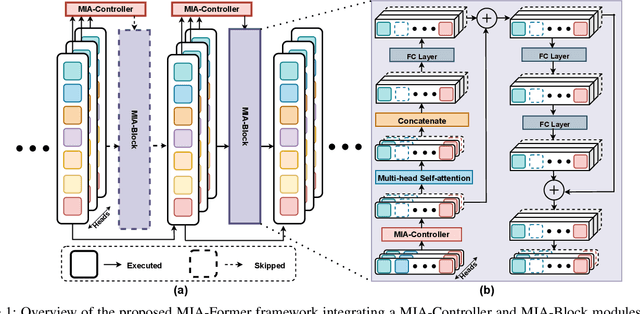
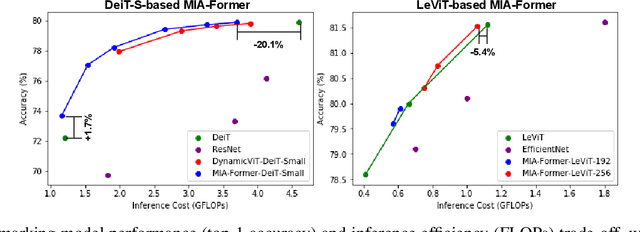
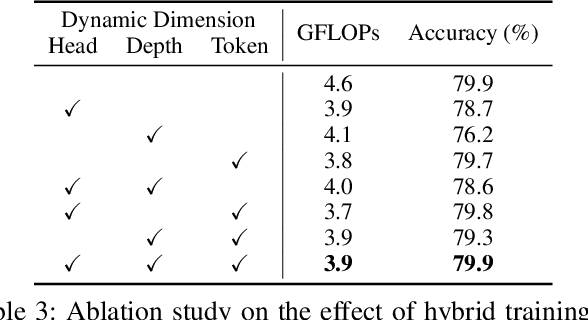
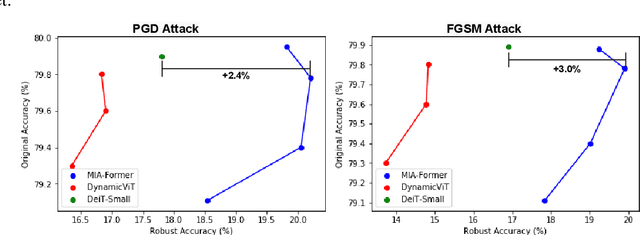
ViTs are often too computationally expensive to be fitted onto real-world resource-constrained devices, due to (1) their quadratically increased complexity with the number of input tokens and (2) their overparameterized self-attention heads and model depth. In parallel, different images are of varied complexity and their different regions can contain various levels of visual information, indicating that treating all regions/tokens equally in terms of model complexity is unnecessary while such opportunities for trimming down ViTs' complexity have not been fully explored. To this end, we propose a Multi-grained Input-adaptive Vision Transformer framework dubbed MIA-Former that can input-adaptively adjust the structure of ViTs at three coarse-to-fine-grained granularities (i.e., model depth and the number of model heads/tokens). In particular, our MIA-Former adopts a low-cost network trained with a hybrid supervised and reinforcement training method to skip unnecessary layers, heads, and tokens in an input adaptive manner, reducing the overall computational cost. Furthermore, an interesting side effect of our MIA-Former is that its resulting ViTs are naturally equipped with improved robustness against adversarial attacks over their static counterparts, because MIA-Former's multi-grained dynamic control improves the model diversity similar to the effect of ensemble and thus increases the difficulty of adversarial attacks against all its sub-models. Extensive experiments and ablation studies validate that the proposed MIA-Former framework can effectively allocate computation budgets adaptive to the difficulty of input images meanwhile increase robustness, achieving state-of-the-art (SOTA) accuracy-efficiency trade-offs, e.g., 20% computation savings with the same or even a higher accuracy compared with SOTA dynamic transformer models.
FBNetV5: Neural Architecture Search for Multiple Tasks in One Run
Nov 30, 2021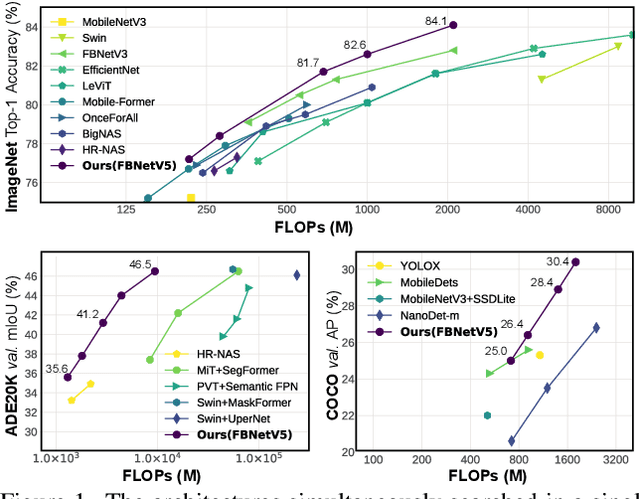
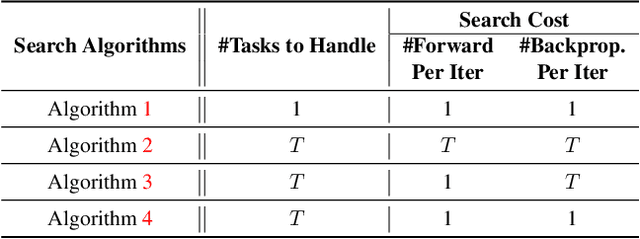
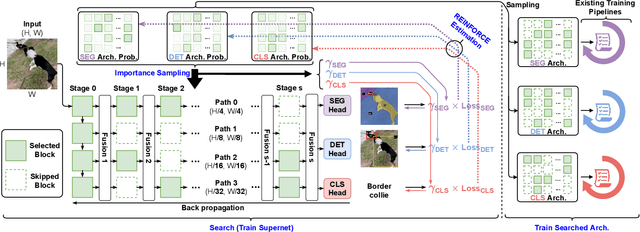
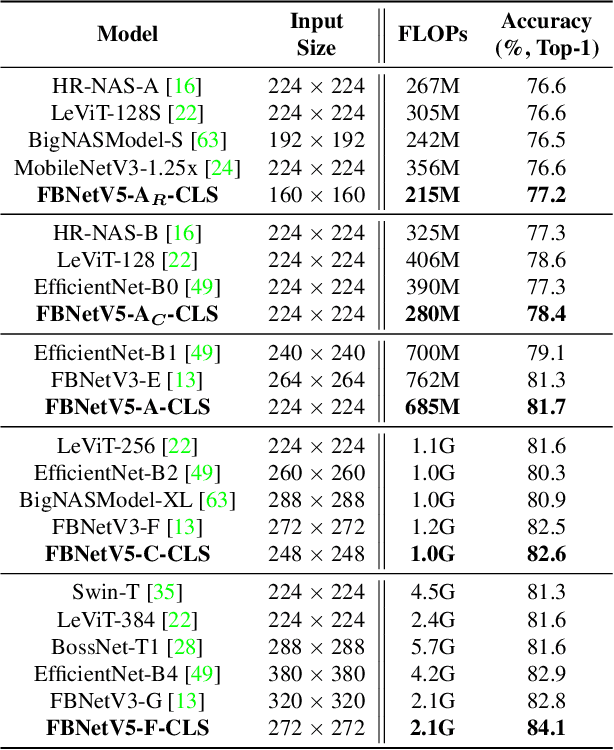
Neural Architecture Search (NAS) has been widely adopted to design accurate and efficient image classification models. However, applying NAS to a new computer vision task still requires a huge amount of effort. This is because 1) previous NAS research has been over-prioritized on image classification while largely ignoring other tasks; 2) many NAS works focus on optimizing task-specific components that cannot be favorably transferred to other tasks; and 3) existing NAS methods are typically designed to be "proxyless" and require significant effort to be integrated with each new task's training pipelines. To tackle these challenges, we propose FBNetV5, a NAS framework that can search for neural architectures for a variety of vision tasks with much reduced computational cost and human effort. Specifically, we design 1) a search space that is simple yet inclusive and transferable; 2) a multitask search process that is disentangled with target tasks' training pipeline; and 3) an algorithm to simultaneously search for architectures for multiple tasks with a computational cost agnostic to the number of tasks. We evaluate the proposed FBNetV5 targeting three fundamental vision tasks -- image classification, object detection, and semantic segmentation. Models searched by FBNetV5 in a single run of search have outperformed the previous stateof-the-art in all the three tasks: image classification (e.g., +1.3% ImageNet top-1 accuracy under the same FLOPs as compared to FBNetV3), semantic segmentation (e.g., +1.8% higher ADE20K val. mIoU than SegFormer with 3.6x fewer FLOPs), and object detection (e.g., +1.1% COCO val. mAP with 1.2x fewer FLOPs as compared to YOLOX).