 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWave-ViT: Unifying Wavelet and Transformers for Visual Representation Learning
Jul 11, 2022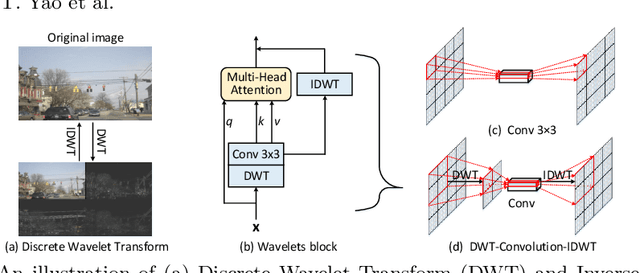
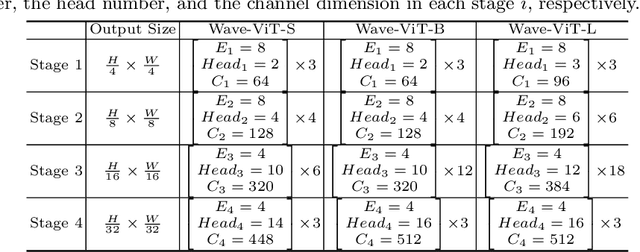
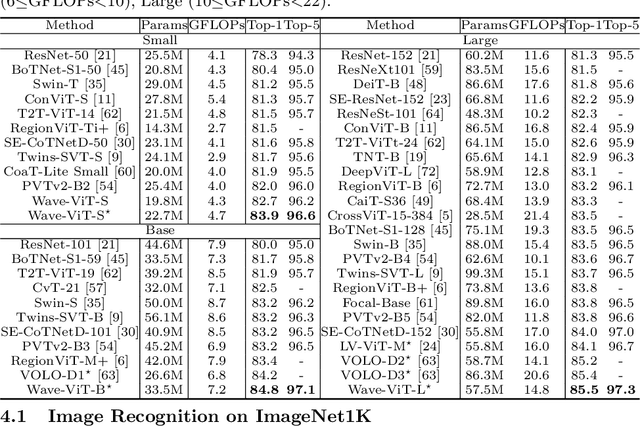
Multi-scale Vision Transformer (ViT) has emerged as a powerful backbone for computer vision tasks, while the self-attention computation in Transformer scales quadratically w.r.t. the input patch number. Thus, existing solutions commonly employ down-sampling operations (e.g., average pooling) over keys/values to dramatically reduce the computational cost. In this work, we argue that such over-aggressive down-sampling design is not invertible and inevitably causes information dropping especially for high-frequency components in objects (e.g., texture details). Motivated by the wavelet theory, we construct a new Wavelet Vision Transformer (\textbf{Wave-ViT}) that formulates the invertible down-sampling with wavelet transforms and self-attention learning in a unified way. This proposal enables self-attention learning with lossless down-sampling over keys/values, facilitating the pursuing of a better efficiency-vs-accuracy trade-off. Furthermore, inverse wavelet transforms are leveraged to strengthen self-attention outputs by aggregating local contexts with enlarged receptive field. We validate the superiority of Wave-ViT through extensive experiments over multiple vision tasks (e.g., image recognition, object detection and instance segmentation). Its performances surpass state-of-the-art ViT backbones with comparable FLOPs. Source code is available at \url{https://github.com/YehLi/ImageNetModel}.
Stand-Alone Inter-Frame Attention in Video Models
Jun 14, 2022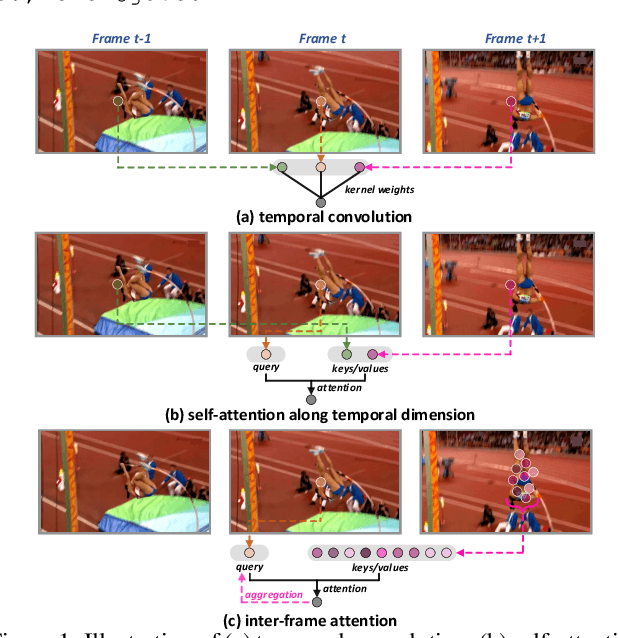
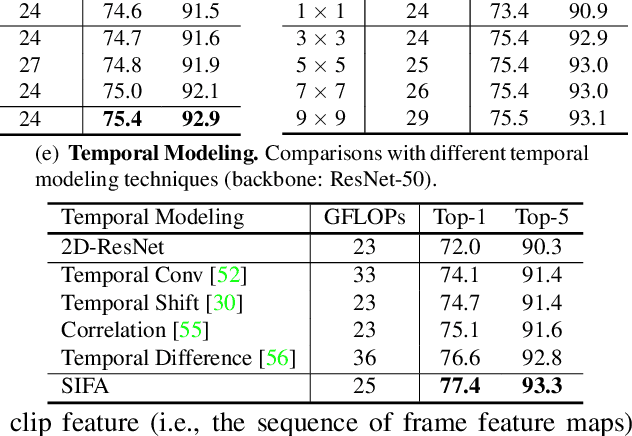
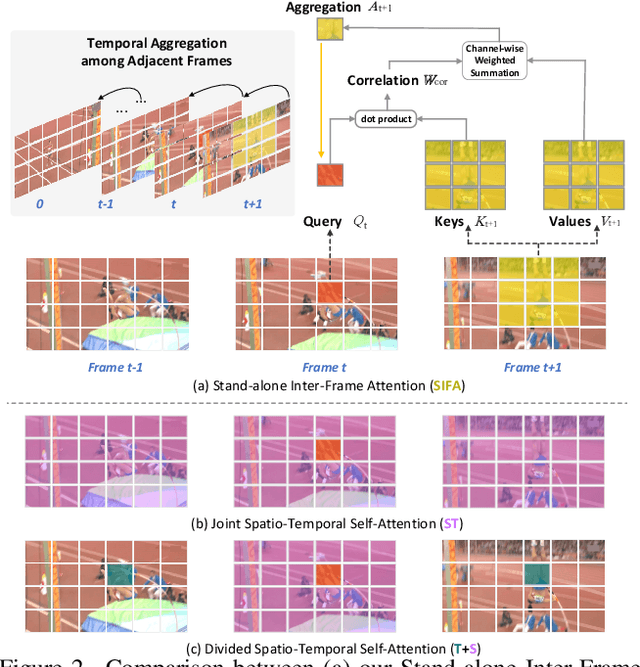
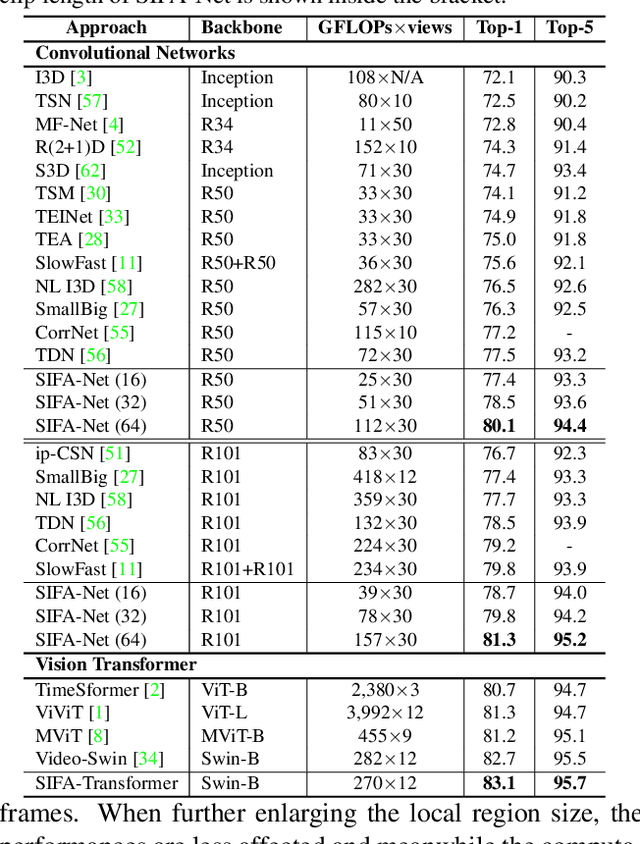
Motion, as the uniqueness of a video, has been critical to the development of video understanding models. Modern deep learning models leverage motion by either executing spatio-temporal 3D convolutions, factorizing 3D convolutions into spatial and temporal convolutions separately, or computing self-attention along temporal dimension. The implicit assumption behind such successes is that the feature maps across consecutive frames can be nicely aggregated. Nevertheless, the assumption may not always hold especially for the regions with large deformation. In this paper, we present a new recipe of inter-frame attention block, namely Stand-alone Inter-Frame Attention (SIFA), that novelly delves into the deformation across frames to estimate local self-attention on each spatial location. Technically, SIFA remoulds the deformable design via re-scaling the offset predictions by the difference between two frames. Taking each spatial location in the current frame as the query, the locally deformable neighbors in the next frame are regarded as the keys/values. Then, SIFA measures the similarity between query and keys as stand-alone attention to weighted average the values for temporal aggregation. We further plug SIFA block into ConvNets and Vision Transformer, respectively, to devise SIFA-Net and SIFA-Transformer. Extensive experiments conducted on four video datasets demonstrate the superiority of SIFA-Net and SIFA-Transformer as stronger backbones. More remarkably, SIFA-Transformer achieves an accuracy of 83.1% on Kinetics-400 dataset. Source code is available at \url{https://github.com/FuchenUSTC/SIFA}.
Comprehending and Ordering Semantics for Image Captioning
Jun 14, 2022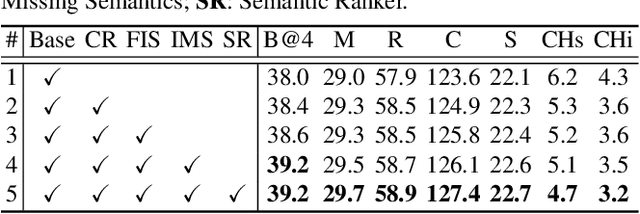
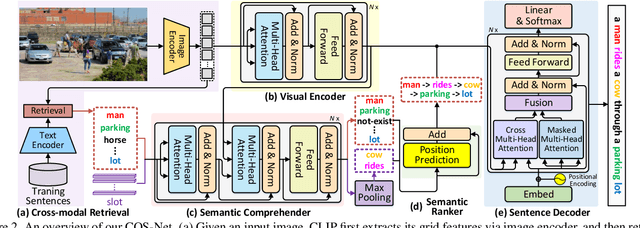
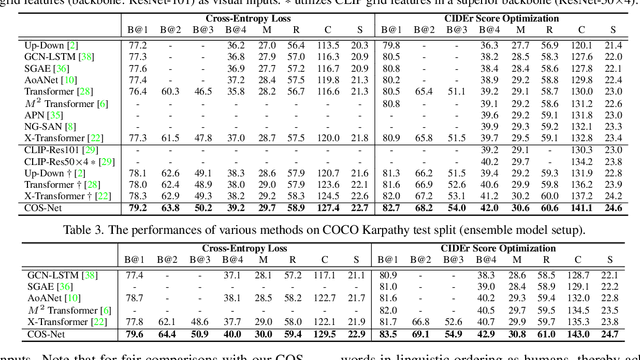
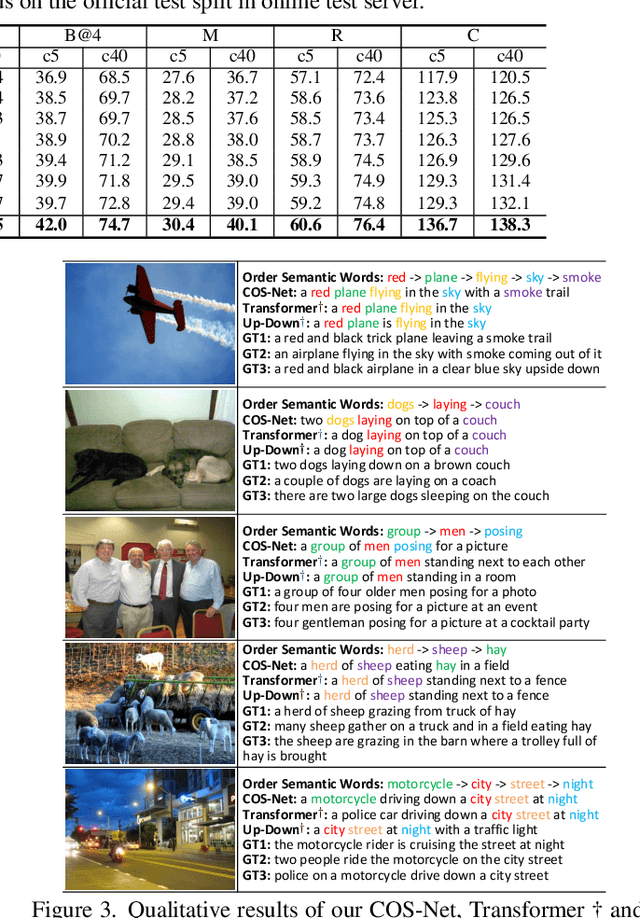
Comprehending the rich semantics in an image and ordering them in linguistic order are essential to compose a visually-grounded and linguistically coherent description for image captioning. Modern techniques commonly capitalize on a pre-trained object detector/classifier to mine the semantics in an image, while leaving the inherent linguistic ordering of semantics under-exploited. In this paper, we propose a new recipe of Transformer-style structure, namely Comprehending and Ordering Semantics Networks (COS-Net), that novelly unifies an enriched semantic comprehending and a learnable semantic ordering processes into a single architecture. Technically, we initially utilize a cross-modal retrieval model to search the relevant sentences of each image, and all words in the searched sentences are taken as primary semantic cues. Next, a novel semantic comprehender is devised to filter out the irrelevant semantic words in primary semantic cues, and meanwhile infer the missing relevant semantic words visually grounded in the image. After that, we feed all the screened and enriched semantic words into a semantic ranker, which learns to allocate all semantic words in linguistic order as humans. Such sequence of ordered semantic words are further integrated with visual tokens of images to trigger sentence generation. Empirical evidences show that COS-Net clearly surpasses the state-of-the-art approaches on COCO and achieves to-date the best CIDEr score of 141.1% on Karpathy test split. Source code is available at \url{https://github.com/YehLi/xmodaler/tree/master/configs/image_caption/cosnet}.
Exploring Structure-aware Transformer over Interaction Proposals for Human-Object Interaction Detection
Jun 13, 2022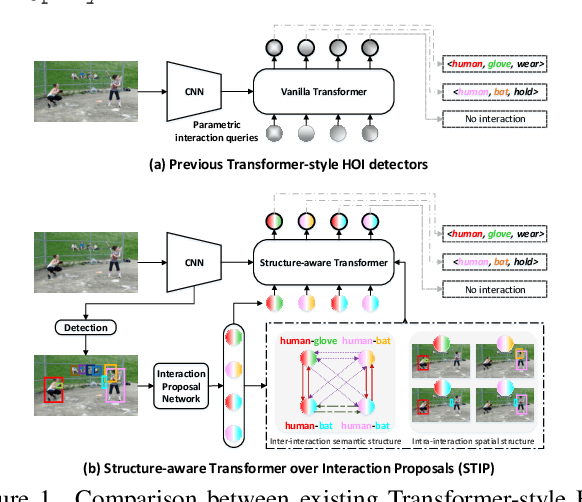
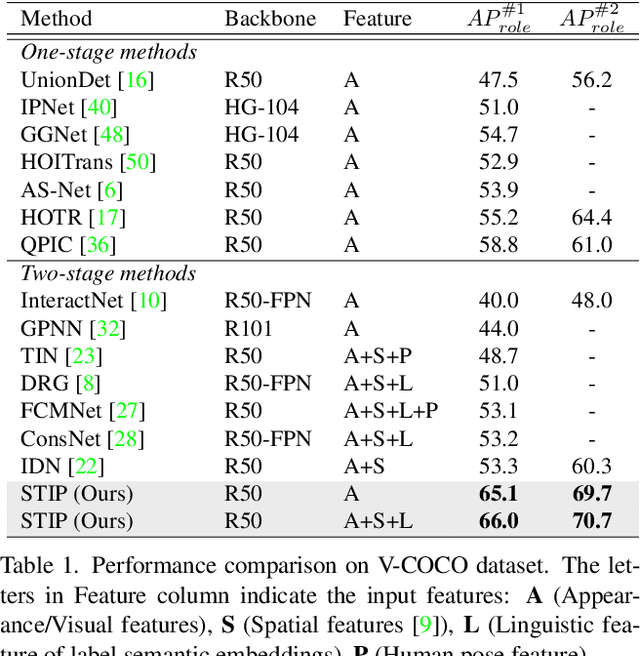
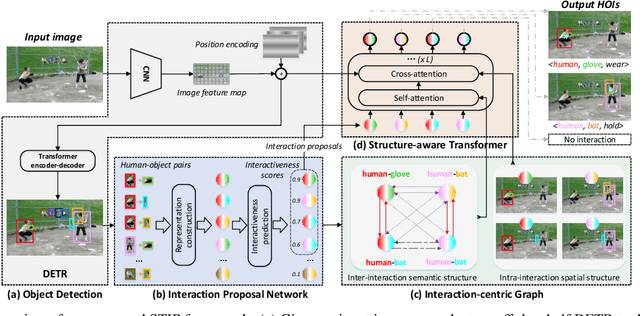
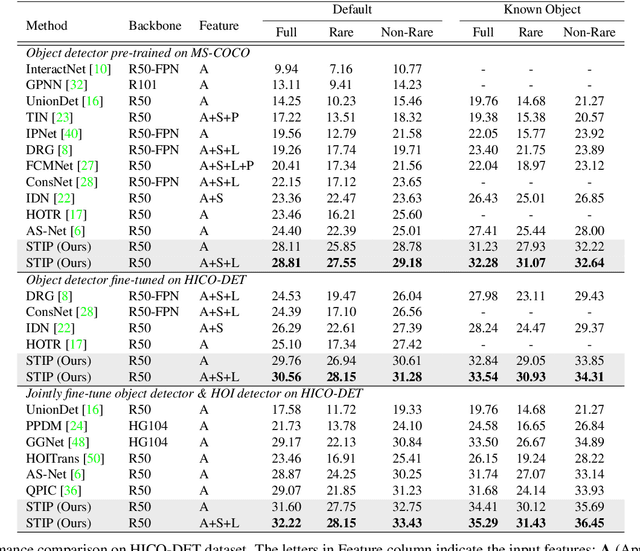
Recent high-performing Human-Object Interaction (HOI) detection techniques have been highly influenced by Transformer-based object detector (i.e., DETR). Nevertheless, most of them directly map parametric interaction queries into a set of HOI predictions through vanilla Transformer in a one-stage manner. This leaves rich inter- or intra-interaction structure under-exploited. In this work, we design a novel Transformer-style HOI detector, i.e., Structure-aware Transformer over Interaction Proposals (STIP), for HOI detection. Such design decomposes the process of HOI set prediction into two subsequent phases, i.e., an interaction proposal generation is first performed, and then followed by transforming the non-parametric interaction proposals into HOI predictions via a structure-aware Transformer. The structure-aware Transformer upgrades vanilla Transformer by encoding additionally the holistically semantic structure among interaction proposals as well as the locally spatial structure of human/object within each interaction proposal, so as to strengthen HOI predictions. Extensive experiments conducted on V-COCO and HICO-DET benchmarks have demonstrated the effectiveness of STIP, and superior results are reported when comparing with the state-of-the-art HOI detectors. Source code is available at \url{https://github.com/zyong812/STIP}.
Silver-Bullet-3D at ManiSkill 2021: Learning-from-Demonstrations and Heuristic Rule-based Methods for Object Manipulation
Jun 13, 2022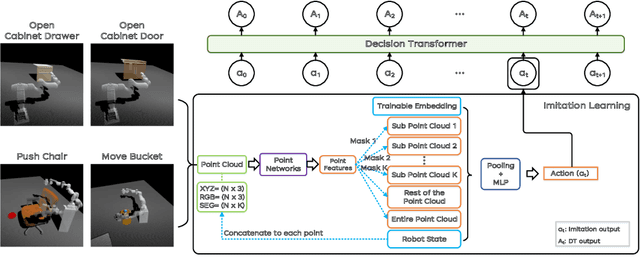



This paper presents an overview and comparative analysis of our systems designed for the following two tracks in SAPIEN ManiSkill Challenge 2021: No Interaction Track: The No Interaction track targets for learning policies from pre-collected demonstration trajectories. We investigate both imitation learning-based approach, i.e., imitating the observed behavior using classical supervised learning techniques, and offline reinforcement learning-based approaches, for this track. Moreover, the geometry and texture structures of objects and robotic arms are exploited via Transformer-based networks to facilitate imitation learning. No Restriction Track: In this track, we design a Heuristic Rule-based Method (HRM) to trigger high-quality object manipulation by decomposing the task into a series of sub-tasks. For each sub-task, the simple rule-based controlling strategies are adopted to predict actions that can be applied to robotic arms. To ease the implementations of our systems, all the source codes and pre-trained models are available at \url{https://github.com/caiqi/Silver-Bullet-3D/}.
A Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
Representing Videos as Discriminative Sub-graphs for Action Recognition
Jan 11, 2022

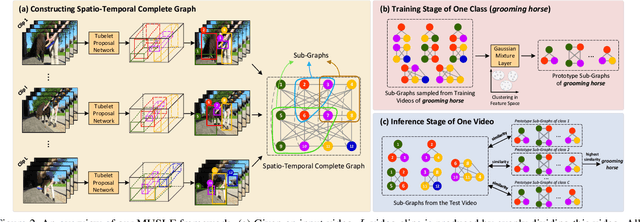
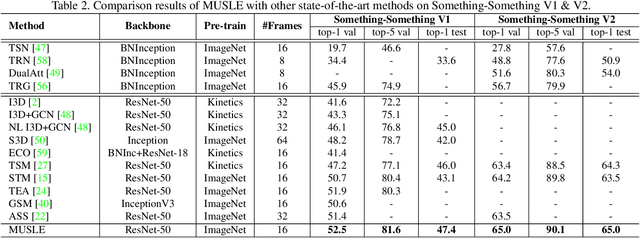
Human actions are typically of combinatorial structures or patterns, i.e., subjects, objects, plus spatio-temporal interactions in between. Discovering such structures is therefore a rewarding way to reason about the dynamics of interactions and recognize the actions. In this paper, we introduce a new design of sub-graphs to represent and encode the discriminative patterns of each action in the videos. Specifically, we present MUlti-scale Sub-graph LEarning (MUSLE) framework that novelly builds space-time graphs and clusters the graphs into compact sub-graphs on each scale with respect to the number of nodes. Technically, MUSLE produces 3D bounding boxes, i.e., tubelets, in each video clip, as graph nodes and takes dense connectivity as graph edges between tubelets. For each action category, we execute online clustering to decompose the graph into sub-graphs on each scale through learning Gaussian Mixture Layer and select the discriminative sub-graphs as action prototypes for recognition. Extensive experiments are conducted on both Something-Something V1 & V2 and Kinetics-400 datasets, and superior results are reported when comparing to state-of-the-art methods. More remarkably, our MUSLE achieves to-date the best reported accuracy of 65.0% on Something-Something V2 validation set.
Uni-EDEN: Universal Encoder-Decoder Network by Multi-Granular Vision-Language Pre-training
Jan 11, 2022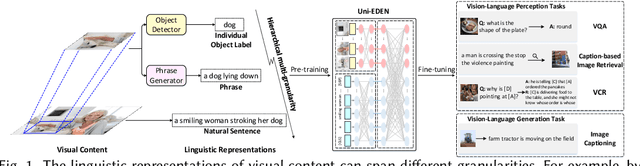
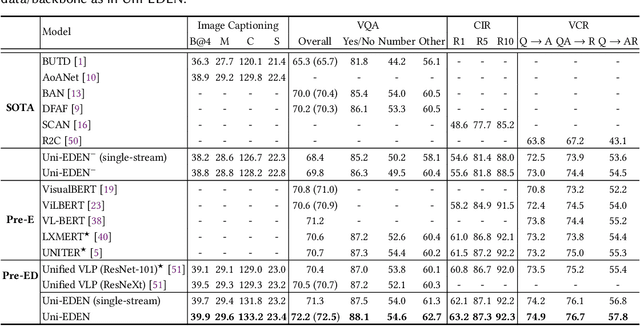
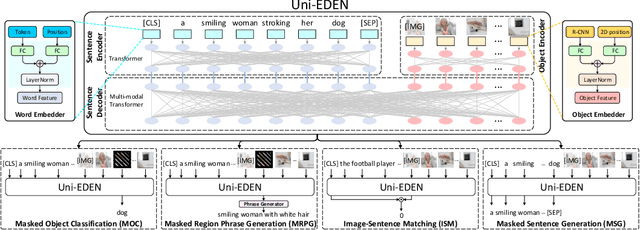
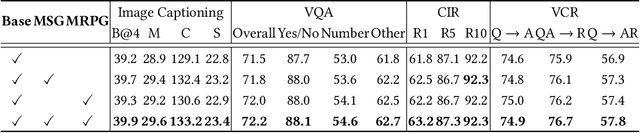
Vision-language pre-training has been an emerging and fast-developing research topic, which transfers multi-modal knowledge from rich-resource pre-training task to limited-resource downstream tasks. Unlike existing works that predominantly learn a single generic encoder, we present a pre-trainable Universal Encoder-DEcoder Network (Uni-EDEN) to facilitate both vision-language perception (e.g., visual question answering) and generation (e.g., image captioning). Uni-EDEN is a two-stream Transformer based structure, consisting of three modules: object and sentence encoders that separately learns the representations of each modality, and sentence decoder that enables both multi-modal reasoning and sentence generation via inter-modal interaction. Considering that the linguistic representations of each image can span different granularities in this hierarchy including, from simple to comprehensive, individual label, a phrase, and a natural sentence, we pre-train Uni-EDEN through multi-granular vision-language proxy tasks: Masked Object Classification (MOC), Masked Region Phrase Generation (MRPG), Image-Sentence Matching (ISM), and Masked Sentence Generation (MSG). In this way, Uni-EDEN is endowed with the power of both multi-modal representation extraction and language modeling. Extensive experiments demonstrate the compelling generalizability of Uni-EDEN by fine-tuning it to four vision-language perception and generation downstream tasks.
Smart Director: An Event-Driven Directing System for Live Broadcasting
Jan 11, 2022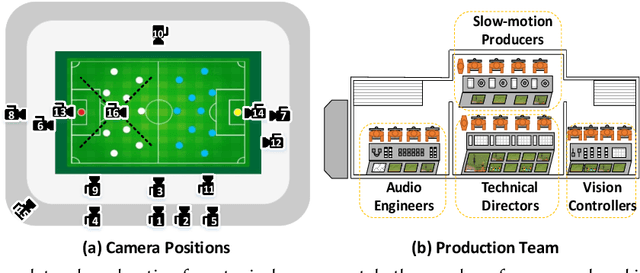
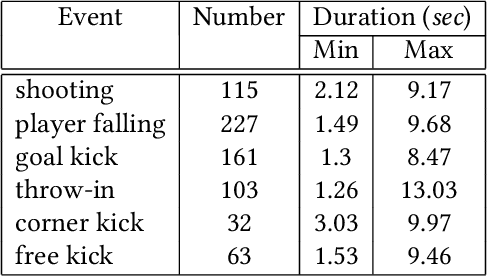
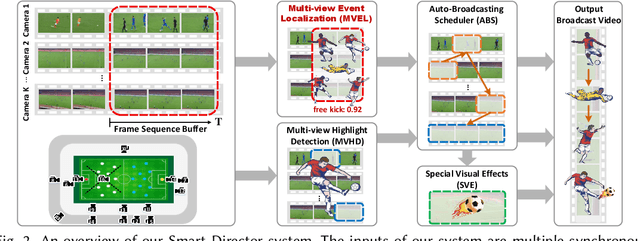
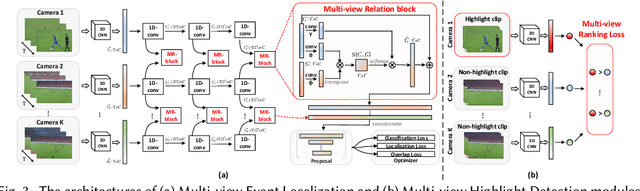
Live video broadcasting normally requires a multitude of skills and expertise with domain knowledge to enable multi-camera productions. As the number of cameras keep increasing, directing a live sports broadcast has now become more complicated and challenging than ever before. The broadcast directors need to be much more concentrated, responsive, and knowledgeable, during the production. To relieve the directors from their intensive efforts, we develop an innovative automated sports broadcast directing system, called Smart Director, which aims at mimicking the typical human-in-the-loop broadcasting process to automatically create near-professional broadcasting programs in real-time by using a set of advanced multi-view video analysis algorithms. Inspired by the so-called "three-event" construction of sports broadcast, we build our system with an event-driven pipeline consisting of three consecutive novel components: 1) the Multi-view Event Localization to detect events by modeling multi-view correlations, 2) the Multi-view Highlight Detection to rank camera views by the visual importance for view selection, 3) the Auto-Broadcasting Scheduler to control the production of broadcasting videos. To our best knowledge, our system is the first end-to-end automated directing system for multi-camera sports broadcasting, completely driven by the semantic understanding of sports events. It is also the first system to solve the novel problem of multi-view joint event detection by cross-view relation modeling. We conduct both objective and subjective evaluations on a real-world multi-camera soccer dataset, which demonstrate the quality of our auto-generated videos is comparable to that of the human-directed. Thanks to its faster response, our system is able to capture more fast-passing and short-duration events which are usually missed by human directors.
Improving Self-supervised Learning with Automated Unsupervised Outlier Arbitration
Dec 15, 2021

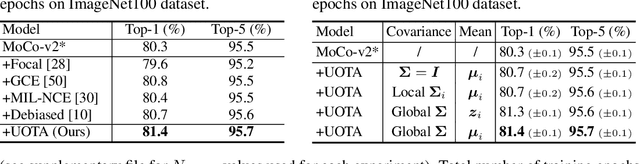
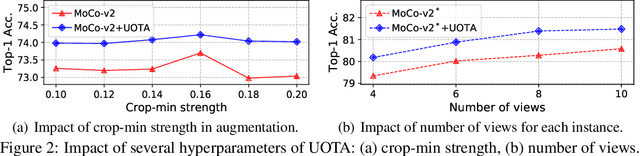
Our work reveals a structured shortcoming of the existing mainstream self-supervised learning methods. Whereas self-supervised learning frameworks usually take the prevailing perfect instance level invariance hypothesis for granted, we carefully investigate the pitfalls behind. Particularly, we argue that the existing augmentation pipeline for generating multiple positive views naturally introduces out-of-distribution (OOD) samples that undermine the learning of the downstream tasks. Generating diverse positive augmentations on the input does not always pay off in benefiting downstream tasks. To overcome this inherent deficiency, we introduce a lightweight latent variable model UOTA, targeting the view sampling issue for self-supervised learning. UOTA adaptively searches for the most important sampling region to produce views, and provides viable choice for outlier-robust self-supervised learning approaches. Our method directly generalizes to many mainstream self-supervised learning approaches, regardless of the loss's nature contrastive or not. We empirically show UOTA's advantage over the state-of-the-art self-supervised paradigms with evident margin, which well justifies the existence of the OOD sample issue embedded in the existing approaches. Especially, we theoretically prove that the merits of the proposal boil down to guaranteed estimator variance and bias reduction. Code is available: at https://github.com/ssl-codelab/uota.