 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Augmented Automated Graph Contrastive Learning
Mar 24, 2023Graph augmentations are essential for graph contrastive learning. Most existing works use pre-defined random augmentations, which are usually unable to adapt to different input graphs and fail to consider the impact of different nodes and edges on graph semantics. To address this issue, we propose a framework called Hybrid Augmented Automated Graph Contrastive Learning (HAGCL). HAGCL consists of a feature-level learnable view generator and an edge-level learnable view generator. The view generators are end-to-end differentiable to learn the probability distribution of views conditioned on the input graph. It insures to learn the most semantically meaningful structure in terms of features and topology, respectively. Furthermore, we propose an improved joint training strategy, which can achieve better results than previous works without resorting to any weak label information in the downstream tasks and extensive evaluation of additional work.
Tightening Discretization-based MILP Models for the Pooling Problem using Upper Bounds on Bilinear Terms
Jul 08, 2022
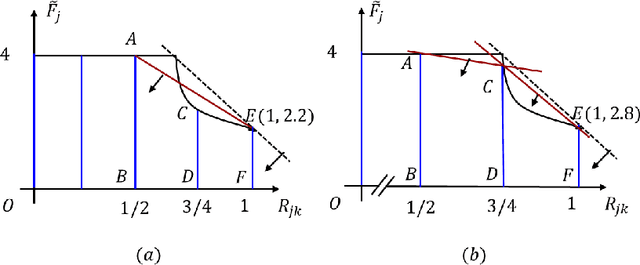
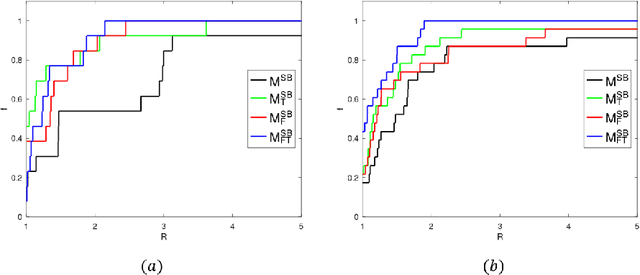
Discretization-based methods have been proposed for solving nonconvex optimization problems with bilinear terms. These methods convert the original nonconvex optimization problems into mixed-integer linear programs (MILPs). Compared to a wide range of studies related to methods to convert nonconvex optimization problems into MILPs, research on tightening the resulting MILP models is limited. In this paper, we present tightening constraints for the discretization-based MILP models for the pooling problem. Specifically, we study tightening constraints derived from upper bounds on bilinear term and exploiting the structures resulting from the discretization. We demonstrate the effectiveness of our constraints, showing computational results for MILP models derived from different formulations for (1) the pooling problem and (2) discretization-based pooling models. Computational results show that our methods reduce the computational time for MILP models on CPLEX 12.10. Finally, we note that while our methods are presented in the context of the pooling problem, they can be extended to address other nonconvex optimization problems with upper bounds on bilinear terms.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Tackling Catastrophic Forgetting and Background Shift in Continual Semantic Segmentation
Jun 29, 2021
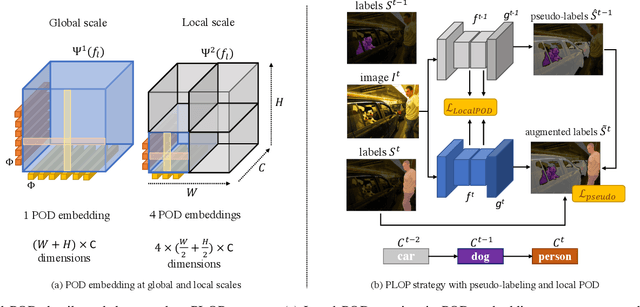
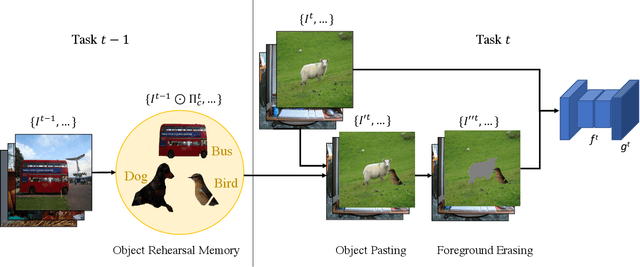

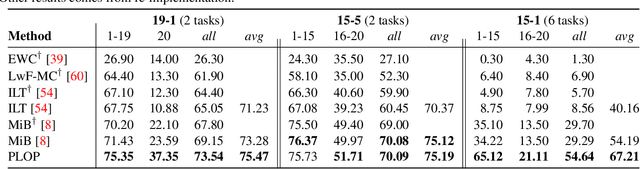
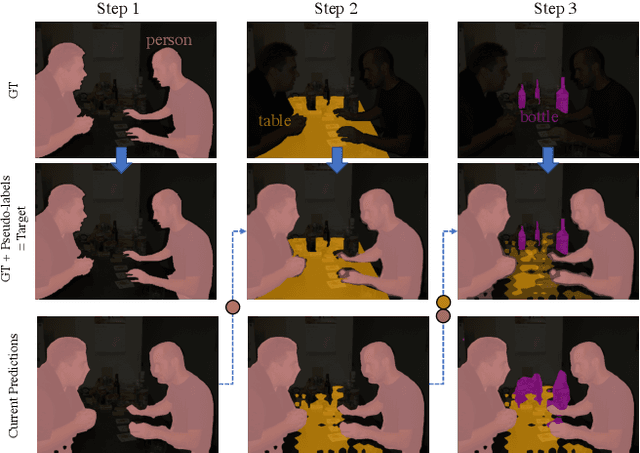
Deep learning approaches are nowadays ubiquitously used to tackle computer vision tasks such as semantic segmentation, requiring large datasets and substantial computational power. Continual learning for semantic segmentation (CSS) is an emerging trend that consists in updating an old model by sequentially adding new classes. However, continual learning methods are usually prone to catastrophic forgetting. This issue is further aggravated in CSS where, at each step, old classes from previous iterations are collapsed into the background. In this paper, we propose Local POD, a multi-scale pooling distillation scheme that preserves long- and short-range spatial relationships at feature level. Furthermore, we design an entropy-based pseudo-labelling of the background w.r.t. classes predicted by the old model to deal with background shift and avoid catastrophic forgetting of the old classes. Finally, we introduce a novel rehearsal method that is particularly suited for segmentation. Our approach, called PLOP, significantly outperforms state-of-the-art methods in existing CSS scenarios, as well as in newly proposed challenging benchmarks.
PLOP: Learning without Forgetting for Continual Semantic Segmentation
Nov 24, 2020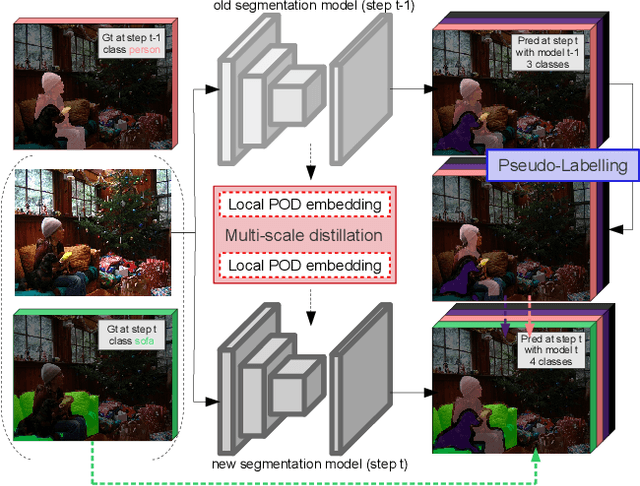

Deep learning approaches are nowadays ubiquitously used to tackle computer vision tasks such as semantic segmentation, requiring large datasets and substantial computational power. Continual learning for semantic segmentation (CSS) is an emerging trend that consists in updating an old model by sequentially adding new classes. However, continual learning methods are usually prone to catastrophic forgetting. This issue is further aggravated in CSS where, at each step, old classes from previous iterations are collapsed into the background. In this paper, we propose Local POD, a multi-scale pooling distillation scheme that preserves long- and short-range spatial relationships at feature level. Furthermore, we design an entropy-based pseudo-labelling of the background w.r.t. classes predicted by the old model to deal with background shift and avoid catastrophic forgetting of the old classes. Our approach, called PLOP, significantly outperforms state-of-the-art methods in existing CSS scenarios, as well as in newly proposed challenging benchmarks.
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
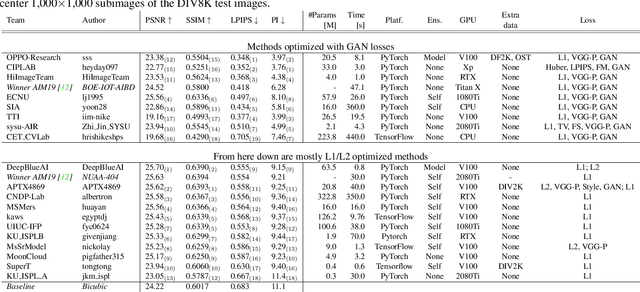

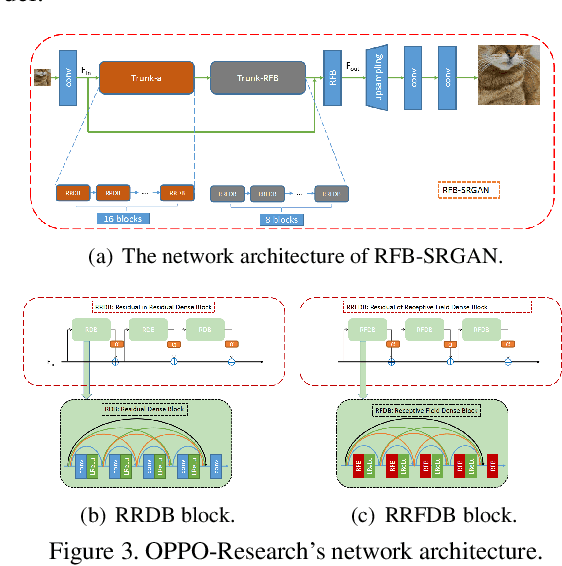
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.
Guiding Variational Response Generator to Exploit Persona
Nov 06, 2019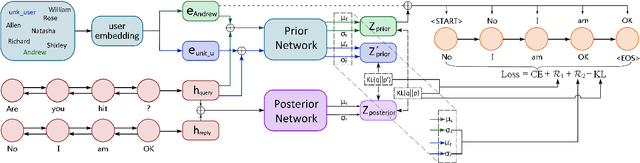
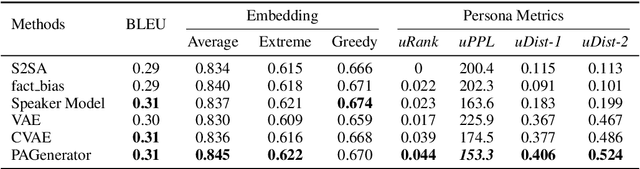
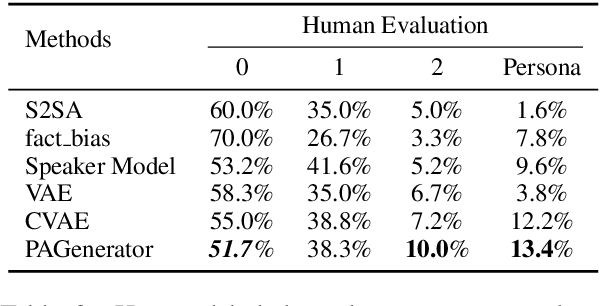

Leveraging persona information of users in Neural Response Generators (NRG) to perform personalized conversations has been considered as an attractive and important topic in the research of conversational agents over the past few years. Despite of the promising progresses achieved by recent studies in this field, persona information tends to be incorporated into neural networks in the form of user embeddings, with the expectation that the persona can be involved via the End-to-End learning. This paper proposes to adopt the personality-related characteristics of human conversations into variational response generators, by designing a specific conditional variational autoencoder based deep model with two new regularization terms employed to the loss function, so as to guide the optimization towards the direction of generating both persona-aware and relevant responses. Besides, to reasonably evaluate the performances of various persona modeling approaches, this paper further presents three direct persona-oriented metrics from different perspectives. The experimental results have shown that our proposed methodology can notably improve the performance of persona-aware response generation, and the metrics are reasonable to evaluate the results.
REVE: Regularizing Deep Learning with Variational Entropy Bound
Oct 15, 2019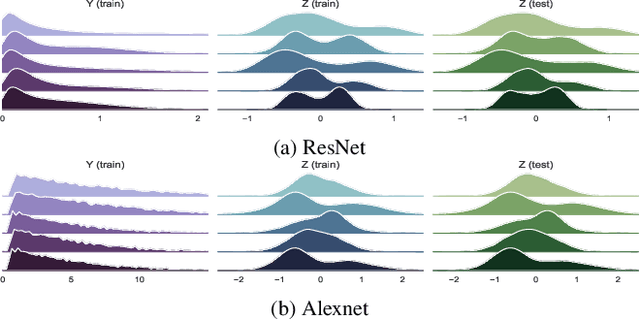
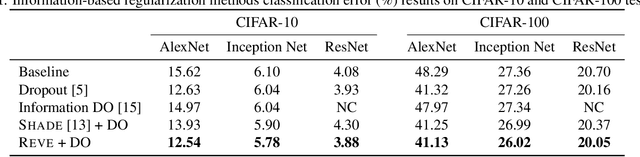
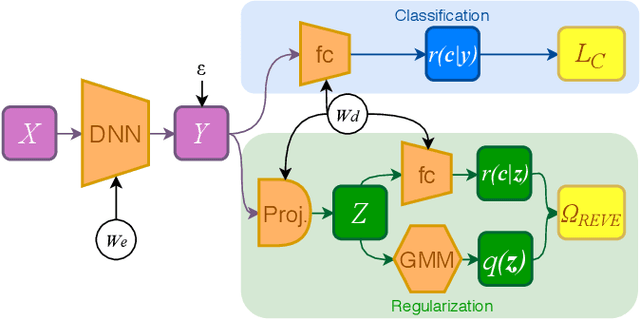
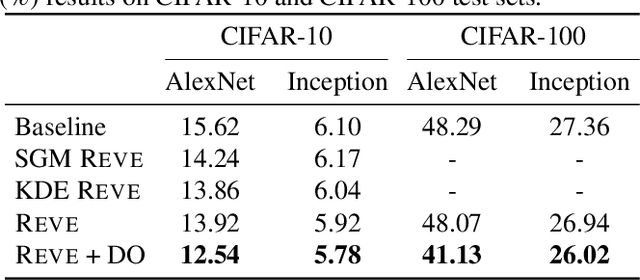
Studies on generalization performance of machine learning algorithms under the scope of information theory suggest that compressed representations can guarantee good generalization, inspiring many compression-based regularization methods. In this paper, we introduce REVE, a new regularization scheme. Noting that compressing the representation can be sub-optimal, our first contribution is to identify a variable that is directly responsible for the final prediction. Our method aims at compressing the class conditioned entropy of this latter variable. Second, we introduce a variational upper bound on this conditional entropy term. Finally, we propose a scheme to instantiate a tractable loss that is integrated within the training procedure of the neural network and demonstrate its efficiency on different neural networks and datasets.
MemeFaceGenerator: Adversarial Synthesis of Chinese Meme-face from Natural Sentences
Aug 14, 2019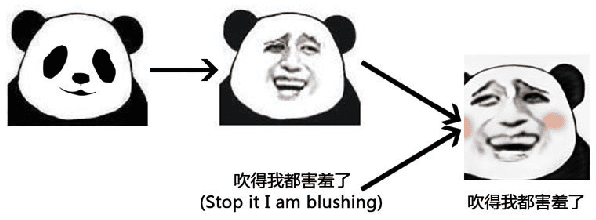
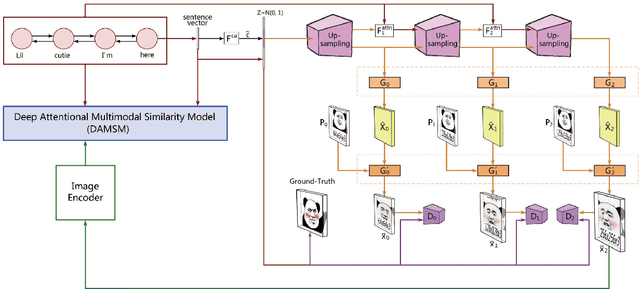
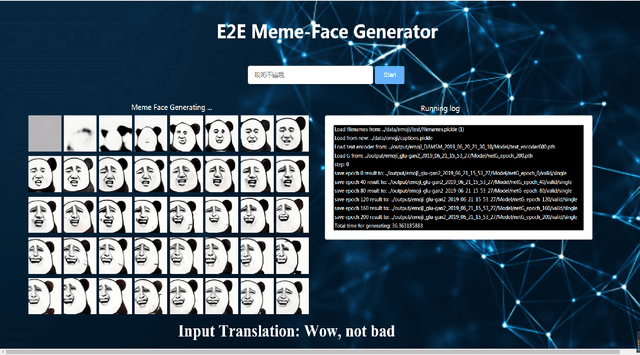

Chinese meme-face is a special kind of internet subculture widely spread in Chinese Social Community Networks. It usually consists of a template image modified by some amusing details and a text caption. In this paper, we present MemeFaceGenerator, a Generative Adversarial Network with the attention module and template information as supplementary signals, to automatically generate meme-faces from text inputs. We also develop a web service as system demonstration of meme-face synthesis. MemeFaceGenerator has been shown to be capable of generating high-quality meme-faces from random text inputs.
SEMEDA: Enhancing Segmentation Precision with Semantic Edge Aware Loss
May 06, 2019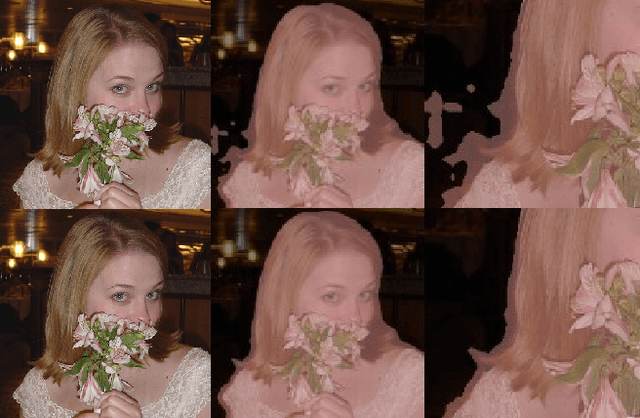
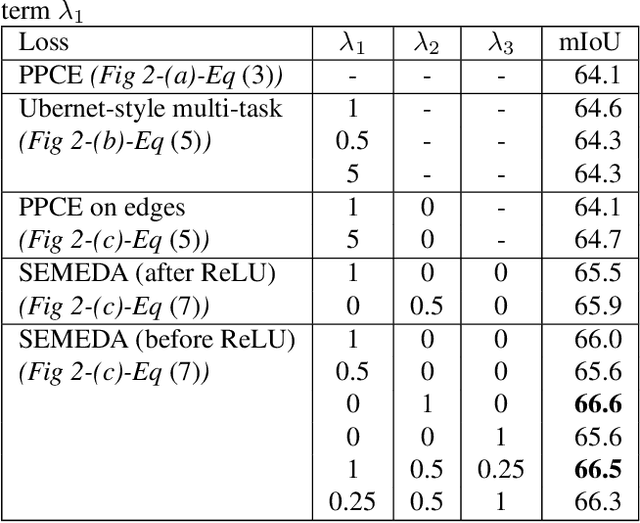

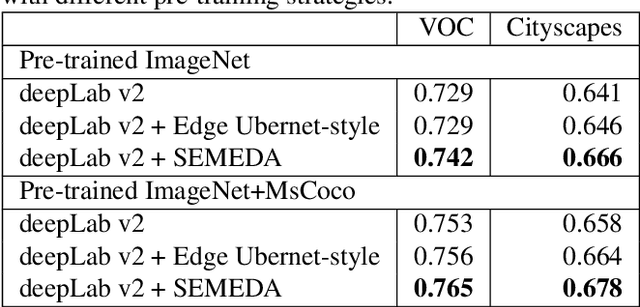
While nowadays deep neural networks achieve impressive performances on semantic segmentation tasks, they are usually trained by optimizing pixel-wise losses such as cross-entropy. As a result, the predictions outputted by such networks usually struggle to accurately capture the object boundaries and exhibit holes inside the objects. In this paper, we propose a novel approach to improve the structure of the predicted segmentation masks. We introduce a novel semantic edge detection network, which allows to match the predicted and ground truth segmentation masks. This Semantic Edge-Aware strategy (SEMEDA) can be combined with any backbone deep network in an end-to-end training framework. Through thorough experimental validation on Pascal VOC 2012 and Cityscapes datasets, we show that the proposed SEMEDA approach enhances the structure of the predicted segmentation masks by enforcing sharp boundaries and avoiding discontinuities inside objects, improving the segmentation performance. In addition, our semantic edge-aware loss can be integrated into any popular segmentation network without requiring any additional annotation and with negligible computational load, as compared to standard pixel-wise cross-entropy loss.